目的
うちの奥さんが「火曜日・水曜日は雨が多い」と言っていたので、曜日ごとに天気を集計し、どの曜日にどんな天気が多いか可視化して確かめてみます。
下準備
モジュールインポートと関数定義
import pandas as pd
pandasのユーティリティメソッドとして自作メソッドless()を定義しておきます。
機能はデータの頭とお尻を5行ずつ表示するものです。
dataframeのメソッドhead() tail() を組み合わせたものです。
pandas DataFrameの出力行を絞るheadとtailを同時に使う
def _less(self, n=10):
"""Append `df.head()` with `df.tail()`
データの頭とお尻の表示
"""
return self.head(n // 2).append(self.tail(n // 2))
# df.less()のようにメソッドとして使えるようにする
setattr(pd.DataFrame, 'less', _less)
setattr(pd.Series, 'less', _less)
データのダウンロード
データは気象庁HPからcsv形式でダウンロードします。
1989年1月13日〜2019年1月13日までの30年分の東京の天気をダウンロードしました。
エンコードがShift_JISなので、nkfを使ってUTF-8に変換しておきます。
(pandas.read_csv() の機能でエンコード変換がありますが、別の機会でも使いまわしたり、UNIX環境ですぐ表示できたりするためには元々をUTF-8で置いておくのが良いと思います。)
!nkf -u data.csv > tokyo_weather.csv # utf-8形式に変換
# ダウンロードしたcsvの表示
data = pd.read_csv('tokyo_weather.csv',header=2, index_col=0, parse_dates=True)
data.less()
| 天気概況(昼:06時〜18時) | 天気概況(昼:06時〜18時).1 | 天気概況(昼:06時〜18時).2 | |
|---|---|---|---|
| 年月日 | |||
| NaT | NaN | 品質情報 | 均質番号 |
| 1989-01-13 | 曇一時雨 | 8 | 1 |
| 1989-01-14 | 曇 | 8 | 1 |
| 1989-01-15 | 曇一時雨 | 8 | 1 |
| 1989-01-16 | 晴一時曇 | 8 | 1 |
| 2019-01-09 | 快晴 | 8 | 1 |
| 2019-01-10 | 曇時々晴 | 8 | 1 |
| 2019-01-11 | 晴 | 8 | 1 |
| 2019-01-12 | 曇時々雨 | 8 | 1 |
| 2019-01-13 | 晴一時曇 | 8 | 1 |
データ整理
データクリーニング
必要なデータは"天気概況(昼:06時〜18時)"の1列のみ。品質番号はいらないので、2,3列目は省きます。
同時に、2つめのヘッダー品質情報・均質番号も取り除き、 pandas.Series形式で保存します。
(あとで気づきましたが、品質情報・均質番号はダウンロードの際に省くことができるようです。)
# データの一部削除・pickle形式での保存
data = data.iloc[1:, 0]
data.to_pickle('tokyo_weather.pkl')
data = pd.read_pickle('tokyo_weather.pkl')
data.less()
年月日
1989-01-13 曇一時雨
1989-01-14 曇
1989-01-15 曇一時雨
1989-01-16 晴一時曇
1989-01-17 曇一時晴
2019-01-09 快晴
2019-01-10 曇時々晴
2019-01-11 晴
2019-01-12 曇時々雨
2019-01-13 晴一時曇
Name: 天気概況(昼:06時〜18時), dtype: object
欠落情報の確認。
pd.DataFrame().isna() でnan値のbool列を作り出して合計して0が出ればnan値がありません。
bool列の中に1個でもTrueがあれば1がでます。
data.isna().sum()
0
0がでたのでデータ欠損はありません。
曜日列の追加
日付けを曜日に変更します。
dataframeのindexにある属性に weekday_name があります。
