目次
1.はじめに
2.確認環境
3.ファイル構成
4.trainとvalディレクトリの中身について
[5.Google Colaboratoryの始め方](#5-Google Colaboratoryの始め方)
6.Googleドライブにマウント(接続)
7.Webから画像を収集
8.学習データとテストデータの作成
9.学習データとテストデータをそれぞれ確認
10.作成したデータで転移学習
11.モデルをテスト
12.学習結果を出力
13.作ったモデルを試してみましょう!(1)
14.作ったモデルを試してみましょう!(2)
15.Flaskを使ってWebアプリを制作
16.考察
17.参考にさせて頂いた記事・サイト
1. はじめに
これはプログラミングスクールのアイデミーさんに提出する為の記事です。
・どんな人に読んで欲しいか
NVIDIA製のGPUが使えないけど機械学習をしたい人。
学習用の画像データを既に自分で用意して簡単な機械学習を体験したい人。
機械学習はどんな感じか流れを確認したい人。
・この記事で分かる事
Google Colaboratoryだけでスクレイピングを使ってデータを集め、
オリジナルデータセットを制作して、
VGG16の転移学習を使ったCNNモデルの2クラス分類を作ってFlaskでWebアプリを作れます。
2. 確認環境
Google Colaboratory
3. ファイル構成
ファイルはGoogleドライブに保存された状態で以下のファイル構成・名前になっていることが前提で進みます。
※実行するだけで画像と同じファイル構成になるコードが後ほどあるので作ろうと思った方はこのまま進んでください。

学習データ(train)とテストデータ(val)は分けて扱います。2クラス以上にしたい場合は、
trainとvalディレクトリにClass_3、Class_4...と追加します。
ですが、今回は多クラス分類については触れませんのでご了承ください。
4. trainとvalディレクトリの中身について
Yahooの画像検索でスクレイピングをするコードが後ほどあります。
それで集められた画像を1クラスを大体(train)9:(val)1になるように振り分けてください。
今回の様な勉強や練習の為のデータ収集は問題無いと思いますが、応用する際には以下の引用させて頂いたスクレイピングの記事を見たり、スクレイピングするサイトの利用規約を確認してから扱って下さい。
今回使ったデータを参考に載せておきます。
train/class_1の中身(一部)
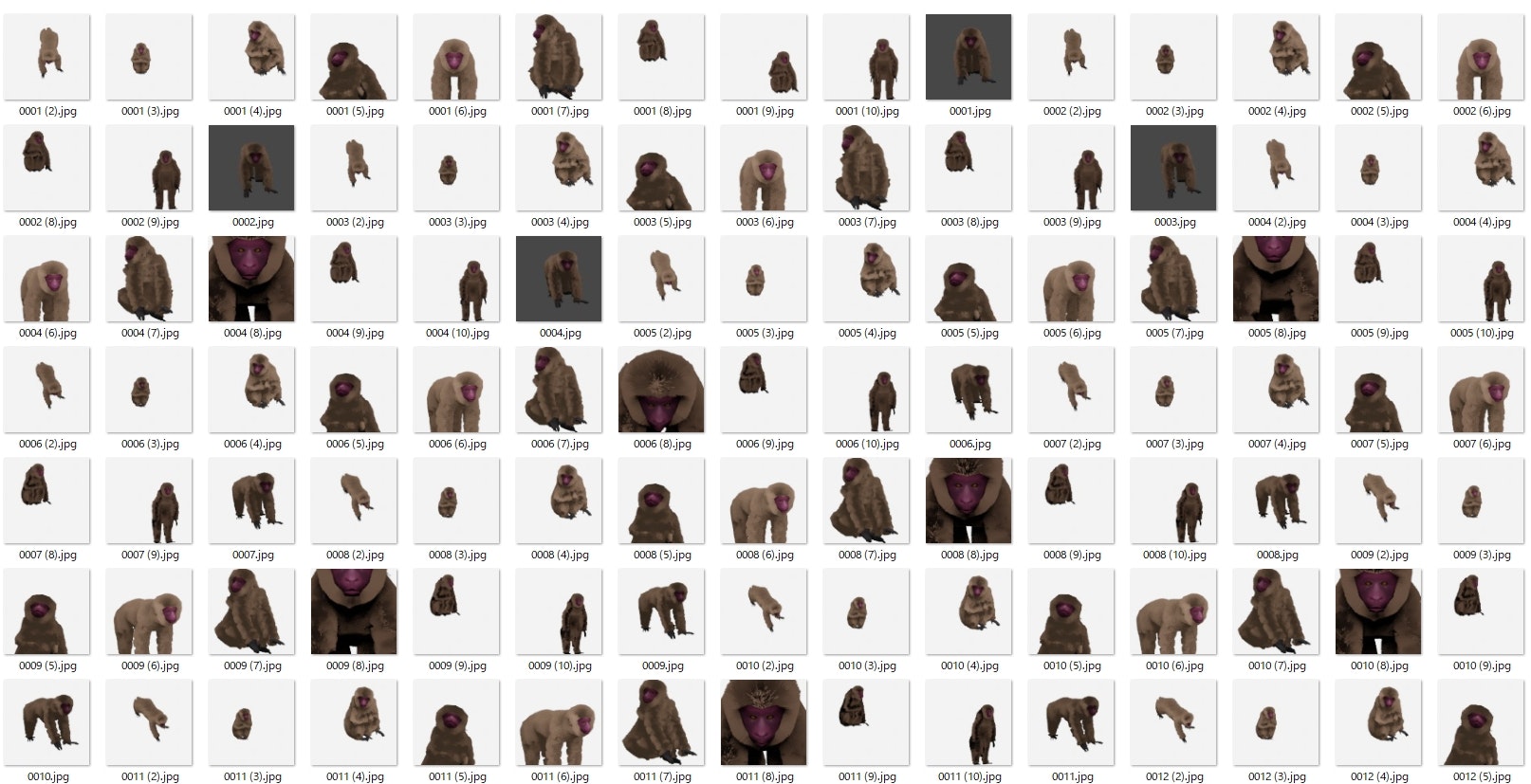
ファイル数: 1,038
train/class_2の中身(一部)

ファイル数: 1,001
3Dモデリングツール(blender)を使用して制作したモデルをレンダリングして出力したものをそのまま使用しています。
何故このような2クラス分類になったかというと、
本当は多クラス分類で猿と猪と鹿を分類するモデルを作ろうとしたのですが、
猿の3Dモデルを作った段階で締め切りに間に合わなくなる予感があったので諦めて以前に作ったブタの貯金箱を利用しました。
ファイル数は1000枚程度が良いとチューターの方に指示されたので従いました。
今回はtrainデータの取得方法については省略します。
val/class_1の中身(一部)

ファイル数: 116
val/class_2の中身(一部)
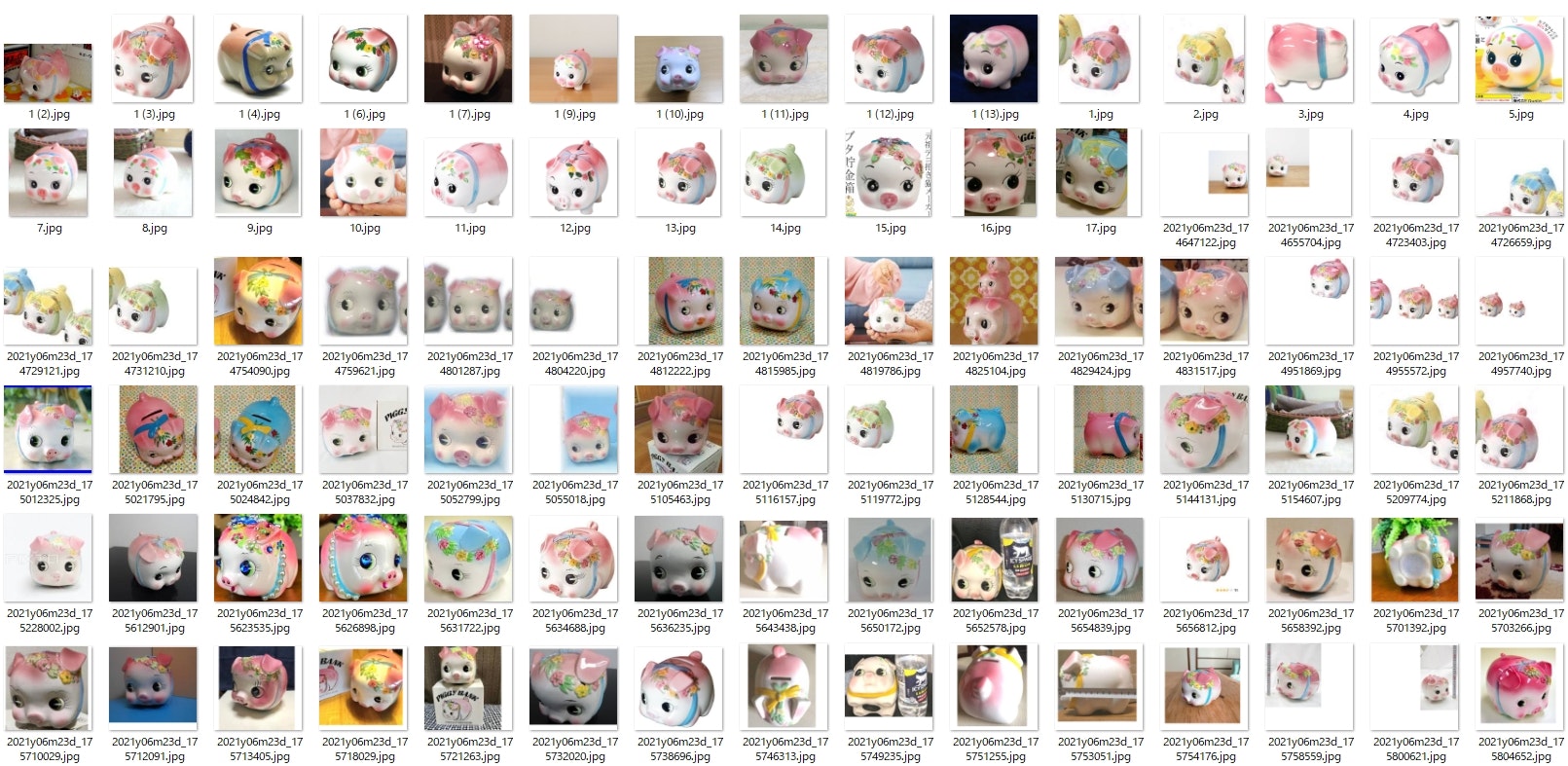
ファイル数: 143
スクレイピングを使用して集めました。
データセットを作る過程でリサイズされるのでそのままフォルダに入れています。
この様なデータにした理由は、
機械学習は画像が本物かどうかを見ているのではなく、
データの特徴を抽出していると学んだので特徴が似ている偽物を用意したら本物を認識できるのではないかと思ったからです。
学習データを3Dモデルで作成したものを撮影して画像化したものを使って、
テストデータをスクレイピングで集めた画像を扱いました。
結果はある程度識別できるようになったので良かったのかなと思います。
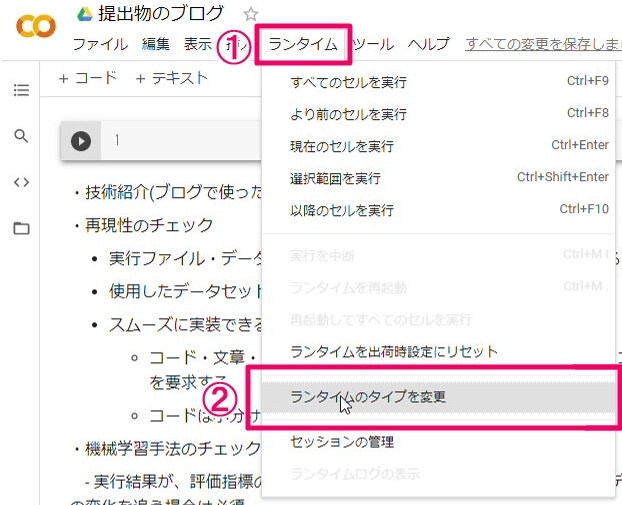
5. Google Colaboratoryの始め方
初心者の方の為にGoogle Colaboratoryの始め方の画像を貼っておきます。
あの時の私のように困る人が居なくなればいいと思います。
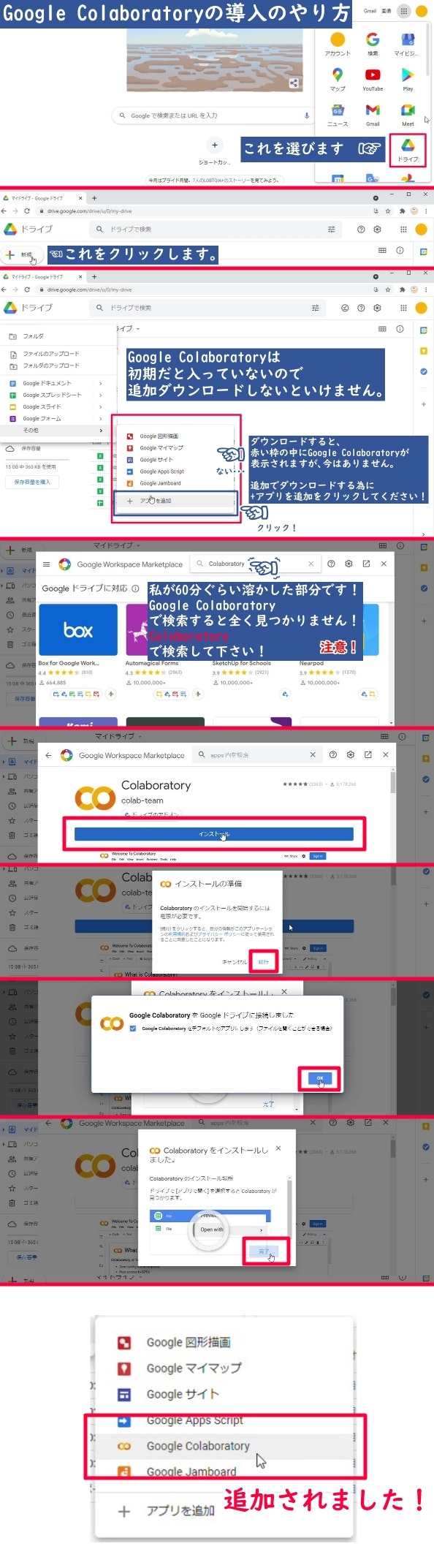
では、Google Colaboratoryをクリックして始めていきましょう。
6. Googleドライブにマウント(接続)
これから書かれているコードのブロックでセル1つ分になります。
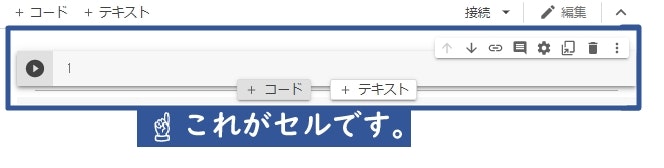
まずはこのコードを実行してGoogleドライブにマウント(接続)します。
セルを選択した状態で Ctrl + Enter でプログラムを実行したり、
画像にある +コード というボタンを押すとセルが増えます。
実行した後に増えたセルに次のプログラムをコピペしていくと良い感じになります。
# Googleドライブから画像やファイルを読み込む時に使います。
from google.colab import drive
drive.mount('/content/drive')
実行した後に(初回はGoogleドライブのファイルへのアクセスを許可してください。)
