stackover flow - Command line CSV viewer?
の質問にあるように、CSVを整形された形で表示するCLIツールを探していたので、とりあえずの解決法を書きます。
日本語の場合はエンコードがShift-jisだったりEUC-JPのCSVファイル(全てはExcelのせい、ゲイツのせい)するので、utf-8に変換してから表示する方法も書きます。
CSV表示コマンド
- column
- tty-table(node.jsのコマンド)
columnコマンド
普通にcatやheadで表示すると,,344,,,22,,みたいになってすごく見づらい経験あると思います。
$ head macrodata.csv
year,quarter,realgdp,realcons,realinv,realgovt,realdpi,cpi,m1,tbilrate,unemp,pop,infl,realint
1959.0,1.0,2710.349,1707.4,286.898,470.045,1886.9,28.98,139.7,2.82,5.8,177.146,0.0,0.0
1959.0,2.0,2778.801,1733.7,310.859,481.301,1919.7,29.15,141.7,3.08,5.1,177.83,2.34,0.74
1959.0,3.0,2775.488,1751.8,289.226,491.26,1916.4,29.35,140.5,3.82,5.3,178.657,2.74,1.09
1959.0,4.0,2785.204,1753.7,299.356,484.052,1931.3,29.37,140.0,4.33,5.6,179.386,0.27,4.06
1960.0,1.0,2847.699,1770.5,331.722,462.199,1955.5,29.54,139.6,3.5,5.2,180.007,2.31,1.19
1960.0,2.0,2834.39,1792.9,298.152,460.4,1966.1,29.55,140.2,2.68,5.2,180.671,0.14,2.55
1960.0,3.0,2839.022,1785.8,296.375,474.676,1967.8,29.75,140.9,2.36,5.6,181.528,2.7,-0.34
1960.0,4.0,2802.616,1788.2,259.764,476.434,1966.6,29.84,141.1,2.29,6.3,182.287,1.21,1.08
1961.0,1.0,2819.264,1787.7,266.405,475.854,1984.5,29.81,142.1,2.37,6.8,182.992,-0.4,2.77
columnコマンドを使えば空白をいい感じに調整してくれます。
私の使っているubuntu16.04, archlinuxには標準で入っていました。
$ column -s, -t macrodata.csv | head
year quarter realgdp realcons realinv realgovt realdpi cpi m1 tbilrate unemp pop infl realint
1959.0 1.0 2710.349 1707.4 286.898 470.045 1886.9 28.98 139.7 2.82 5.8 177.146 0.0 0.0
1959.0 2.0 2778.801 1733.7 310.859 481.301 1919.7 29.15 141.7 3.08 5.1 177.83 2.34 0.74
1959.0 3.0 2775.488 1751.8 289.226 491.26 1916.4 29.35 140.5 3.82 5.3 178.657 2.74 1.09
1959.0 4.0 2785.204 1753.7 299.356 484.052 1931.3 29.37 140.0 4.33 5.6 179.386 0.27 4.06
1960.0 1.0 2847.699 1770.5 331.722 462.199 1955.5 29.54 139.6 3.5 5.2 180.007 2.31 1.19
1960.0 2.0 2834.39 1792.9 298.152 460.4 1966.1 29.55 140.2 2.68 5.2 180.671 0.14 2.55
1960.0 3.0 2839.022 1785.8 296.375 474.676 1967.8 29.75 140.9 2.36 5.6 181.528 2.7 -0.34
1960.0 4.0 2802.616 1788.2 259.764 476.434 1966.6 29.84 141.1 2.29 6.3 182.287 1.21 1.08
1961.0 1.0 2819.264 1787.7 266.405 475.854 1984.5 29.81 142.1 2.37 6.8 182.992 -0.4 2.77
columnコマンドの使い方
$ column -h
使い方:
column [オプション] [<ファイル>...]
