この記事はplotlyとpandasを結びつけるライブラリ"cufflinks"の紹介、およびそれを利用した金融関連のデータ描画、pandas_datareaderや自作モジュールによる金融データの取得、自作モジュールによる金融データの操作を行います。
データの描画
cufflinks 使い方
公式: GitHub - santosjorge/cufflinks
This library binds the power of plotly with the flexibility of pandas for easy plotting.
このライブラリーは簡単なプロットのために「plotlyの力」と「pandasの柔軟性」を結びつけます。
2017年12月現在、condaではインストールできません。
anaconda cloudで探すと(またはぐぐると) biocondaでRNAがなんとかとか言っている生物学系の別のcufflinksが見つかるけれども、全く関係ないものなので注意。
正しくインストールするにはpipを使って下さい。
$ pip install cufflinks
インポートと初期設定
cufflinksをインポートし、オフライン設定を有効化します。
import cufflinks as cf
cf.set_config_file(offline=True)
get_config_file()で'offline': True,設定を確認します。
cf.get_config_file()
{'colorscale': 'dflt',
'datagen_mode': 'stocks',
'dimensions': None,
'offline': True,
'offline_link_text': 'Export to plot.ly',
'offline_show_link': True,
'offline_url': '',
'sharing': 'public',
'theme': 'pearl'}
動作確認
cf.datagen.box(20).iplot(kind='box')

ここ以降の画像は静止画像になっていますが
gifをキャプチャするのが面倒だったのでjupyter notebook上ではマウスオーバー・ドラッグ可能です。
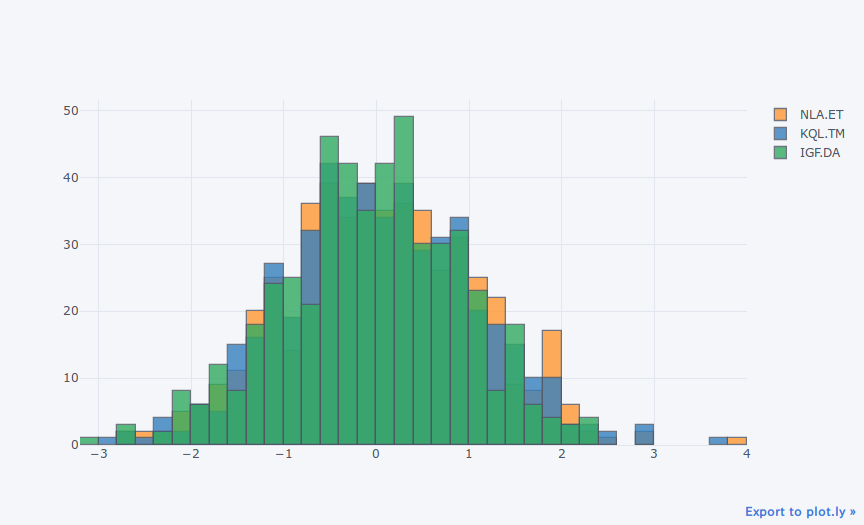
fig = cf.datagen.histogram(3).figure(kind='histogram')
cf.iplot(fig)
cufflinksによるローソク足のプロット
サンプルOHLCデータをプロット
np.random.seed(0) # ランダム状態固定
df = cf.datagen.ohlcv() # ランダムなデータを作成
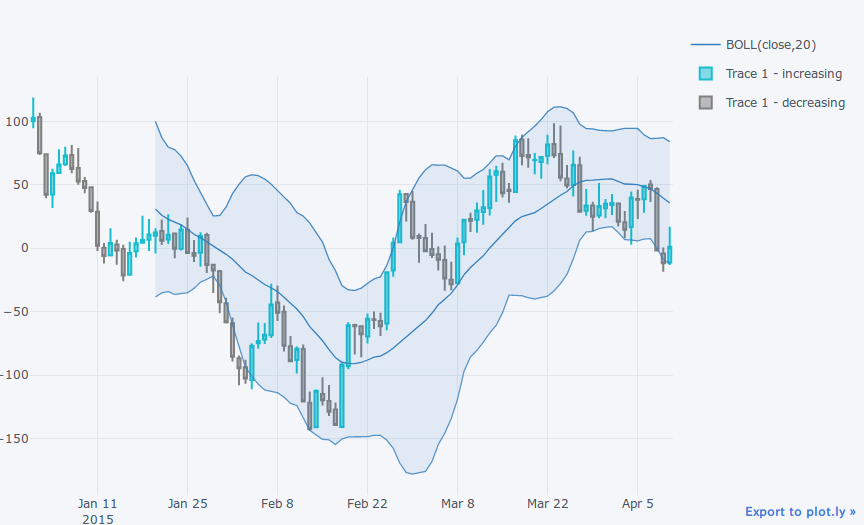
qf = cf.QuantFig(df)
qf.add_bollinger_bands() # ボリンジャーバンド追加
qf.iplot() # ローソク足プロット
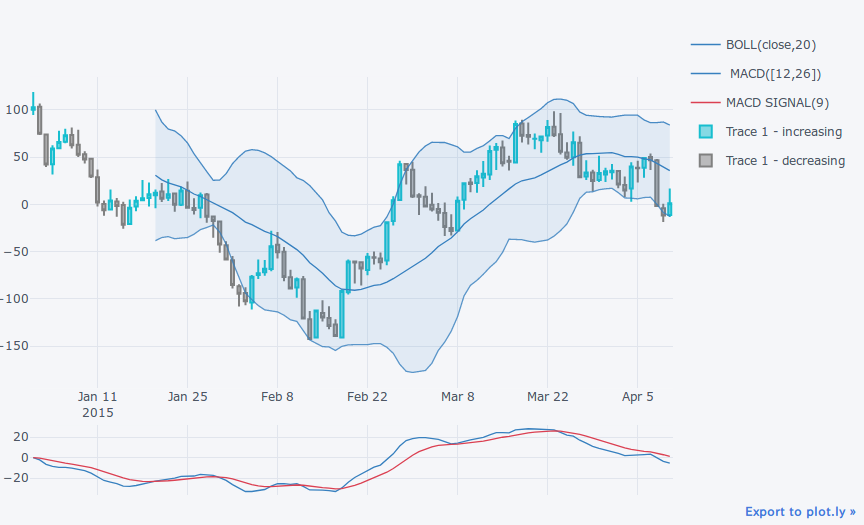
qf.add_macd() # MACD追加
qf.iplot()
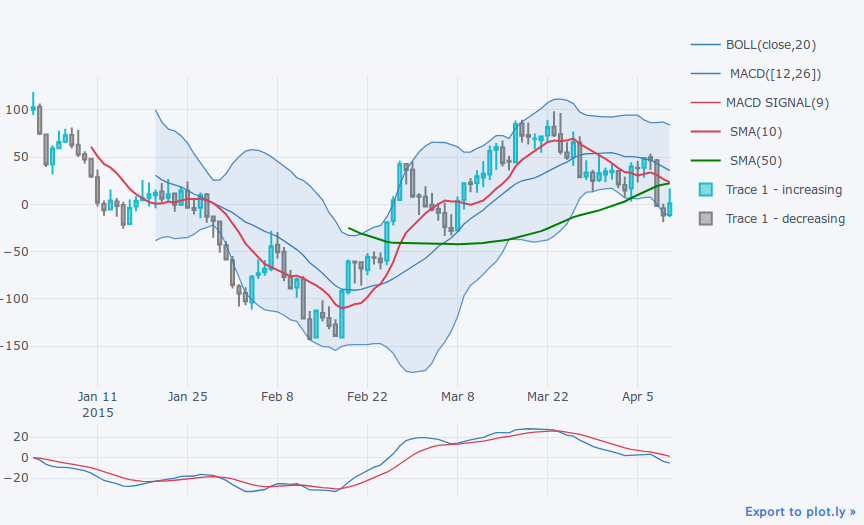
qf.add_sma([10,50],width=2, color=['red', 'green']) # 移動平均線追加
qf.iplot()
出来高も表示
qf = cf.QuantFig(df, legend='top')
qf.add_volume() # 出来高追加
qf.iplot()
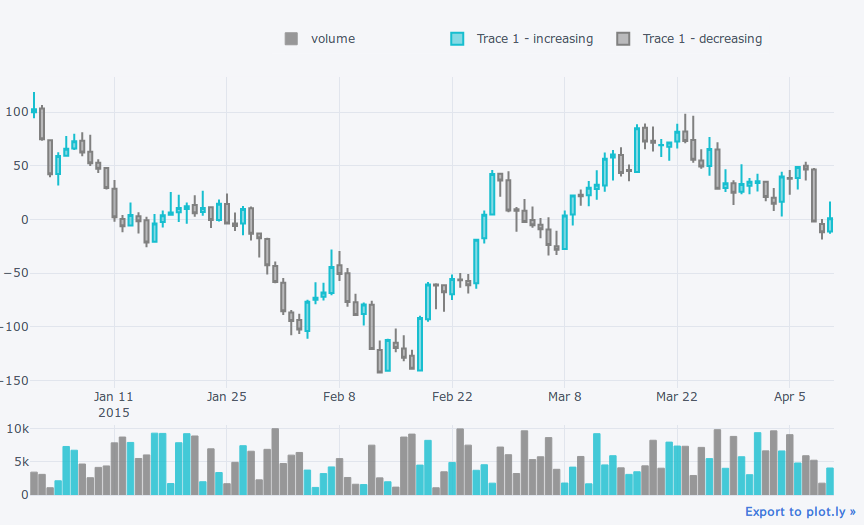
qf.add_shapes(hline=[80, -142], vline=[pd.Timestamp('20150317'), pd.Timestamp('20150218')]) # 価格80, -142に水平線
qf.iplot()
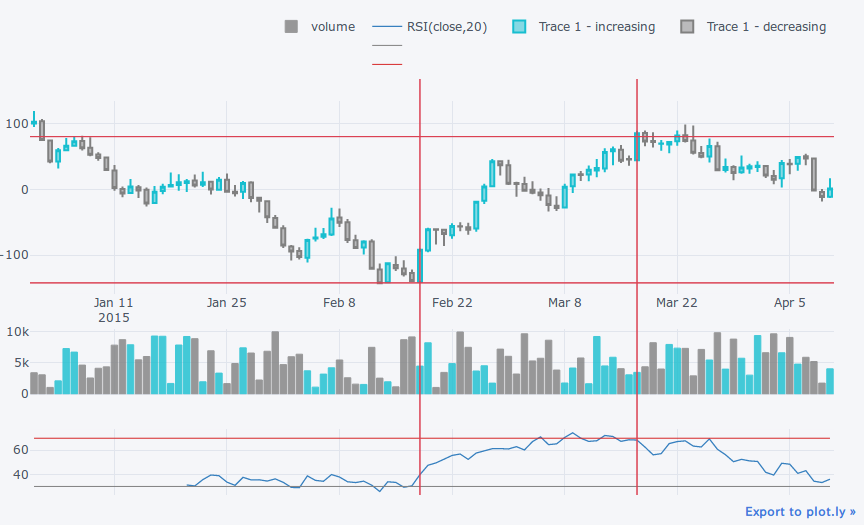
qf.add_trendline('01Jan15', '13Feb15') # トレンドラインの挿入
qf.iplot()
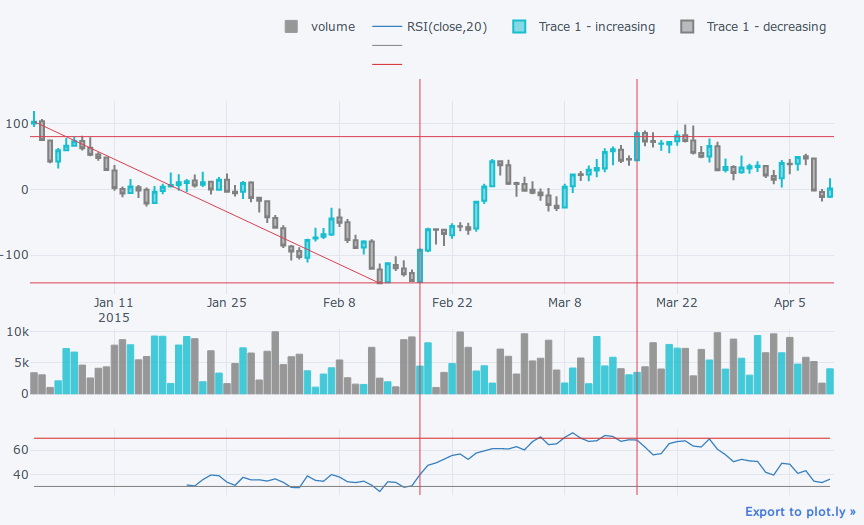
日本人にはあまり馴染みのない'%d%b%y'形式しか受け付けないようです。