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
と表示されます。これで準備が出来ました。
この表示された結果の部分がプログラムを実行した結果や、エラーの内容が表示されます。
7. Webから画像を収集
クローリングとスクレイピングは以下の動画とサイトを引用しています。
# スクレイピングをするのに必要なライブラリをダウンロードします。
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
!pip install selenium
from selenium import webdriver
from time import sleep
import pandas as pd
import os
import requests
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--incognito')
①ダウンロードが終わったら早速画像を集めてみましょう。
# スクレイピングしたい画像の名前を入力してください。
# Googleの画像検索に入力するワードになります。
# 保存するファイルの名前にもなります。
# ""は消さないでその中に検索する文字を入力してください。
search_name = "ブタの貯金箱"
たくさん画像を集めるので少し時間が掛かります。
コードにあるsleepは画像を取得するサイトに迷惑をかけない為のものです。
消さないで下さい。
driver = webdriver.Chrome('chromedriver',options=options)
driver.implicitly_wait(10)
driver.get("https://search.yahoo.co.jp/image")
sleep(3)
search_box = driver.find_element_by_class_name("SearchBox__searchInput")
search_box.send_keys(search_name)
search_box.submit()
file_name = search_name
sleep(3)
height = 1000
while height < 10000:
driver.execute_script("window.scrollTo(0,{});".format(height))
height += 100
sleep(1)
# 画像の要素を選択する
elements = driver.find_elements_by_class_name("sw-Thumbnail")
search_list = []
# 要素からURLを取得する
for i,e in enumerate(elements, start=1):
name = f'{file_name}_{i}'
image_url = e.find_element_by_tag_name('img').get_attribute('src')
d = {"filename": name,"image_url": image_url}
search_list.append(d)
sleep(3)
df = pd.DataFrame(search_list)
# 画像を抽出する為のCSVを出力します。
df.to_csv(search_name + ".csv")
# ブラウザーを閉じます。
driver.quit()
# CSVの読み込みをします。
df = pd.read_csv(search_name + ".csv")
os.makedirs('/content/drive/MyDrive/'+ search_name +'/')
# 作成したディレクトリに画像を保存します。
for save_name,image_url in zip(df.filename[:100],df.image_url[:100]):
image = requests.get(image_url)
with open('/content/drive/MyDrive/' + search_name +'/' + save_name + ".jpg","wb") as f:
f.write(image.content)
sleep(3)
終わったらGoogleドライブに入力した名前と同じフォルダが出来たと思うので、そのフォルダの中から学習用の画像とテスト用の画像に仕分けましょう。
これでClass_1の画像データを集めました。
Class_2の分の画像を集める為に①に戻ってスクレイピングしたい画像の名前を入力して実行してください。
ですが、検索した中に学習して欲しいものが映っていない事があるので、それらは取り除いてください。
今回は画像を100枚くらいを扱うのを想定しています。
消しすぎて100枚以下になったら①の検索ワードを変えて集めてください。少し多いのは大丈夫です。
8. 学習データとテストデータの作成
学習データの作成からモデルの出力は以下の記事とサイトを引用しています。
・Keras Documentation
https://keras.io/ja/
https://keras.io/ja/layers/core/
https://keras.io/ja/applications/#vgg16
