はじめに
Bedrockのご紹介
Amazon Bedrockは、単一のAPIを介して様々なAI企業からの高性能な基盤モデル (FM) を選択できるフルマネージドサービスです。
セキュリティ、プライバシー、責任あるAIを備えた生成 AI アプリケーションを構築するために必要な幅広い機能を提供するサービスです。 (AWS公式から引用)

現在も、世界中のリージョンでの機能拡充が進められており、
今回は、2024/08/09に東京リージョンでClaude 3.5 Sonnetが利用できるようになったことを記念して、Bedrockを活用したシステムを作ってみる。
なにを作成する?
弊社ではAWSリソースを作成する際にIaC(主にTerraform)を用いて、
リソースをデプロイすることが推奨されている。
そこで、IaCの品質を向上させるための改善提案を、
先述したBedrockから利用できるLLM(大規模言語モデル)である、
Claudeから賜りたいと思う。
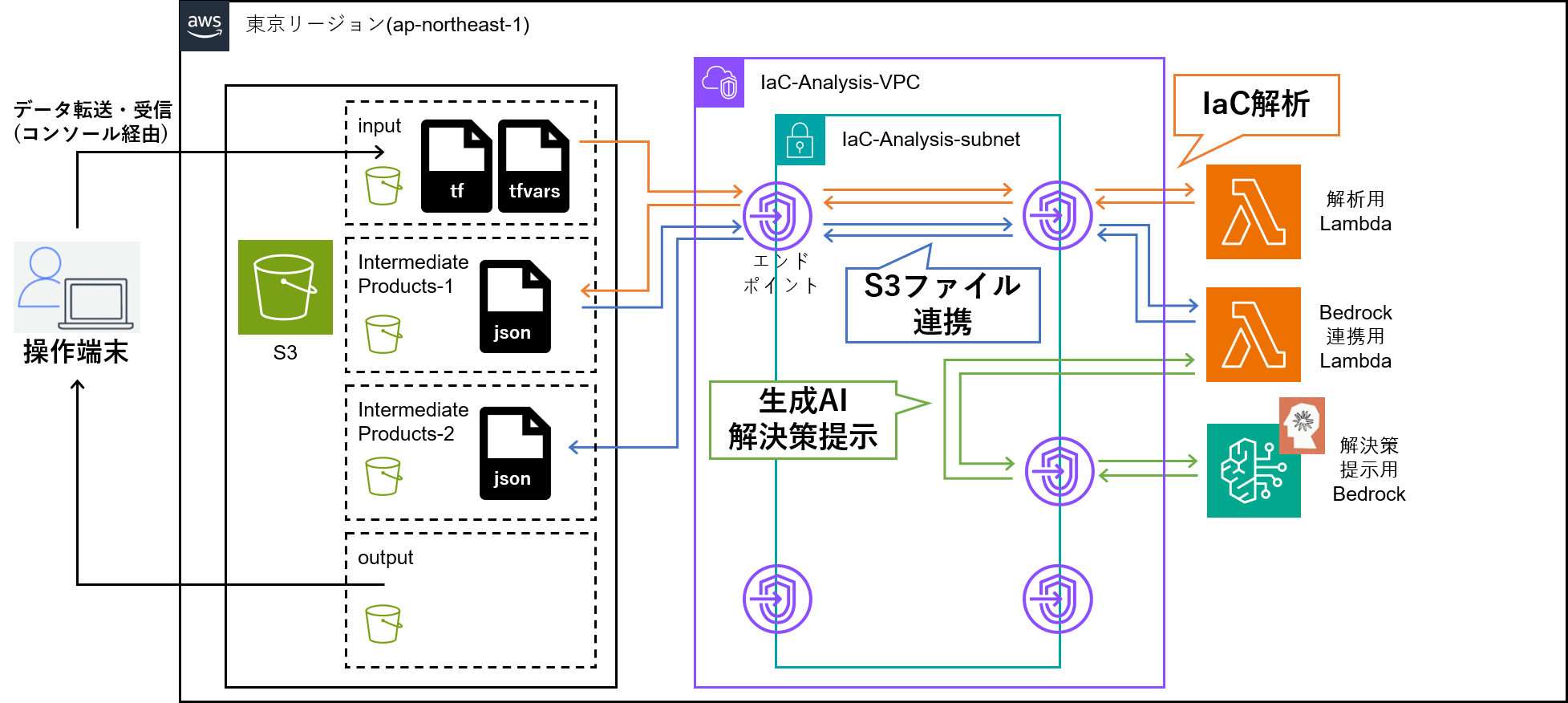
アーキテクチャ図
完成形は以下の通り。
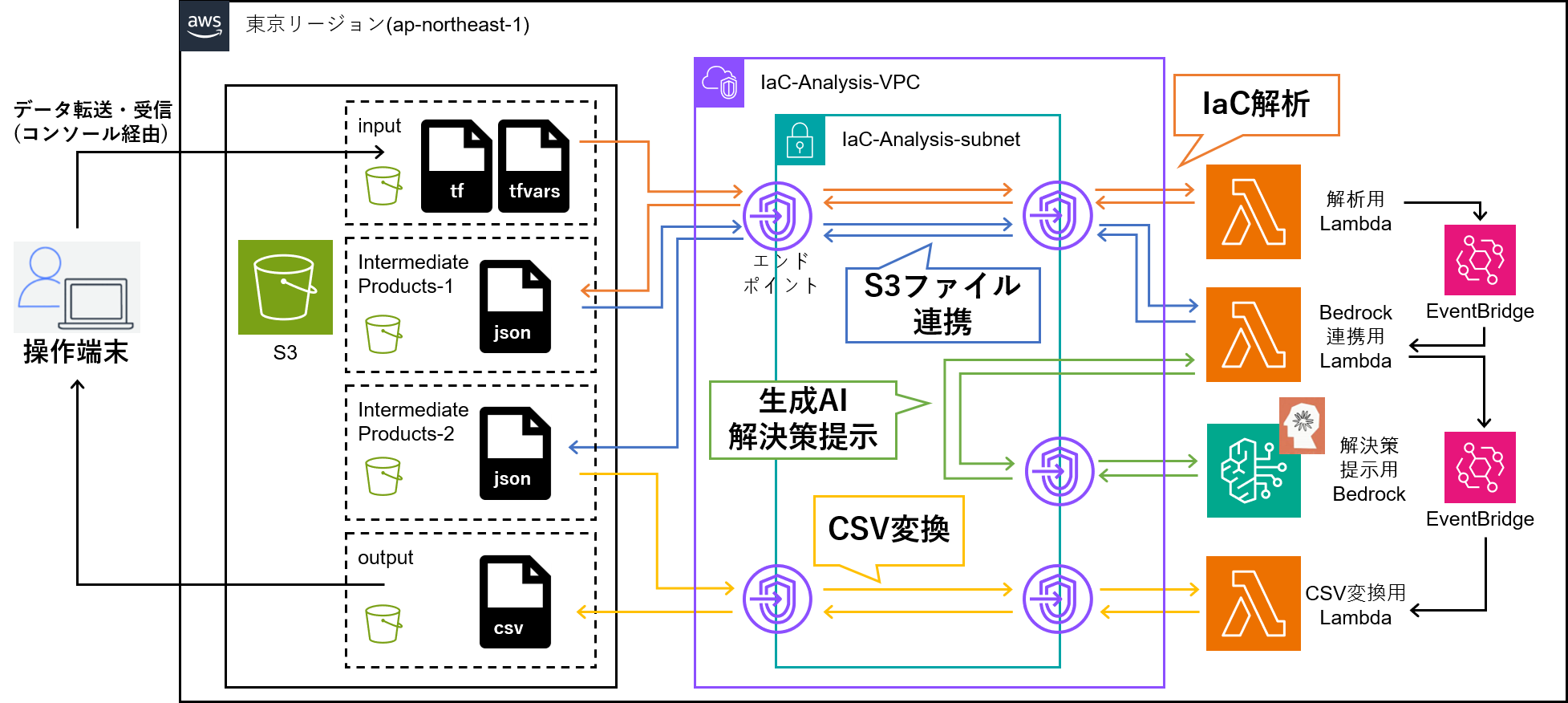
以下のようなSTEPに沿って作成する。
各STEPでの注意事項や、アーキテクチャ図も併せて記載していく。
STEP
1. ネットワーク作成
2. 解析用Lambda関数作成
3. Bedrock連携用Lambda関数作成
4. CSV変換用Lambda関数作成
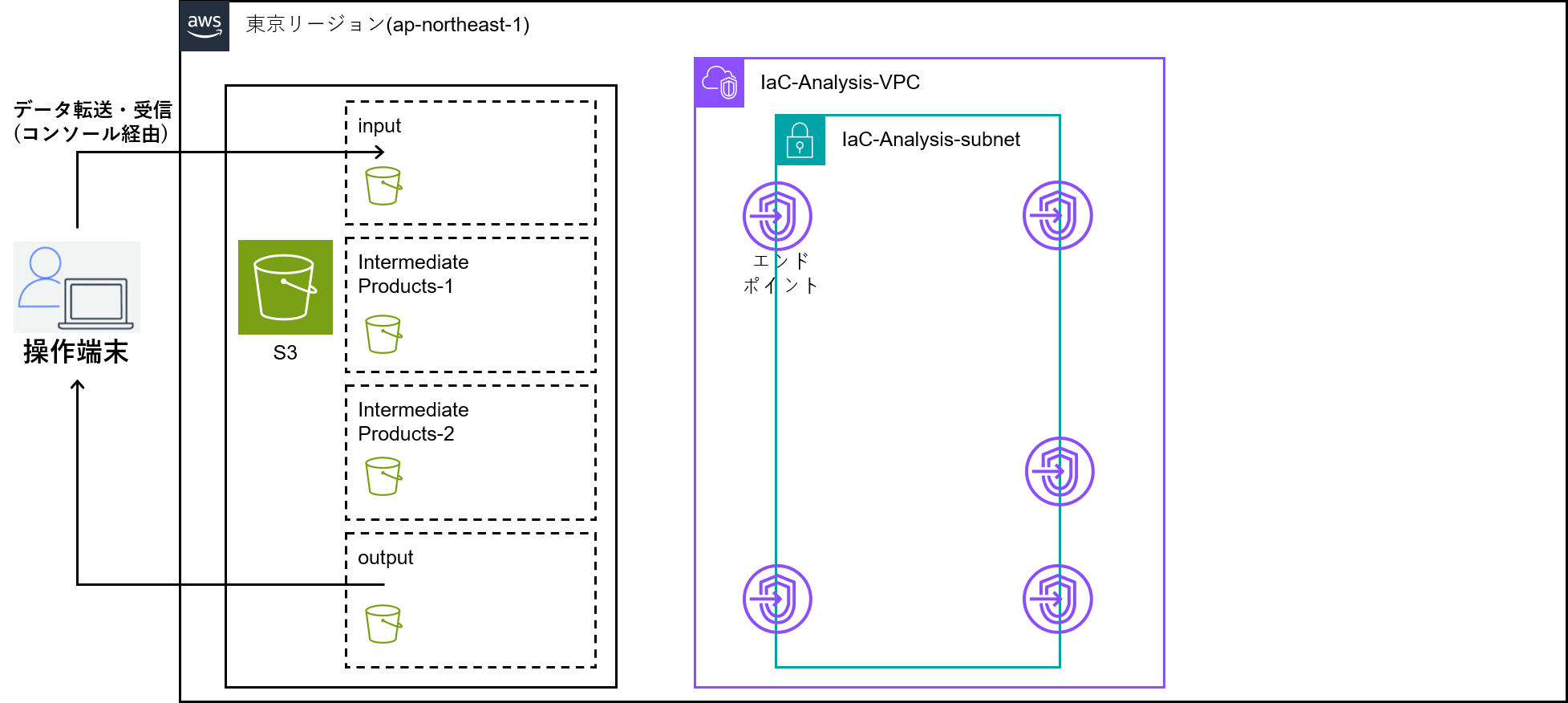
STEP1 - ネットワーク作成
このSTEPで作成するリソースは以下の表の通り。

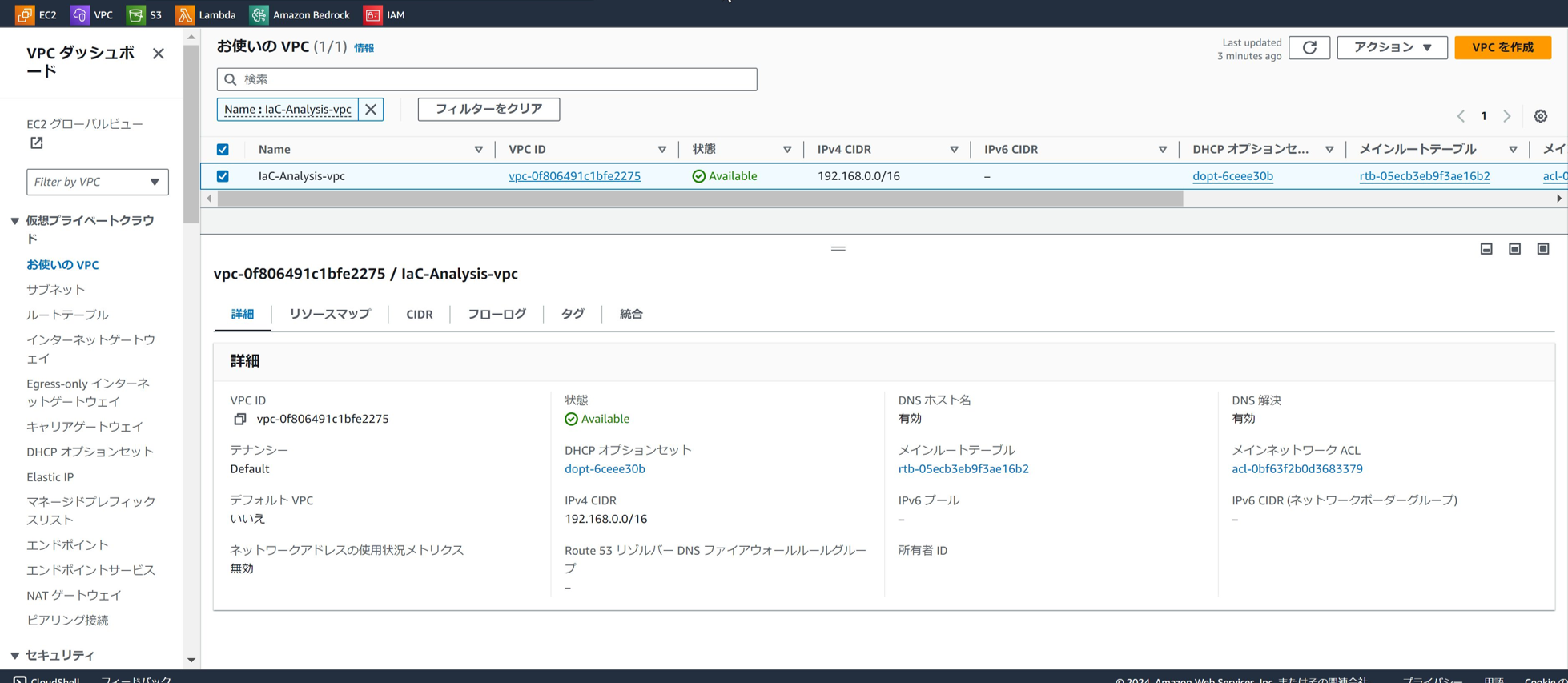
IaC-Analysis-VPC 設定
IaC-Analysis-subnet 設定
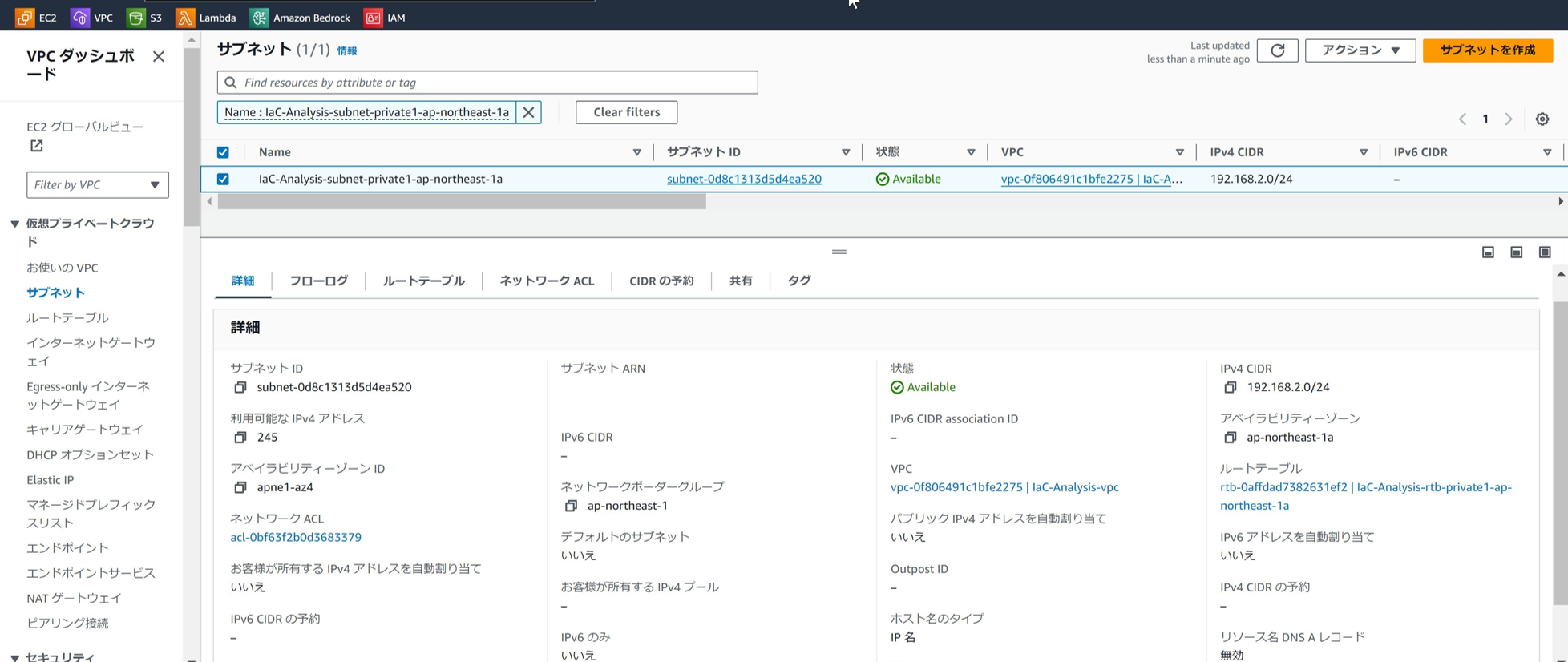
インターネットへの不要な露出はセキュリティリスクに繋がる恐れがあるため、インターネットゲートウェイは利用しない構成にしている。
必要なファイルは都度ダウンロードして、S3に配置する。

ほぼデフォルトの設定でOK。
パブリックアクセスがちゃんとブロックされていることだけ確認。
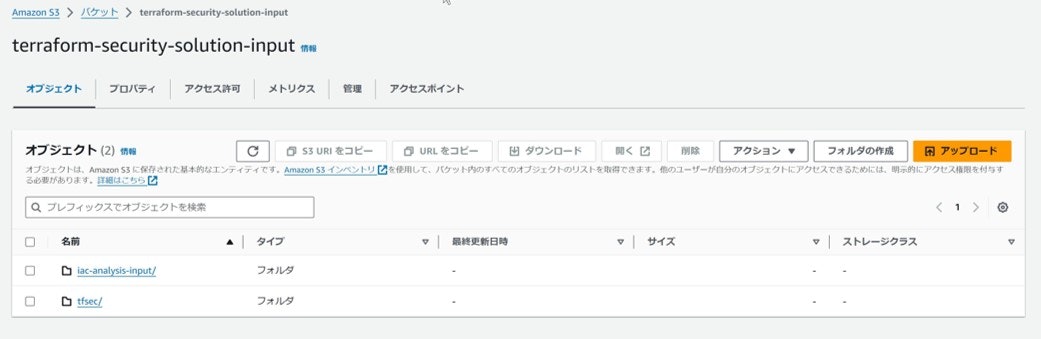
terraform-security-solution-input 設定
intermediate-product-1 設定
intermediate-product-2 設定
terraform-security-solution-output 設定
すべてパブリックアクセスをブロックしたS3バケットだが、
できるならアカウントレベルでパブリックアクセスがブロックされていることが望ましい。

エンドポイント 設定 (サービス名以外は共通設定)
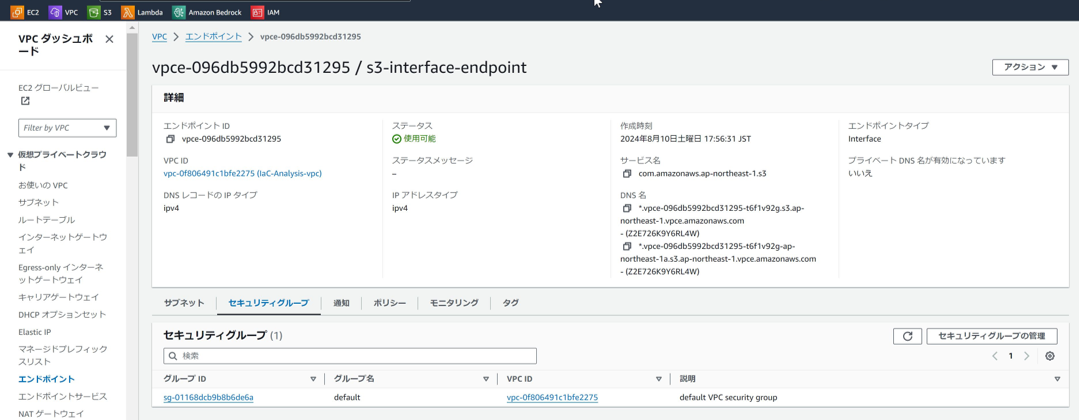
すべてのエンドポイントは同じセキュリティグループに属しており、
同じセキュリティグループ間の通信は許可するように、
インバウンドルールを設定している。
Bedrock用のエンドポイントは4種類あり、念のためすべて作成したが、
課金を抑えたいなら必要/不要は精査するべきポイントではある。
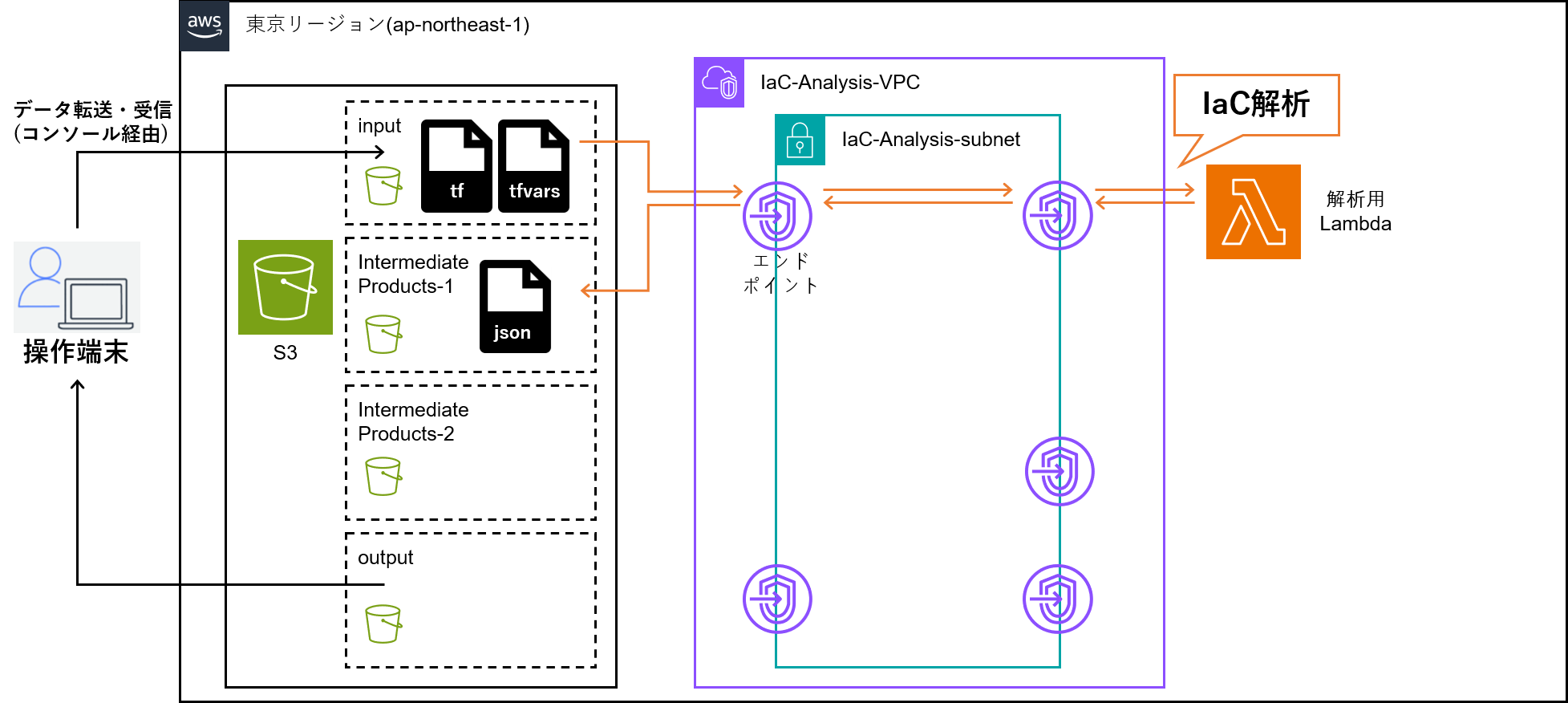
STEP1 完了時点でのアーキテクチャ図は以下の通り。
STEP2 - 解析用Lambda関数作成
STEP2では、S3に格納したtfファイルおよびtfvarsファイルに対して、
Terraformの静的セキュリティスキャンツールであるtfsecを用いて、
コードにセキュリティの脆弱性が無いかをスキャンするLambda関数を作成する。
以下の流れで、詳しい手順を説明していく。
2-1. tfsecのダウンロード & S3格納
2-2. tf, tfvars ファイル格納
2-3. Lambda関数作成 & テスト実行
2-1.tfsecのダウンロード & S3格納
①tfsecの公式GitHubリリースページにアクセスする:
https://github.com/aquasecurity/tfsec/releases
②ページの一番上にある最新のリリースから"Assets" セクションを展開する。
③Linux用のバイナリをダウンロードする。
ファイル名の例:tfsec-linux-amd64
AWS LambdaがAmazon Linux 2 環境で動作するためです。
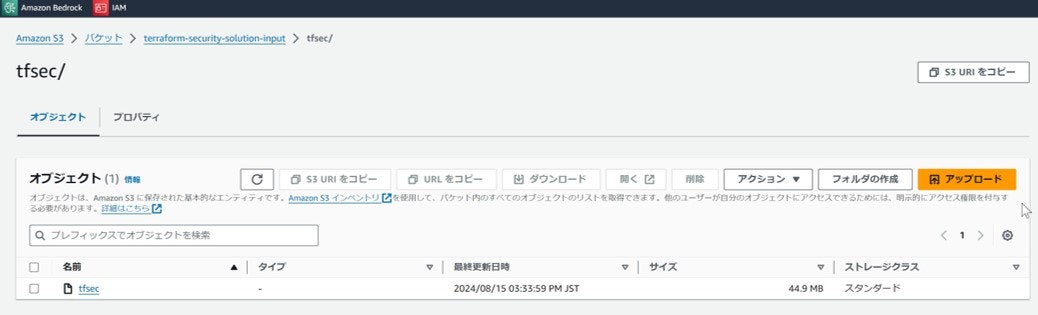
④ダウンロードしたファイルの名前を tfsec に変更する。
⑤tfsec ファイルを[terraform-security-solution-input]バケットの、
