はじめに
システムを利用するお客様や業務部門の方は、社内外の多様化した膨大なデータを分析し、効率的にビジネスを推進しようとする中で、そのデータに本当の価値があるのかを判断している(注1)と思います。一方でシステムを提供する側のデータ管理者は、既存の IT インフラがある状況下で、多様化した膨大なデータの価値を知として最大化して、お客様や業務部門の方の判断を最適化し続けなければならないというプレッシャーがあります。たとえば、データ分析では、新しいデータソースへの接続や、そのデータの取り込み、膨大なデータの管理、レポーティング、パフォーマンス、といった IT インフラの課題に直面するでしょう。このようなデータ分析の課題には、R を使うと効率的に対応することができます。この Tips では、データ管理者が注力すべき領域の 1 つである、R について、構成要素やアーキテクチャを Oracle R の観点から解説します。
Oracle R の構成要素
Oracle Database 11g Release 2(11.2)以降、Oracle からも R が提供されるようになりました。Oracle R Distribution は有償の Oracle R Enterprise と併用することで高いパフォーマンスを期待(注2)できます。次の表では、Oracle R の構成要素について説明します。また、データベース・マニュアルにも R についての記述がありますので必要に応じて参照してください。また、Oracle R のインストールについても、マニュアル(注3)を参照して下さい。
| コンポーネント名 | 主な特徴 |
|---|---|
| Oracle R Distribution | Linux、Solaris および AIX 向けのオープン・ソース R の Oracle の無償版ディストリビューション。Intel の MKL パッケージなど、ハードウェア固有の数学パッケージの実装を利用することで高速なパフォーマンスを得られるように拡張されている。(注4) |
| Oracle R Enterprise | Oracle Advanced Analytics Option(有償)のコンポーネント。Oracle Database 11.2 Enterprise Edition 以降が必要。Oracle R Enterprise は、クライアントとサーバーで構成され、Microsoft Windows 、Oracle Linux、Red Hat Linux、Solaris、IBM AIX、また、Oracle Exadata でも動作可能。 |
Oracle R のアーキテクチャ
Oracle R は、クライアントとサーバーの 2 階層で構成されたアーキテクチャです。クライアント R エンジンは、Oracle Databese への接続と、そのデータベース内のデータとの対話を可能にする R パッケージの集まりです。サーバー R エンジンは、Oracle Databese でクライアント R エンジンをサポートするために必要な機能となるパッケージの集まりです。Oracle R は、データベース内の表、ビュー、外部表、およびデータベース・リンクに対するアクセスを可能にします。また、データベースによって管理される SQL 問い合わせのパラレル実行を利用して、大きなデータセットに対するパフォーマンスを向上させることができます。
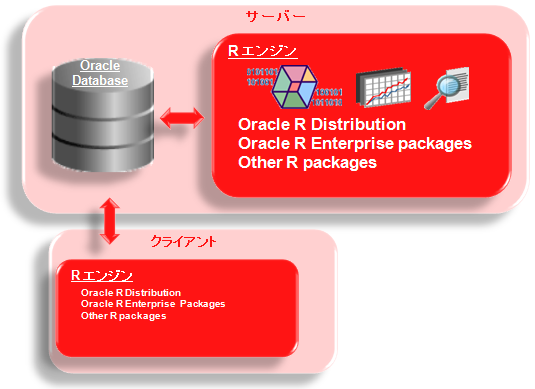
Oracle R の実行
R ではベクトルが処理単位の基本となります。このベクトルは、誤解を恐れずに言うと他のプログラミング言語の配列の概念に相当します。そして、統計解析と可視化を行う一連の手続きは、表現式で構成されます。表現式が R によって解析され、評価されます。R では、プログラミングの基本三構造を記述できますし、try 関数や tryCatch 関数等の構造化例外処理が用意されているので、プログラミング経験者であればすぐに使いこなすことができるようになるでしょう。次のサンプルスクリプトは、R による、一般的な統計 / 数学関数の実行結果例です。
1 から 10 までの合計値を計算する
> sum( 1:10 )
[1] 55
1 から 10 までの平均値を計算する
> mean( 1:10 )
[1] 5.5
1 から 10 までの標準偏差を計算する
> sd( 1:10 )
[1] 3.02765
Oracle R を使う前に
この Tips をご覧になっている方は、日常の業務でデータ分析の必要性がある方だと思っています。Oracle R は、容易に利用が可能なツールですが、データ分析ツールの一種に過ぎません。分析結果をどう扱うのか、少なくとも、自分が見て気がついた点については、何故そう思ったのか?それは意味のあることなのか?を探求し、アクションにつなげていきたいものです。このように、Oracle R を使う前には、データの価値を知として最大化することを考慮しなければなりません。日常の業務で本格的に活用する場合、たとえば、次のような点を検討しましょう。
データの棚卸
・業務用途なのか分析用途なのか?利用目的による分類
・構造化データなのか非構造化データなのか?情報源となるデータ構造による分類
・常に利用するデータなのか、まれに利用するデータなのか?利用頻度による分類
など
システム設計
・On Premise や Cloud 等のサーバー環境の検討
・デスクトップやモバイルなどのクライアント環境の検討
・レポーティングや対話形式で評価できる環境の検討
など
システム運用
・データのローディングやクレンジングの運用
・コーパスやオントロジー等のメタデータの運用
・統計解析に必要なパッケージ管理
・既存システムと共存可能な性能管理
など
(ご参考)R とは?
R は、次のような統計解析用の環境を提供します。(注5)
- データをインタラクティブに解析および可視化するための R Console
- 使いやすいプログラミング言語
- R パッケージによる多数の統計手法(2016/1/8で 7744 個を超える)
R は、GPL というライセンス形態で使用できるフリーで使える統計解析環境として1994 年に登場しました。主な用途はデータの解析と可視化で、現在の利用ユーザーは、ワールドワイドでおよそ 200 万人といわれています。(注6)
統計解析環境としては、S システム(1984 年、AT&T ベル研究所)が最初に存在していました。その後、GNU プロジェクトによりオープンソース化されたということで、乱暴な言い方をすれば、R は S システムのオープンソース版ともいえます。R の使われ方について、少し古いですが、「Bay Area R User Group 2009 Kickoff(注7)」でパネルディスカッションが行われました。ディスカッションによると、R を使っている企業がどのようなワークフローで利用しているか、また、どのような予測モデルを使っているか、そして、ツールとしての強み・弱みを理解することができます。たとえば、Google では、R をデスクトップ分析として使っていて、
1.外部ツールでデータを抽出
2.R へインポート
3.R で解析とモデリングを作成
4.プロダクション環境のためにモデリング結果を Python や C++ で実装
という流れで使っていると言っています。また、Facebook では、ユーザーが Facebook にとどまるための分析に、R のリカーシブパーティショニング(rpart パッケージ)を使っている事例を紹介しています。これらは担当者個人の意見ですので、企業全体の使い方というわけではありませんが、使い方のヒントとして理解しておきたいですね。
注釈
注1 WHITE PAPER Big Data in the Enterprise: When Worlds Collide
注2 R to Oracle Database Connectivity: Use ROracle for both Performance and Scalability
注3 R Enterprise User's Guide Release 1.2
R Enterprise Installation and Administration Guide Release 1.3.1
R Enterprise Installation and Administration Guide Release 1.4
注4 Oracle R Distribution Performance Benchmarks
注5 The R Project for Statistical Computing
注6 Learning R Series
注7 R-bloggers How Google and Facebook are using R