入力を列ごとに整形します。
オプション:
-t, --table create a table
-n, --table-name <name> table name for JSON output
-O, --table-order <columns> specify order of output columns
-N, --table-columns <names> comma separated columns names
-E, --table-noextreme <columns> don't count long text from the columns to column width
-d, --table-noheadings don't print header
-e, --table-header-repeat repeat header for each page
-H, --table-hide <columns> don't print the columns
-R, --table-right <columns> right align text in these columns
-T, --table-truncate <columns> truncate text in the columns when necessary
-W, --table-wrap <columns> wrap text in the columns when necessary
-J, --json use JSON output format for table
-r, --tree <column> column to use tree-like output for the table
-i, --tree-id <column> line ID to specify child-parent relation
-p, --tree-parent <column> parent to specify child-parent relation
-c, --output-width <width> width of output in number of characters
-o, --output-separator <文字列> 表出力時の列区切りを指定します。(既定値はスペース 2 つ)
-s, --separator <文字列> 表の区切り文字列を指定します
-x, --fillrows 列の前に行を埋めます
-h, --help このヘルプを表示します
-V, --version バージョンを表示します
詳しくは column(1) をお読みください。
node.jsのtty-tableコマンド
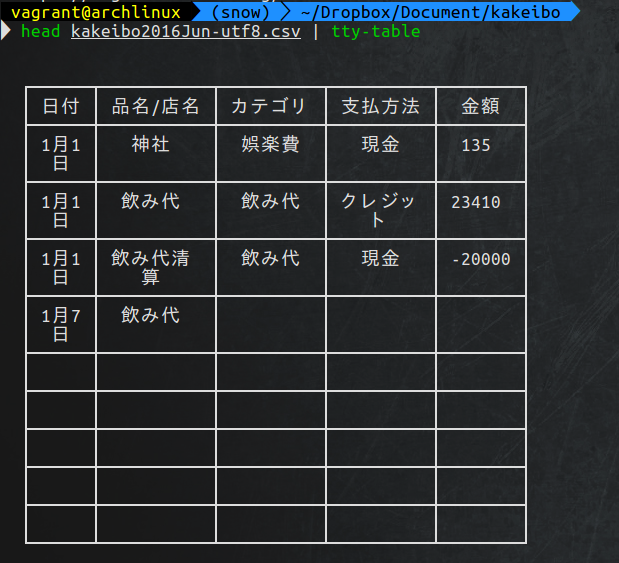
nkfコマンドなどでutf8形式に変換したcsvファイルkakeibo2016Jun-utf8.csvを使います。普通にheadで表示するとコンマだらけで見づらいです。
$ head kakeibo2016Jun-utf8.csv
日付,品名/店名,カテゴリ,支払方法,金額
1月1日,神社,娯楽費,現金,135
1月1日,飲み代,飲み代,クレジット,23410
1月1日,飲み代清算,飲み代,現金,-20000
1月7日,飲み代,,,
,,,,
,,,,
,,,,
,,,,
,,,,
node.jsのtty-tableを使えば、綺麗な表示のテーブルが見れます。
まずはnode.jsのパッケージマネージャnpmをインストールし、npmからtty-tableをインストールします。
$ sudo pacman -S nodejs npm
$ sudo npm i -g tty-table
$ head kakeibo2016Jun-utf8.csv | tty-table
┌──────┬───────────┬──────────┬──────────┬────────┐
│ 日付 │ 品名/店名 │ カテゴリ │ 支払方法 │ 金額 │
├──────┼───────────┼──────────┼──────────┼────────┤
│ 1月1 │ 神社 │ 娯楽費 │ 現金 │ 135 │
│ 日 │ │ │ │ │
├──────┼───────────┼──────────┼──────────┼────────┤
│ 1月1 │ 飲み代 │ 飲み代 │ クレジッ │ 23410 │
│ 日 │ │ │ ト │ │
├──────┼───────────┼──────────┼──────────┼────────┤
│ 1月1 │ 飲み代清 │ 飲み代 │ 現金 │ -20000 │
│ 日 │ 算 │ │ │ │
├──────┼───────────┼──────────┼──────────┼────────┤
│ 1月7 │ 飲み代 │ │ │ │
│ 日 │ │ │ │ │
├──────┼───────────┼──────────┼──────────┼────────┤
│ │ │ │ │ │
├──────┼───────────┼──────────┼──────────┼────────┤
│ │ │ │ │ │
├──────┼───────────┼──────────┼──────────┼────────┤
│ │ │ │ │ │
├──────┼───────────┼──────────┼──────────┼────────┤
│ │ │ │ │ │
├──────┼───────────┼──────────┼──────────┼────────┤
│ │ │ │ │ │
└──────┴───────────┴──────────┴──────────┴────────┘
テキストで貼り付けると形が崩れて見えますが、ターミナル上には綺麗に整形されたテーブルが表示されています。
$ tty-table -h
オプション:
--version バージョンを表示 [真偽]
--csv-delimiter Set the field delimiter. One character only.
[デフォルト: ","]
--csv-escape Set the escape character. One character only.
--csv-rowDelimiter String used to delimit record rows. You can also use a
special constant: "auto","unix","max","windows","unicode".
[デフォルト: "
"]
--format Set input data format
[選択してください: "json", "csv"] [デフォルト: "csv"]
--options‐* Specify an optional setting where * is the setting name.
See README.md for a complete list.
