はじめに
株式会社マーズフラッグ の CGO(Chief Geek Officer) 草間と申します。
8bit時代からPCを使い続け、現在もIT業界で働き、会社ではエンジニアをしています。
本記事は、現在の会社の業務とは無関係の、趣味のページとなっていることをご了承下さい。
本記事の目的
最近流行りの、AIを用いたリアルタイムボイスチェンジャーの簡単な説明と、実際に最短で試す為の手順をメモとして残します。
ボイスチェンジャーとは
入力された音声に対して何らかの加工を施すことで、別の声色を作り出す仕組みです。
古くはボコーダーと呼ばれるエフェクターによるロボット声の楽曲内利用から、ニュース等メディアにおける音声の匿名化、最近ではYouTube等の動画プラットフォーム上でのVTuberやVRChatなどの仮想空間上にて、登場キャラクターや自分のアバターに合わせた声を使いたいシーンなどで活用されています。
ハードウェアボイスチェンジャー
主に、声の高さ(ピッチ)や声質(フォルマント)等をアナログ信号処理する機械(ハードウェア)を指します。
ソフトウェアボイスチェンジャー
ハードウェアボイスチェンジャーの処理をデジタル化したものの他、最近では音声に対する直接の加工ではなく、AIにより学習モデルを用いて入力された音声をリアルタイムで再構成する仕組みのものが登場しました。
特に後者は、近年の目覚ましいGPUの高速化により、急速に一般化した技術となります。
実際に使ってみる
ここでは、AIによるソフトウェアボイスチェンジャー「VC Client」を実際に使ってみます。
音声の学習モデルに関しては、一から作成せずに、既存のデータを利用することとします。
尚、動作環境に関しては、直接バイナリインストールの他、DockerやAnacondaといった仮想環境や、GoogleColabを使う方法もあります。
以降は、バイナリインストールの手順となります。
ダウンロード
①ボイスチェンジャーソフトウェア
今回利用するVC Clientは、RVC(Retrieval-based-Voice-Conversion)やMMVC(RealTime-Many to Many Voice Conversion)、その他の各種音声変換AIエンジンに対応しています。
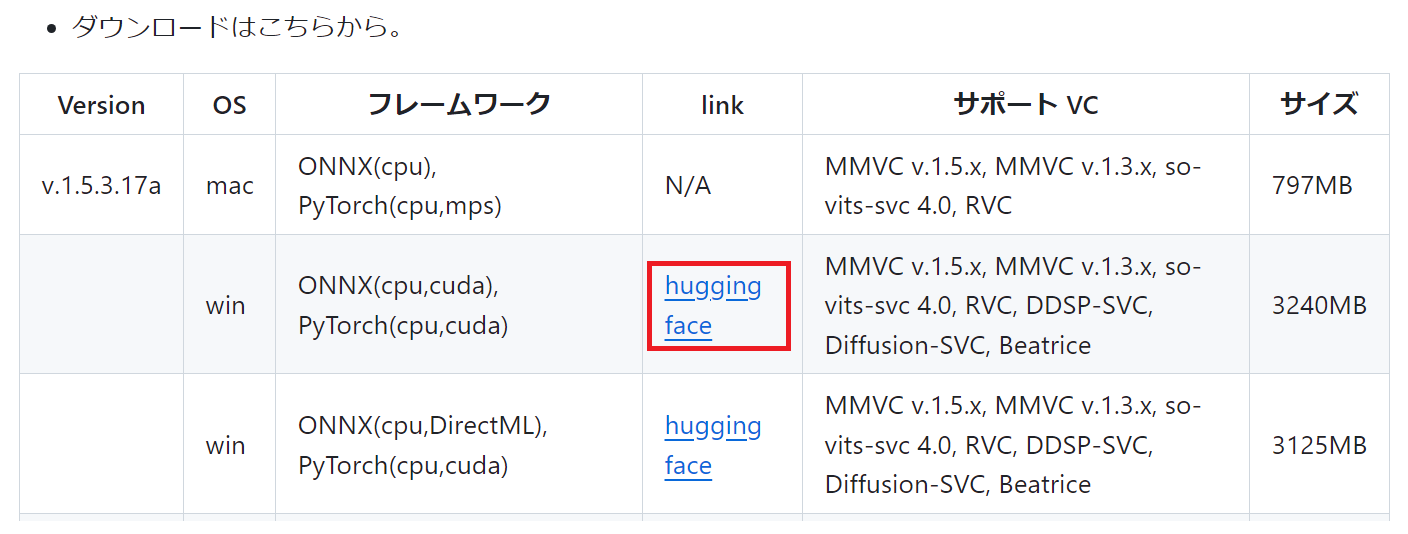
リンク先はどれも同じなので、huggin face をクリック。
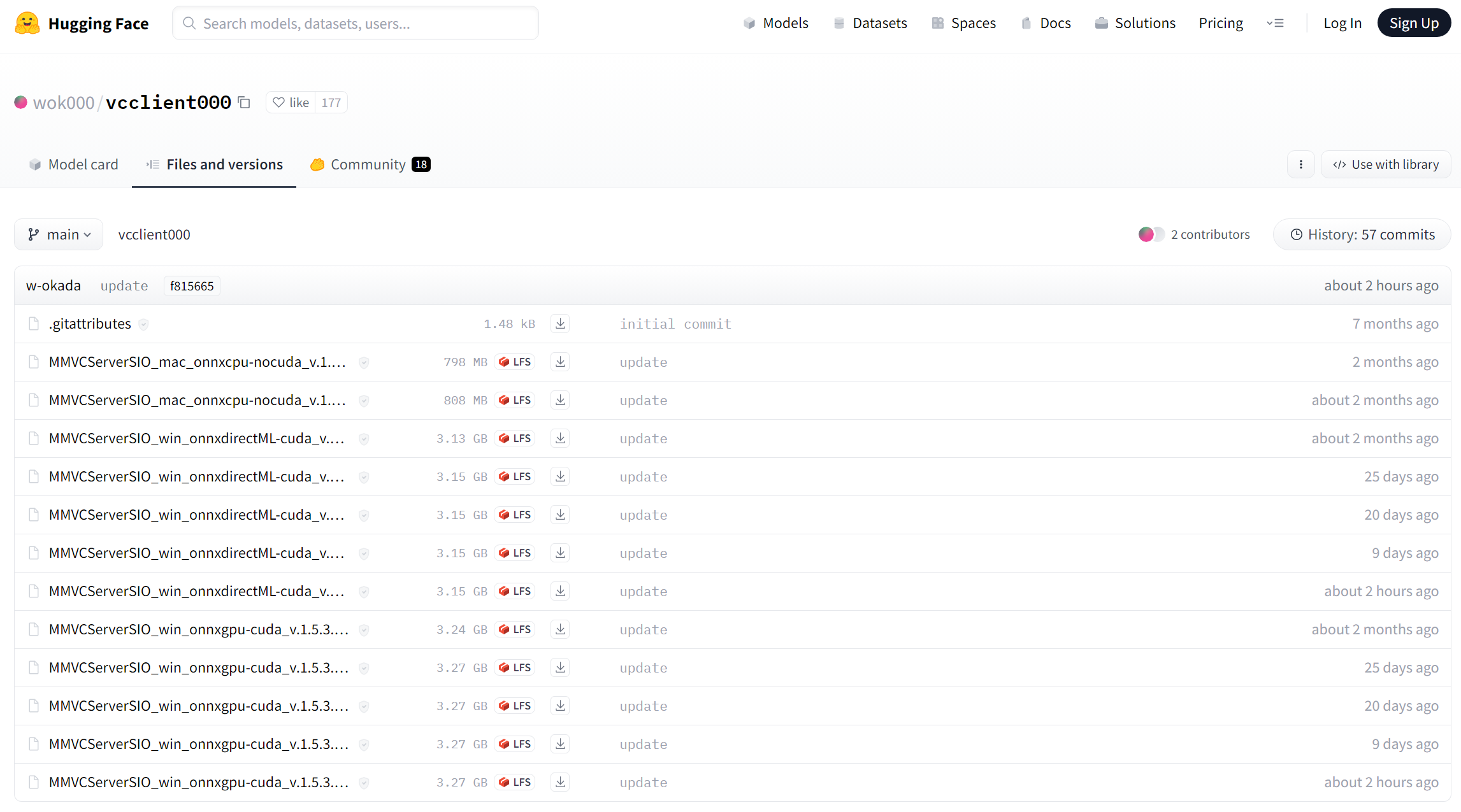
