業務でOpenSearchに関わる機会が増えてきたので基本的な勉強を始めてみました。いろいろな記事を参考にさせてもらってますが、基本的な単語を正しく理解できている必要があるので、自分なりにまとめておきます。
参考:https://opensearch.org/docs/latest/getting-started/intro/
Document
OpenSearchにおけるログのこと。一般的なサーバやアプリケーションが出力するログ一件に相当すると考えて良さそう。OpenSearchの公式では以下のような例で例えられている。
- 生徒のデータベースにおける、一人の生徒
- 従来の(リレーショナル)データベースにおける一行
OpenSearchでログを検索すると、関連するドキュメントを一件ずつ表示してくれます。
Index
Documentの一連の集合、と公式に書かれてますが、咄嗟にイメージしにくいように思います。どういう側面からの集合だ?と思ったんですが、公式の例えで大体わかりました。
- 生徒のデータベースにおける、全ての生徒
- 従来の(リレーショナル)データベースにおける、一つのテーブル
OpenSearchで検索をかけたとき、特定のインデックスの中にあるドキュメントを検索することになります。実際使ってみてわかりましたが、特定のトピックについてログの構造などを指定してインデックスを作成し、作成したインデックスに実際にログを集積していくことになります。
Clusters and nodes
何かしらクラスタを形成するプラットフォーム(KubernetsやKafka等)を使ったことがある人が想像するものそのままです。各ノードがログを集積し、検索処理を行います。このノードの集合がクラスタです。
OpenSearchはシングルノードで稼働することもできますが、将来的には複数のノードに分割することが望ましいようです。また、クラスタをコントロールするコントロールプレーン的なノードや、実際にログを集積し検索するワーカーノード的なノードなど、タイプ別に異なるノードを作成でき、それぞれのノードがサーバに求めるスペックも異なります。
Shards
Redisなどのシャードを形成するDBやプラットフォームを使ったことがある人が想像するものそのままと言っていいと思います。インデックスのドキュメントは各シャードに分割して保存されます。このとき、シャードは各インデックスごとに作成されることに留意が必要です。
例えばWebサーバのログを保存するインデックスとバックエンドのログを保存するインデックスが別々に存在する場合、全てのドキュメントをまとめて分割・保存するシャードが作成されるのではなく、Webサーバのインデックスのシャードが複数個、バックエンドのインデックスのシャードが複数個、それぞれ作成されます。
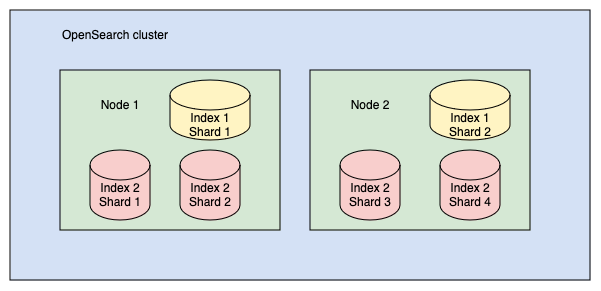
出典:https://opensearch.org/docs/latest/getting-started/intro/#shards
Primary and replica shards
OpenSearchはノード障害時のバックアップとして、各シャードのレプリカシャードを作成します。このレプリカは全てのシャードについて個別に作成されます。要するに何かしらのインデックスに10個のシャードがあれば10個のレプリカが作成されます。これらのレプリカはコピー元のシャードとは異なるノードに保存されます。
また、レプリカシャードは検索速度向上のためにも利用されます。