環境
$ uname -a
Linux archlinux.vagrant.vm 4.19.8-arch1-1-ARCH #1 SMP PREEMPT Sat Dec 8 13:49:11 UTC 2018 x86_64 GNU/Linux
PDFファイルを標準出力に吐き出して読む
pdftotextというコマンドラインツールを使用してPDFファイルをtext形式に変換し、標準出力に吐き出します。
サンプルとしてSed & Awk 2nd Edition.pdfをダウンロードし、そのディレクトリ上で以下のように実行します。(容量は約2MB)
$ pdftotext "Sed & Awk 2nd Edition.pdf"
pdftotextの標準的な使い方として、 上記のように実行するとtxtファイルがディスクに保存され、ターミナル上には何も表示されません。
一方で、第2引数に-(ダッシュ・ハイフン)をつけるとshellの標準出力へ出力され、PDFファイルを変換したtextファイルはディスク上に残りません。
$ pdftotext "Sed & Awk 2nd Edition.pdf" - # ダッシュ必要
テキストが 標準出力にドバっと出るので、lessなどにパイプして読むと良いと思います。
$ pdftotext "Sed & Awk 2nd Edition.pdf" - | less
vimにパイプするときはダッシュが必要です。
$ pdftotext "Sed & Awk 2nd Edition.pdf" - | vim - # ダッシュ必要
PDFファイルをtextファイルに変換する
pdftotextの標準的な使い方はpdftotext [options] <PDFファイル名> [出力ファイル名]です。
このやり方ではPDFファイルを変換したtextファイルはディスク上に残ります。
$ pdftotext --help
pdftotext version 0.71.0
Copyright 2005-2018 The Poppler Developers - http://poppler.freedesktop.org
Copyright 1996-2011 Glyph & Cog, LLC
Usage: pdftotext [options] <PDF-file> [<text-file>]
-f <int> : first page to convert
-l <int> : last page to convert
-r <fp> : resolution, in DPI (default is 72)
-x <int> : x-coordinate of the crop area top left corner
-y <int> : y-coordinate of the crop area top left corner
-W <int> : width of crop area in pixels (default is 0)
-H <int> : height of crop area in pixels (default is 0)
-layout : maintain original physical layout
-fixed <fp> : assume fixed-pitch (or tabular) text
-raw : keep strings in content stream order
-htmlmeta : generate a simple HTML file, including the meta information
-enc <string> : output text encoding name