https://keras.io/ja/getting-started/sequential-model-guide/
https://keras.io/ja/models/about-keras-models/
先程の画像で示したファイル構成になるコードです。
ファイル構成の通りに作って頂ければコピペですべて動きますが、
中身は空なので画像の用意をしましょう。
import os
path = "/content/drive/MyDrive/ColaboratoryApri"
os.mkdir(path)
pass_list = ["/TestFire","/Uploads","/train","/val","/train/class_1","/train/class_2","/val/class_1","/val/class_2"]
for path1 in pass_list:
os.mkdir(path+path1)
先程の画像を使うのであれば、
大体、画像が100枚あれば、90枚が学習用(train)で10枚がテスト用(val)になります。
頑張ってください。
学習の処理を速くする為にランタイムのタイプをGPUにします。
後から変更すると作業が初めからになるので注意しましょう。

まずは学習データの作成をしてから作成したデータの中身をみましょう。
大体の説明はコードのコメントに書いてあります。
勉強を始めた頃の自分が見ても確実に動かせるものを目指しているので、
既にご存じの方には鬱陶しいかもしれませんが、大目に見て下さると嬉しいです。
# 学習データとテストデータの作成に使用します。
from keras.preprocessing.image import ImageDataGenerator
# テスト結果表示用
import matplotlib.pyplot as plt
以下のコードは学習とテストデータに使う為の基本情報を入れます。
グレーで読み込んだり、2クラス以上の分類にする場合はコメントアウトをする等で修正してください。
# 保存するモデルの名前です。
model_name = 'original_model'
# 分類したいもの。trainとvalに入れたファイルの名前と揃えてください。
classes = ['class_1', 'class_2']
# 分類したいもの(classes)と同じ数にします。
class_number = 2
# 親ディレクトリです。末尾に/は付けないでください。
root_dir = '/content/drive/MyDrive/ColaboratoryApri'
# 学習用のデータが入っているディレクトリです。
train_data_dir = '/content/drive/MyDrive/ColaboratoryApri/train'
# テスト用のデータが入っているディレクトリです。
val_data_dir = '/content/drive/MyDrive/ColaboratoryApri/val'
# 学習データとテストデータのディレクトリに入っている画像の高さと幅を入力した数値にリサイズする為の変数です。
# なので、事前にリサイズはしなくても大丈夫です。(トリミングは扱いません。)
data_size = 128
# 学習で使う時に処理するデータの件数です。(この場合は一回の学習で16件のデータを使う)
batch_size = 16
batch_size = 2
# 分類するclassの数。2つは'binary'。3つ以上の場合は、'categorical'
class_mode = 'binary'
# class_mode = 'categorical'
# 2クラス用の損失関数です。2クラス以上は'categorical_crossentropy'をコメントアウトしてください。
loss = 'binary_crossentropy'
# loss = 'categorical_crossentropy'
# カラー画像を扱う場合は'rgb'を選んでください。グレーの場合、'grayscale'をコメントアウトしてください。
color_mode = 'rgb'
# color_mode = 'grayscale'
学習用のデータとテスト用のデータを作成します。
# 学習用のデータを作成します。
train_datagen = ImageDataGenerator(
rotation_range=360.0,
width_shift_range=30.0,
height_shift_range=30.0,
channel_shift_range=100.0,
fill_mode="constant",
rescale= 1.0 / 255,
)
# 学習用のgeneratorを設定します。
train_generator = train_datagen.flow_from_directory(
directory = train_data_dir, #学習用のデータが入っているディレクトリです。
target_size = (data_size, data_size), #画像の高さと画像の幅を指定したサイズにリサイズします。
color_mode = color_mode, #グレーの場合、'grayscale'と入力します。
classes = classes, #分類したいもの
class_mode = class_mode, #分類するclassの数。2つは'binary'。3つ以上の場合は、'categorical'にして下さい。
