はじめに
データを扱う人であれば誰でも、利用者がデータをどんな場面で活用しているのかを想像しているのではないでしょうか。たとえば、技術者が技術トレンドをいち早くキャッチして何のスキルセットを新たに身に付けるか、プロジェクトマネージャが先を見通してどうやって品質、費用、納期をコントロールするか、CEO がこれから伸びていくであろう事業領域を予見してどの事業に経営資源を割り当てるか(注1)など、データの価値を知として最大化している様子をイメージしていると思います。
データの出どころは人それぞれだと思いますが、近頃はブログやニュースサイトといったインターネット上のデータにも価値ある内容が溢れていると考えています。このような客観的なデータを入手することができるのなら、一人で考えるより間違いを発見しやすいですし、ジェームズ・スロウィッキーの「みんなの意見は案外正しい(注2)」で述べられているような群衆の英知を形成できれば、得られるものは多いでしょう。統計学的には、母集団が多ければ多いほど、正確には多様性があるほど、結論を逸脱する可能性は低いと言えます。問題は、インターネット上のデータは膨大であるがゆえに、直感的に把握することが難しいという点です。
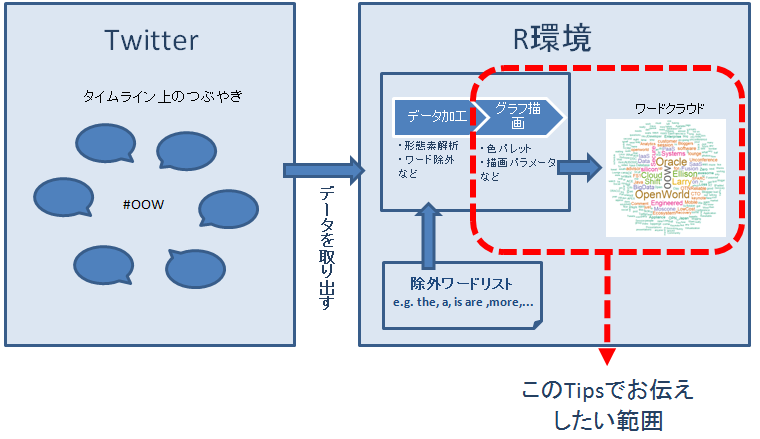
この問題に対して有効なのが文章内の単語を分析してエッセンスをひと目で表すワードクラウドです。ワードクラウドは図のような処理フローで作成します。図は、Twitter から、Oracle Open World の略語である「oow」に関するツイートを取得し、そのデータを加工後、ワードクラウドに描画する手順を示しています。
Twitter からタイムラインを読み込む
まず最初に、R セッションで Twitter を利用できるように、OAuth による認可情報を設定します。OAuth は、ユーザの同意のもとに、あらかじめ信頼関係のある Web サービス間で、セキュアにユーザの権限を受け渡しする、いわゆる、認可情報の委譲のための仕様です。なお、Consumer Key、Consumer Secret、Access Token、Access Token Secretの取得方法については、Tips下部を参照して下さい。
▼サンプルスクリプト
# 作業ディレクトリの指定
setwd("<作業ディレクトリを指定>")
# Twitter接続用に、パッケージ「twitteR(注3)」を読み込みます
library( twitteR )
# Consumer Key をセットします
consumerKey <- "XXXXX"
# Consumer Secret をセットします
consumerSecret <- "XXXXX"
# Access Token をセットします。
accessToken <- "XXXXX"
# Access Token Secret をセットします
accessTokenSecret <- "XXXXX"
# R で認可情報を使用するため、setup_twitter_oauth()関数を実行します
setup_ twitter_oauth( consumerKey, consumerSecret, accessToken, accessTokenSecret )
▼実行結果例
# setup_twitter_oauth() 関数の実行後に表示されるプロンプトに対して「1」を入力します。
[1] "Using direct authentication"
Use a local file to cache OAuth access credentials between R sessions?
