以前作成したGitHub Codespaces上のローカルLLM&LangFlowの環境のハンズオンを作成してみました。
これを行うと、ブラウザだけでLLM&RAGノーコード開発が可能になります。ハンズオンは60分想定で作成しましたが、そんなにかからないと思います。
必要なのはGitHubのアカウントだけなのでやってみてね。(自分は大学の授業で展開する予定🫡)
参考
1. はじめに(約3分)
このハンズオンで学べること
ブラウザのみを使用して、企業でも安心して使えるローカルLLM×RAGチャットボットをほぼノーコードで作成します。
この記事について
対象読者
- AIアプリケーション開発に興味があるが、プログラミング経験がない方
- 企業でセキュアなAI活用を検討している方
- RAG(検索拡張生成)技術を実際に体験したい方
所要時間の目安
-
全体 約60分
- 環境準備 10分程度
- 基本編 12分
- 応用編(RAG機能追加) 30分
- まとめ 5分
必要となるスキル・環境
- プログラミング経験 … 多分不要
- 必要なもの … ブラウザ(Chrome推奨)とGitHubアカウントのみ
- 技術レベル … 初心者向け(コピー&ペーストができればOK)
1.1 このハンズオンの目的
今回は、ブラウザのみを使用して、企業でも安心して使えるローカルLLM×RAGチャットボットを作ります。
「AIに興味はあるけれど、プログラミングは苦手」「開発環境の構築でつまずいてしまう」という方でも大丈夫です。すべての作業はブラウザ上で完結します。そのため、御自身のPCの環境にはまったく影響がありません。
💡**ローカルLLM(大規模言語モデル)**とは、ChatGPTのようなAIを自社環境内で動かす技術です。データが外部に送信されないため、セキュリティ面で優れています。
⚠️今回はGitHub Codespaces(クラウド)上に環境を作成しているため、そういうわけには行きません。ただ、同様の環境を作成を行えば、この目標は達成可能です。
1.2 今日のゴール
60分後には、以下の2つのAIチャットボットが完成を目指します。
| 作成するもの | 特徴 | 活用例 |
|---|---|---|
| 基本チャットボット | 一般的な質問に答えるAI | 社内ヘルプデスク、簡単なQ&A |
| RAG搭載チャットボット | 特定文書の内容について答える専門AI | マニュアル検索、規定確認、技術サポート |
1.3 システム全体像
アーキテクチャ図
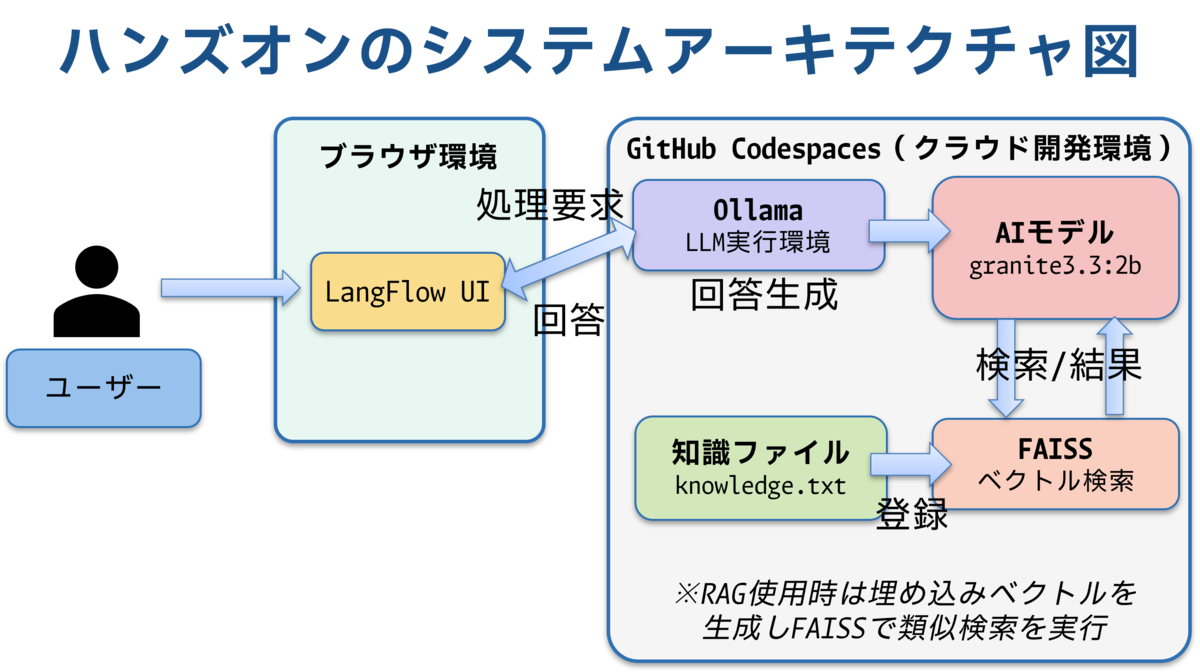
1.4 なぜローカルLLMとRAGなのか
ローカルLLMのメリット
| 観点 | メリット | 具体例 |
|---|---|---|
| セキュリティ | データが外部に送信されない | 機密情報を含む質問も安心 |
| コスト | API利用料金が不要 | 月額費用ゼロで運用可能 |
| 可用性 | ネット接続不要 | オフライン環境でも動作 |
⚠️今回は外部のAPIの利用は行っていないのでコストを気にする必要はありません。
RAG(Retrieval-Augmented Generation = 検索拡張生成)のメリット
| 観点 | メリット | 具体例 |
|---|---|---|
| 最新性 | リアルタイムで情報更新可能 | 最新の社内規定を即座に反映 |
| 専門性 | 組織固有の知識を持たせられる | 自社製品の詳細仕様を学習 |
| 正確性 | 根拠のある回答が可能 | 文書の該当箇所を参照して回答 |
2. 開発環境の準備(約10分)
この章で行うこと
クラウド開発環境の立ち上げとAIツールの自動セットアップ
2.1 環境構築の流れ

