はじめに
環境
- 開発環境 - Windows 10
- 統合環境 - Visual Studio 2019
- 使用言語 - Python 3.7 (64-bit)
筆者について
- 私は10年以上金融商品取引に関するシステムの運用、保守、クライアントサポート業務に従事しています。
- 金融商品取引では、トレーダーの意思により決められたアルゴリズムでロボット取引が過去20年の間に盛んになっていました。しかし、最近多くの業者が推進しているのは、AIが相場を予測して取引する商品です。扱えるデータ量、計算速度、継続稼働能力、感情要因回避など、AIを駆使した技術を使えば、人の分析より高いパフォーマンスを期待できます。今回はドル円の相場を予測するモデルを作ってみることにしました。
- Java, VB, C++, PHPなど複数の言語またはDBを利用した経験はあり、今時のPythonも是非身につけたいのも今回Aidemy Premiumにて「データ分析コース」を3ヶ月受講した理由の一つです。
プロジェクト
概要
- FX(外国為替証拠金取引)は金融商品取引の一つで、月~金まで24時間取引が行われ、平日に休むことなく取引ができます。また、全世界が一つの市場となっており、規模が非常に大きいです。株や先物に比べると、取引できる時間が長く、チャートの連続性があり、仮想通貨に比べると取引量が多くて、歴史が長く、比較的に安定していると考えられています。
- 本プロジェクトは、10年分のUSDJPY(ドル円)の日足データに基づき、深層学習のモデルを使って、翌日の終値を予想させることで、所謂時系列予測です。観測された膨大な時系列データがあれば、ある時間範囲から未来の時刻を予測する、またある時間範囲から未来の時刻を予測するというように、時系列データから入出力データを切り出すだけで、学習のためのデータセットを構成できます。
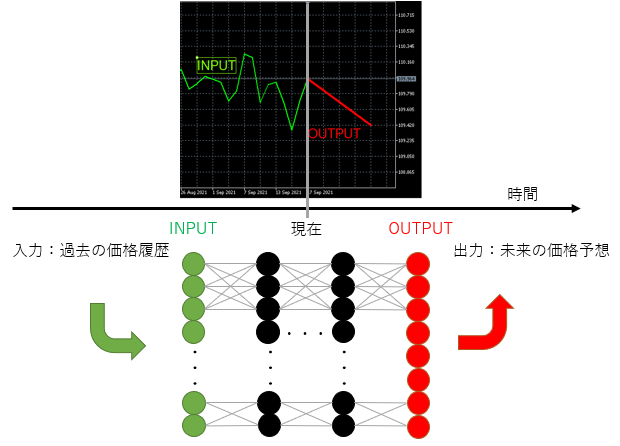
データ取得
MetaTrader 5をインストールして、デモ口座を開設し、USDJPYの過去データを入手できます。USDJPYの2011年09月20日から2021年09月20日の日足データを抽出して、CSVに出力します。
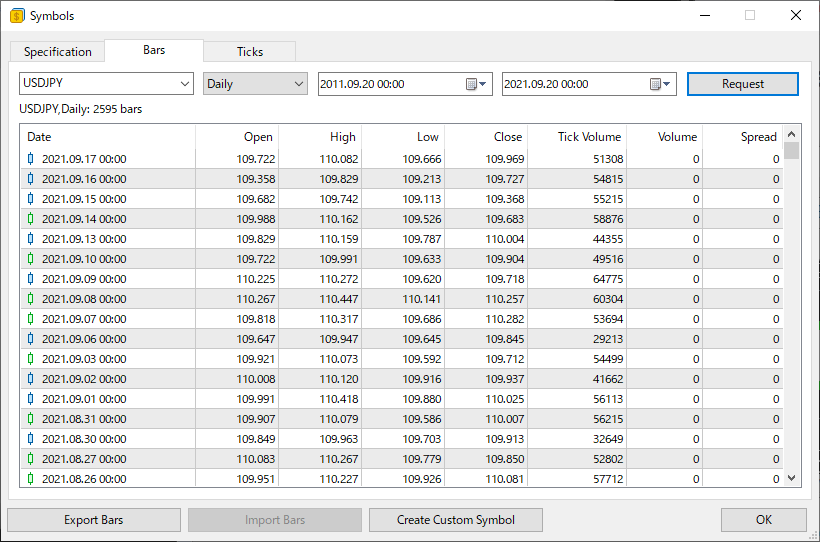
Date - 日付
Open - 始値
High - 高値
Low - 安値
Close - 終値
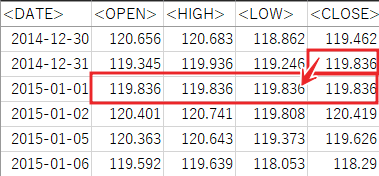
MetaTrader 5の日付やyyyy.mm.ddになっていますが、yyyy-mm-ddに直して、保存します。