-h ヘルプを表示 [真偽]
Copyight github.com/tecfu 2018
pythonのcsvkitパッケージに含まれるcsvlookコマンド
===2018/12/29追記===
インストールはpipやcondaで行います。
$ pip install csvkit
# または
$ conda install csvkit
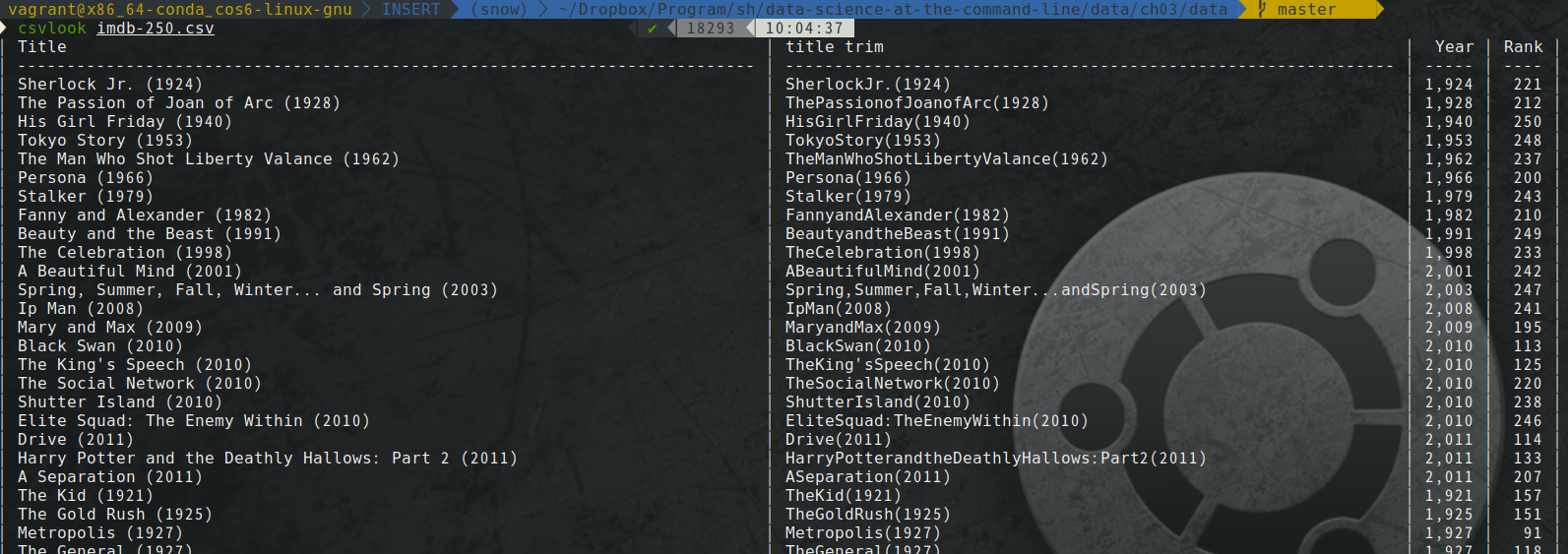
$ csvlook imdb-250.csv
| Title | title trim | Year | Rank |
| --------------------------------------------------------------------------- | -------------------------------------------------------------- | ----- | ---- |
| Sherlock Jr. (1924) | SherlockJr.(1924) | 1,924 | 221 |
| The Passion of Joan of Arc (1928) | ThePassionofJoanofArc(1928) | 1,928 | 212 |
| His Girl Friday (1940) | HisGirlFriday(1940) | 1,940 | 250 |
| Tokyo Story (1953) | TokyoStory(1953) | 1,953 | 248 |
| The Man Who Shot Liberty Valance (1962) | TheManWhoShotLibertyValance(1962) | 1,962 | 237 |
| Persona (1966) | Persona(1966) | 1,966 | 200 |
| Stalker (1979) | Stalker(1979) | 1,979 | 243 |
| Fanny and Alexander (1982) | FannyandAlexander(1982) | 1,982 | 210 |
...(略)
csvkitにはエクセルファイル(.xlsx)をcsv化するコマンドもあって捗る
$ in2csv imdb-250.xlsx | head | csvlook
のようにするとエクセルファイルをcsvに変換して標準出力したものの上10行を拾って上記のように罫線を入れて表示してくれます。
参考: Data Science at the Command Line[PDF]のChapter3
エンコード問題
上記の方法でうまく整形表示されなかった場合、エンコードがshift_jisなどになっているためにエラーとなっている可能性があります。
nkfやiconvでutf8形式に直してから、collumnやtty-tableを再トライしてみましょう。
すべてはExcelのせい、ゲイツのry
ファイルタイプを表示
file -i <filepath>nkf --guess <filepath>uchardet <filepath>
$ file -i kakeibo2016Jun.csv
kakeibo2016Jun.csv: text/plain; charset=unknown-8bit
$ yaourt -S nkf
$ nkf --guess kakeibo2016Jun.csv
Shift_JIS (CRLF)
$ nkf -g kakeibo2016Jun.csv
Shift_JIS
$ sudo pacman -S uchardet
$ uchardet kakeibo2016Jun.csv
SHIFT_JIS
参考: Linux/UNIXでファイルの文字コード(UTF-8 or Shift_JIS or EUC-JP…)を確認する
utf-8に変換
shift-jis形式のkakeibo2016Jun.csvをutf8形式のkakeibo2016Jun-utf8.csvに変換します。
iconvコマンドで変換
$ iconv -f sjis -t utf8 -o kakeibo2016Jun{-utf8,}.csv
iconvの使い方
iconv -f ENCODING -t ENCODING INPUTFILE
- -f : 変換元の文字コード
- -t : 変換後の文字コード
- -o : 出力するファイル
- INPUTFILE : 変換元のファイル名
$ iconv --help
使用法: iconv [OPTION...] [FILE...]