[tfsec/]フォルダにアップロードする。
コンソール画面 キャプチャ
2-2. tf, tfvars ファイル格納
解析したいtfファイルおよびtfsecファイルを、
[terraform-security-solution-input]バケットの
[iac-analysis-input/]フォルダに格納する。
コンソール画面 キャプチャ
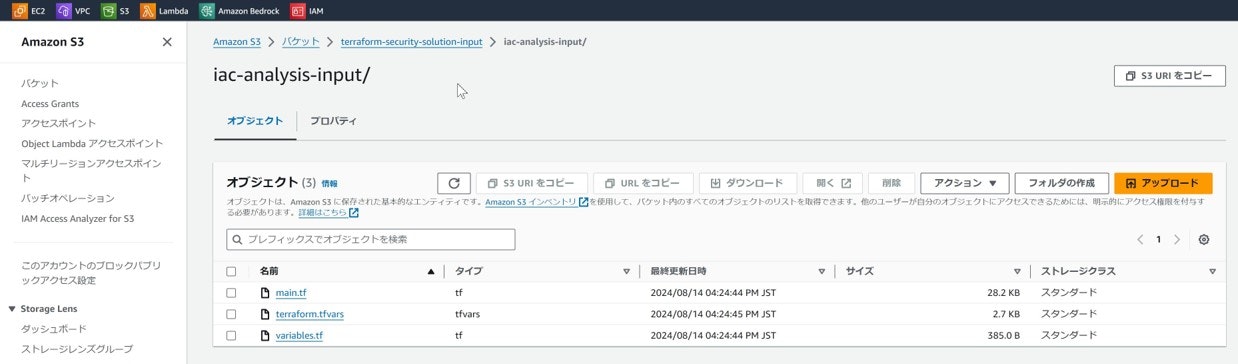
tfファイルのみでも解析可能。
2-3. Lambda関数作成 & テスト実行
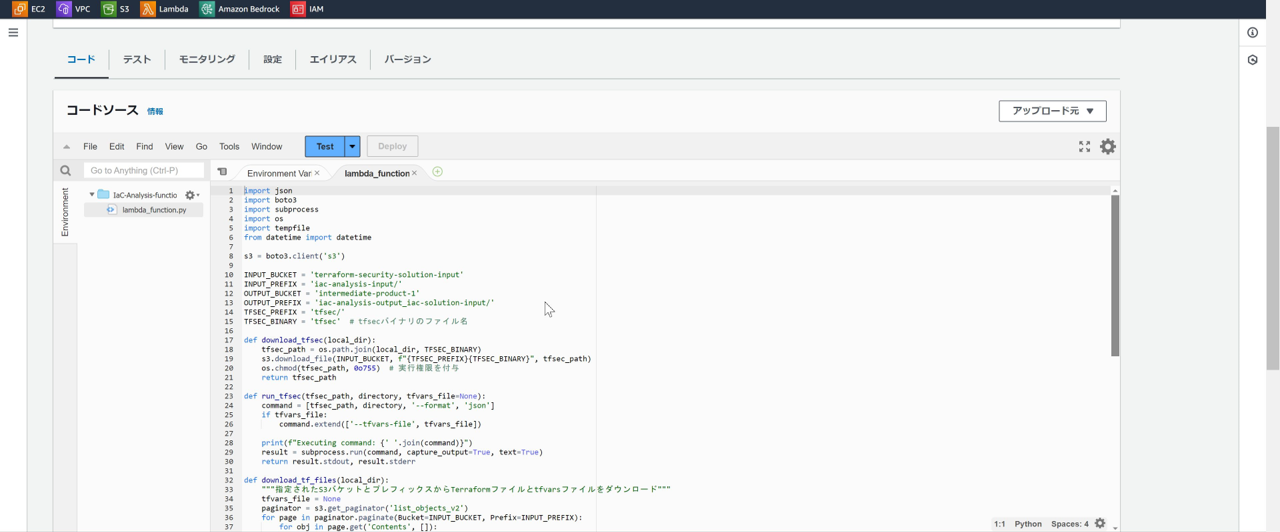
以下のように、Lambda関数を作成し、Pythonコードをデプロイする。
Lambda関数には、インプット用S3バケットの List*,Get*権限と、
アウトプット用S3バケットの List* ,Get*,Put*権限を与えている。

import json
import boto3
import subprocess
import os
import tempfile
from datetime import datetime
s3 = boto3.client('s3')
INPUT_BUCKET = 'terraform-security-solution-input'
INPUT_PREFIX = 'iac-analysis-input/'
OUTPUT_BUCKET = 'intermediate-product-1'
OUTPUT_PREFIX = 'iac-analysis-output_iac-solution-input/'
TFSEC_PREFIX = 'tfsec/'
TFSEC_BINARY = 'tfsec' # tfsecバイナリのファイル名
def download_tfsec(local_dir):
tfsec_path = os.path.join(local_dir, TFSEC_BINARY)
s3.download_file(INPUT_BUCKET, f"{TFSEC_PREFIX}{TFSEC_BINARY}", tfsec_path)
os.chmod(tfsec_path, 0o755) # 実行権限を付与
return tfsec_path
def run_tfsec(tfsec_path, directory, tfvars_file=None):
command = [tfsec_path, directory, '--format', 'json']
if tfvars_file:
command.extend(['--tfvars-file', tfvars_file])
print(f"Executing command: {' '.join(command)}")
result = subprocess.run(command, capture_output=True, text=True)
return result.stdout, result.stderr
def download_tf_files(local_dir):
"""指定されたS3バケットとプレフィックスからTerraformファイルとtfvarsファイルをダウンロード"""
tfvars_file = None
paginator = s3.get_paginator('list_objects_v2')
for page in paginator.paginate(Bucket=INPUT_BUCKET, Prefix=INPUT_PREFIX):
for obj in page.get('Contents', []):
if obj['Key'].endswith(('.tf', '.tfvars')):
local_file_path = os.path.join(local_dir, os.path.basename(obj['Key']))
s3.download_file(INPUT_BUCKET, obj['Key'], local_file_path)
if obj['Key'].endswith('.tfvars'):
tfvars_file = local_file_path
return tfvars_file
def lambda_handler(event, context):
with tempfile.TemporaryDirectory() as tmpdir:
# tfsec バイナリをダウンロード
tfsec_path = download_tfsec(tmpdir)
# S3からTerraformファイルとtfvarsファイルをダウンロード
tfvars_file = download_tf_files(tmpdir)
