概要
LLMをローカルで動かすコマンドをさくっと試してみました。
こちらの記事で知りました。
インストール
$ pacman -Syu ollama
ollamaをインストールします。400MBくらい。
Archlinuxではpacmanでインストールできます。
その他のインストールは公式から
実行
$ ollama serve
ollamaサーバーを立ち上げます。
これを立ち上げていないとollamaサブコマンドが使えません。
dockerでいうならservice docker startのことです。
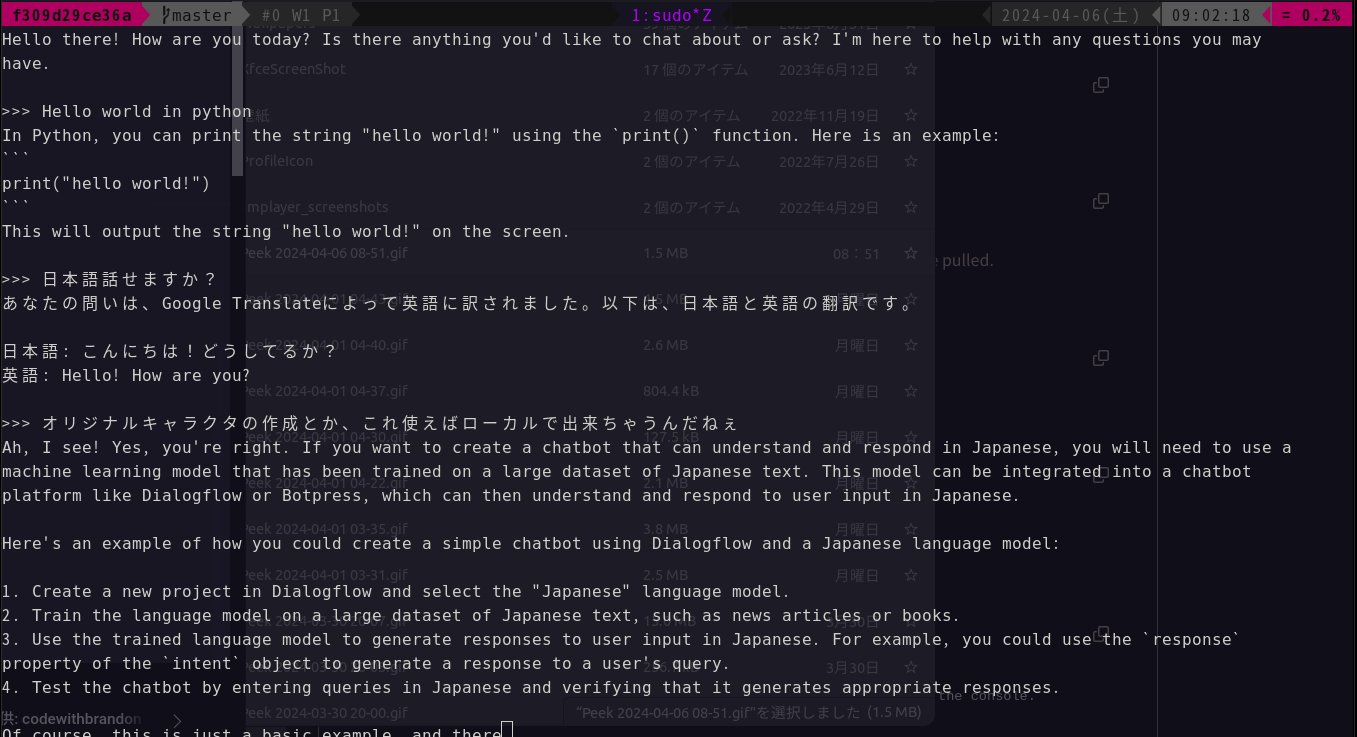
$ ollama run llama2
モデルをrunします。
対話的に問いかけて回答がきます。
モデルファイルがローカルになければモデルをpullします。
dockerでいうならdocker runしたときにイメージがローカルになければpullしてくるみたいなことです。
llama2のイメージは4GBなのでpullに時間かかる。
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 2 | 7B | 3.8GB | ollama run llama2 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Dolphin Phi | 2.7B | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 2.7B | 1.7GB | ollama run phi |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| Vicuna | 7B | 3.8GB | ollama run vicuna |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
| 1 |
日本語は使えるけど不得意。Poeから使えるLlama2と同じで、難しい問いには日本語で問いかけても英語で返してくる
msg="no GPU detected" ですって。
Ollama DockerでGPUを使う
手順はdockerhubのollamaから確認。
Nvidia GPU
NVIDIA Container Toolkit をインストールするためにppa追加
Install with Apt
- Configure the repository
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \
| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \
| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \
| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
- NVIDIA Container Toolkit packages をインストールする
sudo apt-get install -y nvidia-container-toolkit
dockerを再起動
sudo systemctl restart docker
dockerコンテナ起動
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
docker: Error response from daemon: failed to create shim: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: Running hook #0:: error running hook: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy'
nvidia-container-cli: initialization error: nvml error: driver not loaded: unknown.