与えられたファイルのエンコーディングをあるエンコーディングから別のエンコーディングに変換します。
入力/出力形式の指定:
-f, --from-code=NAME 元のテキストのエンコーディング
-t, --to-code=NAME 出力用のエンコーディング
情報:
-l, --list
全ての既知の符号化された文字集合を一覧表示します
出力制御:
-c 出力から無効な文字を取り除く
-o, --output=FILE 出力ファイル
-s, --silent 警告を抑制する
--verbose 経過情報を表示する
-?, --help このヘルプ一覧を表示する
--usage 短い使用方法を表示する
-V, --version プログラムのバージョンを表示する
長い形式のオプションで必須または任意の引数は、それに対応する短い形式のオプションでも同様に必須または任意です。
For bug reporting instructions, please see:
<https://bugs.archlinux.org/>.
nkfコマンドで変換
$ nkf -w kakeibo2016Jun.csv > kakeibo2016Jun-utf8-nkf.csv
$ nkf -g kakeibo2016Jun-utf8-nkf.csv # ファイル形式確認
UTF-8
--overwriteオプションでファイル上書きしてくれるようです。
$ nkf --help
Usage: nkf -[flags] [--] [in file] .. [out file for -O flag]
j/s/e/w Specify output encoding ISO-2022-JP, Shift_JIS, EUC-JP
UTF options is -w[8[0],{16,32}[{B,L}[0]]]
J/S/E/W Specify input encoding ISO-2022-JP, Shift_JIS, EUC-JP
UTF option is -W[8,[16,32][B,L]]
m[BQSN0] MIME decode [B:base64,Q:quoted,S:strict,N:nonstrict,0:no decode]
M[BQ] MIME encode [B:base64 Q:quoted]
f/F Folding: -f60 or -f or -f60-10 (fold margin 10) F preserve nl
Z[0-4] Default/0: Convert JISX0208 Alphabet to ASCII
1: Kankaku to one space 2: to two spaces 3: HTML Entity
4: JISX0208 Katakana to JISX0201 Katakana
X,x Convert Halfwidth Katakana to Fullwidth or preserve it
O Output to File (DEFAULT 'nkf.out')
L[uwm] Line mode u:LF w:CRLF m:CR (DEFAULT noconversion)
--ic=<encoding> Specify the input encoding
--oc=<encoding> Specify the output encoding
--hiragana --katakana Hiragana/Katakana Conversion
--katakana-hiragana Converts each other
--{cap, url}-input Convert hex after ':' or '%'
--numchar-input Convert Unicode Character Reference
--fb-{skip, html, xml, perl, java, subchar}
Specify unassigned character's replacement
--in-place[=SUF] Overwrite original files
--overwrite[=SUF] Preserve timestamp of original files
-g --guess Guess the input code
-v --version Print the version
--help/-V Print this help / configuration
Network Kanji Filter Version 2.1.4 (2015-12-12)
Copyright (C) 1987, FUJITSU LTD. (I.Ichikawa).
Copyright (C) 1996-2015, The nkf Project.
おすすめは確認も出力も簡易なコマンドで済むnkfを使うことですかね。
fileやiconvはデフォルトで入っていると思います。
uchardetはオプションも少ないし、入れなくていいと思いました。
参考: 【linux】ファイルの文字コードを変換する。vi、iconv、nkf (nkfの文字コード判定とか一括変換は便利)