batch_size = batch_size, #バッチサイズ。デフォルトは32です。
shuffle = True, #シャッフル。デフォルトはTrueです。
seed = None, #疑似乱数です。
)
# テスト用のデータを作成します。
val_datagen = ImageDataGenerator(
rotation_range=360.0,
width_shift_range=30.0,
height_shift_range=30.0,
channel_shift_range=100.0,
fill_mode="constant",
rescale= 1.0 / 255,
)
# テスト用のgeneratorを設定します。
val_generator = val_datagen.flow_from_directory(
directory = val_data_dir, #テスト用のデータが入っているディレクトリです。
target_size = (data_size, data_size), #画像の高さと画像の幅を指定したサイズにリサイズします。
color_mode = color_mode, #グレーの場合、'grayscale'と入力します。
classes = classes, #分類したいもの
class_mode = class_mode, #分類するclassの数。2つは'binary'。3つ以上の場合は、'categorical'にして下さい。
batch_size = batch_size, #バッチサイズ。デフォルトは32です。
shuffle = True, #シャッフル。デフォルトはTrueです。
seed = None, #疑似乱数です。
)
実行すると以下のような出力結果が出てきます。

ImageDataGeneratorの形は以下のようになっています。色々試してみてください。
(良く分からない引数は除きました。)
ImageDataGenerator(
featurewise_center=False, #データセット全体で、入力の平均を0にします。
samplewise_center=False, #各サンプルの平均を0にします。
featurewise_std_normalization=False, #入力をデータセットの標準偏差で正規化します。
samplewise_std_normalization=False, #各入力をその標準偏差で正規化します。
zca_whitening=False, #ZCA白色化のイプシロン。
zca_epsilon=1e-06, #ZCA白色化のイプシロン.デフォルトは1e-6です。
rotation_range=0.0, #指定した数値(x)の±(x)px範囲でランダムに回転にします。
width_shift_range=0.0, #指定した数値(x)の±(x)px範囲でランダムに左右方向移動にします。
height_shift_range=0.0, #指定した数値(x)の±(x)px範囲でランダムに上下方向移動にします。
brightness_range=None, #明るさをランダムに変更
shear_range=0.0, #シアー強度
zoom_range=0.0, #ランダムにズームします。
channel_shift_range=0.0, #指定した数値(x)の±(x)の範囲で色調を変更せずに明度を変化させます。
fill_mode='nearest', #縮小や回転で出来た余白をどうやって埋めるか指定します。 "constant", "nearest", "reflect" or "wrap"があります。
cval=0.0, #fill_mode = "constant"のときに境界周辺で利用される値
horizontal_flip=False, #水平方向に入力をランダムに反転します。
vertical_flip=False, #垂直方向に入力をランダムに反転します。
rescale=None, #生成されるテンソルを0~1の範囲に正規化します。(とりあえず動かしたい時はこれだけで他をコメントアウトしてください。)
これでデータの準備が出来ました。
中身がどんな風になっているか学習データとテストデータをそれぞれ確認してみましょう。
9. 学習データとテストデータをそれぞれ確認
成功したらこんな感じに出力されます。

個人的な話ですが、学習結果が伸びなくなった時がありました。
何でなのかさっぱり分からなかったのですが、その時はこんな風に確認しなかったのでパラメーターをいじりすぎていたのでとんでもない画像が出てきたのは良い思い出です。
なので、弄った場合は一応、確認した方が良いと思います。
# 表示用に取り出すバッチサイズを1にします。
batch_size_show = 1
# 学習用の画像の結果を確認します。
print("学習用データ")
# 表示用に別のgeneratorを用意します。違いは代入する名前がtrain_generatorではなく、train_generator_showになっている事だけです。
# もし、train_generatorを変更していた場合は結果が変わってしまうので揃えてください。
train_generator_show = train_datagen.flow_from_directory(
train_data_dir,