自分好みの形式で入力したいときはpandas.Timestampクラスとstrftimeメソッドを混ぜて下のようにしてやると打ち込みやすいと思います。
qf = cf.QuantFig(df, legend='top')
# 上と同様に2015年1月1日から2015年2月13日
start, end = (pd.Timestamp(x).strftime('%d%b%y') for x in ('2015/1/1', '2015-2-13'))
# mapを使うならこう
# `start, end = map(lambda x: pd.Timestamp(x).strftime('%d%b%y'), ('2015/1/1', '2015-2-13'))`
qf.add_trendline(start, end)
qf.iplot()
データの取得
海外株
pandas_datareaderモジュールから米国株式のデータはダウンロードできます。
Functions from pandas_datareader.data and pandas_datareader.wb extract data from various Internet sources into a pandas DataFrame. Currently the following sources are supported:
pandas_datareader.dataとpandas_datareader.wbの関数はインターネット上の様々なデータをpandas DataFrameに抽出します。現在、以下のソースがサポートされています。
- Yahoo! Finance
- Google Finance
- Enigma
- Quandl
- St.Louis FED (FRED)
- Kenneth French’s data library
- World Bank
- OECD
- Eurostat
- Thrift Savings Plan
- Nasdaq Trader symbol definitions
インストールは
$ conda install pandas-datareader
# または
$ pip install pandas-datareader
from pandas_datareader import data
end = pd.datetime.today() # 今日の日付
start = (pd.Period(end, 'D')-300).start_time # 300日前日付
df = data.get_data_yahoo('AMZN', end=end, start=start) # 300日前からのAmazon株価取得
df.tail()
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2017-12-11 | 1164.599976 | 1169.900024 | 1157.000000 | 1168.920044 | 1168.920044 | 2363500 |
| 2017-12-12 | 1166.510010 | 1173.599976 | 1161.609985 | 1165.079956 | 1165.079956 | 2235900 |
| 2017-12-13 | 1170.000000 | 1170.869995 | 1160.270020 | 1164.130005 | 1164.130005 | 2616800 |
| 2017-12-14 | 1163.709961 | 1177.930054 | 1162.449951 | 1174.260010 | 1174.260010 | 3156600 |
| 2017-12-14 | 1163.709961 | 1177.930054 | 1162.449951 | 1176.089966 | 1176.089966 | 1873348 |
qf = cf.QuantFig(df, legend='top', name='AMZN')
qf.add_volume()
qf.iplot()
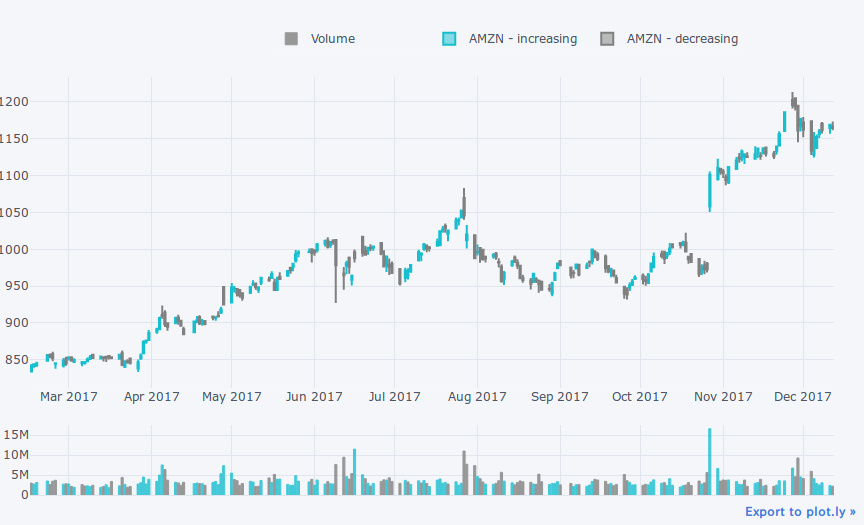
日本株
jsmモジュール利用して、日本株を取得してpandas DataFrameで返してくれるモジュールを組み立てました。
Qiita - 日本株の株価を取得してpandasデータフレームに格納する