1: Yes
2: No
Selection: 1
▼サンプルスクリプト
# TwitterのTimelineを取得します
tweets <- userTimeline( "Oracle", n = 3200)
# 結果をファイル "tweets.R" に書き込みます
sink( file = "tweets.R" )
# 変数「tweets」を表示します
tweets
# 出力を再びコンソールに切替えます
sink()
ワードクラウド用にデータを加工する
データの加工には、日本語形態素解析パッケージの「RMeCab」を使用します。サンプルコードで使用している、除外キーワードリストとは、データからノイズと考えられるデータを除外するために、たとえば、記号や助詞などのデータを格納します。
▼サンプルスクリプト
# 日本語テキストの解析用に、パッケージ「RMeCab(注4)」を読み込みます
library( RMeCab )
# RMeCabFreq()関数で、変数「Tweets」を日本語形態素解析します
twitWord <- RMeCabFreq( "tweets.R" )
# 除外キーワードリストを読み込みます
excludeWord <- read.table( "Exclude.txt", header = T )
# 変数「Tweets」を、一般名詞と固有名詞に絞り込みます
twitWord <- twitWord[twitWord[, 2] == "名詞"&( twitWord[, 3] == "一般" | twitWord[, 3] == "固有名詞" ),]
# 変数「twitWord」に、除外用フラグ列を追加します
twitWord <- cbind( twitWord, c(rep(0, times = nrow( twitWord ))))
# 除外キーワードリストとマッチするものは除外フラグをオンにします
twitWord[na.omit( match( excludeWord$exclude, twitWord$Term )), 5] <- 1
# 頻出度が5回以上の語に絞り込みます
twitWord <- twitWord[ twitWord[,4] > 4 & twitWord[,5] == 0, ]
ワードクラウドに描画する
ワードクラウドの描画には、wordcloud() 関数を使用します。scale パラメータで文字サイズを変更したり、rot.per パラメータで縦横比率を変更したりすることで、見やすさを調整します。
▼サンプルスクリプト
# ワードクラウド生成用に、パッケージ「wordcloud(注5)」を読み込みます
library( wordcloud )
# カラーパレット用に、パッケージ「RColorBrewer(注6)」を読み込みます
library( RColorBrewer )
# ワードクラウドを描画します
wordcloud( twitWord[,1],twitWord[,4], scale = c( 6, 1 ), min.freq = 3, max.words = Inf, random.order = FALSE, rot.per = .05, colors = brewer.pal( 8, "Dark2" ))
▼実行結果例

さいごに
Twitter の個々のつぶやきを直感的に把握できるワードクラウドにすることができました。なお、ダニエル・カーネマンが『ファスト & スロー』(注7)で述べているように、直感による判断は、不確実性下で極めて経済的で概ね効率的ですが、時には系統的で予測可能なエラーにつながる点に注意してください。これは普通の人々に限られるわけではなく、経験豊富な高度に統計解析の訓練を受けた専門家であっても、同じバイアスにかかりやすいものです。
ご参考
Twitter のアプリケーションを作成するには?
ワードクラウドの解説からは離れますが、Twitter のアプリケーションを作成する手順をご紹介します。
- Twitter アプリケーション管理サイト(https://apps.twitter.com/)を開く。
- 「Create New App」ボタンをクリックする。
- Application Details 画面でアプリケーション名などの必要事項を入力する。
R の場合はローカル実行になるので、Website 欄には、「http://127.0.0.1」を入力。 - 「Yes, I agree」チェックボックスをオンにし、「Create your twitter application」ボタンをクリックする。
- Twitter アプリケーションページから「Keys and Access Tokens」タブを開き、Consumer Key、Consumer Secret、Access Token、Access Token Secret を確認する。
注釈
注 1 William N., Jr. Thorndike『The Outsiders』(2012 年 10 月 23 日 , Harvard Business School Pr, 251 ページ)
注 2 2James Surowiecki『The Wisdom of Crowds』(2005 年 8 月 16 日 , Anchor, 336 ページ)
注 3 サンプルスクリプトは、twitteR 1.1.8 を使用しています。
注 4 サンプルスクリプトは、RMeCab 0.9993 を使用しています。
注 5 サンプルスクリプトは、wordcloud 2.4 を使用しています。
注 6 サンプルスクリプトは、RColorBrewer 1.1-2 を使用しています。
注 7 Daniel Kahneman『Thinking, Fast and Slow』(2012 年 5 月 10 日 , Penguin, 512 ページ)