今回はAWSの画像分析サービスのAWS Rekognitionを使って、S3バケットに格納した画像を解析・ラベリングし、ラベルデータをDynamoDBに格納する仕組みを作っていきます。
今回のゴール
S3バケットに画像ファイルをアップロードするとAmazon Rekognition imageで画像を解析し、どんな内容の画像なのかラベルを付けて、その中の3ラベルをDynamoDBに書き込みする。一連の処理はS3バケットへの画像格納をトリガーに、Lambdaで実行する。
構成図にするとこんな感じです。

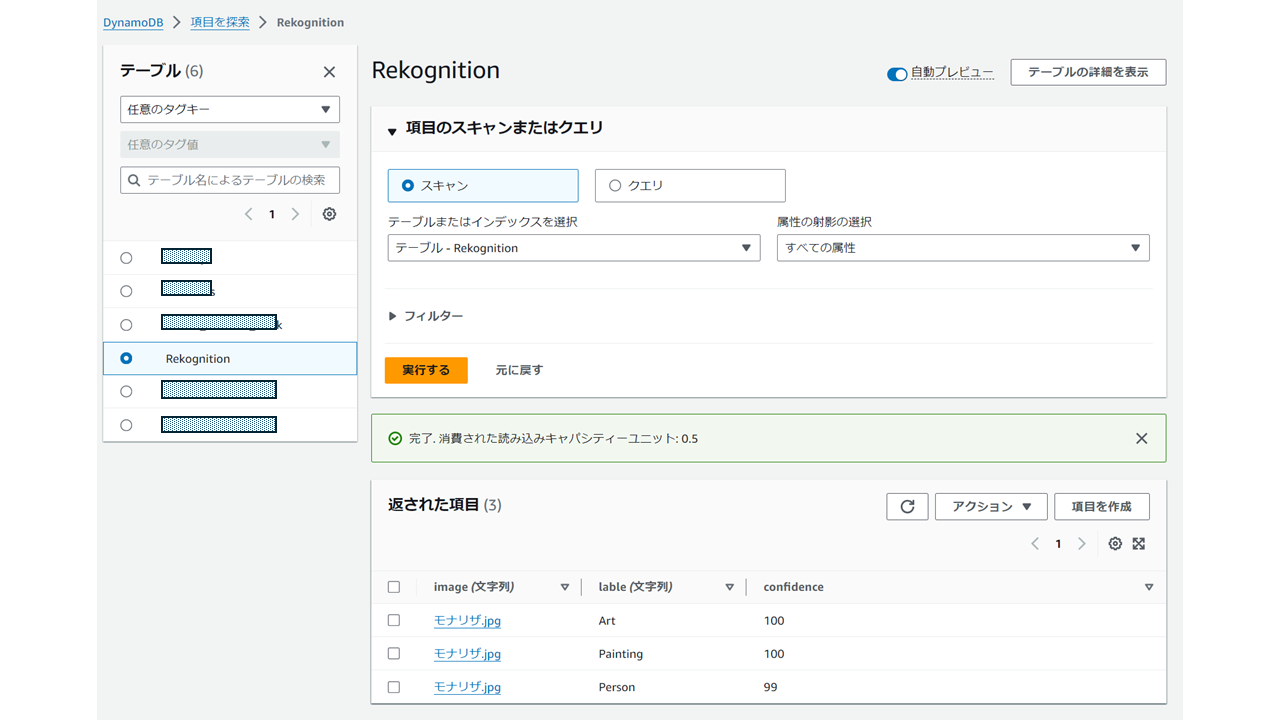
最終的にDynamoDBにこんな感じで画像解析した結果のラベルが格納されていればOkとします。
※解析に使った画像はモナリザなので、「Art」、「Painting」、「person」とラベリングされています。
前提条件(免責事項)
-Lambdaの処理はpython(この記事執筆時点の最新3.12)で記述します。※下手くそコードです
-設定にあたり、リソース使用時に課金が発生しますので使い終わったらリソース削除しましょう
設定の流れ
実際の設定ですが以下の流れになります。
①S3バケットの作成
②Lambdaの設定
③DynamoDBのテーブル作成
④動作確認
①S3バケットの作成
まずは画像でデータを格納するS3バケットを作成します。基本的にS3バケットには特に変わった設定はせず、デフォルトの状態で作成していきます。
バケットタイプは「汎用」を選択してください。

