ISWCとは?
International Semantic Web Conference の略称です。18回目の今年は、オークランド(ニュージーランド)で開催されました。ISWCがどのような位置付けなのかは、関連国際会議の俯瞰図(神嶌敏弘氏)をご参照ください。 また、対象となるテクノロジー領域は、Wikipedia Semantic Web Stackをご参照ください。

出典:http://iswc2019.semanticweb.org
Oct-27
Keynote: The Tao of Knowledge Revisited
- 発表者
- Valentina Tamma(Liverpool University)
- サマリ
- 知識の道の再訪。質的実証の設計が重要であることを改めて解説するキーノートセッション。質的法則を十分に設計することは価値があり、質的および量的の検証を創造的に組み合わることによって、新たな法則を得る機会の可能性を言及していた。
- 関連資料
Logical Semantics Approach for Data Modeling in XBRL Taxonomies
- 発表者
- Olga Danilevitch(XBRL International, Inc.)
- サマリ
- XBRLの技術領域は、ファイナンシャルレポーティング、ナチュラルランゲージ、タクソノミーモデリングの3つによって構成される。XBRLのセマンティックテクノロジーへの今後の貢献は、これらの技術領域での大規模データ活用(AI含む)にあると言及していた。たとえば、中小規模(e.g. PetroChina, NTT Data, AI Fujitsu Labs, etc.)のデータ粒度の可視化にフォーカスすることのできる動的データ構造を求められていたり、金融領域での信頼あるデータ構造が求められたりなどだ。
- 関連資料
Towards More Intelligent SPARQL Querying Interfaces
- 発表者
- Hashim Khan
- サマリ
- SPARQLエンドポイントは、データダンプと比べて、最新データ、低バンドワイド、低アベイラビリティ、低クライアントコスト、サーバーコストが高いという特徴がある。SPARQLエンドポイントは、アベイラビリティとパフォーマンスのトレードオフの課題がある。具体的には、次のよう課題だ。
- どのようにクエリ実行前にワークスレッショルドを定義するか
- どのようにワークスレッショルドを有効にするか
- どのようにサーバーの状況をクライアントに通知するか
- どのようにサーバーの空き状況によってクライアントのクエリを中断するか
- SPARQLエンドポイントは、データダンプと比べて、最新データ、低バンドワイド、低アベイラビリティ、低クライアントコスト、サーバーコストが高いという特徴がある。SPARQLエンドポイントは、アベイラビリティとパフォーマンスのトレードオフの課題がある。具体的には、次のよう課題だ。
- 関連資料
The Butterfly Effect in Knowledge Graphs: Predicting the Impact of Changes in the Evolving Web of Data
- 発表者
- Romana Pernischová
- サマリ
- ナレッジグラフを変更した際の影響について理解を深める方法論について言及していた。課題設定は、リコメンデーションなどの運用を考慮した影響の測定について定義すること。今後は様々なナレッジグラフで適応性を確認して方法論のさらなる改善を行うことを発表していた。
- 関連資料
A Knowledge Graph for Ecotoxicological Risk Assessment and Effect Prediction
- 発表者
- Erik Bryhn Myklebust
- サマリ
- エコトキシコロジカル(生態毒性学的影響)領域に関連するナレッジをカバーすることを目指した調査結果の発表。化学化合物が種に及ぼすエコトキシコロジカルを判断するには、膨大な実証実験が必要となる。そこで、ナレッジグラフを予測アプローチに統合するための調査を行っていた。
- 関連資料
Semantic Enrichment for Large-Scale Data Analytics
- 発表者
- Vincenzo Cutrona
- サマリ
- 不特定多数ユーザの探索的なユースケース、Web経由のデータアクセスのユースケースなど、大規模データの分析におけるセマンティックデータの充実について言及していた。セマンティックデータを充実させる際の課題として、データ変換に課題があり、調査会社によると、80%の時間を費やしているという。解決策として、アノテーション付与やテーブルマッピングのツールなどの方法論の提供を解説していた。
- 関連資料
Knowledge-based geospatial data integration and visualization with Semantic Web technologies
- 発表者
- Weiming Huang
- サマリ
- 地理空間情報処理にセマンティックウェブテクノロジーを活用するジオビジュアライゼーションの実装について言及していた。近年、Spatial Data Infrastructure(SDI)の需要が欧米で高まっている状況であり、地理空間上でオントロジーを扱う方法論として貢献できると解説していた。
- 関連資料
Ontologies and AI in Recruiting. A Rule-Based Approach to address ethical and legal auditing
- 発表者
- Carmen Fernández Martínez and Alberto Fernandez
- サマリ