クリスマスと年末年始が取引休止になる場合、前日の終値でその日のOHLCを埋めます。
データの前処理
- データの読み込み
import pandas as pd
df = pd.read_csv('.\\usdjpy_daily_201109200000_202109170000.csv', index_col="<DATE>",encoding="shift-jis",delimiter="\t", parse_dates=True)
df.index = pd.date_range("2011-09-20", "2021-09-17", freq="b")
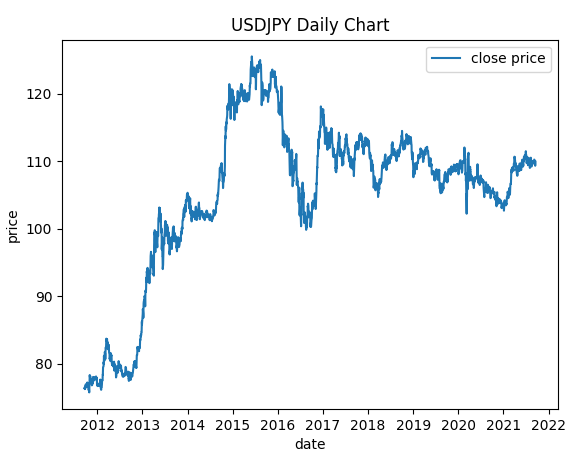
- 描画してデータを確認
# 描画
plt.title("USDJPY Daily Chart")
# グラフのx軸とy軸の名前設定
plt.xlabel("date")
plt.ylabel("price")
# データのプロット
plt.plot(df["<CLOSE>"], label="close price")
plt.legend()
plt.show()
訓練データ・テストデータの分割
- データの95%を訓練用で、5%は検証用にします。
close_price = df["<CLOSE>"]
test = close_price[:]
train = close_price[:int(len(close_price) * 0.7)]
データの整理
- 自己相関係数
import matplotlib.pyplot as plt
import statsmodels.api as sm
fig=plt.figure(figsize=(12,8))
ax = fig.add_subplot()
sm.graphics.tsa.plot_acf(close_price, lags=261,ax = ax)
plt.show()
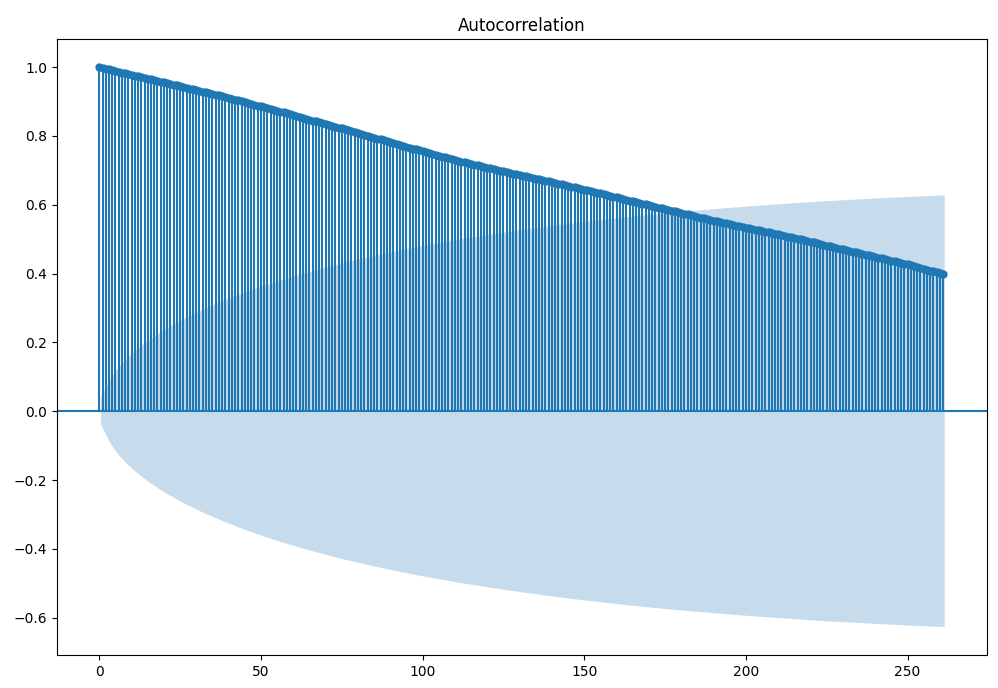
影の部分が95%信頼区間です。 大体180個前までのデータに大きく影響を受けていることが分かります。次に偏自己相関係数を求めます。
import matplotlib.pyplot as plt
import statsmodels.api as sm
fig=plt.figure(figsize=(12,8))
ax = fig.add_subplot()
sm.graphics.tsa.plot_pacf(close_price, lags=261,ax = ax)