2.2 GitHub Codespacesの起動
動作環境であるGitHubのリポジトリへのアクセスし、GitHub Codespaces(以降、Codespaces)環境を起動します。
2.2.1. GitHubリポジトリにアクセス
👉GitHubにログインしていない場合は、先にサインインを行ってください。
2.2.2. 緑色の 【<> Code】 ボタンをクリック
2.2.3. 【Codespaces】 タブを選択

2.2.4. 【Create codespace on main】 をクリック

ここまでの操作で、新しいタブが開き、Setting up your codespaceという画面が表示された後、VSCodeライクな画面が表示されます。

2.3 自動セットアップの待機
環境構築の確認
Codespacesが起動すると、ターミナル(画面下部の領域)で自動的にツールがインストールされます。
⚠️初回起動時は8-10分程度かかります。
インストール処理の様子

インストールされるツール一覧
| ツール名 | 役割 | サイズ | インストール時間 |
|---|---|---|---|
| LangFlow | AIアプリをノーコードで作成 | 約200MB | 2-3分 |
| Ollama | ローカルAIモデルの実行環境 | 約100MB | 1分 |
| granite3.3:2b | 対話用の軽量AIモデル | 約1.5GB | 3-5分 |
| nomic-embed-text | 文書検索用AIモデル | 約250MB | 1-2分 |
インストール完了の状態
👉目安としては、コンソール部分の【ポート】タブが途中③や④の表記がされていれば大丈夫のようです。
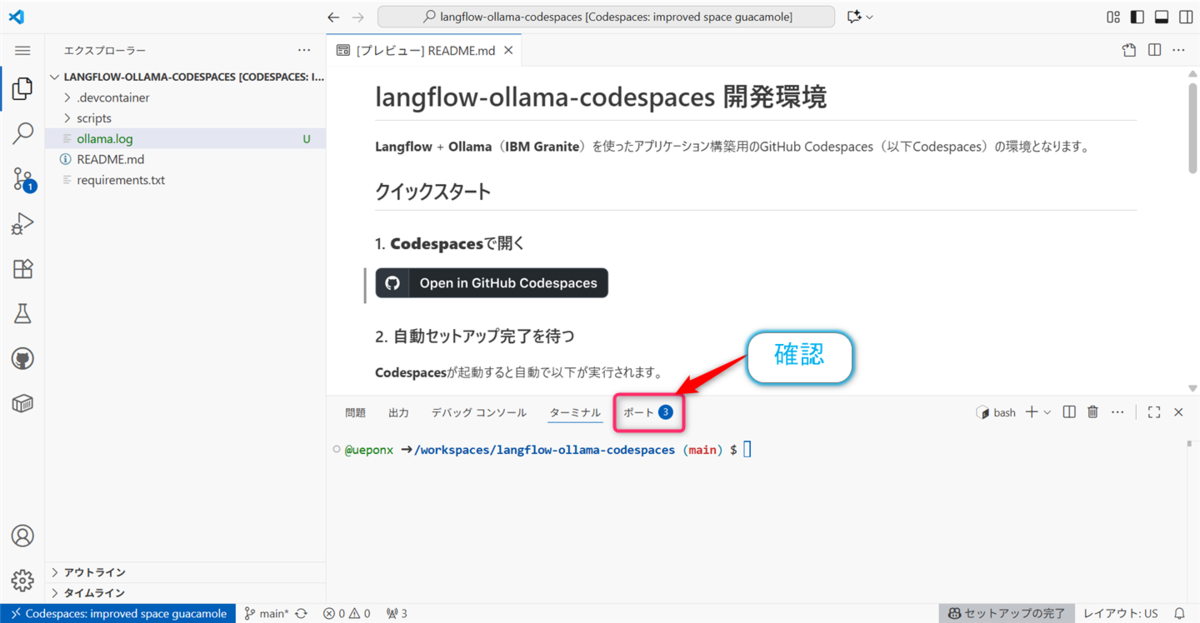
2.4 LangFlowの起動
ターミナルの動作が一段落つくとにプロンプト表示がされるので($ マークや codespace という文字)、以下のコマンドを入力します。
⚠️上記のステップが完全に終了していないとエラーが発生しますので、必ず完了を確認してください。
bash scripts/start-langflow.sh