# tfsecを実行
output, errors = run_tfsec(tfsec_path, tmpdir, tfvars_file)
# 結果をJSONとしてパース
try:
results = json.loads(output)
except json.JSONDecodeError:
results = {"error": "Failed to parse tfsec output"}
# 結果をS3にアップロード
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
result_key = f"{OUTPUT_PREFIX}tfsec_result_{timestamp}.json"
s3.put_object(Bucket=OUTPUT_BUCKET, Key=result_key, Body=json.dumps(results, indent=2))
if errors:
print(f"Errors occurred: {errors}")
return {
'statusCode': 200,
'body': json.dumps({
'message': 'tfsec analysis completed',
'result_location': f"s3://{OUTPUT_BUCKET}/{result_key}"
})
}
コンソール画面 キャプチャ
各関数の機能は以下の通り。
| 関数名 | 機能 |
|---|---|
| download_tfsec | tfsecファイルをS3バケットからダウンロードする |
| run_tfsec | tfsecを実行する。tfvarsファイルがあれば、 コマンドにオプションを追加して解析する |
| download_tf_files | S3バケットからtfファイルとtfvarsファイルを ダウンロードする。 |
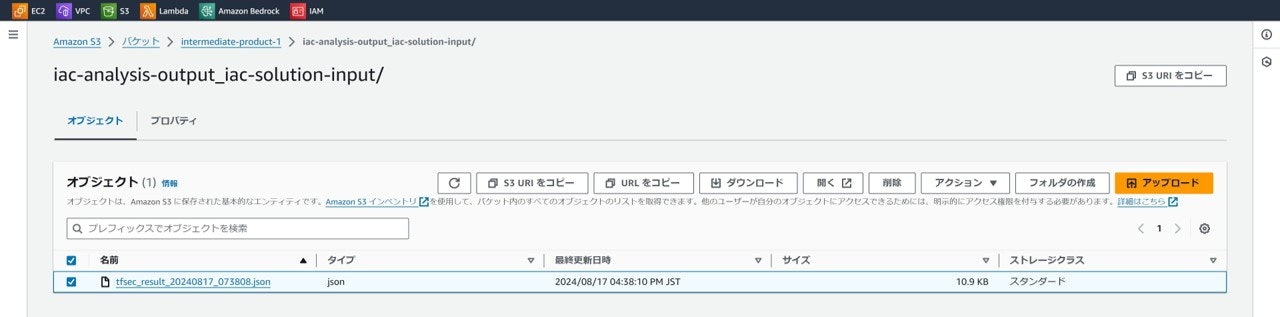
この時点で解析用Lambda関数をテスト実行すると、
tfsecの実行結果jsonファイルがアウトプット用のS3バケットに格納され、
以下のようなファイルがダウンロードできる。
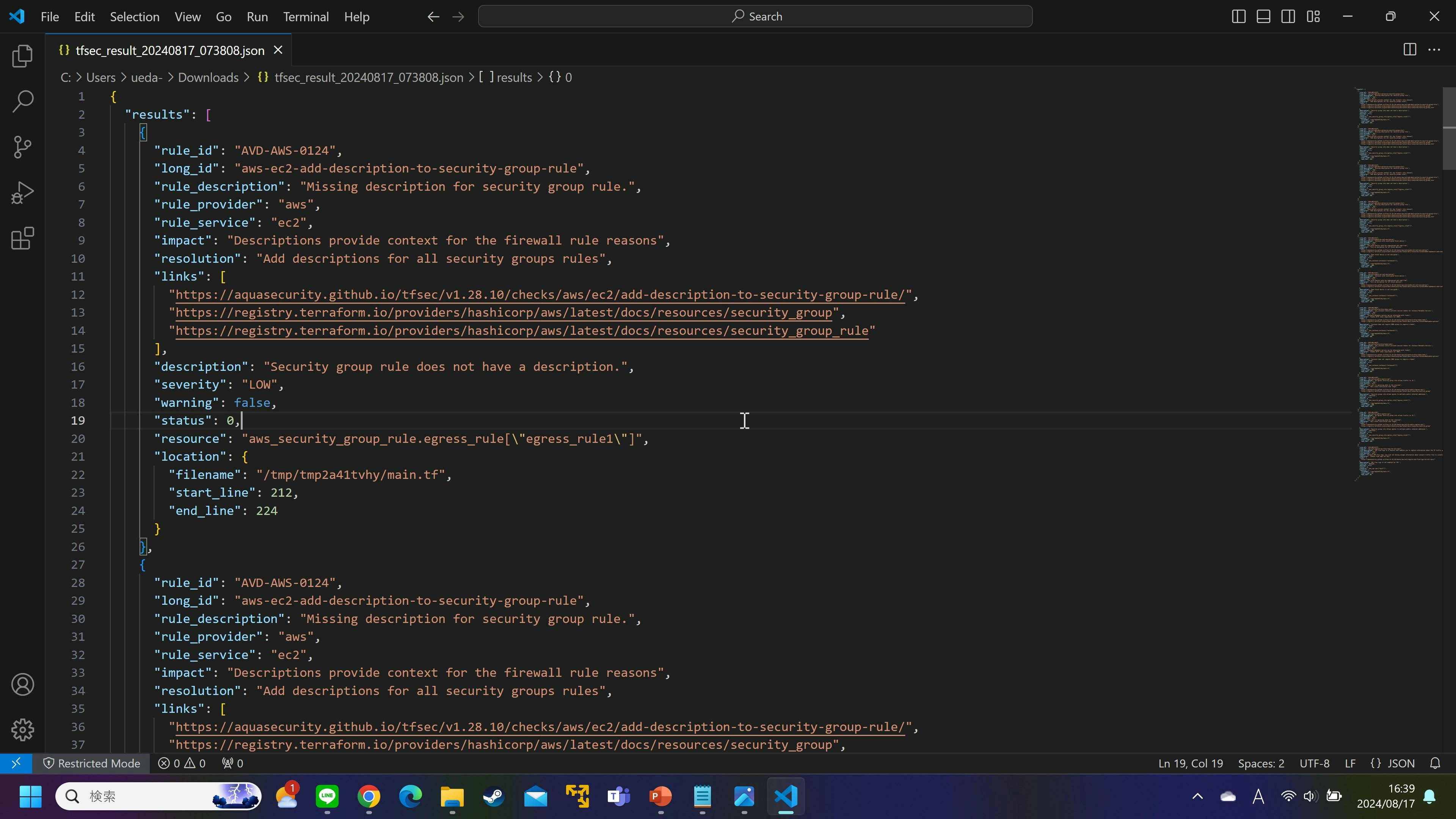
これだけでは読みにくい上に説明も簡素なので、
次のSTEPでは、Bedrockを使ってこのjsonファイルに説明を追加していく。
STEP2 完了時点でのアーキテクチャ図は以下の通り。
STEP3 - Bedrock連携用Lambda関数作成
STEP3では、tfsecの解析結果をBedrockに渡して解決策を提示してもらう。
Claude 3.5 Sonnetがほんの少し前に利用できるようになったことは前述したが、
最新ではなく以前のメジャーバージョンを利用することも、
もちろん可能である。
以下の流れで、詳しい手順を説明していく。
3-1. Bedrockで Claude 3.5 Sonnet を有効化
3-2. Lambda関数作成 & テスト実行
3-1. Bedrockで Claude 3.5 Sonnet を有効化
利用したいモデルはマネジメントコンソールから
事前に有効化しておく必要がある。
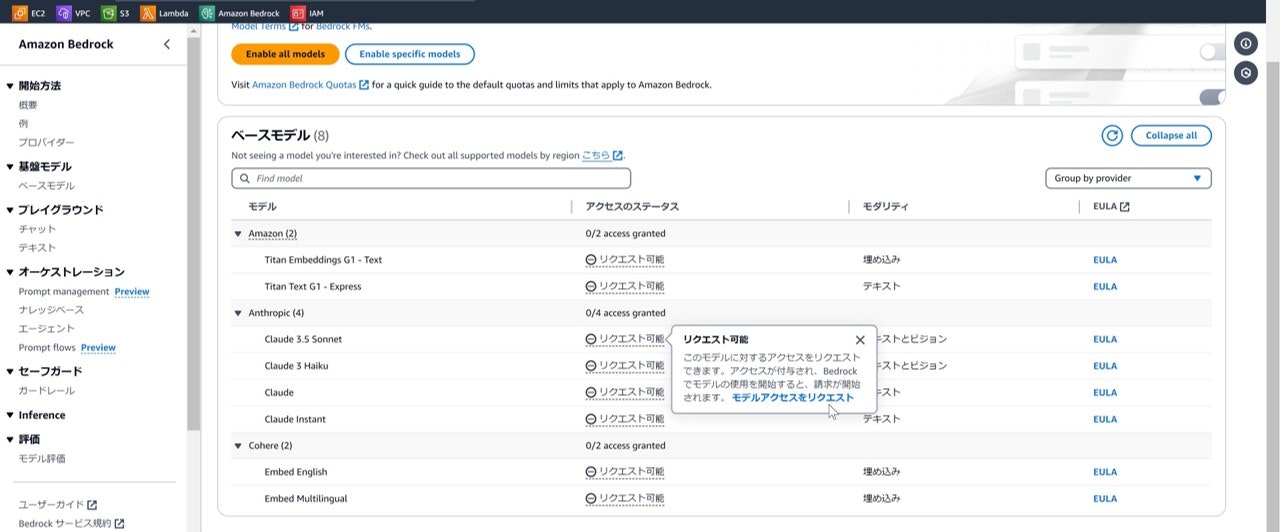
①マネジメントコンソールからBedrockを検索してアクセスする。
②左ツリーの一番下に「Bedrock configurations」があるので、
そこから「モデルアクセス」を選択する。
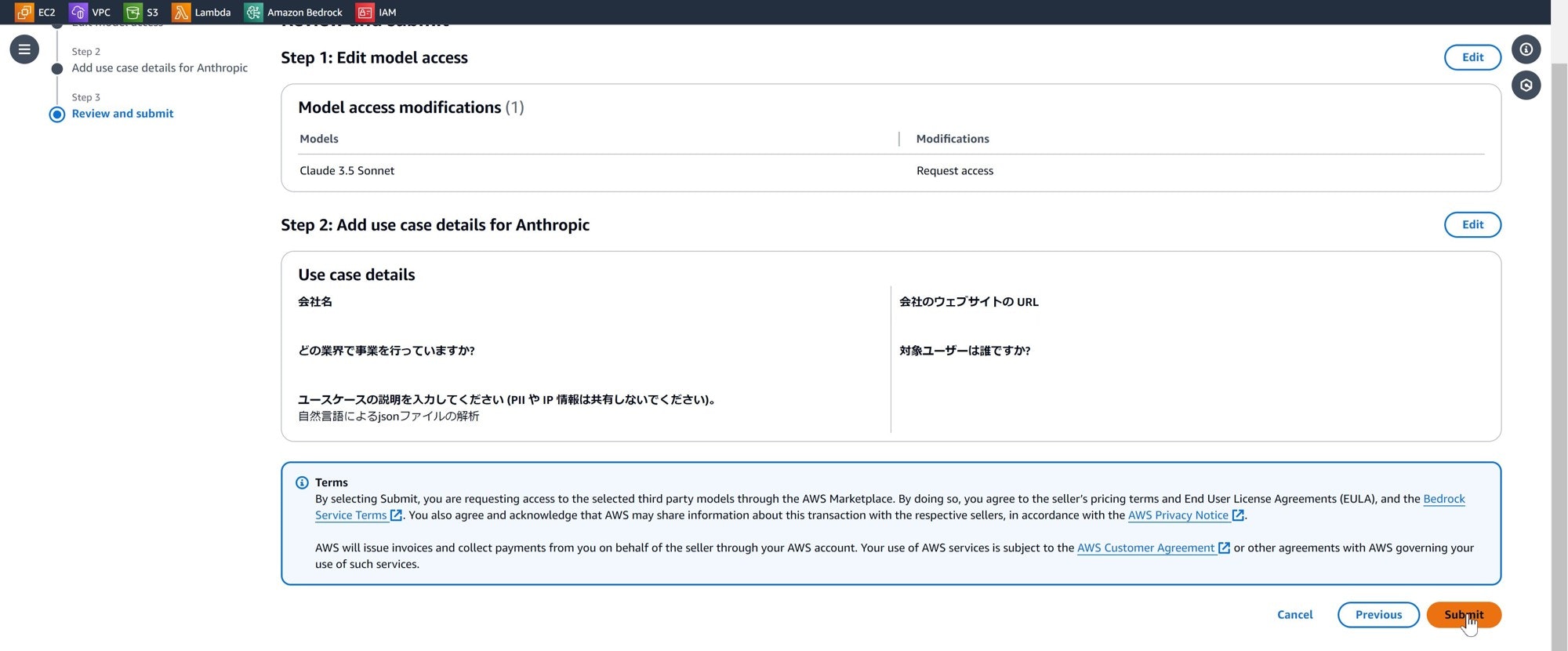
③Anthropicのモデルから「Claude 3.5 Sonnet」をリクエストする。
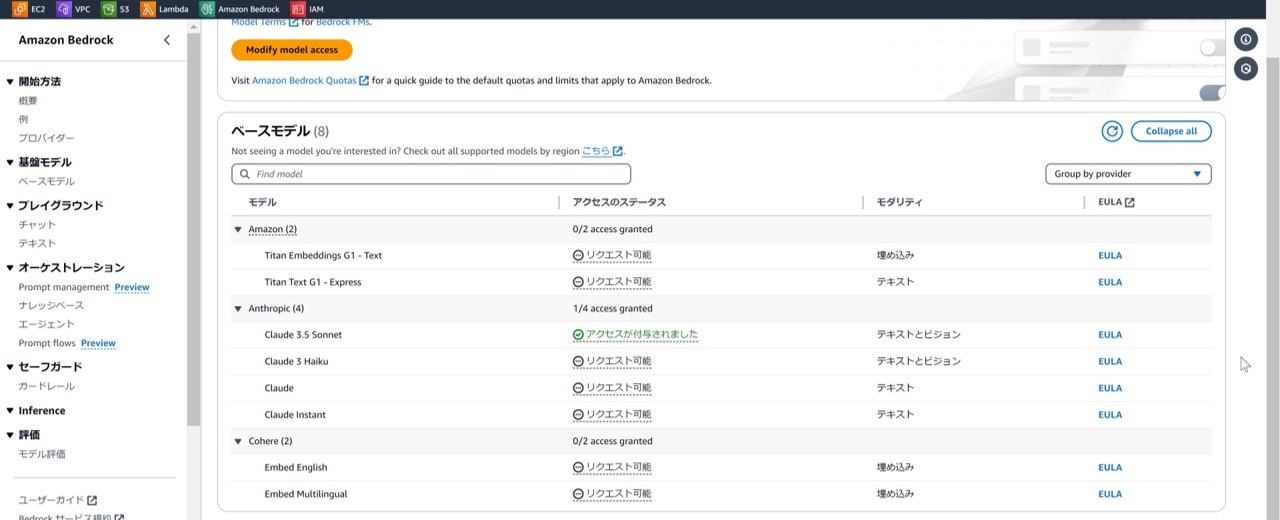
④アクセスステータスが「アクセスが付与されました」になったら利用可能。
コンソール画面 キャプチャ
3-2. Lambda関数作成 & テスト実行
以下のように、Lambda関数を作成し、Pythonコードをデプロイする。
Lambda関数からBedrockを呼び出すのに1-2分ほど時間を要するため、
他の関数よりタイムアウト時間を長くしている。
脆弱性の数が少ないと3分ほどで完了するが、
数が多いとさらに伸びることになる。

import json
import boto3
import os
from datetime import datetime
# 東京リージョンを明示的に指定してクライアントを初期化
s3 = boto3.client('s3', region_name='ap-northeast-1')
bedrock = boto3.client('bedrock-runtime', region_name='ap-northeast-1')