利用OS(Mac/Windows)、GPUの種類(NVIDIA/AMD/Intel)に対応した最新のものをクリックし、ダウンロード。
②学習済モデル(音声データ)
今回はVC Client内蔵のモデルを使うため不要ですが、BOOTH等のマーケットサイトよりダウンロードして使用することも可能です。
BOOTH内、"RVC"で検索:
※有料・無料の他、それぞれに利用規約があるので注意してください
③仮想オーディオデバイス
仮想オーディオケーブルとも呼ばれるもので、ボイスチェンジャーの出力を、他のソフトウェア(LINE、Zoom、Discord等)のオーディオ入力として接続する為に必要です。
単に聞くだけの場合は、必要ありません。
ここでは、「YAMAHA SYNCROOM」を利用します。
起動
最初に、ダウンロードした YAMAHA SYNCROOMをインストールします。
次に、ダウンロードしたVC Clientのアーカイブを展開し、start_http.bat を実行します。
※起動中、以下のコンソール画面はそのままにしておきます
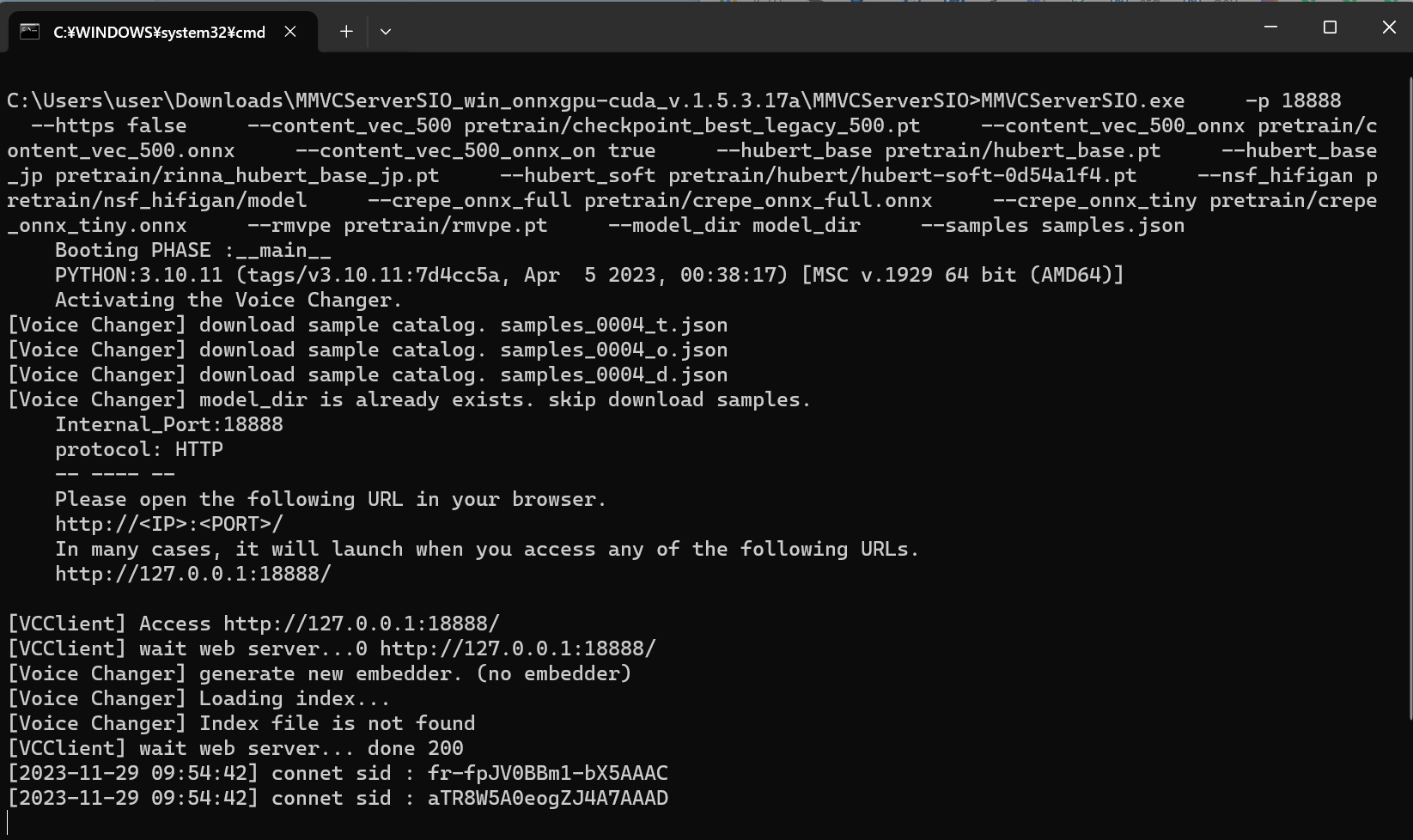
初回は各種ダウンロードを行う為、時間が掛かります。