出力例の抜粋

確認ポイント
- エラーメッセージが表示されていない
- 「LangFlow is running」というメッセージが表示されている
- ポート番号7860が表示されている
2.5 LangFlowへのアクセス
ブラウザでLangFlowの開発画面を開きます。

上記のOpen LangFlowのURLを【Ctrl+クリック】するとブラウザの新規タブが開き、以下のような画面が表示されます。
LangFlowの起動画面

その後、【Create first flow】ボタンをクリックし、

表示されたダイアログの【Blank Flow】ボタンをクリックするとLangFlowの編集画面が表示されます。

これで開発環境の構築が完了しました。早速アプリを作成していきましょう。
3. 基本編:シンプルなAIチャットボット(約12分)
この章で行うこと
LangFlowの基本操作とAIチャットボットの構成要素を理解する
3.1 基本チャットボットの構成

3.2 新規プロジェクトの作成
プロジェクトで開発を開始します。
もし、編集画面担っていなければ以下の作業を行ってフロー作成画面に遷移してください。
- LangFlowの画面中央にある 【+ New Project】 をクリック
- テンプレート一覧から 【Blank Flow】 を選択
3.3 必要なComponents(部品)の配置
4つのComponentsを追加
以下のComponentsを左側メニューから探して、編集画面にドラッグ&ドロップします。
💡Componentsが見つからない場合は、検索ボックスにComponents名を入力すると素早く見つかります。
| 部品名 | カテゴリ | 役割 | 配置順 |
|---|---|---|---|
| Chat Input | Inputs | ユーザーからの質問を受け取る | 1番目(左端) |
| Prompt Template | Prompts | AIへのプロンプトを作成する | 2番目 |
| Ollama | Models | AIによる回答を生成する | 3番目 |
| Chat Output | Outputs | AIの回答を表示する | 4番目(右端) |

3.4 部品の設定
3.4.1 Prompt Template Componentsの設定
Prompt Template Componentsをクリック
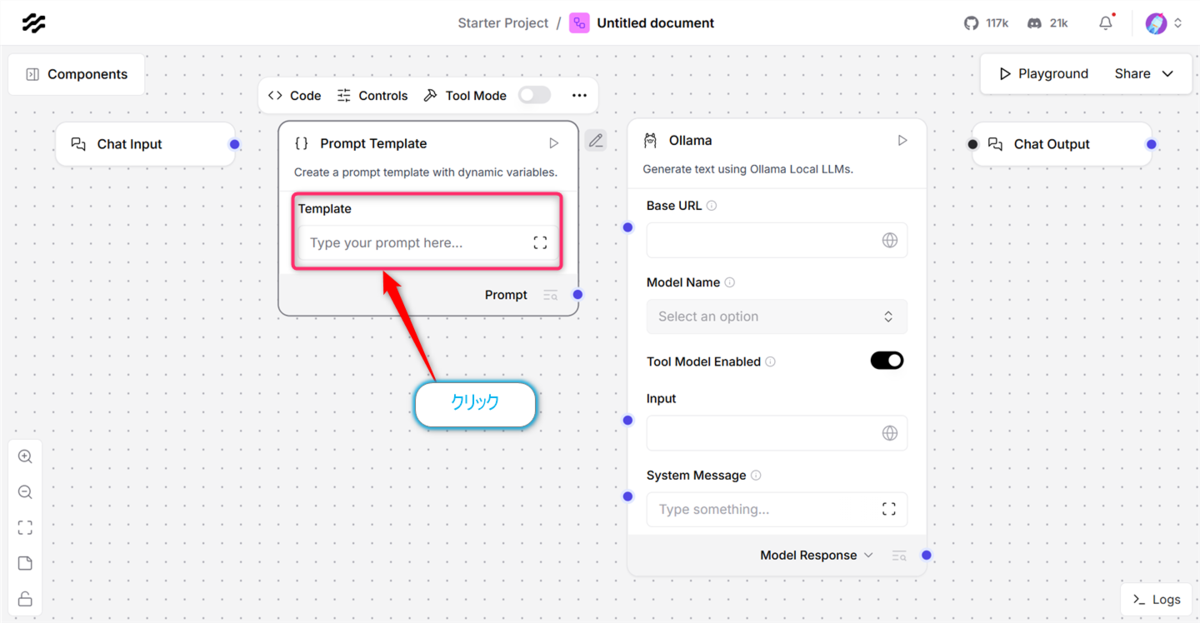
右側パネルの 【Template】 をクリックすると【Edit Prompt】ダイアログが表示されるのでここに以下の文章を入力します。この文章がAIへの指示(プロンプト)となります。入力後は【Check&Save】をクリックします。
👉プロンプトとはユーザーからの入力に対してAIがどのように応答するかを定義する指示文のことです。プロンプトはAIの出力に大きな影響を与えるため、明確かつ具体的に記述することが重要です。
あなたは親切で優秀なアシスタントです。
ユーザーからの質問に対して、簡潔に日本語で回答してください。
質問:{input_value}