target_size = (data_size, data_size), #画像の高さと画像の幅を指定したサイズにリサイズします。
color_mode = color_mode, #グレーの場合、'grayscale'と入力します。
classes = classes, #分類したいもの
class_mode = class_mode, #分類するclassの数。2つは'binary'。3つ以上の場合は、'categorical'にして下さい。
batch_size = batch_size_show, #バッチサイズ。デフォルトは32です。
shuffle = True, #シャッフル。デフォルトはTrueです。
seed = None, #疑似乱数です。
)
# 表示用として画像とラベルを格納するリストを用意します。
imgs_1 = []
labbels_1 = []
# rangeの引数は表示させたい枚数です。
for i in range(50):
x,y = train_generator_show.next() #next()でgeneratorの要素を順番に取り出します。
imgs_1.append(x[0])
labbels_1.append(y)
# generatorクラスのクラス分類確認
print(train_generator_show.class_indices)
# 表示設定
fig = plt.figure(figsize=(12,12))
fig.subplots_adjust(hspace=0.5, wspace=0.5)
row = 10
col = 10
for i, img in enumerate(imgs_1):#インデックス番号, 要素をenumerateで取得できます。
plot_num = i+1
plt.subplot(row, col, plot_num,xticks=[], yticks=[])
plt.imshow(img)
plt.title('%d' % labbels_1[i])
plt.show()
print("*****************************************************************")
# テスト用の画像の結果を確認します。
print("テスト用データ")
val_generator_show = val_datagen.flow_from_directory(
val_data_dir,
target_size = (data_size, data_size), #画像の高さと画像の幅を指定したサイズにリサイズします。
color_mode = color_mode, #グレーの場合、'grayscale'と入力します。
classes = classes, #分類したいもの
class_mode = class_mode, #分類するclassの数。2つは'binary'。3つ以上の場合は、'categorical'にして下さい。
batch_size = batch_size_show, #バッチサイズ。デフォルトは32です。
shuffle = True, #シャッフル。デフォルトはTrueです。
seed = None, #疑似乱数です。
)
# 表示用として画像とラベルを格納するリストを用意します。
imgs_2 = []
labbels_2 = []
# rangeの引数は表示させたい枚数です。
for i in range(50):
x,y = val_generator_show.next() #next()でgeneratorの要素を順番に取り出します。
imgs_2.append(x[0])
labbels_2.append(y)
# generatorクラスのクラス分類確認
print(val_generator_show.class_indices)
# 表示設定
fig = plt.figure(figsize=(12,12))
fig.subplots_adjust(hspace=0.5, wspace=0.5)
row = 10
col = 10
for i, img in enumerate(imgs_2):#インデックス番号, 要素をenumerateで取得できます。
plot_num = i+1
plt.subplot(row, col, plot_num,xticks=[], yticks=[])
plt.imshow(img)
plt.title('%d' % labbels_2[i])
plt.show()
10. 作成したデータで転移学習
良い感じに画像を作成したら早速使ってみましょう。
今回は転移学習ですが、いつかは自力で組んでみたいです。
# データ解析の手法
from keras.models import Sequential, Model
# 深層学習に使うレイヤー(層)
from keras.layers import Dense, Flatten, Input, Dropout
# 畳み込み13層と全結合層3層で出来た16層のニューラルネットワーク
from keras.applications.vgg16 import VGG16
#最適化アルゴリズム
from keras.optimizers import Adam
from tensorflow.keras import optimizers
# 2.作成したデータをテスト
#モデルの入力画像として利用するためのオプションのKerasテンソル。