日本の株式市場の株価・財務データを取得するツールです。
各種データは、 Yahoo!ファイナンス からスクレイピングしています。
インストールは
$ pip install jsm
from read_nikkei import get_jstock # 日本企業の株価取得モジュール
pandas_datareaderと異なる点
- 銘柄はsymbol(Amazonなら'AMZN'とする)ではなく株価コード(数字4桁)で取得
- 週足、月足での取得も可能(freq='W', freq='M'オプション)
- デフォルトは日足(freq='D')
- 期間の指定(periods=<数字>)で「endまたはstartから数えて<数字>本足の取得」
- periodsを指定するとendまたはstartオプションが必ず必要です。
- デフォルトでは、今日から数えて30日前からの日足データの取得(
freq='D', end=pd.datetime.today(), periods=30と同様)- pandas_datereaderではデフォルトで2010年1月1日から今日までの株価取得(
start=20100101, end=pd.datetime.today())
- pandas_datereaderではデフォルトで2010年1月1日から今日までの株価取得(
from read_nikkei import get_jstock
# 今日から100日前からの任天堂株価を取得
df = get_jstock(7974, end=pd.datetime.today(), periods=100)
df.tail()
Get data from 2017-09-08 to 2017-12-17
/home/u1and0/.pyenv/versions/anaconda3-5.0.0/envs/snow/lib/python3.6/site-packages/bs4/__init__.py:181: UserWarning:
No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 193 of the file /home/u1and0/.pyenv/versions/anaconda3-5.0.0/envs/snow/lib/python3.6/runpy.py. To get rid of this warning, change code that looks like this:
BeautifulSoup(YOUR_MARKUP})
to this:
BeautifulSoup(YOUR_MARKUP, "lxml")
なんかBeautifulSoup関連のワーニング出ますが、jsm作者に何とかしてもらうしかないんですかねー
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2017-12-11 | 43800 | 44380 | 43400 | 44380 | 44380 | 1822300 |
| 2017-12-12 | 44380 | 44380 | 43710 | 43900 | 43900 | 1536600 |
| 2017-12-13 | 43430 | 44140 | 43100 | 43930 | 43930 | 2045600 |
| 2017-12-14 | 43700 | 43800 | 42800 | 43010 | 43010 | 2012200 |
| 2017-12-15 | 42500 | 43380 | 42320 | 43030 | 43030 | 2283300 |
qf = cf.QuantFig(df, legend='top', name='任天堂')
qf.iplot()
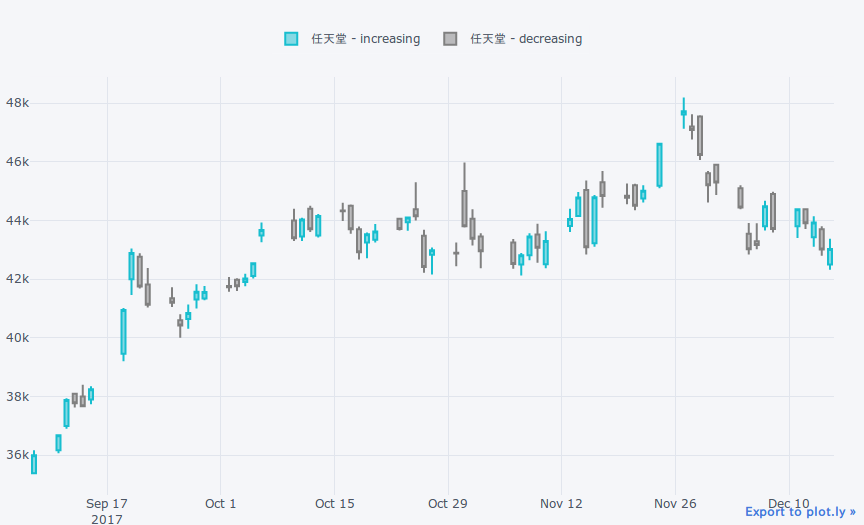
為替
為替のデータはpandas_datereaderからでもある程度は取得可能です。
遡って1996年からの日足データを手に入れることができるようです。
日足
df = data.get_data_yahoo('JPY=X', start='1990')
df.head()
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 1996-10-30 | 114.370003 | 114.480003 | 113.610001 | 114.180000 | 114.180000 | 0.0 |