INPUT_BUCKET = 'intermediate-product-1'
INPUT_PREFIX = 'iac-analysis-output_iac-solution-input/'
OUTPUT_BUCKET = 'intermediate-product-2'
OUTPUT_PREFIX = 'iac-solution-output_iac-conversion-input/'
MODEL_ID = 'anthropic.claude-3-5-sonnet-20240620-v1:0' # Claude 3.5 SonnetのモデルID
def list_tfsec_result_files():
response = s3.list_objects_v2(Bucket=INPUT_BUCKET, Prefix=INPUT_PREFIX)
return [item['Key'] for item in response.get('Contents', []) if item['Key'].endswith('.json')]
def read_tfsec_results(file_key):
response = s3.get_object(Bucket=INPUT_BUCKET, Key=file_key)
return json.loads(response['Body'].read().decode('utf-8'))
def generate_prompts(tfsec_results):
prompts = []
for result in tfsec_results.get('results', []):
prompt = f"""あなたはIaCのセキュリティ問題に対する解決策を提案するAWSエキスパートです。
以下のtfsecによって検出されたセキュリティ問題を分析し、解決策を日本語で提案してください:
ルールID: {result.get('rule_id')}
説明: {result.get('description')}
影響: {result.get('impact')}
リソース: {result.get('location', {}).get('filename')}
以下の5点について、それぞれ個別に回答してください:
1. explanation: なぜこれがセキュリティ上の懸念事項なのかの簡単な説明
2. solution-by-terraform: Terraformファイルを修正して問題を解決するためのステップバイステップの手順
3. solution-by-console: デプロイ後にAWSマネジメントコンソールで問題を修正するためのステップバイステップの手順
4. bestpractice: 同様の問題を防ぐためのベストプラクティス
5. reference: この問題に関連するAWSのドキュメントやベストプラクティスガイドへの参照リンク
回答は以下の形式で提供してください:
explanation: [ここに説明を記入]
solution-by-terraform: [ここにTerraformでの解決手順を記入]
solution-by-console: [ここにマネジメントコンソールでの解決手順を記入]
bestpractice: [ここにベストプラクティスを記入]
reference: [ここに参照リンクを記入]
"""
prompts.append((result, prompt))
return prompts
def invoke_bedrock(prompt):
try:
response = bedrock.invoke_model(
modelId=MODEL_ID,
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 2000,
"temperature": 0.7,
"messages": [
{
"role": "user",
"content": prompt
}
]
})
)
response_body = json.loads(response['body'].read().decode())
if 'content' in response_body and len(response_body['content']) > 0:
return response_body['content'][0]['text']
else:
print("Unexpected response structure:", response_body)
return "解決策を生成できませんでした。"
except Exception as e:
print(f"Error invoking Bedrock: {str(e)}")
return f"エラーが発生しました: {str(e)}"