df = pd.DataFrame({'曜日':data.index.weekday_name, '天気':data})
df.less()
| 曜日 | 天気 | |
|---|---|---|
| 年月日 | ||
| 1989-01-13 | Friday | 曇一時雨 |
| 1989-01-14 | Saturday | 曇 |
| 1989-01-15 | Sunday | 曇一時雨 |
| 1989-01-16 | Monday | 晴一時曇 |
| 1989-01-17 | Tuesday | 曇一時晴 |
| 2019-01-09 | Wednesday | 快晴 |
| 2019-01-10 | Thursday | 曇時々晴 |
| 2019-01-11 | Friday | 晴 |
| 2019-01-12 | Saturday | 曇時々雨 |
| 2019-01-13 | Sunday | 晴一時曇 |
これを用いて、インデックスを曜日にしたpandas.Seriesを作ります。
weather = df['天気']
weather.index = df['曜日']
weather.less()
曜日
Friday 曇一時雨
Saturday 曇
Sunday 曇一時雨
Monday 晴一時曇
Tuesday 曇一時晴
Wednesday 快晴
Thursday 曇時々晴
Friday 晴
Saturday 曇時々雨
Sunday 晴一時曇
Name: 天気, dtype: object
ここまで df なんて作らずに一発で変換することもできますが、 df は後でも使うので残しておきます。。
ちなみに、data から df を噛まさずに変換するなら
weather = data.copy()
weather.index = data.index.weekday_name
weather.index.name = '曜日'
天気のカウント
晴れとか曇りの数を数えてみます。
value_count() メソッドを使用します。
# 天気のカウント、上位20を表示
weather.value_counts().head(20)
晴 1686
快晴 1022
曇 998
晴一時曇 598
曇一時雨 398
曇一時晴 389
晴時々曇 385
曇時々晴 378
曇後晴 312
雨 299
曇時々雨 299
晴後曇 262
晴後一時曇 261
雨時々曇 240
薄曇 222
曇後雨 205
雨一時曇 185
晴後薄曇 184
曇後一時雨 174
雨後曇 171
Name: 天気, dtype: int64
天気の区分って「晴れ」「曇り」たくさんあることを知りました。(csv見たときに気づけ!)
簡単化するために、「晴れ」「曇り」「雨」「雪」の4区分にざっくり分類し直します。
天気の分類
例えば「曇一時雨」といった名前の天気は「晴れ」「曇り」「雨」「雪」のうちどれに当てはまるでしょうか?
おそらく「曇り」と答える人が多いでしょう。(雨は一時的なものだからメインではない。)
例えば「大雨後曇」といった名前の天気は「晴れ」「曇り」「雨」「雪」のうちどれに当てはまるでしょうか?
先程より意見はわかれるかもしれませんが、おそらく「雨」と答える人が多いでしょう。(後に曇りだから大雨がメインの天気でしょう。)
この規則で行くと、「晴」「曇」「雨」「雪」のうち最初に現れた文字をメインの天気として捉えて4分類してよいでしょう。(大雑把に。)
# 天気を表した文字列に対して
# 「晴れ」「曇り」「雨」「雪」の4区分に最初にマッチした文字を表示
word = ['晴', '曇', '雨', '雪']
testword = '大雨後曇'
test_weth = [i for i in testword if i in word]
test_weth
['雨', '曇']
文字列はシーケンスなので for で回すと1字ずつ抜かれていくので、あとは if で word の中にある文字あ合った時に i に格納して test_weth 要素の一つとします。
test_weth の最初の文字をメインの天気とするにはスライスで [0] とします。
test_weth[0]
'雨'
関数化します。
def weather_sw(wtype):
"""天気の分類4タイプ"""
word = ['晴', '曇', '雨', '雪']
wli = [i for i in wtype if i in word]
return wli[0]
先程のweatherシリーズすべての要素に関数を適用して、天気を4区分に分類します。
weather.apply(weather_sw).head(20)
