pandasのaxisの疑問
pandasのデータフレームに対して関数を適用する際に、軸の指定をすることはよくあることです。
その際にaxisの指定の仕方について疑問に生じたこととその回答についてメモしておきます。
前提
以下のようなデータフレームの操作に関する場合を考える。
df = pd.DataFrame([[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]],
columns=["col1", "col2", "col3", "col4"])
df
col1 col2 col3 col4
0 1 1 1 1
1 2 2 2 2
2 3 3 3 3
平均を取る
df.mean(axis=1)として平均を取ると、行ごとの平均が求まります。
df.mean(axis=1)
0 1
1 2
2 3
削除する
一方で、df.drop(name, axis=1)とすると、列を削除することになります。
df.drop("col4", axis=1)
col1 col2 col3
0 1 1 1
1 2 2 2
2 3 3 3
疑問
平均を取る作業では、asis=1によって、行の平均が求まり、
削除の作業では、axis=1によって、列を削除することになります。
このpandas仕様は非常にわかりにくいように思います。
回答
stackoverflowにて非常にわかりやすい説明があったので、実はそちらを簡単に和訳したものがこの記事です。
axis=0はそれぞれの列に対してだったり、それぞれの行ラベル(インデックス)に対してメソッドを適用する場合に用います。
axis=1はそれぞれの行だったり、列ラベル(列名)に対してメソッドを適用する場合に用います。
これをわかりやすく説明した画像を元の記事から引用します。
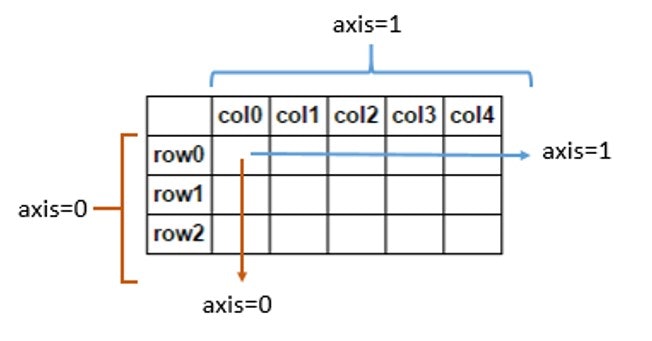
覚え方
axis=0('index') →列ごとに処理を行う
つまり、垂直方向に次元が圧縮される
結果、行が残る
axis=1('columns')→行ごとに処理を行う
つまり、水平方向に次元が圧縮される
結果、列が残る
この3段階の理解をしておくと忘れにくいはずです。
dropの処理も、レコードを1つ1つ削除していくことで、結果列を削除していると考えればうまく理解できる
補足
ちなみにこのpandasの仕様はnumpyの仕様に従っているらしいです。
詳しくはこちら