- 雇用市場における人工知能(AI)活用は、倫理的および法的側面で賛否両論であり、運用には外部および中立の監査を必要とする。潜在的な人種差別を減らすための中立的な監査をする解決策として、マルチエージェントシステムアーキテクチャについて言及していた。エージェントは、インタビュー設計エージェント、インタビュー監査エージェント、セレクションエージェントなど、機能と人が分離できるようになっている。
- 関連資料
Policy-compliant Data Processing: RDF-based Restrictions for Data-protection
- 発表者
- Sven Lieber
- サマリ
- 個人のプライバシーや個人情報を保護するために、オントロジーを利用したポリシーによって制限する方法論を解説していた。具体的には、Shapes Constraint Language (SHACL)/Shape Expressions (ShEx)を使うことを言及していた。SHACL/ShExは、RDFグラフがDSLで記述された制約に従っているかを検証するためのテクノロジー。
- 関連資料
Decentralized Route Planning across the Web of Data
- 発表者
- Julian Rojas
- サマリ
- Web上に分散しているデータをSPARQLで問い合わせる際の効率化テクニックについて言及していた。例えば、セマンティックモデルの作り方や、データ分割についてなど。ただし、オーディエンスからは、データモデルのアプローチなのか、アルゴリズムのアプローチなのか、解決策が明確でないと指摘されていた。
A Decentralized Provenance Network for Linked Open Data
- 発表者
- サマリ
- Linked Open Data のためのネットワークの分散化について言及していた。たとえば、DCAT、LDP、SHACLなどのガイドに従ったURIの設定などであり、基本的なデータ品質に関するエンジニア視点の発表だった。
- 関連資料
Oct-28
Openning Session
- サマリ
- Co-Chair Jing Sunらによるオープニングセッション。スポンサーの紹介、施設の紹介。SWSA(Semantic Web Science Association) President の Ian Horrocks から優秀論文賞などのアワード発表。ISWC活動状況の報告(トレンド、論文数、コントリビューション)。Track(Doctoral Consortium、reproducibility、In-Use、Journal、Workshop、Poster、Challenges、Metadata、Proceedingsなど)の紹介。2019 SWSA Distinguished Dissertation Award は、Petar Ristoski (IBM Almaden Research Center, California, USA) が受賞した。論文は、
Exploiting Semantic Web Knowledge Graphs in Data Mining
- Co-Chair Jing Sunらによるオープニングセッション。スポンサーの紹介、施設の紹介。SWSA(Semantic Web Science Association) President の Ian Horrocks から優秀論文賞などのアワード発表。ISWC活動状況の報告(トレンド、論文数、コントリビューション)。Track(Doctoral Consortium、reproducibility、In-Use、Journal、Workshop、Poster、Challenges、Metadata、Proceedingsなど)の紹介。2019 SWSA Distinguished Dissertation Award は、Petar Ristoski (IBM Almaden Research Center, California, USA) が受賞した。論文は、
Keynote: Semantics: the business technology disruptor of the future
-
発表者
- Dougal Watt
-
サマリ
- これからのインフォメーションマネジメントは、ナレッジセントリックが重要だと言及していた。従来の設計アプローチをアプリケーションセントリックと定義、それは最初にアプリケーションからアーキテクチャを見て、それからプロセスについて考え、最後にデータの保存方法について考えるアプローチである。一方、最新の設計アプローチをナレッジセントリックと定義し、最初にナレッジを構造化することから始めて、すべてのレガシーシステムからすべてのデータを取り込む。これは、企業のビジネスが将来どのように競争したいかを示すモデルとなる。ナレッジグラフのテクノロジースタックは、Amazon Neptune を利用している。(写真参照)

- これからのインフォメーションマネジメントは、ナレッジセントリックが重要だと言及していた。従来の設計アプローチをアプリケーションセントリックと定義、それは最初にアプリケーションからアーキテクチャを見て、それからプロセスについて考え、最後にデータの保存方法について考えるアプローチである。一方、最新の設計アプローチをナレッジセントリックと定義し、最初にナレッジを構造化することから始めて、すべてのレガシーシステムからすべてのデータを取り込む。これは、企業のビジネスが将来どのように競争したいかを示すモデルとなる。ナレッジグラフのテクノロジースタックは、Amazon Neptune を利用している。(写真参照)
-
関連資料
How to make latent factors interpretable by feeding Factorization machines with knowledge graphs
- 発表者
- Vito Walter Anelli, Tommaso Di Noia, Eugenio Di Sciascio, Azzurra Ragone and Joseph Trotta.