plt.show()
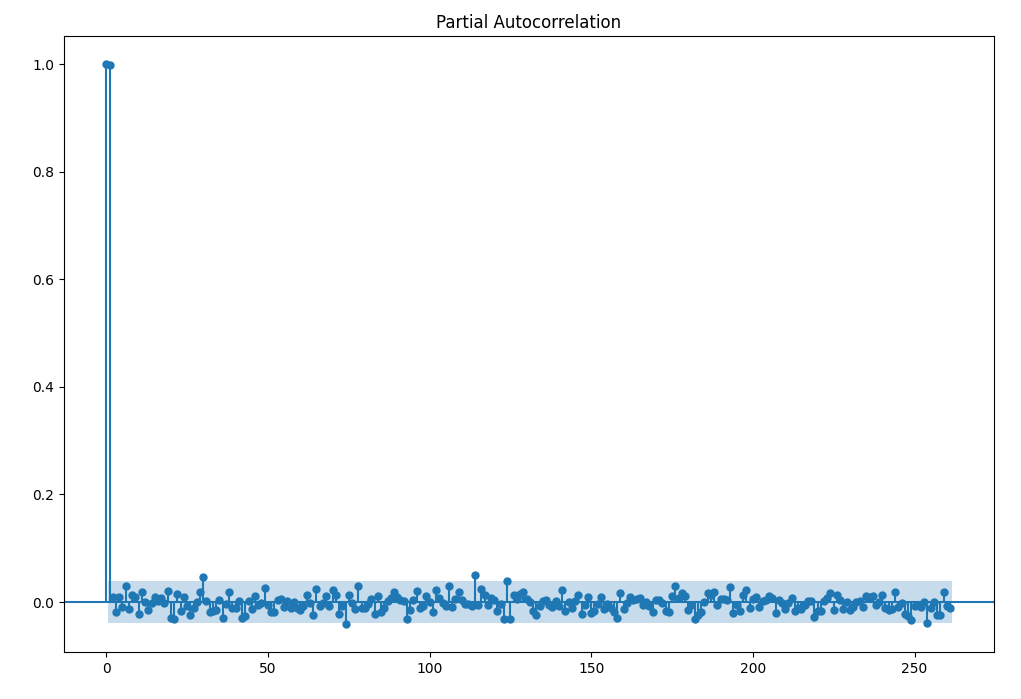
この結果を見て、左から1と30番目のデータが影響を与えていることがわかります。
- データパターン
sm.tsa.seasonal_decompose(close_price, freq=261).plot()
plt.show()
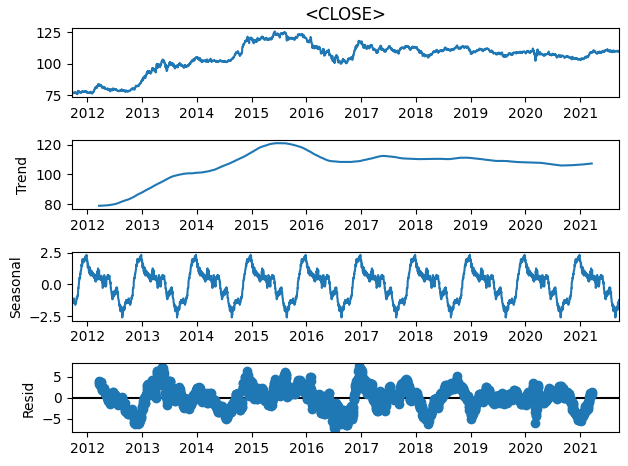
機械学習モデル
-
以下の基本的な時系列モデルがありますが、為替の価格変動は時間や季節の要因で動くものではないが、経済指標の発表やニュースイベントに影響される金融商品ではありますが、今回は筆者の練習という観点からシンプルなSARIMAモデルを採用しました。
- AR(自己回帰モデル)
- MA(移動平均モデル)
- ARMA(自己回帰移動平均モデル)
- ARIMA(自己回帰和分移動平均モデル)
- SARIMA(季節自己回帰和分移動平均モデル)
-
SARIMAの引数を選択
max_p = 3
max_q = 3
max_d = 2
max_sp = 1
max_sq = 1
max_sd = 1
pattern = max_p*(max_d + 1)*(max_q + 1)*(max_sp + 1)*(max_sq + 1)*(max_sd + 1)
modelSelection = pd.DataFrame(index=range(pattern), columns=["model", "aic"])
+ 自動SARIMA選択
num = 0
for p in range(1, max_p + 1):
for d in range(0, max_d + 1):
for q in range(0, max_q + 1):
for sp in range(0, max_sp + 1):
for sd in range(0, max_sd + 1):
for sq in range(0, max_sq + 1):
sarima = sm.tsa.SARIMAX(
train, order=(p,d,q),
seasonal_order=(sp,sd,sq,30),
enforce_stationarity = False,
enforce_invertibility = False
).fit()
modelSelection.loc[num]["model"] = "order=(" + str(p) + ","+ str(d) + ","+ str(q) + "), season=("+ str(sp) + ","+ str(sd) + "," + str(sq) + ")"