確認ポイント
-
{input_value}の波括弧が正しく入力されている(これは変数として機能するので必ず確認してください。) - プロンプトには「日本語で」という指示が含まれている
入力後は以下のようになります。

3.4.2 Ollama Componentsの設定
OllamaComponentsをクリック

Componentsの設定を以下の様にします。
⚠️LangFlowの不具合か、【Base URL】を設定しても、【Model Name】の選択がうまくいかないことがあるようです。その場合は、別部分のUIを操作しているとうまく設定できるようになります。
-
【Base URL】 …
http://localhost:11434 -
【Model Name】 …
granite3.3:2bを選択 -
【Tool Model Enabled】 …
OFF

確認ポイント
- ドロップダウンリストにモデル名が表示され、granite3.3:2bが選択されている
3.5 部品の接続
データフローの作成を行います。以下のComponentsの端子を接続していきます(出力ポート→入力ポートへドラッグ)。
- [ ] 【Chat Input】 → 【Prompt Template(input_value)】
- [ ] 【Prompt Template】 → 【Ollama(Input)】
- [ ] 【Ollama】 → 【Chat Output】

完成したフロー(これをimportしても動作します)
3.6 動作テスト
チャットボットとの会話を行います。
画面右上の 【▶ Playground】 をクリック
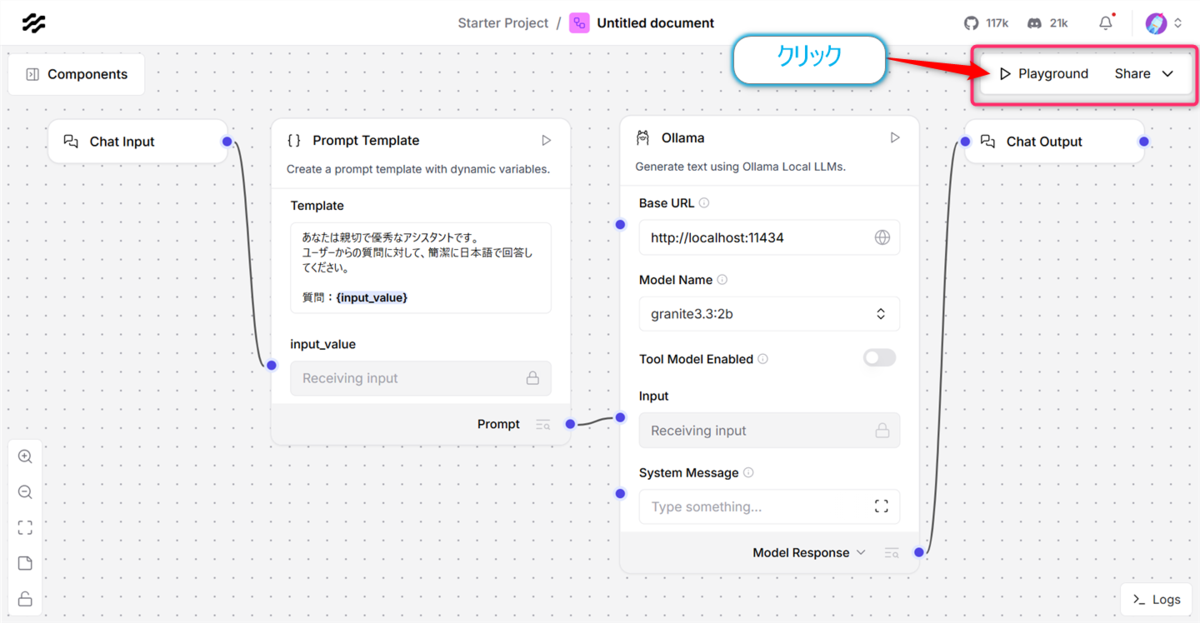
テキスト入力欄に質問を入力して【Enterキー】を押下する。
⚠️初回の生成はモデルをメモリにロードするため圧倒的に時間がかかります。タイムアウトすることもありますが、2回目以降は高速になります。
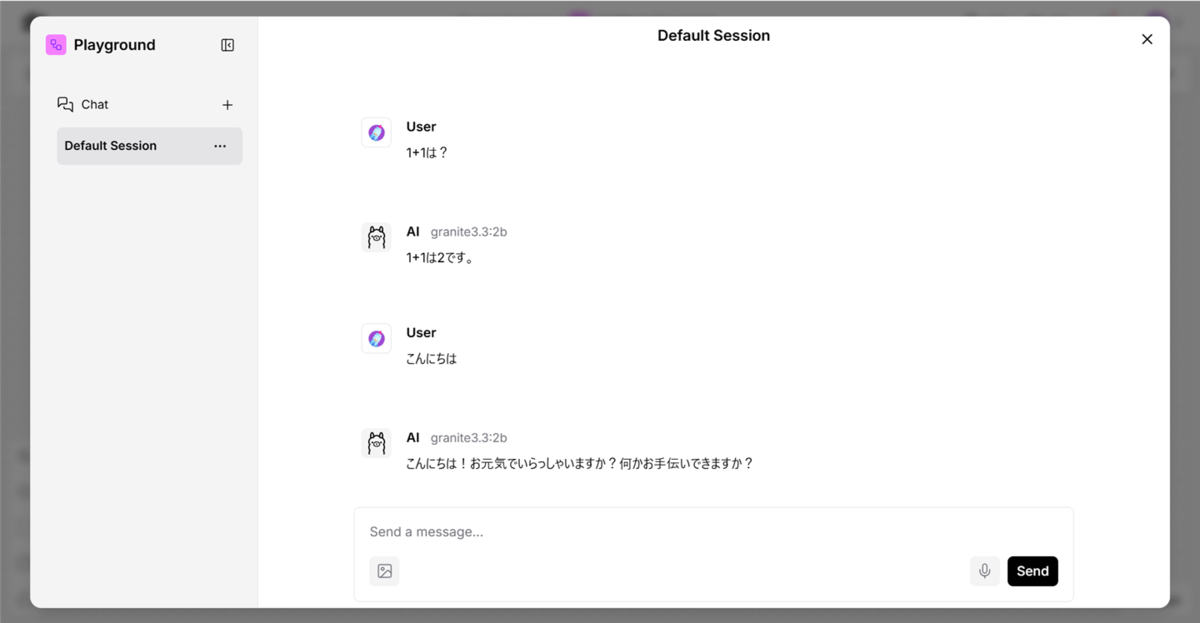
テスト質問と期待される回答
| 質問 | 期待される回答 |
|---|---|
| 日本の首都は? | 東京です |
| 1+1は? | 2です |
| こんにちは | こんにちは!何かお手伝いできることはありますか? |
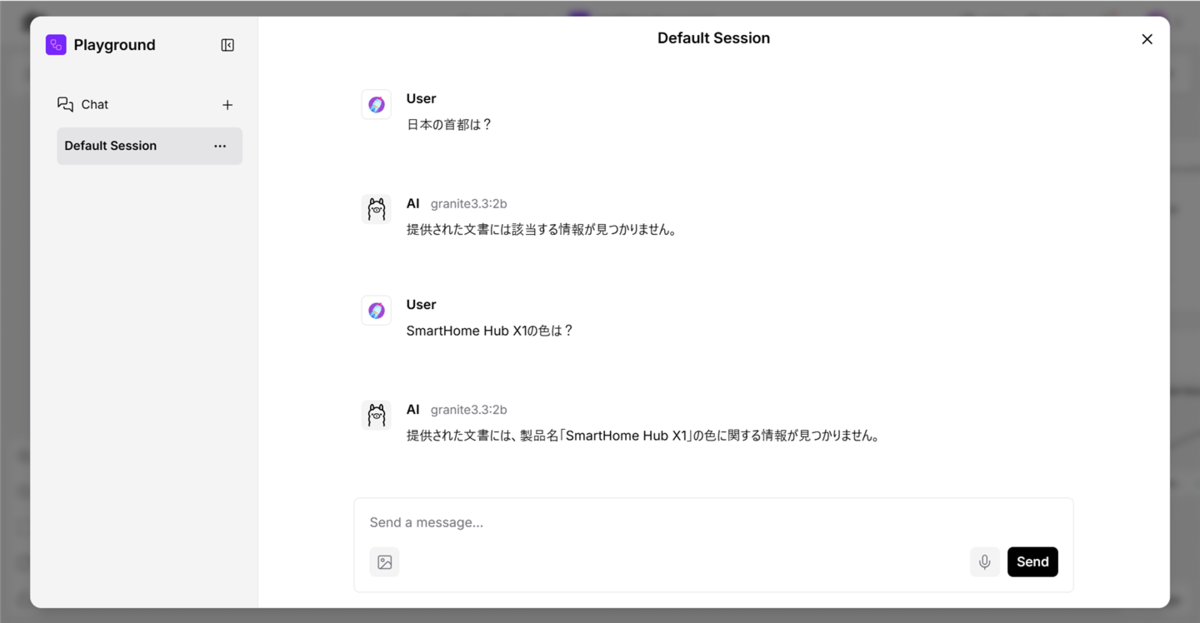
これで基本チャットボットの完成となります。このチャットボットではLLMが一般的な知識を使用して質問への回答を行います。逆にいえば、学習に用いられないような特定の文書に基づいた回答ができないという弱点があります。