- サマリ
- Hybrid Factorization Machine(kaHFM) の実証実験。解釈可能なモデルを訓練するためのナレッジグラフを使用して、Factorization Machine の潜在因子を初期化する方法の検証について言及していた。
- 関連資料
A Framework for Evaluating Snippet Generation for Dataset Search
- 発表者
- Xiaxia Wang, Jinchi Chen, Shuxin Li, Gong Cheng, Jeff Z. Pan, Evgeny Kharlamov, Yuzhong Qu
- サマリ
- データセットの情報はメタデータだけだとわかりずらい。これをスニペット生成によって改善する実証実験。良いスニペットの定義は、キーワード、キーワード間のコネクション、スキーマ(頻出クラス&プロパティ)、データ(セントラルエンティティ)であると仮説を立てて、オントロジーを設計した。実際のデータを使っておらず、あくまでもサンプルデータセットでの実証。
- 関連資料
Summarizing News Articles using Question-and-Answer Pairs via Learning
- 発表者
- Xuezhi Wang and Cong Yu(Google Research, New York, USA)
- サマリ
- Q&Aシステムにおけるセマンティックテクノロジー活用に関しての Google の研究発表。ニュースストーリーに関連付けられたデータから質問をマイニングし、ストーリーのコンテンツから直接質問を学習するという仕組み。ニュース記事の重要で興味深い側面をキャプチャするための質問と回答のペアを持つニュース記事の構造化された要約を生成する学習ベースのアプローチの最初の実証実験らしい。検証データは、SQuAD dataset 2 を使用している。
- 関連資料
Using a Knowledge Graph of Scenes to Enable Search of Autonomous DrivingData
- 発表者
- Cory Henson, Stefan Schmid, Anh Tuan Tran and Antonios Karatzoglou
- サマリ
- セマンティックテクノロジを使用したボッシュでの実証実験について解説していた。データの用途は、自動運転技術向けの大規模データの提供を想定している。効果としては、自動運転データを表現、統合、およびクエリするケイパビリティの向上。また、さまざまなプロジェクト内や部門内のデータサイエンティストやエンジニアがお互いのアプリケーションのデータを再利用できることを見込んでいる。
- 関連資料
Using Event Graph to Improve Question Answering in E-commerce Customer Service
- 発表者
- Feng-Lin Li, Kehan Chen, Yan Wan, Weijia Chen, Qi Huang and Yikun Guo
- サマリ
- 質問応答サービスを提供するインテリジェントアシスタント「AliMe」について解説していた。1日当たり数百万もの質問に90%以上回答できるとしている。本セッションでは、質問タイプ「why」、「whether」、「what if」、および「how next」に対する正確な回答を得るための推論の仕組みである、Event Graph を提案していた。イベントは、起きうるシチュエーションの選択肢のプロパティのようだ。なお、ベースラインのナレッジグラフは、WIKIDATA、DBpedia、YAGOなどを使って生成したそうだ。
- 関連資料
Federated search experiences in DISQOVER
- 発表者
- Kenny Knecht, Paul Vauterin and Hans Constandt
- サマリ
- フェデレーテッドサーチをするために、ONTOFORCE というツールを使用するアプローチを紹介していた。実際にバイオメディカル領域の140の異なるデータセットを動かしているとのこと。
- 関連資料
Querying Enterprise Knowledge Graph With Natural Language
- 発表者
- Junyi Chai, Yonggang Deng, Maochen Guan, Yujie He, Bing Li and Rui Yan(Microsoft AI & R, Bellevue, WA, USA)
- サマリ
- 大規模エンタープライズナレッジグラフへの対話型インターフェイスの研究について解説していた。この仕組みをYugen(ユーザーの質問に答えるディープラーニングベースの対話型AI)と呼んでいた。すでに企業向けに、コールドスタートの課題やドメイン固有データの検出の課題などに取り組んでいるらしい。Yugenは音声ベースなので、特定のクエリ言語を学習するコストを抑えられることがメリット。