| 1996-10-31 | NaN | NaN | NaN | NaN | NaN | NaN |
| 1996-11-01 | 113.500000 | 113.500000 | 113.500000 | 113.500000 | 113.500000 | 0.0 |
| 1996-11-04 | 113.349998 | 113.980003 | 112.949997 | 113.879997 | 113.879997 | 0.0 |
| 1996-11-05 | 113.709999 | 114.330002 | 113.449997 | 114.250000 | 114.250000 | 0.0 |
qf = cf.QuantFig(df[-1000:], legend='top', name='USDJPY日足') # 最後から1000本足をプロット
qf.iplot()
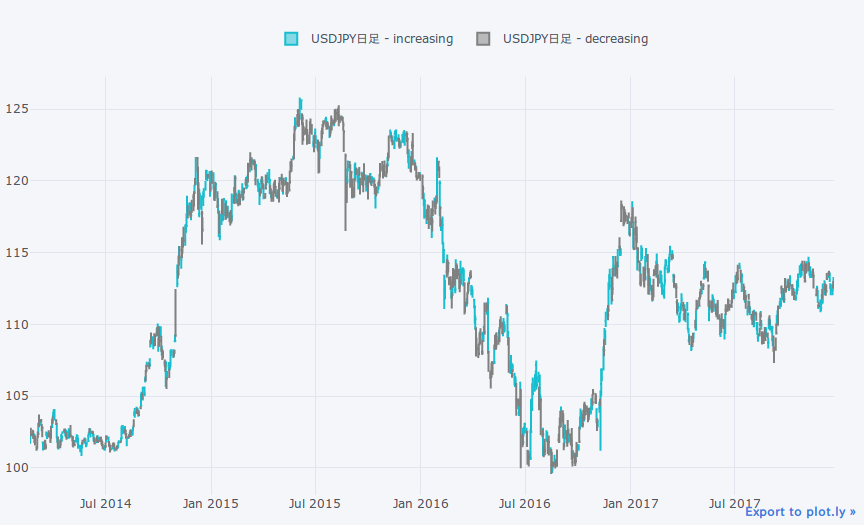
1分足
1分足を扱うにはMetaTraderなどで扱われるヒストリカルファイル(.hst)をダウンロードしてくると利用できます。
MT4,5を使っている人はPCの中のどこかに.hst拡張子のファイルがあると思うので探して下さい。
MT4,5を利用していない人はFXDD TRADINGなどからダウンロードして下さい。
wgetやaria2を使える環境にある人は
$ wget http://tools.fxdd.com/tools/M1Data/USDJPY.zip
$ aria2c -x10 -s10 -k1M http://tools.fxdd.com/tools/M1Data/USDJPY.zip
2005年からの主要通貨1分足をhstファイルを圧縮したzip形式でダウンロードできます。容量の目安は50MB程度、zip解凍すると200MB程度です。
hstファイルをpandas DataFrameに変換
hst形式のままでは使えませんので、hstファイルをpandas DataFrame形式に変換するコードを書きました。
Qiita - u1and0/MT4ヒストリカルデータをpython上で扱えるようにしたりcsvに保存する
zip解凍から行ってくれますので、ダウンロードしたファイルはzip解凍しておく必要はありません。
from read_hst import read_hst
df = read_hst('/home/u1and0/Data/USDJPY.zip')
df = df[-1000:]
df.head()
Extracting USDJPY.hst...
| open | high | low | close | volume | |
|---|---|---|---|---|---|
| time | |||||
| 2017-11-16 15:57:00 | 113.027 | 113.030 | 113.001 | 113.001 | 77.0 |
| 2017-11-16 15:58:00 | 113.003 | 113.008 | 113.002 | 113.003 | 70.0 |
| 2017-11-16 15:59:00 | 113.003 | 113.010 | 113.000 | 113.001 | 72.0 |
| 2017-11-16 16:00:00 | 113.001 | 113.015 | 112.996 | 113.015 | 78.0 |
| 2017-11-16 16:01:00 | 113.015 | 113.027 | 113.010 | 113.025 | 89.0 |
qf = cf.QuantFig(df, name='USDJPY分足')
qf.add_volume()
qf .iplot()
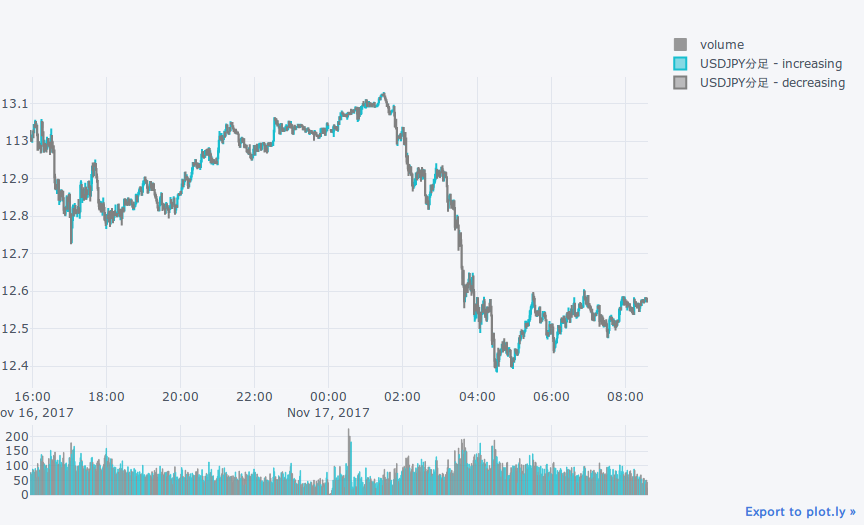
データ操作
ローソク足OHLCの時間足変換
参考: qiita - u1and0/ローソク足OHLCの時間足を変える
ohlcデータの時間軸を変えます。
def _ohlcv(columns, open=None, high=None, low=None, close=None, volume=None):
"""Make a dictionary of {open:'***', low:'***', high:'***', close:'***', volume:'***'}"""