4. 応用編:専門知識を持つAIチャットボット(RAG体験)(約30分)
この章で行うこと
チャットボットにRAG技術を追加して、特定の文書に基づいた回答するAIシステムに改良する
4.1 RAGシステムの全体像
RAGの大まかなフローは以下の様になっています。

4.2 RAGとは
👉RAG(Retrieval-Augmented Generation = 検索拡張生成) は、AIが回答する際に外部の知識データベースから関連情報を検索して参照する技術です。

4.3 知識ファイルの準備
RAGの知識の元となるテキストファイルの準備
以下の内容のknowledge.txtを事前にPCに作成する。
製品名:SmartHome Hub X1
カテゴリ:スマートホーム制御システム
基本仕様:
- サイズ:幅120mm × 奥行120mm × 高さ35mm
- 重量:280g
- 電源:USB-C(5V/2A)またはACアダプター(100-240V)
- 通信方式:Wi-Fi(2.4GHz/5GHz)、Bluetooth 5.0、Zigbee 3.0
- 対応音声アシスタント:Amazon Alexa、Google Assistant、Apple Siri
主な機能:
- 最大50台のスマートデバイスを同時制御
- スマートフォンアプリによる遠隔操作
- 音声コマンドによる家電操作
- タイマー機能とスケジュール設定
- 電力使用量モニタリング機能
- 自動化ルール(最大20個まで設定可能)
対応デバイス:
- Philips Hue、TP-Link Kasa、SwitchBotシリーズ
- 赤外線リモコン対応家電(エアコン、テレビ、照明など)
- Matter規格対応デバイス
保証とサポート:
- 保証期間:購入日から2年間
- テクニカルサポート:平日9:00-18:00(土日祝日除く)
- ファームウェア更新:自動更新対応(月1回程度)
価格:オープン価格(実売価格 12,800円前後)
4.4 RAG用の部品配置
4.4.1 新規プロジェクトを作成する
LangFlowに戻り【+ New Project】ボタンをクリックし