input_tensor = Input(shape=(data_size, data_size, 3))
# VGGのロード部分。
vgg16 = VGG16(include_top=False, #全結合層。転移学習では不要なので、False。
weights='imagenet', #Noneでランダム初期化。'imagenet'はImageNetで学習した重みになります。
input_tensor=input_tensor, #モデルの入力画像として利用するためのオプションのKerasテンソルです。
)
model = Sequential()
# Flattenは入力を1次元ベクトルに変換して次元削減します。バッチサイズに影響を与えません。
model.add(Flatten(input_shape=vgg16.output_shape[1:]))
# 入力値が0以下は出力値が常に0、入力値が0より上の時は出力値が入力値と同じ値になります。
model.add(Dense(256, activation='relu'))
# 精度を上げる為に一部のニューロンを無効化します。
model.add(Dropout(0.5))
# 0~1の間を出力します。
model.add(Dense(1, activation='sigmoid'))
# 入力はvgg.input, 出力は, modelにvgg16の出力を入れたものです。
vgg16_model = Model(inputs=vgg16.input, outputs=model(vgg16.output))
# 最後のconv層の直前までの層を凍結する(凍結:学習から省く)
for layer in vgg16_model.layers[:10]:
layer.trainble=False
# コンパイル(まだモデルのファイルは出力されません。次で作成されます。)
vgg16_model.compile(loss=loss,
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9, decay=0.0, nesterov=False),
metrics=['accuracy'])
以下の出力結果が出てくれば大丈夫です。

Vgg16のダウンロードをした結果が出ているだけなので、何度かモデルを作り直していたら結果は表示されません。
11. モデルをテスト
モデルをテストします。
これを上手く出力できれば精度が良いかは別ですが、モデルは一応完成です。
このコードの下に出力の見本画像を貼っておきますので、何かおかしいと思った時に比べてみてください。
# コールバック用
from keras.callbacks import EarlyStopping,ModelCheckpoint
steps_per_epoch = train_generator.n
validation_steps = val_generator.n
# Epoch数の設定。後述のEarlyStoppingがあるので、このままで大丈夫です。
nb_epoch = 1000
# コールバックの設定
# patienceの数字だけval_lossが更新しなければ自動停止します。
es = EarlyStopping(monitor='val_loss', patience=10, verbose=1)
# save_best_onlyでlossを更新したときにモデルを保存します。(ここでモデルのファイルが作成されます。)
cp = ModelCheckpoint(filepath = root_dir + model_name + '.hdf5', save_best_only=True)
# CNN学習開始。fit_generatorを使用します。
history = vgg16_model.fit(
train_generator,
steps_per_epoch = steps_per_epoch // batch_size,
epochs = nb_epoch,
verbose=1,
validation_data=val_generator,
validation_steps = validation_steps // batch_size,
callbacks=[es, cp])
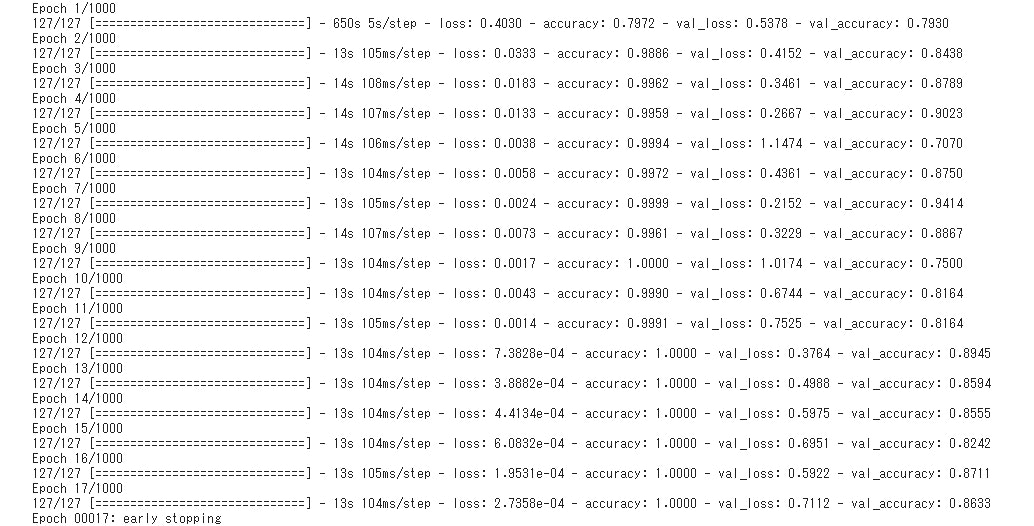
eary stoppingが出たら無事完了です。
Epochの数の決まり方はtrainのFound÷batch_sizeなので上は2039÷16=127.4375になります。
小数点は切り捨てになるみたいなので127になるようです。
数字を変えると色々と学習結果が変わるので試してみましょう。
バッチサイズは2のべき乗にするのが良いそうなので、16.32.64.128辺りで試すと良いかもしれません。
今回一番いい結果になったモデルのバッチサイズは128でした。
(下の画像です。先程の式でEpochの数が15になるか電卓を叩いて確認してみるとEpochの数の感覚がつかみやすいかもしれません。)

もし、ValueError: Expect x to be a non-empty array or dataset.というエラーが出たら、
モデルに使った画像の枚数に対してバッチサイズが大きすぎると出るので気を付けてください。
これでとりあえずモデルは完成しました。 では、学習結果を出力してみましょう!