曜日
Friday 曇
Saturday 曇
Sunday 曇
Monday 晴
Tuesday 曇
Wednesday 晴
Thursday 曇
Friday 雨
Saturday 晴
Sunday 晴
Monday 雨
Tuesday 晴
Wednesday 晴
Thursday 雨
Friday 晴
Saturday 晴
Sunday 晴
Monday 晴
Tuesday 晴
Wednesday 曇
Name: 天気, dtype: object
関数を作るまでもなく、 more_itertools モジュールの first_true() で同じことができます。
# weatherデータの中の最初に出てくる'晴曇雨雪'の中の文字を返す
from more_itertools import first_true
weather.apply(first_true, pred=lambda x: x in list('晴曇雨雪')).head(20)
曜日
Friday 曇
Saturday 曇
Sunday 曇
Monday 晴
Tuesday 曇
Wednesday 晴
Thursday 曇
Friday 雨
Saturday 晴
Sunday 晴
Monday 雨
Tuesday 晴
Wednesday 晴
Thursday 雨
Friday 晴
Saturday 晴
Sunday 晴
Monday 晴
Tuesday 晴
Wednesday 曇
Name: 天気, dtype: object
曜日ごとの天気を集計
本来の目的、各曜日の天気をカウントしていきます。
- 先程定義した関数をシリーズのデータごとに適用して、天気を4分類します。
- インデックス(曜日)でグループ化します。
-
values_count()メソッドで天気をインデックス(曜日)ごとにカウントします。
# 4分類した天気を曜日ごとに集計
weather_four = weather.apply(first_true, pred=lambda x: x in list('晴曇雨雪'))
# weather_sw()関数をシリーズのデータに適用
weather_group = weather_four.groupby(level=0) # インデックスでグループ化
weather_count = weather_group.value_counts() # グループ化したデータに対してデータカウント
weather_count
曜日 天気
Friday 晴 771
曇 588
雨 201
雪 6
Monday 晴 694
曇 663
雨 204
雪 4
Saturday 晴 737
曇 627
雨 192
雪 10
Sunday 晴 711
曇 655
雨 194
雪 6
Thursday 晴 756
曇 601
雨 205
雪 3
Tuesday 晴 738
曇 635
雨 189
雪 3
Wednesday 晴 747
曇 602
雨 213
雪 3
Name: 天気, dtype: int64
天気ランキング(曜日ごと)
思っていたのと違ったテーブルが出てきたので、データを再調整します。
やりたいこと
- 曜日ごとではなく天気ごとにグループ化
- 天気の多い順に曜日を並べ替えて天気ごとの曜日ランキングにする。
breakdown = weather_count.swaplevel(0) # 天気ごとに区分するようにlevelを交換
sort_by_weather = breakdown.sort_index() # 天気ごとのグループで表示
weather_ranking = sort_by_weather.sort_values(ascending=False) # 天気の数で曜日を並び替え
weather_ranking
天気 曜日
晴 Friday 771
Thursday 756
Wednesday 747
Tuesday 738
Saturday 737
Sunday 711
Monday 694
曇 Monday 663
Sunday 655
Tuesday 635
Saturday 627
Wednesday 602
Thursday 601
Friday 588
雨 Wednesday 213
Thursday 205
Monday 204
Friday 201
Sunday 194
Saturday 192
Tuesday 189
雪 Saturday 10
Friday 6
Sunday 6
Monday 4
Tuesday 3
Thursday 3
Wednesday 3