modelSelection.loc[num]["aic"] = sarima.aic
num = num + 1
print(modelSelection.sort_values(by='aic').head())
ARMAでしたら、自動的に最適引数を選択してくれる関数がありますが、SARIMAだと引数が多くて、デフォルトで用意されていません。このように自作のものになります。あまり対象範囲を広げると、実行するにはかなりの時間がかかってしまうため、適度に設定しました。
model aic
249 order=(3,1,3), season=(0,0,1) 3341.482795
185 order=(2,2,3), season=(0,0,1) 3341.486526
252 order=(3,1,3), season=(1,0,0) 3342.516918
281 order=(3,2,3), season=(0,0,1) 3343.225979
41 order=(1,1,1), season=(0,0,1) 3343.348783
このように、aicが一番小さいのはorder=(3,1,3), season=(0,0,1)という結果がでました。
- モデルの作成
SARIMA_usdjpy = sm.tsa.statespace.SARIMAX(train,order=(3,1,3),seasonal_order = (0,0,1,30)).fit()
- 予測値の算出
prediction = SARIMA_usdjpy.predict()
forecast = SARIMA_usdjpy.forecast(steps=261)
予測値の可視化
import matplotlib.pyplot as plt
from matplotlib import rcParams
import datetime
import matplotlib.dates as mdates
plt.title("USDJPY Daily Training")
sxmin='2015-04-01'
sxmax='2021-09-17'
xmin = datetime.datetime.strptime(sxmin, '%Y-%m-%d')
xmax = datetime.datetime.strptime(sxmax, '%Y-%m-%d')
plt.xlim([xmin,xmax])
plt.ylim([90,130])