12. 学習結果を出力
# エラーが出たらprint(history.history)で名前を確認しましょう。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# 'r'を'bo'にすると下の見本みたいな出力になります。
plt.plot(epochs, acc, 'r', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'r', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
いかがだったでしょうか。狙った結果が出たら良いですね。
参考になりにくいと思いますが、ついでに私が出力したモデルのグラフを付けておきます。
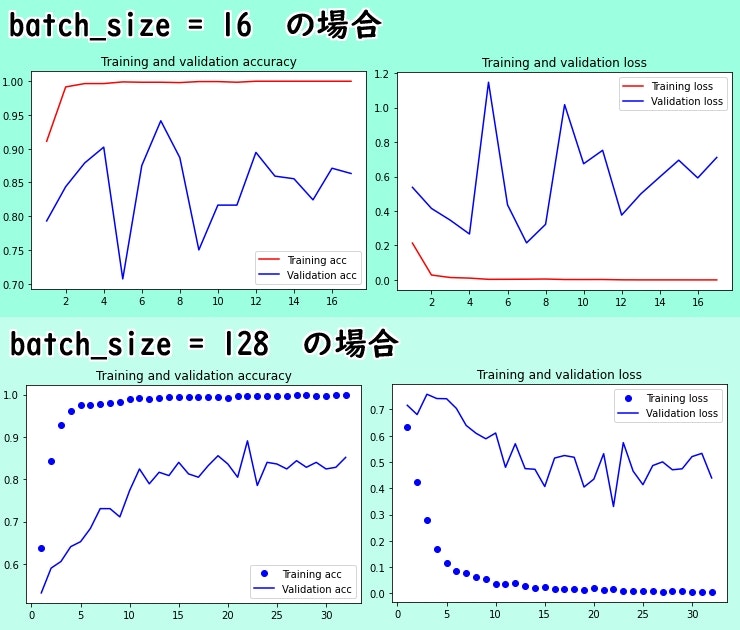
学習データとテストデータが違い過ぎるのであんまりきれいなグラフではありませんが、過学習はしていないので大丈夫です。
今回は2クラスのどちらかが分かればそれで良いのです。
13. 作ったモデルを試してみましょう!(1)
学習・テストデータに使っていない画像データを使ってモデルを確認します。
TestFireに判別したい画像を入れてください。
使用したデータを使うと確認する意味が無いので注意しましょう。
まずは必要なモジュールなどをインストールします。
# ここから下はこのセルを実行したらColaboratoryを再起動した時にも全部動きます。
from tensorflow.python.keras.models import load_model
import numpy as np
from keras.preprocessing.image import load_img,img_to_array, array_to_img, save_img
import matplotlib.pyplot as plt
from keras import backend as K
import glob
import cv2
from IPython.display import display_png
# 何個かモデルを作った時にテストが出来ます。
# このセルで読み込んだモデルをテストします。
model=load_model('/content/drive/MyDrive/ColaboratoryApri/original_model.hdf5')
# モデルが読み込めているか確認
model.summary()
読み込めたら以下のような出力がされます。

# フォルダの中に入っている画像をまとめてテストします。読み込みたいファイルを指定して下さい。
file_name = "/content/drive/MyDrive/ColaboratoryApri/TestFire" + "/*" #末尾の/*を消さないようにしてください。
files = glob.glob(file_name)
img_shape = (128, 128, 3)
一枚ずつは面倒なので一気に調べてしまいましょう。
テストしたい画像をTestFireに入れておくのを忘れないで下さい。
忘れていたら画像を入れてから上のセルをもう一度実行してください。
上手く行くと以下のような出力がされます。
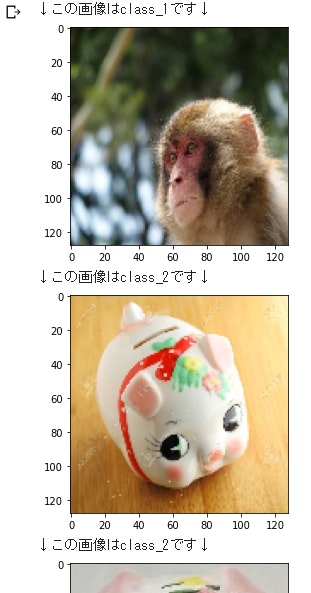
# クラスを判定します。
# 3クラス以上はelifで適当に増やしてください。
for file in files:
img = load_img(file, grayscale=False, target_size=img_shape)
#ニューラルネットワークに入れる為にnumpyのarray型に変換する
x_test = img_to_array(img) / 255
#CNNに入れるためにreshapeで(n, w, h, c)型にしてやる
#0~1の少数が出力されるので、np.roundで出力をクラスラベルに変更してやる(0or1)
gazou = np.round(model.predict(x_test.reshape(1,128,128,3)))
if gazou == 0:
print("↓この画像はclass_1です↓")
elif gazou == 1:
print("↓この画像はclass_2です↓")
plt.subplot().imshow(x_test)
plt.show()
14. 作ったモデルを試してみましょう!(2)
引用させて頂いたのは以下の記事になります。
上手く行くと以下のような出力がされます。

ちなみに上の画像は正しく認識していた時の出力結果です。
上手く認識できなかった時は以下のようになります。

こうやってみられるのはとても面白いですね。
# モデルがどこを見ているのか確認できます。
# 対象イメージの読込み
for file in files:
img = img_to_array(load_img(file, target_size=(128,128)))
H,W =img.shape[:2]
img_nad = img_to_array(img)/255
img_nad = img_nad[None, ...]
#特長マップを抜き出すレイヤー指定
get_layer_output = K.function([model.layers[0].input],[model.layers[17].output])
print(model.layers[17])
layer_output = get_layer_output([img_nad])[0]
#特長マップ合成
G, R, ch = layer_output.shape[1:]
res = np.zeros((G,R))
for i in range(ch):
img_res = layer_output[0,:,:,i]
res = res + img_res
res = res/ch
#特長マップ平均の平坦化
res_flatte = np.ma.masked_equal(res,0)
res_flatte = (res_flatte - res_flatte.min())*255/(res_flatte.max()-res_flatte.min())
res_flatte = np.ma.filled(res_flatte,0)
#色付け
acm_img = cv2.applyColorMap(np.uint8(res_flatte), cv2.COLORMAP_JET)
acm_img = cv2.cvtColor(acm_img, cv2.COLOR_BGR2RGB)
acm_img = cv2.resize(acm_img,(H,W))
#元絵と合成
mixed_img = (np.float32(acm_img)*0.6 + img *0.4)
#表示
out_img = np.concatenate((img, acm_img, mixed_img), axis=1)
display_png(array_to_img(out_img))
これでモデルの制作は終了です。
次の段階へ移りましょう。
あと少しで今回の内容は完了しますのでもうひと頑張りです。
15. Flaskを使ってWebアプリを制作
引用させて頂いたのは以下の記事になります。
・[簡単]FLASKで画像AIをWEBアプリ化する!(GOOGLE COLABORATORY)
まずはモジュールをインポートしてください。
!pip install Flask==1.0.3
!pip install flask-ngrok #Google ColaboratoryでFlaskを使うのに必要
classの数やフォルダの名称を変更をしていなければこのまま実行してください。
import os
from flask import Flask, request, redirect, url_for
from werkzeug.utils import secure_filename
from flask_ngrok import run_with_ngrok
from keras.models import Sequential, load_model
import keras,sys
import numpy as np
from PIL import Image
from keras.preprocessing.image import load_img,img_to_array
classes = ['class_1', 'class_2']