ダイアログで【+ Blank Flow】ボタンをクリック

4.4.2 9つのComponentsを配置
| Components名 | カテゴリ | 役割 |
|---|---|---|
| File | Data | テキストファイルを読み込む |
| Split Text | Processing | テキストを適切なサイズに分割 |
| Ollama Embeddings | Embedding Models | 文章を検索可能な形式に変換 |
| FAISS | Vector Stores | 変換した文章を保存・検索 |
| Parse | Processing | 検索結果を文字列に変換 |
| Prompt Template | Prompts | AIへの指示と検索結果を組み合わせる |
| Ollama | Models | 最終的な回答を生成 |
| Chat Input | Inputs | ユーザーからの質問を受け取る |
| Chat Output | Outputs | AIの回答を表示 |
推奨レイアウト
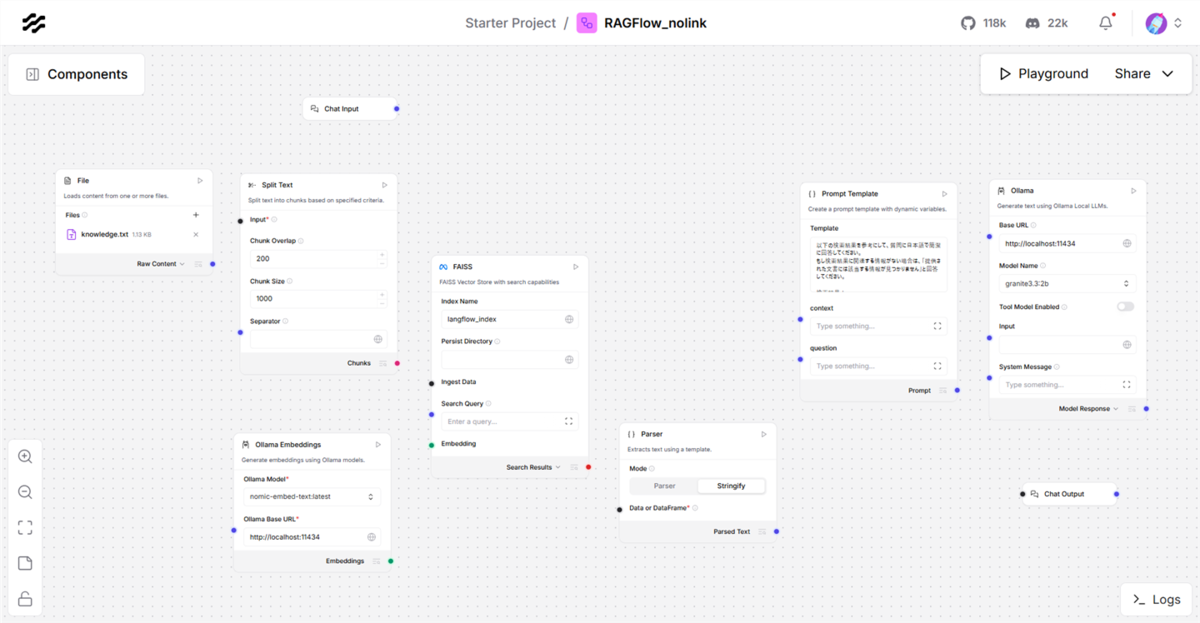
4.5 部品の詳細設定
以降は配置した各Componentsの設定を行ないます。
4.5.1. File Componentsの設定
File Componentsの【Select files】ボタンをクリックして、
【Click or drag files here】のエリアで
事前に準備したknowledge.txtをアップロード。

4.5.2. Ollama Embeddings Componentsの設定
Ollama Embeddings Componentsのフィールドを以下のように設定
- Ollama Model …
nomic-embed-text:latest - Ollama Base URL …
http://localhost:11434

4.5.3. Parse Componentsの設定
Parse Componentsのフィールドを以下のように設定
- Mode …
Stringify

⚠️実はこれは手抜きの設定です🙇
本来であれば取得したデータをJSONから抜き出す必要があります。正しい方法はParse Componentsの前にData Operations Componentsを挿入し、【Select Keys】値にJSONデータで取り出すKey名を指定することになります。今回はtextを設定します。

修正行ったフロー(完成したものを一部修正したものでimportしても動作します)
4.5.4. Prompt Template Componentsの設定
Prompt Template Componentsのフィールドを以下のように設定

以下の検索結果を参考にして、質問に日本語で簡潔に回答してください。
もし検索結果に関連する情報がない場合は、「提供された文書には該当する情報が見つかりません」と回答してください。
検索結果:
{context}
質問:{question}
回答:

4.5.5. Ollama Componentsの設定
Ollama Componentsのフィールドを以下のように設定
- Base URL …
http://localhost:11434 - Tool Model Enabled …
OFF - Model Name …
granite3.3:2b

4.6 Componentsの接続
設定したComponentsの端子を接続していきます。
Components間の接続を行う
以下の順にComponents間の接続を行ってください。

接続チェックリスト
- [ ] File → Split Text (Data)
- [ ] Split Text → FAISS (Ingest Data)
- [ ] Ollama Embeddings → FAISS (Embedding Model)
- [ ] Chat Input → FAISS (Search Query)
- [ ] FAISS → Parse (Data or DataFrame)
- [ ] Parse → Prompt Template (context)
- [ ] Chat Input → Prompt Template (question)
- [ ] Prompt Template → Ollama (Input)
- [ ] Ollama → Chat Output
接続が完了すると以下の状態になります。

完成したフロー(これをimportしても動作します)
4.7 動作確認とテスト
RAG機能付きチャットボットのテスト
製品に関する質問(正解があるもの)
| 質問 | 回答例 |
|---|---|
| SmartHome Hub X1の重さは? | 280g |
| 保証期間はどのくらいですか? | 2年間 |
| 対応している音声アシスタントは? | Amazon Alexa、Google Assistant、Apple Siri |
| 価格はいくらですか? | 実売価格12,800円前後 |