-listenc : list available encodings
-eol <string> : output end-of-line convention (unix, dos, or mac)
-nopgbrk : don't insert page breaks between pages
-bbox : output bounding box for each word and page size to html. Sets -htmlmeta
-bbox-layout : like -bbox but with extra layout bounding box data. Sets -htmlmeta
-opw <string> : owner password (for encrypted files)
-upw <string> : user password (for encrypted files)
-q : don't print any messages or errors
-v : print copyright and version info
-h : print usage information
-help : print usage information
--help : print usage information
-? : print usage information
読書目的なら"-layout" "-nopgbrk"オプションはつけたほうが良さげ1
この下の説明では敢えてオプションを入れておきますが、
私の環境では普段オプションつけるのが面倒なので、
alias pdftotext="pdftotext -layout -nopgbrk"
のようにしてaliasを設定しました。
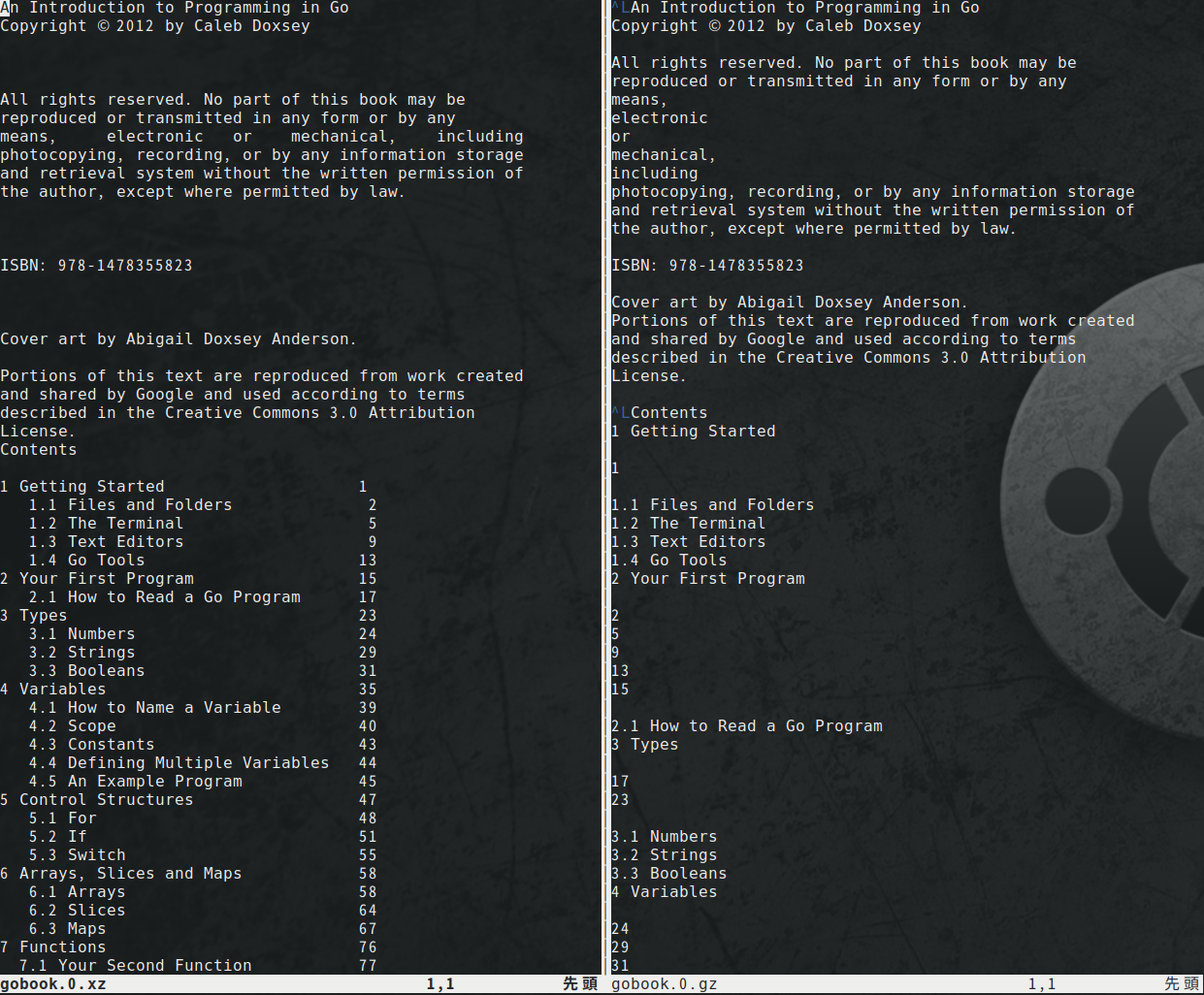
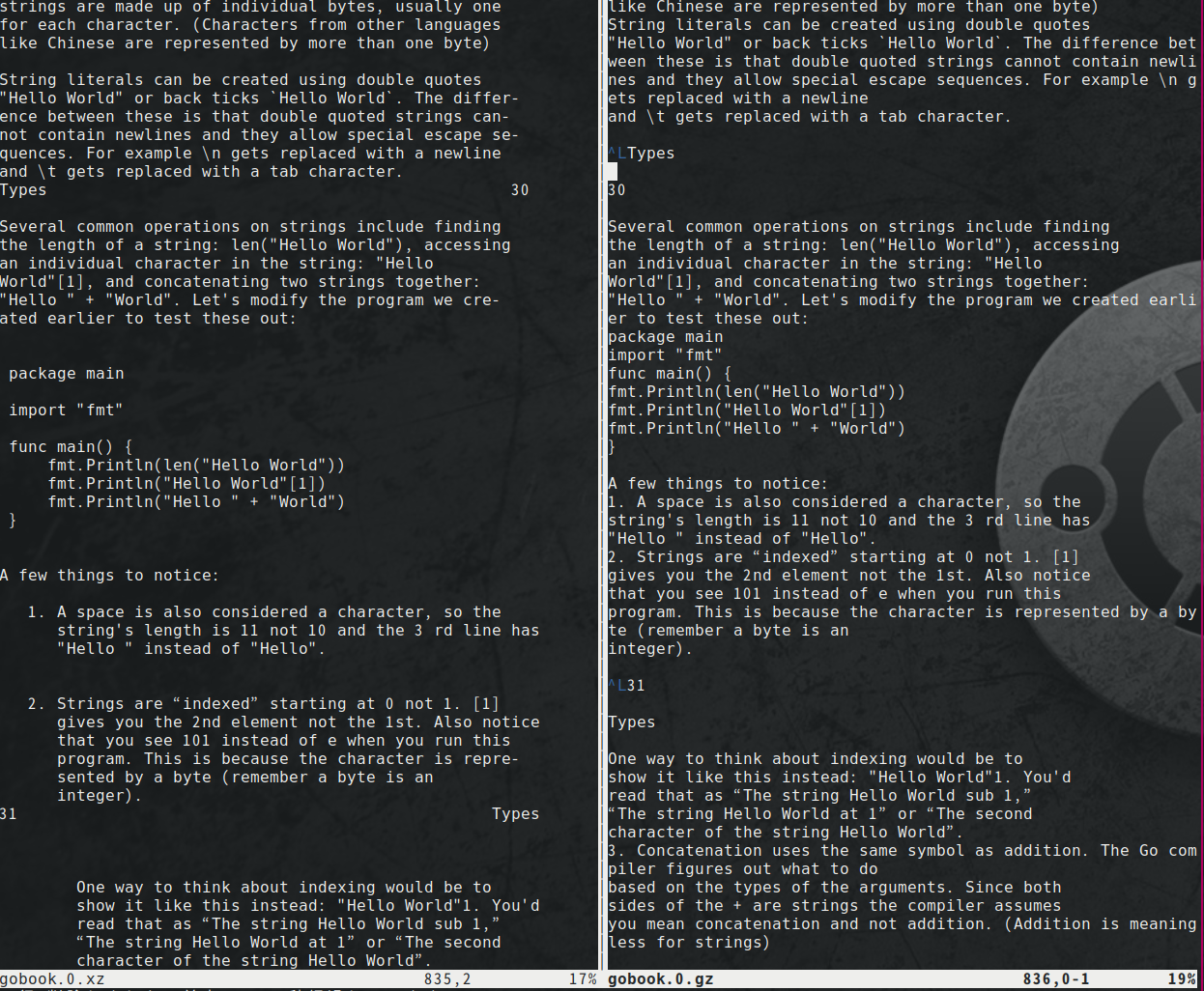
表示比較
-layout -nopgbrkオプション有り/無し表示比較
左が"-layout -nopgbrk"オプション付き、右がオプションなしです。
拡張子がgz, xzで違いますが、内容と表示しているページは同じです。
オプションをつけるとインデントが施され(-layout)、ページをまたいだ改行が消えます(-nopgbrk)。
kindleに送信したPDF/TEXT表示比較
kindleに送信したPDFファイルとテキストファイルの表示比較を行います。
[PDF] 最初のページ~目次まで


[TEXT] 最初のページ~目次まで

[PDF] 関数と項目インデント

[TEXT] 関数と項目インデント

TEXT形式で表示しても遜色ないように見えると思います。
PDFをTEXT変換してkindleで読むメリット:
- PDFに比べてファイルサイズが25%程度に押さえられるので、本来入れられる4倍量の本を収納可能
- ファイルを開く際の処理が軽い
- PDFファイルは開くときに読み込みが遅い
- 文字サイズ、段落の幅間の調整が効く
- PDFファイルはPCやA4サイズの紙で見ることに最適化されているので、kindleだと文字サイズが小さすぎる
- 老眼には絶対ムリ
- 老眼でなくても厳しい
- 目に悪い
- パラ読み(スライダーを動かしてページを高速にめくっていく機能)ができる
- 文字間が広いので選択がしやすい
- そのため辞書も引きやすい
- PDFは文字選択がしづらくていつもイライラする
- 本文内で文字検索を行うと検索結果が一覧表示される
- PDFで検索すると一覧表示されず、次と前の検索結果にしか進むことができない
PDFをTEXT変換してkindleで読むデメリット:
- 図や写真が削られる