その後、Voice Changer Client Demoというウィンドウが表示され、起動完了です。
尚、Webブラウザ(Chromeのみ)のインターフェースも利用可能で、http://127.0.0.1:18888/ (上記の場合)へアクセスすることでも同じ画面となります。
設定
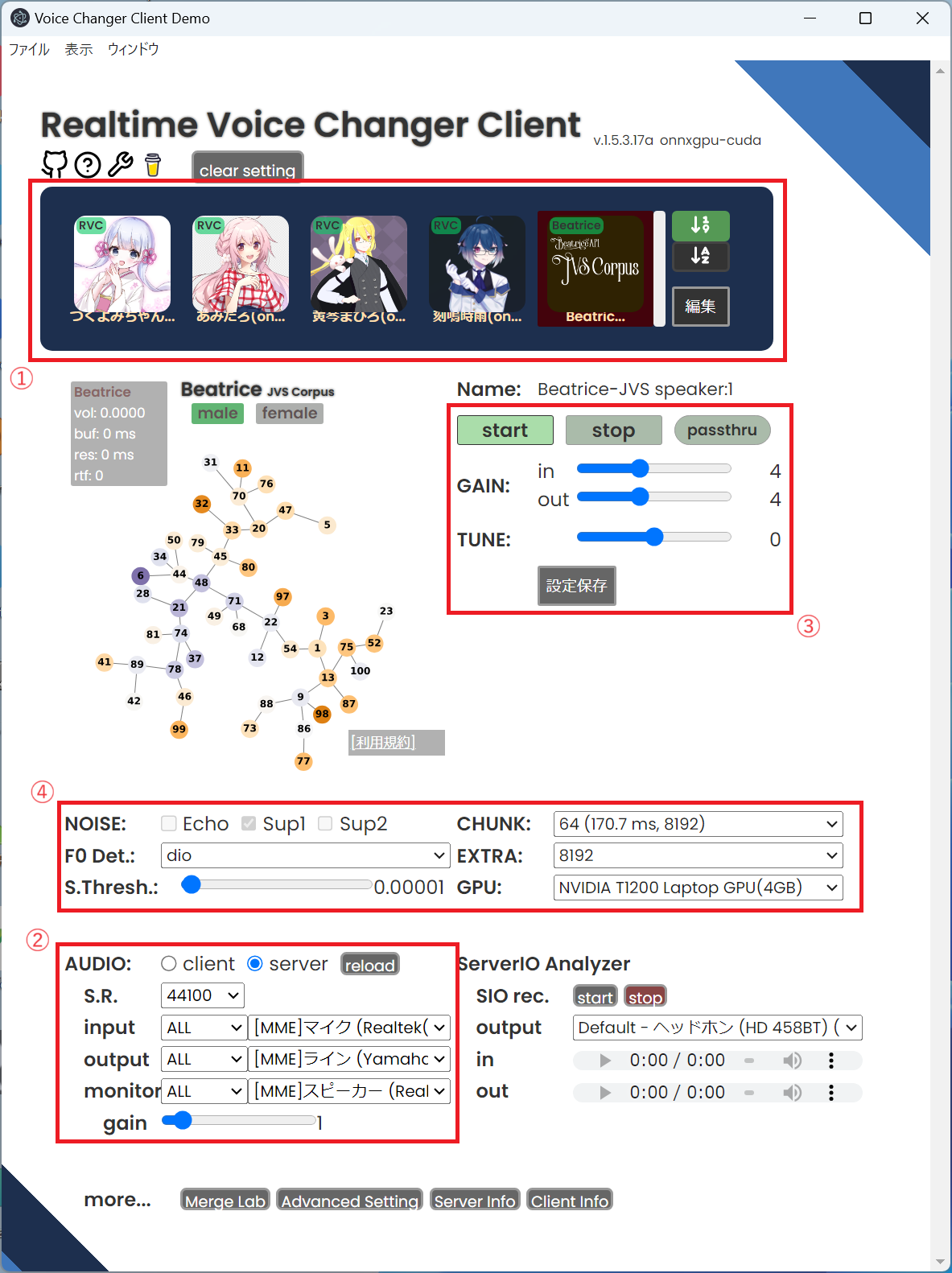
①モデルの選択
ウインドウ上部にあるアイコンのいずれかをクリックすることで、音声モデルを選択できます。
編集ボタンからは、別途ダウンロードしたモデルを追加で設定することも可能です。
②入出力デバイスの選択
AUDIOにて、clientモードかserverモードを選択します。
clientモードだとエコーキャンセル機能とノイズ抑制機能が使えますが、特に必要なければ遅延の少ないserverモードを選択します。
inputには音声入力デバイス(マイク)を、outputには音声出力デバイス(スピーカ、又は仮想オーディオデバイス)を選択します。
outputとは別に出力の音声を聞きたい場合にはmonitorにスピーカ等を選択します。
③コントローラ
startを押すと音声変換を開始、stopで停止します。
GAINのinで入力、outで出力レベルの調整ができます。
TUNEにて、変換ピッチの設定を行います。
男→女であれば+12、その逆は-12前後が目安です。
④詳細設定
F0 Det. にて、ピッチ抽出のアルゴリズムを選択します。
GPU無しでCPUを使う場合は軽負荷のdioか高精度のharvestを、GPUを使う場合はcrepeやrmvpeを選択します。
CHUNKは変換一回当たりの内部バッファの大きさです。
長くすると効率的な変換となりますが、変換までの時間が掛かります。
短すぎると音声が途切れ気味となります。
EXTRAは変換に際に過去の音声をどれだけ使うかを設定します。
値が大きいと変換精度は上がりますが、変換までの時間が掛かります。
GPUは変換に用いるGPU、又はCPUを選択します。
更に詳しい設定は、以下ページを参照下さい。
おわりに
リアルタイムボイスチェンジャーは、音声モデルの作成や高精度のリアルタイム変換には高速なGPUを必要としますが、本記事のように試してみるだけであれば低速なGPU、或いはある程度高速なCPUのみでも使えることが分かりました。
本記事を参考に、是非皆さんも、新しい世界を体験してみては如何でしょうか。
以上です。