auto_dict = {str(v).lower(): v for v in columns} # Lower case of columns dictionary
my_dict = {'open': open, 'high': high, 'low': low,
'close': close, 'volume': volume} # User defined OHLCV
updater = {k: v for k, v in my_dict.items() if v} # Remove `None` values in `my_dict`
auto_dict.update(updater) # Swap `auto_dict` with `my_dict` except `None` value
return auto_dict
def ohlc2(self, open=None, high=None, low=None, close=None, volume=None):
"""`pd.DataFrame.resample(<TimeFrame>).ohlc2()`
Resample method converting OHLC to OHLC
"""
auto_dict = _ohlcv(self.asfreq().columns, open, high, low, close, volume)
# Make dict as `agdict` for `df.resample(<Time>).agg(<dict>)`
try:
agdict = {auto_dict['open']: 'first',
auto_dict['high']: 'max',
auto_dict['low']: 'min',
auto_dict['close']: 'last'}
except KeyError as e:
raise KeyError('Columns not enough {}'.format(*e.args))
# Add `volume` columns
if 'volume' in auto_dict:
agdict[auto_dict['volume']] = 'sum'
return self.agg(agdict)
# Add instance as `pd.DataFrame.resample('<TimeFrame>').ohlc2()`
resample.DatetimeIndexResampler.ohlc2 = ohlc2
df.resample('H').ohlc2().head()
| open | high | low | close | volume | |
|---|---|---|---|---|---|
| time | |||||
| 2017-11-16 15:00:00 | 113.027 | 113.030 | 113.000 | 113.001 | 219.0 |
| 2017-11-16 16:00:00 | 113.001 | 113.059 | 112.800 | 112.840 | 6319.0 |
| 2017-11-16 17:00:00 | 112.840 | 112.951 | 112.725 | 112.783 | 6509.0 |
| 2017-11-16 18:00:00 | 112.785 | 112.888 | 112.766 | 112.884 | 5264.0 |
| 2017-11-16 19:00:00 | 112.884 | 112.905 | 112.794 | 112.857 | 4129.0 |
qf = cf.QuantFig(df.resample('H').ohlc2(), name='USDJPY時間足')
qf.add_volume()
qf.iplot()
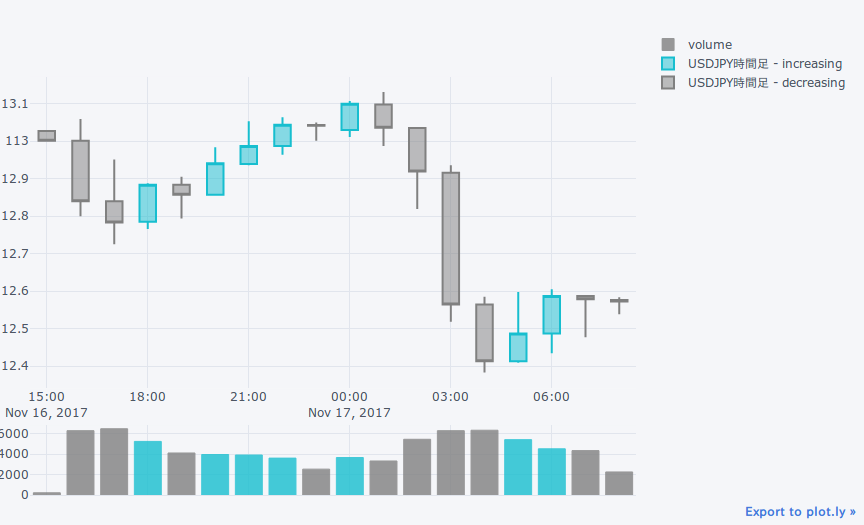
日経平均のデータを取得して、調整後終値(Adjusted Closing Price, Adj Close)を終値として扱いたいときは、ohlc2の引数に与えてあげます。
df = data.get_data_yahoo('^N225') # 日経平均日足の取得
df.head()
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2010-01-04 | 10609.339844 | 10694.490234 | 10608.139648 | 10654.790039 | 10654.790039 | 104400.0 |