Name: 天気, dtype: int64
お待ちかねの「雨が多い曜日ランキング」
weather_ranking['雨']
曜日
Wednesday 213
Thursday 205
Monday 204
Friday 201
Sunday 194
Saturday 192
Tuesday 189
Name: 天気, dtype: int64
雨が多い曜日ランキングを見てみると、30年間で水曜日が雨の日が213日でトップのようです。
一方で火曜日雨の日は189日で最下位でした。
年代ごとに集計
年代ごとの曜日ごとに階層化します。
df.less()
| 曜日 | 天気 | |
|---|---|---|
| 年月日 | ||
| 1989-01-13 | Friday | 曇一時雨 |
| 1989-01-14 | Saturday | 曇 |
| 1989-01-15 | Sunday | 曇一時雨 |
| 1989-01-16 | Monday | 晴一時曇 |
| 1989-01-17 | Tuesday | 曇一時晴 |
| 2019-01-09 | Wednesday | 快晴 |
| 2019-01-10 | Thursday | 曇時々晴 |
| 2019-01-11 | Friday | 晴 |
| 2019-01-12 | Saturday | 曇時々雨 |
| 2019-01-13 | Sunday | 晴一時曇 |
最初に作ったデータフレーム df に"年"列を追加します。
天気列は先ほどと同様に4分類にしておきます。
# 年列作成・天気列分類
dft = df.copy()
dft['年'] = df.index.year
dft['天気'] = dft['天気'].apply(first_true, pred=lambda x: x in list('晴曇雨雪'))
dft.less()
| 曜日 | 天気 | 年 | |
|---|---|---|---|
| 年月日 | |||
| 1989-01-13 | Friday | 曇 | 1989 |
| 1989-01-14 | Saturday | 曇 | 1989 |
| 1989-01-15 | Sunday | 曇 | 1989 |
| 1989-01-16 | Monday | 晴 | 1989 |
| 1989-01-17 | Tuesday | 曇 | 1989 |
| 2019-01-09 | Wednesday | 晴 | 2019 |
| 2019-01-10 | Thursday | 曇 | 2019 |
| 2019-01-11 | Friday | 晴 | 2019 |
| 2019-01-12 | Saturday | 曇 | 2019 |
| 2019-01-13 | Sunday | 晴 | 2019 |
クロステーブル pandas.crosstab() で集計します。
年代別かつ天気別に曜日を集計したいので、 [dft['年'],dft['天気']], dft['曜日'] のようにしてMultiIndexになるような指定をします。
# 年・天気別に曜日を集計
weather_crs = pd.crosstab([dft['年'],dft['天気']], dft['曜日'])
weather_crs.less(28)
| 曜日 | Friday | Monday | Saturday | Sunday | Thursday | Tuesday | Wednesday | |
|---|---|---|---|---|---|---|---|---|
| 年 | 天気 | |||||||
| 1989 | 晴 | 20 | 24 | 20 | 25 | 21 | 20 | 20 |
| 曇 | 16 | 16 | 21 | 16 | 23 | 20 | 19 | |
| 雨 | 15 | 10 | 10 | 10 | 6 | 10 | 11 | |
| 1990 | 晴 | 24 | 26 | 27 | 22 | 29 | 27 | 25 |
| 曇 | 16 | 22 | 15 | 21 | 16 | 16 | 17 | |
| 雨 | 12 | 5 | 10 | 9 | 6 | 8 | 9 | |
| 雪 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | |
| 1991 | 晴 | 27 | 26 | 19 | 23 | 23 | 29 | 29 |
| 曇 | 15 | 15 | 22 | 20 | 17 | 19 | 17 | |