def parse_bedrock_response(response):
parts = {}
current_part = None
for line in response.split('\n'):
if line.startswith('explanation:'):
current_part = 'explanation'
parts[current_part] = line.split(':', 1)[1].strip()
elif line.startswith('solution-by-terraform:'):
current_part = 'solution-by-terraform'
parts[current_part] = line.split(':', 1)[1].strip()
elif line.startswith('solution-by-console:'):
current_part = 'solution-by-console'
parts[current_part] = line.split(':', 1)[1].strip()
elif line.startswith('bestpractice:'):
current_part = 'bestpractice'
parts[current_part] = line.split(':', 1)[1].strip()
elif line.startswith('reference:'):
current_part = 'reference'
parts[current_part] = line.split(':', 1)[1].strip()
elif current_part:
parts[current_part] += ' ' + line.strip()
return parts
def lambda_handler(event, context):
tfsec_files = list_tfsec_result_files()
all_solutions = {}
for file_key in tfsec_files:
tfsec_results = read_tfsec_results(file_key)
prompts = generate_prompts(tfsec_results)
file_solutions = []
for result, prompt in prompts:
bedrock_response = invoke_bedrock(prompt)
parsed_response = parse_bedrock_response(bedrock_response)
file_solutions.append({
"problem": {
"rule_id": result.get('rule_id'),
"description": result.get('description'),
"impact": result.get('impact')
# "resource" 列を削除しました
},
"explanation": parsed_response.get('explanation', '説明を生成できませんでした。'),
"solution-by-terraform": parsed_response.get('solution-by-terraform', 'Terraformでの解決策を生成できませんでした。'),
"solution-by-console": parsed_response.get('solution-by-console', 'コンソールでの解決策を生成できませんでした。'),
"bestpractice": parsed_response.get('bestpractice', 'ベストプラクティスを生成できませんでした。'),
"reference": parsed_response.get('reference', '参照リンクを生成できませんでした。')
})
all_solutions[os.path.basename(file_key)] = file_solutions
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
output_key = f"{OUTPUT_PREFIX}bedrock_solutions_{timestamp}.json"
s3.put_object(
Bucket=OUTPUT_BUCKET,
Key=output_key,
Body=json.dumps(all_solutions, indent=2, ensure_ascii=False)
)
return {
'statusCode': 200,
'body': json.dumps(f'Solutions in Japanese generated and saved to s3://{OUTPUT_BUCKET}/{output_key}')