- だから軽いんですけどね
- ページやブックマークジャンプが効かない
- ページ位置No.という覚え辛いジャンプ方法しかなく、番号表示しかないブックマークを自分でつけていくしかありません
- 目次や索引からのジャンプが効かない
- 検索機能で対応していくしかなさそうです
pdftotextのインストール
お使いのOS・パッケージマネージャーにより、pdftotextコマンドが使用できるようになるpopplerをインストールしてください。
$ apt install poppler-utils
$ yum install poppler-utils
$ pacman -S poppler
$ brew install poppler
$ pdftotext -v
pdftotext version 0.71.0
Copyright 2005-2018 The Poppler Developers - http://poppler.freedesktop.org
Copyright 1996-2011 Glyph & Cog, LLC
オンライン上のPDFをターミナル上で読む
curlでPDFを取得してpdftotextに投げているだけです。
PDFをcurlで標準出力に出そうとすると、binaryを標準出力に出すことになるためにエラーになるので、ワンライナーにはできませんでした。2
やむを得ず一時ファイルを作成するshell scriptを作成しました。3
ダウンロードしたPDFファイルや変換したtextファイルはディスク上に残りません。
$ pdffetch -layout -nopgbrk https://doc.lagout.org/operating%20system%20/linux/Sed%20%26%20Awk.pdf | less
#!/bin/sh
_pdffetchusage() {
cat << EOF
curl -> pdftotext -> stdout as text
Usage:
pdffetch <options> [url]
Option:
-h | --help: Print this help
pdftotext options: see \`man pdftotext\`
Dependency:
pdftotext
curl
EOF
}
if [ "$1" != '-h' ] || [ "$1" != '--help' ]; then
tmpfile=$(mktemp)
curl -Lo ${tmpfile} "${@:$#}" && pdftotext "${@:1:$#-1}" ${tmpfile} -
# "${@:$#}" : last argument
# "${@:1:$#-1}" : all arguments except last one
trap "rm ${tmpfile}" 0
else
_pdffetchusage
exit 1
fi
日本語PDFもものによってはいけます。
$ pdffetch -layout -nopgbrk https://att.liam.page/attachment/Git/progit.ja.pdf | less
ダウンロード後にそのまま圧縮形式で保存するときはパイプしてください。
$ pdffetch -layout -nopgbrk https://doc.lagout.org/operating%20system%20/linux/Sed%20%26%20Awk.pdf | xz -c > "Sed & Awk 2nd Edition.xz"
圧縮ファイルとして保存する
このやり方ではPDFファイルを変換した圧縮ファイルはディスク上に残ります。
text形式にすると平均75%圧縮、xz形式にすると平均90%超圧縮できます。
ファイル形式変わっているので圧縮とは言わない...
テキストとして読めるなら、使用目的変わっていないんだから圧縮と言っても良いんじゃ?
Unix Power Tools 3rd Edition.pdf
$ ls -lhs Unix\ Power\ Tools.*
8.5M -rw-rw-r-- 1 vagrant vagrant 8.4M 2019-01-02 20:13 'Unix Power Tools.pdf'
2.3M -rw-r--r-- 1 vagrant vagrant 2.3M 2019-01-02 21:24 'Unix Power Tools.txt'
632K -rw-r--r-- 1 vagrant vagrant 627K 2019-01-03 09:21 'Unix Power Tools.xz'
AN INTRODUCTION TO PROGRAMMING IN GO
$ ls -1sSh gobook.0.*
2.8M gobook.0.pdf
124K gobook.0.txt
40K gobook.0.zip
40K gobook.0.gz
36K gobook.0.bzip2
36K gobook.0.xz
ものによっては圧縮率99%を実現!
On the flyで圧縮
atoolをインストールして、以下のコードをシェル上で実行してください。
PDFとxzファイル名は適宜変更してください。
$ pdftotext -layout -nopgbrk "somepdffile.pdf" - | apack "somepdffile.xz" -
pdftotextコマンドと"-"でsomepdffile.pdfを表示出力に出力し、
apackコマンドと"-"で標準入力をsomepdffile.xzというxzファイルに変換します。
apackはファイル名の拡張子でどんなタイプの圧縮をかけるか判別してくれるので、xzを例えばgzに変えればgzipで圧縮をかけてくれます。
以下はatoolを使わず、gzipでワンライナーで圧縮する例。
$ pdftotext -layout -nopgbrk "Sed & Awk 2nd Edition.pdf" - | gzip -c > "Sed & Awk 2nd Edition.gz"
# "Sed & Awk 2nd Edition.gz"が作成されます
teeコマンドを使えばtextファイルとgzipファイル同時に出力できます。
$ pdftotext -layout -nopgbrk "Sed & Awk 2nd Edition.pdf" - |
tee "Sed & Awk 2nd Edition.txt" |
gzip -c > "Sed & Awk 2nd Edition.gz"
# "Sed & Awk 2nd Edition.txt"と"Sed & Awk 2nd Edition.gz"が作成されます
シェルスクリプトを使って圧縮
gzip, bzip2, xz
pdftogz, pdftobz2, pdftoxzを作りました。3 4
使い方はpdftogz <options> [pdffile.pdf]
optionsにはpdftotextのオプションが入ります。
$ pdftogz -layout -nopgbrk "Sed & Awk 2nd Edition.pdf"
# Sed & Awk 2nd Edition.gzが作成されます
bzip2, xzも同様。
#!/bin/sh
_pdftogzusage() {
cat << EOF
Convert pdffile to text, then compress to gzip file.
Usage:
pdftogz [pdffilename]
Option:
-h: Print this help
pdftotext options: see \`man pdftotext\`
Dependency:
pdftotext
gzip
EOF
}
LASTARG="${@:$#}"
if file "${LASTARG}" 2>&1 /dev/null | grep -q 'PDF' ; then # pdf check
GZIPFILE=$(echo $(basename "${LASTARG}" '.pdf').gz) # rename .pdf to .gz
pdftotext "$@" - | gzip -c > "${GZIPFILE}"
elif [ "$1" = '-h' ] || [ "$1" = '--help' ]; then
_pdftogzusage
exit 0
else
_pdftogzusage
exit 1
fi
pdftobz2
#!/bin/sh
_pdftobz2usage() {
cat << EOF
Convert pdffile to text, then compress to bzip2 file.
Usage:
pdftobz2 [pdffilename]
Option:
-h: Print this help
pdftotext options: see \`man pdftotext\`
Dependency:
pdftotext
bzip2
EOF
}
LASTARG="${@:$#}"
if file "${LASTARG}" 2>&1 /dev/null | grep -q 'PDF' ; then # pdf check
BZ2FILE=$(echo $(basename "${LASTARG}" '.pdf').bz2) # rename .pdf to .bz2
pdftotext "$@" - | bzip2 -c > "${BZ2FILE}"
elif [ "$1" = '-h' ] || [ "$1" = '--help' ]; then
_pdftobz2usage
exit 0
else
_pdftobz2usage
exit 1
fi
pdftoxz
#!/bin/sh
_pdftoxzusage() {
cat << EOF
Convert pdffile to text, then compress to xz file.
Usage:
pdftoxz [pdffilename]
Option:
-h: Print this help
pdftotext options: see \`man pdftotext\`
Dependency:
pdftotext
xz
EOF
}
LASTARG="${@:$#}"
if file "${LASTARG}" 2>&1 /dev/null | grep -q 'PDF' ; then # pdf check
XZFILE=$(echo $(basename "${LASTARG}" '.pdf').xz) # rename .pdf to .xz
pdftotext "$@" - | xz -c > "${XZFILE}"
elif [ "$1" = '-h' ] || [ "$1" = '--help' ]; then
_pdftoxzusage
exit 0
else
_pdftoxzusage
exit 1
fi
圧縮ファイルは解凍せずにそのまま読める。そう、vimならね。
vimのちからってすげー
# vimで読むときは解凍せずそのまま読める
$ vim "Sed & Awk 2nd Edition.xz"
追記:vimなら直接PDFファイルをテキスト変換して開くことができる vimを高機能なPDFリーダーにする設定 5
lessで見たいときは解凍してパイプしないと読めません。
# lessで読むときは解凍必要
$ xz -dc "Sed & Awk 2nd Edition.xz" | less
nanoにパイプしたら読み込みに大変時間がかかりましたので、やってはいけない。
zip
zipコマンドはgzip, bzip2, xzとは使用するコマンドが異なります。
$ pdftotext -layout -nopgbrk "Bash-Beginners-Guide.pdf" - | zip "Bash-Beginners-Guide.zip" -
pdftozipを作りました。3 4
使い方はpdftozip <options> [pdffile.pdf]
pdftozip
#!/bin/sh
_pdftozipusage() {
cat << EOF
Convert pdffile to text, then compress to zip file.