| 雨 | 10 | 11 | 11 | 9 | 12 | 5 | 6 | |
| 1992 | 晴 | 33 | 28 | 26 | 26 | 24 | 29 | 28 |
| 曇 | 14 | 17 | 17 | 22 | 21 | 14 | 22 | |
| 雨 | 5 | 7 | 9 | 4 | 8 | 9 | 3 | |
| 1993 | 晴 | 26 | 20 | 24 | 22 | 26 | 24 | 22 |
| 2015 | 雪 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2016 | 晴 | 30 | 10 | 25 | 18 | 24 | 21 | 16 |
| 曇 | 16 | 30 | 24 | 26 | 22 | 23 | 33 | |
| 雨 | 7 | 12 | 4 | 8 | 5 | 8 | 3 | |
| 雪 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
| 2017 | 晴 | 25 | 29 | 24 | 27 | 25 | 25 | 25 |
| 曇 | 23 | 19 | 19 | 18 | 21 | 20 | 20 | |
| 雨 | 4 | 4 | 9 | 8 | 6 | 7 | 7 | |
| 2018 | 晴 | 26 | 23 | 27 | 27 | 19 | 24 | 18 |
| 曇 | 17 | 26 | 22 | 20 | 28 | 23 | 26 | |
| 雨 | 8 | 3 | 3 | 5 | 5 | 5 | 7 | |
| 雪 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | |
| 2019 | 晴 | 2 | 1 | 1 | 1 | 1 | 2 | 2 |
| 曇 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
stack() でシリーズに戻してやったほうが見やすいかもしれません。
# 曜日列をインデックス化
weather_ranking_by_year = weather_crs.stack()
weather_ranking_by_year.less(42)
年 天気 曜日
1989 晴 Friday 20
Monday 24
Saturday 20
Sunday 25
Thursday 21
Tuesday 20
Wednesday 20
曇 Friday 16
Monday 16
Saturday 21
Sunday 16
Thursday 23
Tuesday 20
Wednesday 19
雨 Friday 15
Monday 10
Saturday 10
Sunday 10
Thursday 6
Tuesday 10
Wednesday 11
2018 雪 Friday 1
Monday 1
Saturday 0
Sunday 0
Thursday 0
Tuesday 0
Wednesday 1
2019 晴 Friday 2
Monday 1
Saturday 1
Sunday 1
Thursday 1
Tuesday 2
Wednesday 2
曇 Friday 0
Monday 0
Saturday 1
Sunday 1
Thursday 1
Tuesday 0
Wednesday 0
dtype: int64
雨の日だけ抽出するために loc[] を使います。
# 雨の日だけ選択
rainyday = weather_ranking_by_year.loc[:, '雨']
rainyday.less(7*4) # 頭とお尻7*4行表示
年 曜日
1989 Friday 15
Monday 10
Saturday 10
Sunday 10
Thursday 6
Tuesday 10
Wednesday 11
1990 Friday 12
Monday 5
Saturday 10
Sunday 9
Thursday 6
Tuesday 8
Wednesday 9
2017 Friday 4
Monday 4
Saturday 9
Sunday 8
Thursday 6
Tuesday 7
Wednesday 7
2018 Friday 8
Monday 3
Saturday 3
Sunday 5
Thursday 5
Tuesday 5
Wednesday 7
dtype: int64
-