}
コンソール画面 キャプチャ

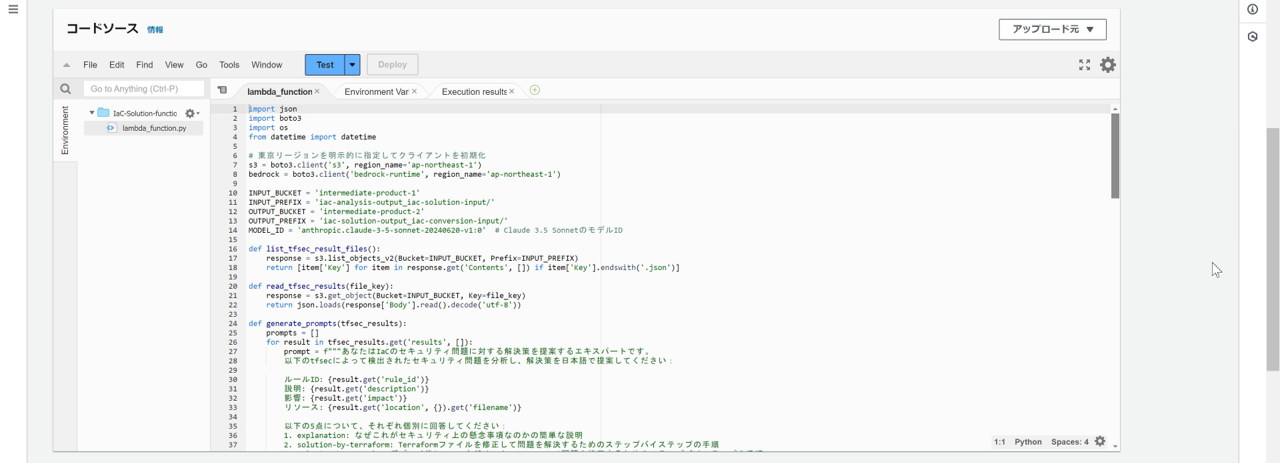

各関数の機能は以下の通り。
| 関数名 | 機能 |
|---|---|
| list_tfsec_result_files | S3バケット内に格納されているtfsecの解析結果ファイルをリストする |
| read_tfsec_results | tfsecの解析結果ファイルの内容を確認する。ここで確認されたtfsecの検知結果それぞれに対してプロンプトが与えられる |
| generate_prompts | Bedrock(Claude)に渡すプロンプトを生成している 与えるプロンプトに対する回答の形式に、それぞれキー(explanation,referenceなど)を個々に付与することで後にフォーマットしやすくしている |
| invoke_bedrock | 生成されたプロンプトを使用して、 Bedrockからモデルを呼び出し、応答を取得する |
| parse_bedrock_response | Bedrockから返された応答を解析し、 構造化されたデータに変換する generate_prompts関数で指定されたキー値に基づいて行を分割するよう指定する |
"max_tokens": 2000 で指定している。
日本語の場合、出力トークン数が増えてしまう(=課金額が高くなってしまう)ので、プロンプトを英語で指定すれば課金を抑えられる
temperatureの値に関する解説
invoke_bedrock関数内にtemperatureという値を指定している。
解決策の提示に重要な値であるため、役割を解説する。
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 2000,
"temperature": 0.7,
AWS公式の解説(https://docs.aws.amazon.com/bedrock/latest/userguide/inference-parameters.html) を和訳するとこのようになる。
予測される出力の確率分布の形状に影響し、モデルがより低い確率の出力を選択する可能性に影響します。
・より低い値を選択すると、モデルはより高い確率の出力を選択するようになります。
・より高い値を選択すると、モデルはより低い確率の出力を選択するようになります。技術的に言えば、temperatureは次のトークンの確率質量関数を調整します。temperatureが低いと関数が急峻になり、より決定論的な応答につながり、temperatureが高いと関数が平坦になり、よりランダムな応答につながります。
平たく言えば、値が高いほど様々な言葉を選んで自由な回答を返し、値が低いほど定型的な答えに寄っていくということである。
0 や 1 などの極端な値を設定することは少なく、だいたい 0.3 から 0.7 を設定するのが一般的である。
回答に高い確実性を求めるのであれば、この値を低く設定することが推奨される。
Bedrockから得られた結果はjsonファイルで出力されている。
最後にCSVファイルに変換することで、利用者が読みやすい形に整形して完成とする。
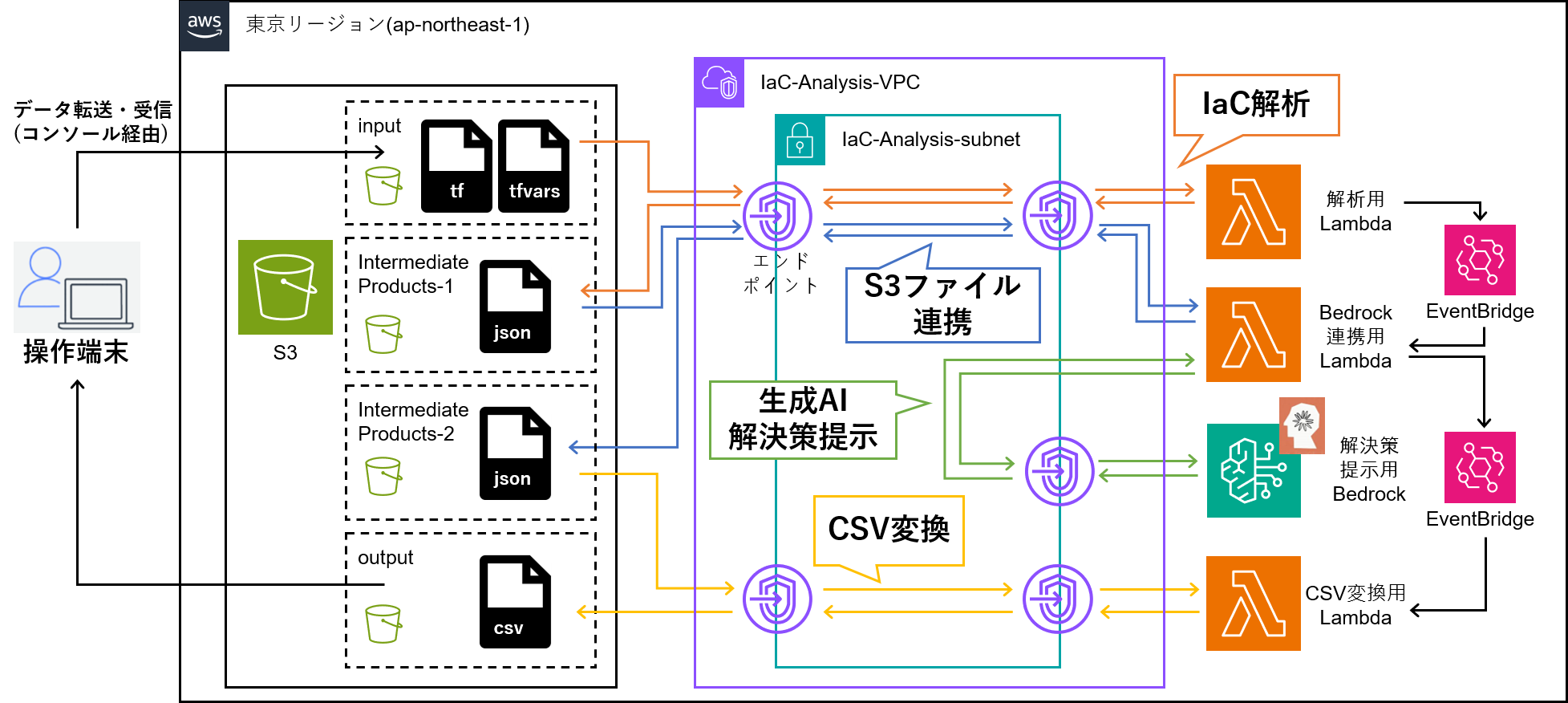
STEP3 完了時点でのアーキテクチャ図は以下の通り。
STEP4 - CSV変換用Lambda関数作成
最後にjsonファイルをCSVに変換する。
import json
import csv
import boto3
import io
from datetime import datetime
import os
s3 = boto3.client('s3')
INPUT_BUCKET = 'intermediate-product-2'
INPUT_PREFIX = 'iac-solution-output_iac-conversion-input/'
OUTPUT_BUCKET = 'terraform-security-solution-output'
OUTPUT_PREFIX = 'iac-conversion-output/'
def list_json_files():
response = s3.list_objects_v2(Bucket=INPUT_BUCKET, Prefix=INPUT_PREFIX)
if 'Contents' not in response:
return []
return [file['Key'] for file in response['Contents'] if file['Key'].endswith('.json')]
def read_json_file(file_key):