- 関連資料
Product Classification Using Microdata Annotations
- 発表者
- Ziqi Zhang and Monica Paramita
- サマリ
- Webで公開されたマークアップデータ(ここではRDFやMicrodataを指す)を使用して、製品を普遍的なカテゴリに自動で分類するタスクを解説していた。チャレンジは、分類に必要な情報の扱い(例:個別のウェブサイトの扱い、ウェブサイト間の一貫性、サイト固有の商品ラベルなど)になる。ディープラーニングのインプットデータにRDFを使った事例となる。
Difficulty-controllable Multi-hop Question Generation From Knowledge Graphs
- 発表者
- Vishwajeet Kumar, Yuncheng Hua, Guilin Qi, Ganesh Ramakrishnan, Lianli Gao and Yuan-Fang Li.
- サマリ
- ニューラルネットワークベースのマルチホップクエスチョンについて解説していた。マルチホップクエスチョンとは、グラフ構造のノードを2回以上ホップスなければ回答できない質問のこと。解決策として、難易度を条件とするエンコーダーデコーダーモデルを実装し、大規模なナレッジグラフを介して複雑な質問を生成することができたと言及していた。ただし、実現は難しく今後の研究が必要そうだった。
- 関連資料
Deep learning for noise-tolerant RDFS reasoning
- 発表者
- Bassem Makni and James Hendler(IBM Watsonのリサーチャーもやっているらしい)
- サマリ
- 現実のWebデータは本質的にノイズが多いので、ナレッジグラフの構築では、ルールベースではなく、ノイズトレランスにすべきと言及していた。RDFグラフを階層化し、ディープラーニングを使用してセマンティックWebデータからRDFSルールを学習するモデル。このセッションでは、型推論に焦点を当て、完全なRDFS(RDF Schema)推論を目指していない。
- 関連資料
Oct-29
Keynote: For knowledge
- 発表者
- Jérôme Euzenat, James Hendler
- サマリ
- ナレッジは重要であり、我々はこの視点を失っている、というトーンで始まった。マシンがナレッジを把握できるようにするセマンティックウェブのアイディアはすばらしい。だがしかし、過去20年のセマンティックウェブは、データに焦点を当てている。データはナレッジなしには意味がない、それは、凡例のない地図のようなものだ、と言う。メソドロジー、サイエンティフィックだけではない、ナレッジの進化が必要であり、知識をどのように生かして発展させることができるか?チェンジパラダイムを問いかけるセッションだった。
- 関連資料
- Ontology Matching(ASIN: B00GJDESFK)
- Semantic Web for the Working Ontologist: Effective Modeling in RDFS and OWL(ASIN: B005XJ7AGA)
Towards Semantic Integration of Bosch Manufacturing Data
- 発表者
- Anees Mehdi, Evgeny Kharlamov, Daria Stepanova, Felix Loesch and Irlan Grangel Gonzalez
- サマリ
- BOSCHにおける、インダストリ4.0のためのセマンティックデータインテグレーションのチャレンジ。製造オペレーションマネジメントのリファレンスモデルであるIEC/ISO 62264に準拠している。
- 関連資料
Towards Integrating Ontologies into Verification for Autonomous Driving
- 発表者
- Arut Prakash Kaleeswaran, Arne Nordmann and Anees Ul Mehdi
- サマリ
- BOSCHの事例。自律的な運転は、人間の介入なしに実現しなければならないが、従来の検証方法はシステムの機能的整合性のみに焦点を合わせているためマッチしない。外部世界との整合性をとるために、複雑なコンテキストを考慮する必要があるため、オントロジーを使用した検証方法を考案した。
- 関連資料
The European Data Portal: Scalable Harvesting and Management of Linked Open Data
- 発表者
- Fabian Kirstein, Simon Dutkowski, Benjamin Dittwald and Manfred Hauswirth
- サマリ