sort_values()で多い順に並べ替えようとしたら階層構造崩れたのでやめました。 - 2019年はまだ昼に雨が降っていないようなので表から抜けています。
年/曜日の表に並んでいたほうが見やすいかもしれません。
# 曜日別/年代別 雨の日数
rainy_table = rainyday.unstack() # 曜日インデックスを列にする
rainy_table.rename({
"Monday": "月",
"Tuesday": "火",
"Wednesday": "水",
"Thursday": "木",
"Friday": "金",
"Saturday": "土",
"Sunday": "日",
}, axis='columns', inplace=True) # カラム名を和名に変更
rainy_table = rainy_table.loc[:,list('月火水木金土日')] # 月〜日順に並び替え
rainy_table
| 曜日 | 月 | 火 | 水 | 木 | 金 | 土 | 日 |
|---|---|---|---|---|---|---|---|
| 年 | |||||||
| 1989 | 10 | 10 | 11 | 6 | 15 | 10 | 10 |
| 1990 | 5 | 8 | 9 | 6 | 12 | 10 | 9 |
| 1991 | 11 | 5 | 6 | 12 | 10 | 11 | 9 |
| 1992 | 7 | 9 | 3 | 8 | 5 | 9 | 4 |
| 1993 | 8 | 8 | 10 | 9 | 7 | 9 | 7 |
| 1994 | 3 | 4 | 4 | 6 | 4 | 3 | 4 |
| 1995 | 7 | 5 | 4 | 4 | 8 | 6 | 6 |
| 1996 | 5 | 8 | 6 | 4 | 9 | 5 | 6 |
| 1997 | 8 | 7 | 7 | 5 | 4 | 7 | 6 |
| 1998 | 7 | 4 | 6 | 7 | 13 | 7 | 5 |
| 1999 | 4 | 4 | 9 | 4 | 5 | 5 | 6 |
| 2000 | 7 | 4 | 9 | 5 | 5 | 4 | 6 |
| 2001 | 6 | 4 | 8 | 11 | 7 | 4 | 4 |
| 2002 | 8 | 9 | 6 | 6 | 9 | 4 | 6 |
| 2003 | 12 | 10 | 6 | 6 | 4 | 8 | 5 |
| 2004 | 9 | 6 | 5 | 4 | 6 | 5 | 9 |
| 2005 | 8 | 7 | 9 | 5 | 2 | 4 | 2 |
| 2006 | 5 | 7 | 11 | 7 | 6 | 5 | 8 |
| 2007 | 3 | 7 | 8 | 6 | 4 | 6 | 8 |
| 2008 | 10 | 7 | 3 | 7 | 5 | 7 | 8 |
| 2009 | 6 | 5 | 7 | 8 | 11 | 5 | 7 |
| 2010 | 7 | 3 | 9 | 11 | 2 | 6 | 4 |
| 2011 | 6 | 3 | 7 | 5 | 4 | 8 | 4 |
| 2012 | 4 | 7 | 4 | 6 | 7 | 11 | 8 |
| 2013 | 6 | 7 | 10 | 7 | 7 | 5 | 5 |
| 2014 | 8 | 4 | 11 | 14 | 3 | 8 | 8 |
| 2015 | 5 | 7 | 8 | 10 | 8 | 4 | 9 |
| 2016 | 12 | 8 | 3 | 5 | 7 | 4 | 8 |
| 2017 | 4 | 7 | 7 | 6 | 4 | 9 | 8 |
| 2018 | 3 | 5 | 7 | 5 | 8 | 3 | 5 |
pandas.DataFrame.style を使って年代ごとに、最も雨の多い曜日の背景を赤くします。(qiitaで色表示がうまくいかなかったのでスクリーンショット)
# 行に対する最大値の背景を赤くする
def highlight_max(s):
''' highlight the maximum in a Series red. '''
is_max = s == s.max()
return ['background-color: red' if v else '' for v in is_max]
rainy_table.style.apply(highlight_max, axis=1)
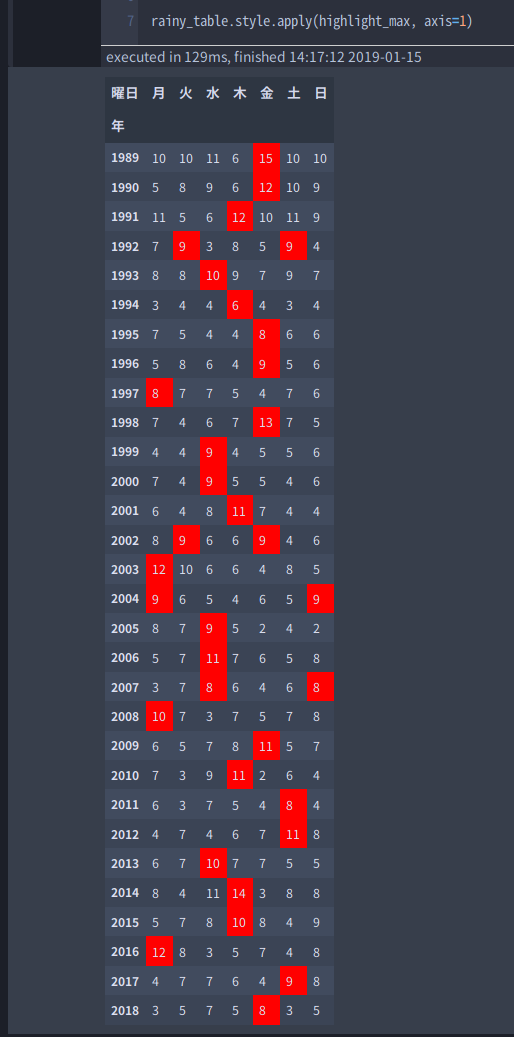
水曜日だけが必ずしも雨が多いわけではなさそうですね。
パッと見。続くかも。