response = s3.get_object(Bucket=INPUT_BUCKET, Key=file_key)
content = response['Body'].read().decode('utf-8')
return json.loads(content)
def convert_to_csv(json_content):
output = io.StringIO()
output.write('\ufeff') # BOMを追加
writer = csv.writer(output, quoting=csv.QUOTE_ALL)
headers = ['ルールID', '説明', '影響', '場所','詳細',
'Terraformファイルでの修正方法', 'コンソールでの修正方法', 'ベストプラクティス', '参考']
writer.writerow(headers)
for file_name, problems in json_content.items():
if isinstance(problems, list):
for problem in problems:
row = [
problem.get('problem', {}).get('rule_id', ''),
problem.get('problem', {}).get('description', ''),
problem.get('problem', {}).get('impact', ''),
problem.get('problem', {}).get('location', ''),
problem.get('explanation', ''),
problem.get('solution-by-terraform', ''),
problem.get('solution-by-console', ''),
problem.get('bestpractice', ''),
problem.get('reference', '')
]
writer.writerow(row)
else:
print(f"Unexpected data structure for file {file_name}: {problems}")
return output.getvalue()
def upload_csv(csv_content, file_name):
s3.put_object(
Bucket=OUTPUT_BUCKET,
Key=f"{OUTPUT_PREFIX}{file_name}",
Body=csv_content.encode('utf-8'),
ContentType='text/csv; charset=utf-8'
)
def process_json_file(json_file):
json_content = read_json_file(json_file)
csv_content = convert_to_csv(json_content)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
base_name = os.path.basename(json_file).replace('.json', '')
csv_file_name = f"{base_name}_{timestamp}.csv"
upload_csv(csv_content, csv_file_name)
return csv_file_name
def lambda_handler(event, context):
json_files = list_json_files()
if not json_files:
return {
'statusCode': 404,
'body': json.dumps('No JSON files found')
}
processed_files = []
for json_file in json_files:
try:
csv_file_name = process_json_file(json_file)
processed_files.append(f"s3://{OUTPUT_BUCKET}/{OUTPUT_PREFIX}{csv_file_name}")
except Exception as e:
print(f"Error processing file {json_file}: {str(e)}")
return {
'statusCode': 200,
'body': json.dumps(f'CSV files created and uploaded: {", ".join(processed_files)}')
}
これまでに作った関数を、S3バケットのPUTアクションをトリガーにEventBridgeで連携させることで、Lambda関数間は自動で連携するように制御する。
完成しました。
テストしてみる
関数を起動すると、5分程度で結果のファイルがアウトプット用のS3バケットに格納される。
作成されたアウトプットファイルをダウンロードしてExcelで開くとこのように見えてくる。
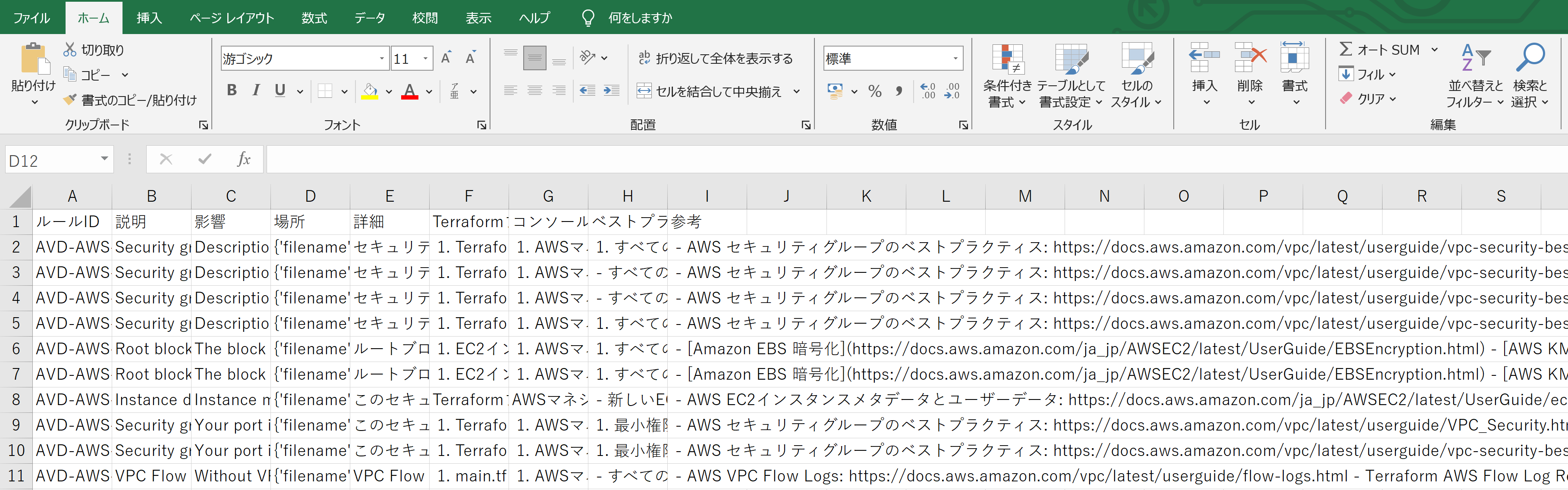
例としてセキュリティグループに説明がないことに対する解決策を抜粋して紹介する。
この結果をもとに、IaCを修正したりデプロイ後にマネジメントコンソールから修正するなど、品質向上に役立てることができる。
| 項目名 | 値 |
|---|---|
| ルールID | AVD-AWS-0124 |
| 説明 | Security group rule does not have a description. |
| 影響 | Descriptions provide context for the firewall rule reasons |
| 場所 | {'filename': '/tmp/tmpiy_qnuml/main.tf', 'start_line': 212, 'end_line': 224} |
| 詳細 | セキュリティグループルールに説明がないことは、セキュリティ上の懸念事項です。説明は、そのルールの目的や必要性を明確にし、他の開発者や運用チームがルールの意図を理解するのに役立ちます。説明がないと、不要なルールが残ったり、誤って変更されたりするリスクが高まります。 |
| Terraformファイルでの修正方法 | 1. Terraformファイルを開きます。 2. 該当するセキュリティグループルールのリソースを見つけます。 3. 各ルールに description 属性を追加します。例: hcl resource "aws_security_group_rule" "example" { type = "ingress" from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] security_group_id = aws_security_group.example.id description = "Allow inbound HTTP traffic" } 4. 変更を保存し、 terraform plan と terraform apply を実行して変更を適用します。 |
| コンソールでの修正方法 | 1. AWSマネジメントコンソールにログインします。 2. EC2ダッシュボードに移動します。 3. 左側のメニューから「セキュリティグループ」を選択します。 4. 該当するセキュリティグループを選択します。 5. 「インバウンドルール」または「アウトバウンドルール」タブを選択します。 6. 説明のないルールを見つけ、「ルールの編集」をクリックします。 7. 各ルールに適切な説明を追加します。 8. 「ルールの保存」をクリックして変更を適用します。 |
| ベストプラクティス | 1. すべてのセキュリティグループルールに明確で具体的な説明を追加する。 2. 説明には、ルールの目的、対象となるトラフィック、必要性の理由を含める。 3. 定期的にセキュリティグループルールをレビューし、不要なルールを削除する。 4. IaCツールを使用する場合、説明の追加を強制するカスタムルールやポリシーを実装する。 5. チーム内でセキュリティグループルールの命名規則と説明の標準を確立する。 |
| 参考 | - AWS セキュリティグループのベストプラクティス: https://docs.aws.amazon.com/vpc/latest/userguide/vpc-security-best-practices.html - AWS Well-Architected フレームワーク(セキュリティの柱): https://docs.aws.amazon.com/wellarchitected/latest/security-pillar/welcome.html |
最後に
Bedrock然り、生成AIの現場活用に頭を悩ませている人は多いと思います。
この記事がそういった方の一助になれば幸いです。
引用元
[1]基盤モデルによる生成 AI アプリケーションの構築 - Amazon Bedrock
https://aws.amazon.com/jp/bedrock/
[2]Claude入門 - Anthropic
https://docs.anthropic.com/ja/docs/intro-to-claude
[3]【tfsec】Terraformの静的セキュリティスキャンを行ってみよう!
https://dev.classmethod.jp/articles/tfsec-overview-scanning/