知識外の質問(答えられないもの)
| 質問 | 回答例 |
|---|---|
| 日本の首都は? | 提供された文書には該当する情報が見つかりません |
| SmartHome Hub X1の色は? | 文書に記載がないため答えられません |
4.8 RAGの仕組み解説
簡単にRAGで使用しているEmbedding(埋め込み)の概念とVector Storeについて書いておきます。
詳しくはネット上の資料をご参照ください。
Embedding(埋め込み)の概念
💡Embeddingとは、テキストを数値ベクトルに変換する技術です。これにより、意味的に類似したテキスト同士を数学的に比較できるようになります。
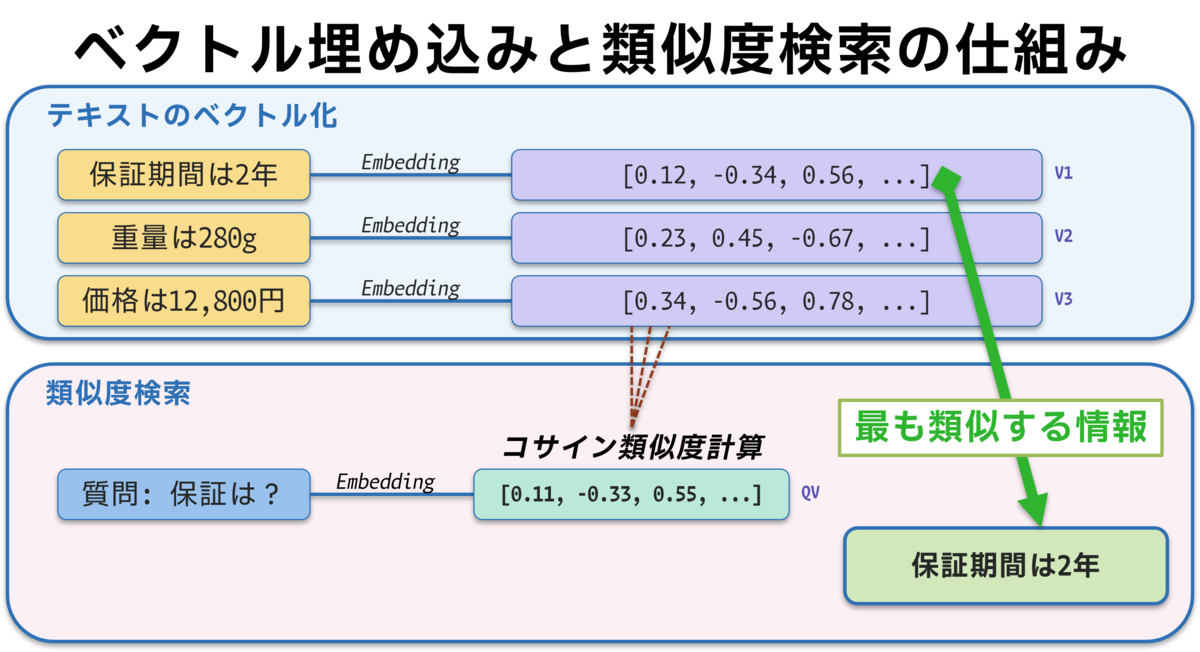
Vector Store(FAISS)とは
💡Vector Storeは、Embeddingで変換されたベクトルを効率的に保存・検索するためのデータベースです。今回使用しているFAISSはFacebookが開発した高性能なベクトル検索ライブラリで、大規模なデータセットでも高速に類似度検索が可能です。
以下のような特徴があります。
- 高速な類似度検索を実現
- 数千〜数百万の文書から瞬時に関連情報を発見
- 意味的に近い内容を数値的に判断
5. おわりに(約5分)
本日のハンズオンで、以下を作成できました。
- 環境構築なしでAI開発環境を準備
- プログラミングなしでAIチャットボットを構築
- RAG技術で専門知識を持つAIを実現
- セキュアな環境でのAI活用を体験
この技術を拡張して、組織の知識資産を活かした独自のAIシステムを構築できます。ぜひ実務で活用してみてください!
5.1 コマンドリファレンス
開発環境の起動後はコンソールで以下のコマンドを実行することができます。
# Ollamaの動作確認
bash scripts/test-ollama.sh
# LangFlowの再起動
bash scripts/start-langflow.sh
# インストール済みモデルの確認
ollama list
# 新しいモデルの追加(例:llama3)
ollama pull llama3
5.2 トラブルシューティング
| カテゴリ | 問題 | 解決方法 |
|---|---|---|
| 起動関連 | LangFlowが起動しない |
bash scripts/start-langflow.shで再起動 |
| モデル関連 | Ollamaモデルが選択できない | Tool Model EnabledをOFFに設定 |
| 接続関連 | 部品が接続できない | ポート名を確認(大文字小文字に注意) |
| 日本語関連 | 文字化けする | ファイルのエンコーディングをUTF-8に統一 |
| RAG関連 | 検索精度が低い | チャンクサイズを調整(デフォルト1000→500文字) |
| パフォーマンス | 応答が遅い | より軽量なモデルを試す |
5.3 参考リソース
公式ドキュメント: