はじめに
似たような文書がいくつかあって、それらの違いが何なのかを大まかに把握したいというシチュエーションはありませんか?例えば、とある製品の新機能を紹介した資料があって、昔と今のトレンドにどのような変化があるかを大まかに把握したい、というようなシチュエーションです。このような場合、文書の特徴を抽出する手法の一つである、tf-idf(Term Frequency - Inverse Document Frequency)を利用するとよいでしょう。
tf-idf は、文書中の単語に関する重みの一種であり、主に情報検索や文章要約などの分野で利用されます。tf-idf を簡単にご説明すると、単語が1つの文書中にどれだけ出現するか、それと、全文書の中で単語が出現する文書がどれだけあるかを計算しています。詳しい計算式は Web で調べてもらえればすぐに見つかると思います。この Tips では、tf-idf を、RMeCab ライブラリの docMatrix ファンクションで利用しています。処理の流れは次の通りです。
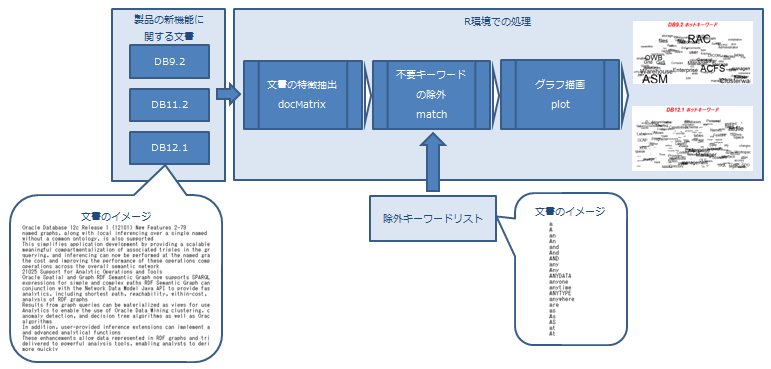
tf-idfによる文書の特徴抽出
▼サンプルスクリプト
R
# 日本語形態素解析のライブラリ(注1)を読み込みます
library (RMeCab)
# ワーキングディレクトリを指定します
setwd("ワーキングディレクトリ")
# 除外キーワードリストを読み込みます
e1 <- read.table('Exclude.txt', header=T)
# 文書が格納されているディレクトリを指定します
targetDir <- "文書が格納されているディレクトリ"
# tf-idfで文書の特徴を抽出します
test <- as.data.frame( docMatrix(targetDir, weight = "tf*idf" ) )
# 除外用フラグを追加します(4列目になります)
test <- cbind(test, c(rep(0, times=nrow(test))))
# キーワード列を複製します(5列目になります)
test <- cbind(test, c(rownames(test)))
# 除外キーワードリストに含まれる単語の除外用フラグをオンにします
test[na.omit(match(e1[,1], test[,5])), 4] <- 1
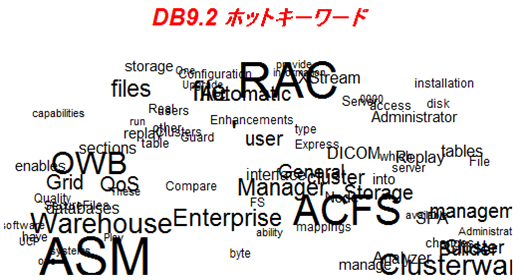
# 文書「DB9.2」から、頻出度が20以上の単語を抽出します
DB9.2 <- test[ test[,1] > 19 & test[,4] == 0 , ]
# 配置先(x,y)をランダム値から生成してバインドします(6,7列目になります)
p <- cbind(sample(1:nrow(DB9.2)),sample(1:nrow(DB9.2)))
DB9.2 <- cbind(DB9.2,p)
# グラフ描画します
plot(DB9.2[,6],DB9.2[,7],type="n",xaxt = "n", yaxt = "n",frame = FALSE,ann=FALSE)
text(DB9.2[,6],DB9.2[,7],labels =DB9.2[,5],cex=DB9.2[,1]/40)
title(main="DB9.2 ホットキーワード",cex.main=1.4,font.main=4,col.main="red")
▼実行結果例
R
# 文書「DB12.1」から、頻出度が20以上の単語を抽出します
DB12.1 <- test[ test[,3] > 19 & test[,4] == 0 , ]
# 配置先(x,y)をランダム値から生成してバインドします(6,7列目になります)
p <- cbind(sample(1:nrow(DB12.1)),sample(1:nrow(DB12.1))) # ポジションをランダム決定する
DB12.1 <- cbind(DB12.1,p) # ポジションを結果にバインド(6,7列目)
# グラフ描画します
plot(DB12.1[,6],DB12.1[,7],type="n",xaxt = "n", yaxt = "n",frame = FALSE,ann=FALSE)
text(DB12.1[,6],DB12.1[,7],labels =DB12.1[,5],cex=DB12.1[,1]/40)
title(main="DB12.1 ホットキーワード",cex.main=1.4,font.main=4,col.main="red")
▼実行結果例

注釈
注 1 サンプルスクリプトは、RMeCab 0.9993 を使用しています。