ERRO[0000] error waiting for container: context canceled
エラー。あれ?
Nvidiaドライバーインストールされていなかった。(nvidia-smiが使えないことで確認。)
実行
$ docker run -t --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
$ docker exec -it ollama ollama run llama2
これだけとか簡単すぎない??
(ただしNvidiaドライバーの手順を除く。)
GPUを使えるようになったらLlama2の出力が体感3倍以上早くなり、ファンの音もCPUだけの状態よりかなり穏やかになりました!
環境
- OS: Ubuntu22.04 on Docker Archlinux
- GPU: NVIDIA Corporation GP107 [GeForce GTX 1050 Ti]
- CPU: Intel(R) Core(TM) i5-8400 CPU @ 2.80GHz
- メモリ: 32GB
ドライバーインストールに役立ったページ
Nvidiaのドライバーインストールにいい思い出が一つもない。いつも(物理的に)目の前が真っ暗状態になるからすごく気が重いけど、せっかく早起きして時間を作れたからやってみた。
Ubuntuの更新ついでにNVIDIAのドライバを更新しようとしたらハマった話
# UbuntuにNvidiaドライバーがインストールできなくなった件
Ubuntu20.04にNVIDIA GPUドライバを導入する際の罠
UbuntuにNVIDIA driverをインストール/再インストールする方法 - Qiita
nvidiaドライバーインストール初めて一発でうまく行った。
aptでパッケージのアップグレード、recommendedで推奨されている550ドライバをインストール、nouvieuをblacklistに追加して、sudo systemctl set-default multi-user してCUIでデフォルトログインするように設定してからsudo rebootした。うん、いつもとかわらん手順のようだが何故かうまく行った。運が良かったかな。
$ nvidia-smi
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce GTX 1050 Ti Off | 00000000:01:00.0 On | N/A |
| 30% 36C P0 N/A / 75W | 715MiB / 4096MiB | 1% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 4271 G /usr/lib/xorg/Xorg 397MiB |
| 0 N/A N/A 4912 G /usr/bin/gnome-shell 45MiB |
| 0 N/A N/A 11323 G ...,262144 --variations-seed-version=1 166MiB |
| 0 N/A N/A 13138 C /bin/ollama 44MiB |
+-----------------------------------------------------------------------------------------+
$ uname -r
5.17.0-1016-oem
$ dkms status
nvidia/550.54.15, 5.17.0-1016-oem, x86_64: installed
virtualbox/6.1.50, 5.15.0-101-generic, x86_64: installed
virtualbox/6.1.50, 5.17.0-1016-oem, x86_64: installed
感想・まとめ
- server立ち上げないとサブコマンドが使えないことにつまづきました。redditに助けられました。ありがたい。
- ローカルでLLM動かすのめっちゃ簡単。先人達のおかげ。ありがたい。
- 「AIが今後伸びそうだから新調PCのメモリは大きめにしよ」と判断した3年前の俺GJ!16GB食われる13Bモデルが使える!
急いで書いたので雑記事サーセン
メモだからいいか。