Usage:
pdftozip [pdffilename]
Option:
-h: Print this help
pdftotext options: see \`man pdftotext\`
Dependency:
pdftotext
zip
EOF
}
LASTARG="${@:$#}"
if file "${LASTARG}" 2>&1 /dev/null | grep -q 'PDF' ; then # pdf check
ZIPFILE=$(echo $(basename "${LASTARG}" '.pdf').zip) # rename .pdf to .zip
pdftotext "$@" - | zip "${ZIPFILE}" -
elif [ "$1" = '-h' ] || [ "$1" = '--help' ]; then
_pdftozipusage
exit 0
else
_pdftozipusage
exit 1
fi
圧縮されているファイル名にカーソル合わせてEmter()押すことで圧縮ファイルの内容を見ることができます。
vim "Bash-Beginners-Guide.zip"
# ディレクトリをvimで開いたかのような画面になるので
# ファイル名"-"にカーソル合わせて<CR>
# するとファイルの内容が見れる
または標準出力に解凍し、パイプからのless.
unzip -p "Bash-Beginners-Guide.zip" | less
余談ですが、kindleがサポートしている形式に"zipファイル"がありますが、この方法で圧縮したzipファイルをkindleにeメールとして送信してもエラーで変換されませんでした。他の人のサイトを見る感じ、zipで見れるのはjpegとかの画像ファイルをまとめたzipファイルがkindle上で見れる話だそうで、テキストファイルの圧縮はサポートしてないのかな、と。
Kindle パーソナル・ドキュメントで変換・転送できるドキュメントは以下のファイル形式です:
Microsoft Word (.doc, .docx)
Rich Text Format (.rtf)
HTML (.htm, .html)
Text (.txt) documents
圧縮フォルダ (zip , x-zip)
Mobi book
まとめ
# PDFをテキスト変換する
$ pdftotext -layout -nopgbrk "Sed & Awk 2nd Edition.pdf"
# "Sed & Awk 2nd Edition.txt"が生成されます
# PDFをテキスト変換して標準出力で読む
$ pdftotext -layout -nopgbrk "Sed & Awk 2nd Edition.pdf" - | less
# ファイルは生成されません
# オンライン上のpdfを標準出力で読む
$ pdffetch -layout -nopgbrk https://doc.lagout.org/operating%20system%20/linux/Sed%20%26%20Awk.pdf | less
# ファイルは生成されません
# PDFをテキスト変換してgzip圧縮をかける(1)
$ pdftotext -layout -nopgbrk "Sed & Awk 2nd Edition.pdf" - | gzip -c > "Sed&Awk2ndEdition.gz"
# "Sed & Awk 2nd Edition.gz"が生成されます
# bzip2, xzも同様
# オンライン上のpdfをtext形式に変換してgzip圧縮で保存する
$ pdffetch -layout -nopgbrk https://doc.lagout.org/operating%20system%20/linux/Sed%20%26%20Awk.pdf | gzip -c > "Sed & Awk 2nd Edition.gz"
# "Sed & Awk 2nd Edition.gz"が生成されます
# PDFをテキスト変換してgzip圧縮をかける(2)
$ pdftogz -layout -nopgbrk "Sed & Awk 2nd Edition.pdf"
# "Sed & Awk 2nd Edition.gz"が生成されます
# pdftobz2, pdftoxzも同様
# text展開とgzip圧縮を同時に行う
$ pdftotext -layout -nopgbrk "Sed & Awk 2nd Edition.pdf" - |
tee "Sed & Awk 2nd Edition.txt" |
gzip -c > "Sed & Awk 2nd Edition.gz"
# "Sed & Awk 2nd Edition.txt"と"Sed & Awk 2nd Edition.gz"が作成されます
# 圧縮したtextファイルをvimで読む
$ vim "Sed & Awk 2nd Edition.gz"
# bzip, xzも同様
$ vim "Bash-Beginners-Guide.zip"
# ファイルは生成されません
# 圧縮したtextファイルをlessで読む
$ gzip -dc "Sed & Awk 2nd Edition.gz" | less
# bzip, xzも同様
$ unzip -p "Bash-Beginners-Guide.zip" | less
# ファイルは生成されません
-
pdftogz, pdftobz2, pdftoxz, pdftozip, pdffetchのソースコード u1and0/oneliner-pdftocompressfile ↩ ↩2 ↩3
-
参考: 圧縮展開系のコマンドのまとめ ↩ ↩2
-
vimでPDFを直接開く方法 vimを高機能なPDFリーダーにする設定 ↩