| 2010-01-05 | 10719.440430 | 10791.040039 | 10655.570313 | 10681.830078 | 10681.830078 | 166200.0 |
| 2010-01-06 | 10709.549805 | 10768.610352 | 10661.169922 | 10731.450195 | 10731.450195 | 181800.0 |
| 2010-01-07 | 10742.750000 | 10774.000000 | 10636.669922 | 10681.660156 | 10681.660156 | 182600.0 |
| 2010-01-08 | 10743.299805 | 10816.450195 | 10677.559570 | 10798.320313 | 10798.320313 | 211800.0 |
df.resample('W').ohlc2().head() # 普通に週足に変換
| Open | High | Low | Close | Volume | |
|---|---|---|---|---|---|
| Date | |||||
| 2010-01-10 | 10609.339844 | 10816.450195 | 10608.139648 | 10798.320313 | 846800.0 |
| 2010-01-17 | 10770.349609 | 10982.099609 | 10729.860352 | 10982.099609 | 963000.0 |
| 2010-01-24 | 10887.610352 | 10895.099609 | 10528.330078 | 10590.549805 | 872000.0 |
| 2010-01-31 | 10478.309570 | 10566.490234 | 10198.040039 | 10198.040039 | 779500.0 |
| 2010-02-07 | 10212.360352 | 10438.410156 | 10036.330078 | 10057.089844 | 794700.0 |
df.resample('W').ohlc2(close='Adj Close').head() # 終値をAdj Closeに指定
| Open | High | Low | Adj Close | Volume | |
|---|---|---|---|---|---|
| Date | |||||
| 2010-01-10 | 10609.339844 | 10816.450195 | 10608.139648 | 10798.320313 | 846800.0 |
| 2010-01-17 | 10770.349609 | 10982.099609 | 10729.860352 | 10982.099609 | 963000.0 |
| 2010-01-24 | 10887.610352 | 10895.099609 | 10528.330078 | 10590.549805 | 872000.0 |
| 2010-01-31 | 10478.309570 | 10566.490234 | 10198.040039 | 10198.040039 | 779500.0 |
| 2010-02-07 | 10212.360352 | 10438.410156 | 10036.330078 | 10057.089844 | 794700.0 |
ohlc2()の引数にはopen, high, low, close, volumeを与えることができます。
例えば次のようにカラム名が4本値と関係ないデータを渡しても、きちんと引数を指定してやればOHLCVで変換してくれます。
np.random.seed(19)
df = cf.datagen.ohlcv() # データ生成
df.columns = range(1,6) # カラム名を数字に変える
df.head()
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 2015-01-01 | 100.000000 | 106.526092 | 77.530418 | 81.491630 | 8015 |
| 2015-01-02 | 83.748302 | 85.962681 | 63.060215 | 65.605544 | 5769 |