image_size = 128
UPLOAD_FOLDER = '/content/drive/MyDrive/ColaboratoryApri/Uploads' #どこに保存する
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
run_with_ngrok(app) #Google Colab特有なもの
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
# ファイル名に'png', 'jpg', 'jpeg', 'gif'が含まれているかの関数
def allowed_file(filename):
return '.' in filename and filename.rsplit('.',1)[1].lower() in ALLOWED_EXTENSIONS
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
file_name = secure_filename(file.filename)
file.save(os.path.join(app.config['UPLOAD_FOLDER'], file_name))
filepath = os.path.join(app.config['UPLOAD_FOLDER'], file_name)
#モデルの読み込み
model = load_model('/content/drive/MyDrive/ColaboratoryApri/original_model.hdf5')
image = load_img(filepath, grayscale=False, target_size=(128, 128, 3))
x_test = img_to_array(image) / 255
#CNNに入れるためにreshapeで(n, w, h, c)型にしてやる
#0~1の少数が出力されるので、np.roundで出力をクラスラベルに変更してやる(0or1)
gazou = np.round(model.predict(x_test.reshape(1,128,128,3)))
if gazou == 0:
return "この画像はclass_1です。"
elif gazou == 1:
return "この画像はclass_2です。"
return render_template("html", gazou=gazou)
return '''
<!doctype html>
<html lang="ja">
<head>
<style type="text/css">
body {
background-color: #99CCFF
}
h1 {
color: #FFFFFF;
margin: 70px 0px 30px 0px;
text-align: center;
}
p {
color: #FFFFFF;
margin: 10px 0px 30px 0px;
text-align: center;
}
.answer {
color: #FFFFFF;
margin: 70px 0px 30px 0px;
text-align: center;
}
</style>
<meta charset="UTF-8">
<title>class_1かclass_2の画像ファイルを判定します。</title>
</head>
<body>
<h1>class_1かclass_2の画像ファイルを判定します!</h1>
<p>画像を送信してください</p>
<form method = post enctype = multipart/form-data>
<p><input type=file name=file>
<input type=submit value="判定する">
<input type="reset" value="別の画像にする">
</form>
</body>
</html>
'''
from flask import send_from_directory
@app.route('/content/drive/MyDrive/ColaboratoryApri/TestFire')#各自設定
def uploaded_file(filename):
#ファイルのダウンロードをする
#第1引数はファイルが配置されているディレクトリのパス
#第2引数はダウンロード対象のファイル
return send_from_directory(app.config['UPLOAD_FOLDER'], filename)
app.run()
動いたらRunning on http://~.ioのリンクをクリックしてください。
問題無ければ以下の画像のようなページが開くので デスクトップとかに画像を置いてファイルを選択からアップロードして判定してみてください。


判定出来たらこの画面になります。
以上ですべての工程が終了しました。お疲れ様でした。
16. 考察
1:目的
3Dモデルを用いた学習データでスクレイピングをして集めたテストデータを機械学習で見分ける事が出来るのか。
2:目的の対象や達成するための方法
見分けるものは「ブタの貯金箱」と「ニホンザル」。
CNNとVGG16を用いた転移学習。
3:結果
作成した機械学習モデルに2種類の画像を30枚をテスト。
初期は正解率が50%以下だった。
設定が良く分かっておらず、適当に決めたせいで学習用の画像が崩壊していたせいだった。
最終的に30枚に関しては100%になった。
mageNetで学習した重みを無効化すると初期以下になった。
デプロイしたアプリでテストに使った30枚と違う画像で10枚程度試した所、9枚正解した。
4:結果に基づいた考察
mageNetで学習した重みを無効化すると初期以下になったので、重みは大事だと学んだ。
3Dモデルを使った学習データはある程度識別できるようになったので今回の様な場合は悪くないと思う。
5:考察に基づいた結論
今回実地した機械学習の結果に基づいて
3Dモデルを用いた学習データは機械学習で使える。
17. 参考にさせて頂いた記事・サイト
・Keras Documentation
https://keras.io/ja/
- https://keras.io/ja/layers/core/
- https://keras.io/ja/applications/#vgg16
-
https://keras.io/ja/getting-started/sequential-model-guide/
*https://keras.io/ja/models/about-keras-models/
・[簡単]FLASKで画像AIをWEBアプリ化する!(GOOGLE COLABORATORY)
ほとんどそのまま引用しているものばかりです。
上記の情報が無ければこの記事は完成は出来ませんでした。
無料で公開して下さって本当にありがたいです。
最後に
第四次革命スキル習得講座を受けてみたくて株式会社アイデミーさんのAIアプリ開発コース(6ヶ月)を受講しました。
(税込み¥858.000。コース修了で¥458.000。修了日の翌日から 1 年以内に被保険者として雇用されている場合は¥298.000(6ヶ月の場合(2021))
それまでのプログラミングの経験は全く無く、受講する1か月前に数年前に買ったまま積読していた本を使いました。
正直、3ヵ月間の勉強はすぐに頭が痛くなって一日に2時間ぐらいしか出来なかったりと捗りませんでしたが、更に3か月をかけてやっと慣れてきたと思います。
基礎は事前に放置していた数年間の内に本を使ってもっと勉強していればアイデミー受講中にもっと踏み込んだ勉強が出来てよかったのにと思いました。for文をうっすらと理解するのに1か月ぐらいかかりましたし、数学が分からなくて勉強を始めたら結局遡って小学生の範囲からやり直しました。
検索して出てきた過去のアイデミー受講者達の出来の良さに眩暈がする事もありました。
ですが、クラスの引数とか、最初見た時は何が書いてあるか分からないものが微妙に理解できるとすごく嬉しかったです。
調べる内容も勉強が進むと得られる情報に変化があって成長を感じました。
いろんな人達の力を借りましたが、ここまで来れました。
プログラミングのエラーを解決する時に一昔前とは違って田舎でも勉強したり、学びたいと思った時に簡単に情報を得られたり、選んだりできる良い時代になったと強く思いました。
ですが、私の場合は仕事と掛け持ちだったら成果物が出来ていなかったと思います。
ここまで読んでいただきありがとうございます。