- European Data Portalの実装について。トリプルストアは、Virtuoso、全文検索は、Elasticsearch、ブラウジングは、SPARQL、RESTful APIなど。Java frameworkは、Vert.x8 を使用し、スケーラブルな microservice approach を採用した。システムは、container-orchestration を採用した。2019年5月にローンチ。
- 関連資料
Open Services for Lifecycle Collaboration (OSLC) – Extending REST APIs to Connect Data
- 発表者
- Axel Reichwein and Fernando Lopez
- サマリ
- OSLCは、ソフトウェアやシステムエンジニアリング領域のスタンダードを提供する。現状のデメリットとしては、セマンティックウェブ領域ではまだ認知度が低い、デザインするベンダーがまだ少ないためロックインされる。ただし、スタンダードとしての活動を進めていくので、トライしてほしい。
- 関連資料
On the Use of Cloud and Semantic Web Technologies for Generative Design
-
発表者
- Daniel Mercier and Ali Hashemi(AUTODESK)
-
サマリ
- データソースの統合、データバリデーション、データマネージメントの課題に対処した Generative Design(GD) を、セマンティックテクノロジーを使用して解決した。これらはパブリッククラウド上(AWS、Azure、GCP)でサービスメッシュによって構成されている。AUTODESKとしては、SOAアプローチと合わせて対策しているが、ここでは後者は語られなかった。
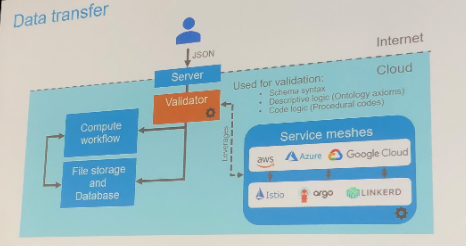
- データソースの統合、データバリデーション、データマネージメントの課題に対処した Generative Design(GD) を、セマンティックテクノロジーを使用して解決した。これらはパブリッククラウド上(AWS、Azure、GCP)でサービスメッシュによって構成されている。AUTODESKとしては、SOAアプローチと合わせて対策しているが、ここでは後者は語られなかった。
-
関連資料
Business Driven Insight via a Schema-Centric Data Fabric
- 発表者
- Dougal Watt, Brad Bebee and Michael Schmidt
- サマリ
- ビジネスインテリジェンス(BI)プロジェクトは、80%の高い失敗率となっている。原因は第一に自ネス成果に直結しないこと、第二に自らのデータから洞察できないことだと言う。解決策として、データをセマンティックデータとして定義し、これらの分析の課題解決を支援した。プラットフォームは、Amazon Neptuneを使用した。グラフであれば、ビジネスユーザーが理解できる形式でビジネスデータをモデル化して管理できる。なお、DWHはOracleからRedshiftに移行したとのこと。
Thales XAI Platform: Adaptable Explanation of Machine Learning Systems – A Knowledge Graphs Perspective
- 発表者
- Freddy Lecue
- サマリ
- フランスの電子機器企業のデジタルプラットフォームの構築事例。そのプラットフォームではAIを活用しているが、クリティカルシステム(例えば列車事故の予防システムなど)ではAIの予測結果に説明が必要になる。ナレッジグラフは、予測結果の説明に使うために利用した。具体的には、画像からAIによって物体検知させた結果をグラフ構造で可視化する。
- 関連資料
Transactional Guarantees for SPARQL Query Execution with Amazon Neptune
- 発表者
- Brad Bebee, Ankesh Khandelwal, Sainath Mallidi, Bruce McGaughy, Simone Rondelli, Michael Schmidt and Bryan Thompson
- サマリ
- AMAZON Neptune の実装について、SPARQLトランザクションのアイソレーションレベルに関する仕様について言及していた。ノンシリアライザブルを回避するために、レンジロックするなどの特徴の紹介。
- 関連資料
Oct-30
Keynote: Extracting Knowledge from the Data Deluge to Reveal the Mysteries of the Universe
-
発表者
- Melanie Johnston-Hollitt
-
サマリ
- 宇宙の謎を明らかにするために、データ大洪水からナレッジを抽出する事例を紹介していた。Astrophysics(天体物理学)は、大規模データを扱うデータ集約型の研究分野の一つ。たとえば、現在の望遠鏡は年間数十ペタバイトのデータを生成している。SKAプロジェクトのオーストラリアの望遠鏡では、1日あたり157テラバイト、年間4.9ゼタバイト近いデータを生成している。これらのデータは1日あたり1ペタバイトのデータキューブとしてキュレーションし、世界の天文コミュニティに配信される。生成された膨大なデータをナレッジとして活用するために、自動化されたセマンティックプロセスが必要になると考えた。より優れたデータのタグ付け、データのコーディネートだけでなく、アルゴリズム、人工知能、オントロジーの改善によって、自動でナレッジを追跡し抽出する必要があった。
-
用語解説
- Square Kilometre Array (SKA)プロジェクトは、2025年から科学観測を開始する予定の、1平方キロメートルの集光面積を持つ、世界最大の電波望遠鏡を建設する国際的な試み。
Learning to Rank Query Graphs for Complex Question Answering over Knowledge Graphs
-
発表者
- Gaurav Maheshwari, Priyansh Trivedi, Denis Lukovnikov, Nilesh Chakraborty, Asja Fischer and Jens Lehmann
-
サマリ
- 複雑なQ&Aに対応できるナレッジグラフを目指すために、ニューラルネットワークのインプットとなるいくつかのランキングモデルを考案して調査した。モデルは、クエリの固有の構造をグラフとしている。
-
関連資料
Pretrained Transformers for Simple Question Answering
-
発表者
- Denis Lukovnikov, Asja Fischer and Jens Lehmann
-
サマリ
-
関連資料
http://jens-lehmann.org/files/2019/iswc_bert_simple_questions.pdf
QaldGen: Towards Microbenchmarking of Question Answering Systems Over Knowledge Graphs
-
発表者
- Kuldeep Singh, Muhammad Saleem, Abhishek Nadgeri, Felix Conrads, Jeff Z. Pan, Axel-Cyrille Ngonga Ngomo and Jens Lehmann
-
サマリ
- ドメインスペシフィックなQ&Aシステムをテストしようとすると、質問を生成する手間があるので、マイクロベンチマークが必要だと言及していた。マイクロベンチマークに有用な質問を生成するためのフレームワークとして、QaldGenを提案していた。
-
関連資料
etc
Poster
-
Amazon Neptune
- これからは、データをナレッジとして活用できるプラットフォームが競争優位の源泉となる

- これからは、データをナレッジとして活用できるプラットフォームが競争優位の源泉となる
-
poLyInfo
- 日本から唯一のポスター、NIMS谷藤先生ら

- 日本から唯一のポスター、NIMS谷藤先生ら
Minute Madness
- 2011年に始まったISWCの伝統的なミーティングスタイルで、言い換えると、ライトニングトーク。以下、主な発表内容。セマンティックのウェアラブルコンピューティングへの活用、フェイクニュースの判断、分散ウェブシステムシンポジウムの告知、IBMの採用告知、ナレッジグラフをスケールさせるジョブ、イタリア当局などデータマネジメントのジョブ、エンタープライズナレッジグラフ構築(R2RMLマッピングなど)のサービス、リサーチパートナーの募集、など。
Useful information
- GitHubをベースとしたSemanGit なるものがボン大学(ドイツ)から研究発表されていた。http://www.semangit.de 発表者によると、GitHub Rest API との違いはないとしたものの、スキルセットの発掘、個別の実証データへのアクセス、盗作の検知などのゴール設定が可能な技術だと言及していた。詳しいレポートはこちら 。
- The Microsoft Academic Knowledge Graph: A Linked Data Source with 8 Billion Triples of Scholarly Data は、80億の学術データのトリプルを作成したことを発表していた。こちらからRDFデータセットをダウンロードできる。
- geonames は、地理空間のデータセットを提供している。
- Affectiva は、emotion measurement technology を提供する企業である。
- Tracking Progress in Natural Language Processing は、NLP 領域の研究状況をアップデートしている。
- 検証で使われるデータセット