| 2015-01-03 | 65.592938 | 76.415738 | 47.096441 | 56.526309 | 9328 |
| 2015-01-04 | 58.160297 | 64.929405 | 52.899053 | 57.952424 | 4412 |
| 2015-01-05 | 58.498021 | 69.737244 | 34.999141 | 41.165273 | 6892 |
週足に変更するため、open, high, low, close, volumeをそれぞれ1,2,3,4,5と指定します。
df.resample('W').ohlc2(open=1, high=2, low=3, close=4, volume=5) # 引数にohlcvのカラム名を指定
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 2015-01-04 | 100.000000 | 106.526092 | 47.096441 | 57.952424 | 27524 |
| 2015-01-11 | 58.498021 | 98.722285 | 25.081057 | 85.380938 | 34592 |
| 2015-01-18 | 85.227185 | 116.629094 | 56.120302 | 104.003280 | 35803 |
| 2015-01-25 | 103.913949 | 139.336095 | 82.181452 | 109.151731 | 38910 |
| 2015-02-01 | 108.334060 | 126.237090 | 75.235135 | 101.461833 | 39578 |
| 2015-02-08 | 101.868035 | 131.537039 | 27.324298 | 57.099236 | 33278 |
| 2015-02-15 | 55.782685 | 98.734416 | 49.267611 | 61.573598 | 34527 |
| 2015-02-22 | 62.830502 | 104.472611 | 48.834591 | 85.477329 | 30116 |
| 2015-03-01 | 84.665842 | 123.096526 | 44.282473 | 121.435018 | 40203 |
| 2015-03-08 | 120.073562 | 154.933346 | 120.073562 | 123.635981 | 55421 |
| 2015-03-15 | 123.368637 | 130.713508 | 54.363323 | 74.063469 | 50965 |
| 2015-03-22 | 72.393416 | 130.067377 | 61.799581 | 119.121722 | 35717 |
| 2015-03-29 | 120.383713 | 213.487056 | 111.342313 | 202.147684 | 36784 |
| 2015-04-05 | 202.951959 | 211.550772 | 102.660010 | 106.082669 | 42398 |
| 2015-04-12 | 106.244248 | 115.505312 | 76.272411 | 106.781127 | 23787 |
ただし、カラム名がFalseになるもの(0, None, False, np.NaNなど)を指定すると失敗します。
平均足
def heikin_ashi(self, open=None, high=None, low=None, close=None):
"""Return HEIKIN ASHI columns"""
df = self.copy()
auto_dict = _ohlcv(df.columns, open, high, low, close)
df['hopen'] = (df[auto_dict['open']].shift() + df[auto_dict['close']].shift()) / 2
df['hclose'] = df[[auto_dict['open'],
auto_dict['high'],
auto_dict['low'],
auto_dict['close']]].mean(1)