plt.plot(test, color = "b")
plt.plot(prediction, label="prediction", color = "r")
plt.plot(forecast, label="forecast", color = "y")
plt.legend()
plt.show()
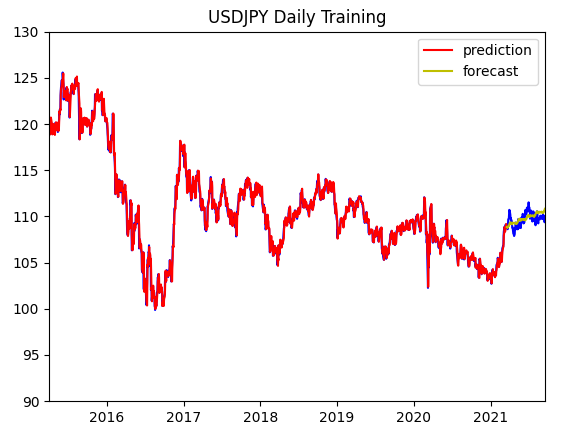
青は実際のデータ、赤は学習したデータで、黄は予想になっています。
ピッタリではありませんが、今年度のドル円トレンドを予想できたではないかと思います。
考察
2020年3月に金融市場に起きたコロナショックがチャートに大きなギャップを描いています。
それ以降のチャートで、拡大してみましょう。
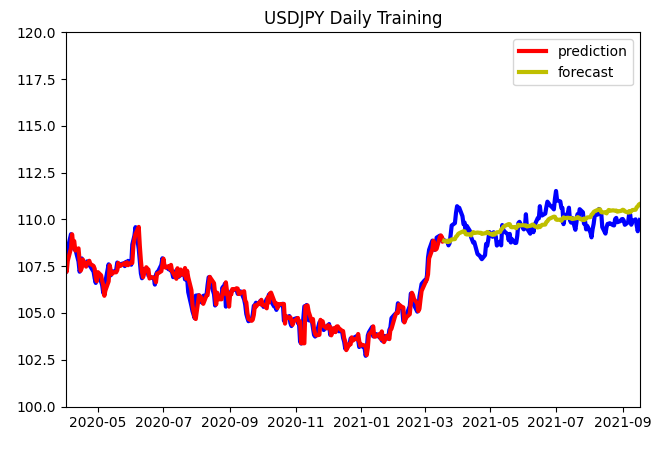
緩やかな上昇トレンドはある程度予想できていると思いますが、上下の波はなく、精度を上げる余裕が沢山あるようです。
パラメタを調整してみました。
SARIMA_usdjpy = sm.tsa.statespace.SARIMAX(train,order=(0,1,0),seasonal_order = (1,1,1,120)).fit()
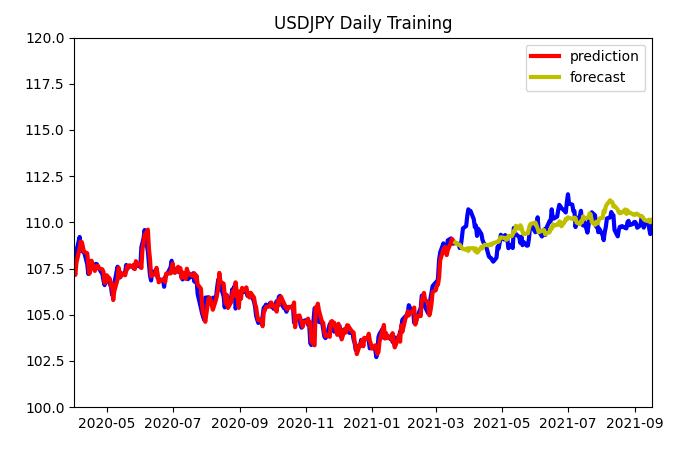
このようにちょっと改善されたようですね。
学習の期間、回数、モデルのパラメタの最適化を行えば、精度をもっと高められるだろうと思います。
おわりに
- こころえ
筆者はプログラムの経験があるとはいえ、Pythonと統計学の初心者です。
ここで、学んだ時系列分析の知識をいかして、SARIMAを使ったドル円相場のトレンド予想をしてみました。
独学より、期間を設けて、相談相手のチューターがいて、助言や評価してくれる形で勉強したほうが効率的でした。
- 今後の展望
実際に為替の分析には経済指標イベント、ニュース、他の金融商品との関連性などの要因がありますので、このトレンド予想の精度を高めるために、より優秀なモデリングを探ったり、他の要因を加えて、例えばニュースのテキスト分析や経済指標のデータ分析と予想、他の金融商品の値動きとの連動を分析できるようになったら、優れたトレーディングAIができるでしょう。
弊社の業務上では、Pythonを使ってデータ分析することはすくないが、Pythonを利用しているシステムが増えており、弊社の製品とインターフェースするなど、連携する場面が出てきました。
これで、Pythonを使った相手のシステムの立場で提案したり、助言したりできるようになると思います。