df['hhigh'] = df[[auto_dict['high'], 'hopen', 'hclose']].max(1)
df['hlow'] = df[[auto_dict['low'], 'hopen', 'hclose']].min(1)
return df[['hopen', 'hhigh', 'hlow', 'hclose']]
pd.DataFrame.heikin_ashi = heikin_ashi
df = data.get_data_yahoo('^GSPC') # S&P500指数の取得
df.tail()
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2017-12-18 | 2685.919922 | 2694.969971 | 2685.919922 | 2690.159912 | 2690.159912 | 3724660000 |
| 2017-12-19 | 2692.709961 | 2694.439941 | 2680.739990 | 2681.469971 | 2681.469971 | 3368590000 |
| 2017-12-20 | 2688.179932 | 2691.010010 | 2676.110107 | 2679.250000 | 2679.250000 | 3241030000 |
| 2017-12-21 | 2683.020020 | 2692.639893 | 2682.399902 | 2684.570068 | 2684.570068 | 3273390000 |
| 2017-12-22 | 2684.219971 | 2685.350098 | 2678.129883 | 2683.340088 | 2683.340088 | 2399830000 |
普通にローソク足の表示
qf = cf.QuantFig(df, name='S&P500ローソク足', legend='top',
slice=(pd.Timestamp('20170901'), pd.Timestamp('20171220')))
qf.iplot()
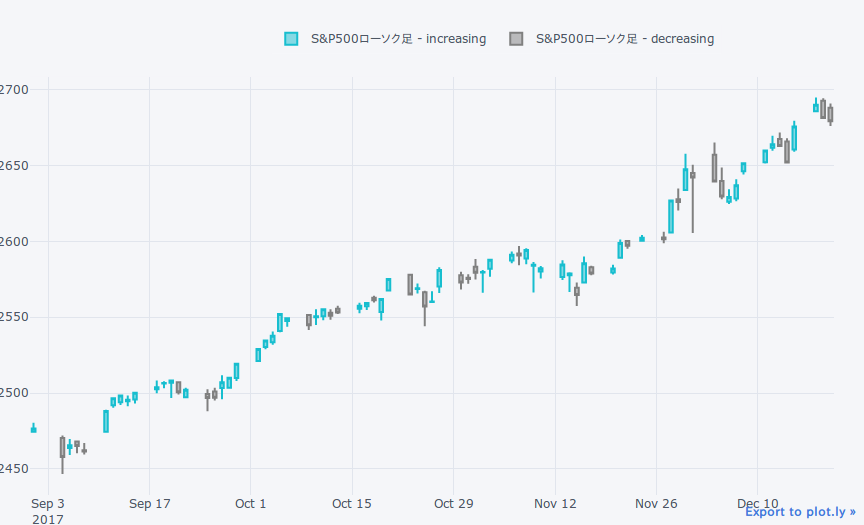
平均足の表示は平均足メソッドを使用します。
he = df.heikin_ashi()
he.tail()
| hopen | hhigh | hlow | hclose | |
|---|---|---|---|---|
| Date | ||||
| 2017-12-18 | 2668.219971 | 2694.969971 | 2668.219971 | 2689.242432 |
| 2017-12-19 | 2688.039917 | 2694.439941 | 2680.739990 | 2687.339966 |
| 2017-12-20 | 2687.089966 | 2691.010010 | 2676.110107 | 2683.637512 |
| 2017-12-21 | 2683.714966 | 2692.639893 | 2682.399902 | 2685.657471 |
| 2017-12-22 | 2683.795044 | 2685.350098 | 2678.129883 | 2682.760010 |
qf = cf.QuantFig(he, name='S&P500平均足', legend='top',
slice=(pd.Timestamp('20170901'), pd.Timestamp('20171220')))
qf.iplot()
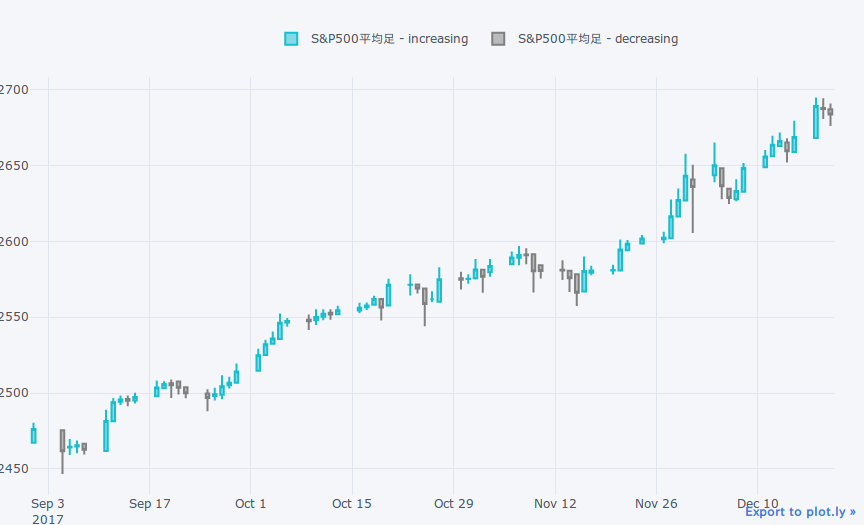
ローソク足と比べて陽線、陰線が続きやすくなっています。
まとめ
- グラフの描画
-
plotlyとpandasをの合わせ技をやりやすくしてくれるcufflinks
-
- データの取得
- 海外株、主要通貨、主要指数 →
pandas-datareader - 日本株 →
jsm+ 自作モジュールでpandas DataFrame化 - 為替の1分足 → FXDDからhstファイルをダウンロード + 自作モジュールでpandas DataFrame化
- 海外株、主要通貨、主要指数 →
- データ操作
- OHLCをOHLCに変換 → 自作ohlc2()メソッド
- 平均足 → 自作heikinashi()メソッド