ACL設定やパブリックアクセスブロックはデフォルトのままで「バケットの作成」まで進めてください。

リージョンだけちゃんと利用する予定のリージョンになっているか確認しましょう。またバケット名は一意にする必要があるので他バケットと重複しなさそうな名前にしましょう。
②Lambdaの設定
Lambdaの作成は手動で内容を入れていきますので「一から作成」を選択します。関数名は任意のものを記入すます。ランタイムは今回Pythonを利用するので「Python」の任意のバージョンを選択してください。実行ロールは「基本的なLambdaアクセス権で新しいロールを作成」を選択しておきます。ロールの設定はあとから変えますのでいったんこのままでOKです。

これで関数を作成まで進めてください。
②-1 Lambda用ロールに権限追加
作成されたLambda関数を選択して、表示すると以下のような画面になります

先ほど作成したLambda関数の実行ロールはデフォルトのままで、デフォルトだとCloudwatchしか実行権限が付与されていないのでS3バケットを読み取りしたり、DynamoDBに書き込みができないです。そのため必要なリソースへのアクセス権限を付与する必要があります。「設定タブ」をクリックすると実行ロールの現状設定が表示されます。ロール名のところがリンクになっているのでクリックして、IAMのロール設定とのところにアクセスします。

許可ポリシーのところで「許可を追加」で「ポリシーをアタッチ」をクリックしてください。

どういうポリシーをアタッチするか設定する画面になるので、「AmazonS3FullAccess」と「AmazonDynamoDBFullAccess」をアタッチしてください。
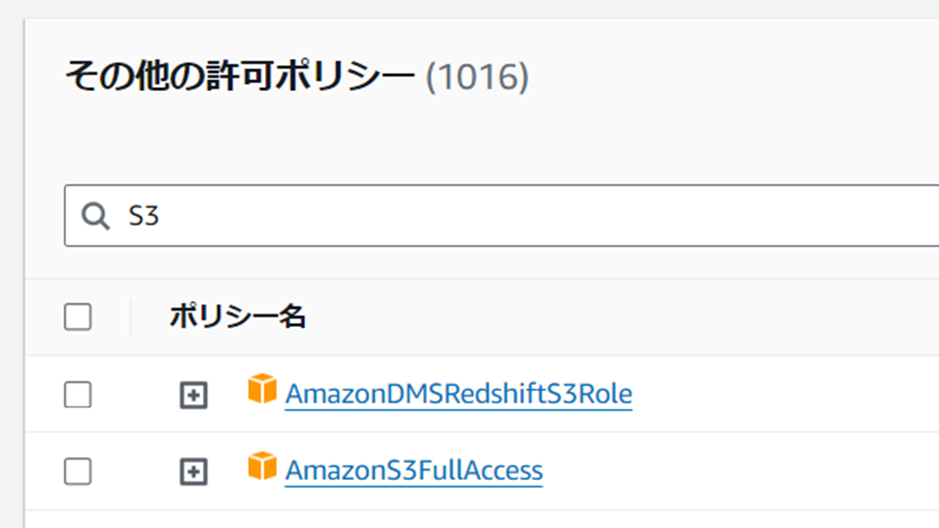
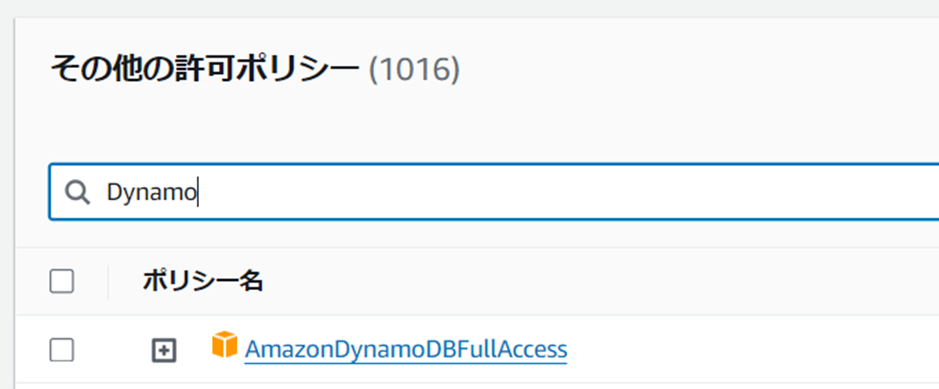
アタッチ後は以下のようなポリシー設定になります。

②-2 トリガーの設定
Lambda関数が実行されるトリガーを設定していきます。今回は特定のS3バケットに指定のファイル名のJPGファイルをアップしたら動作するように設定していきます。Lambdaの設定画面で「+トリガーを追加」というボタンをクリックするとどのサービスをトリガーにするか選択できますので、「S3」を選択します。
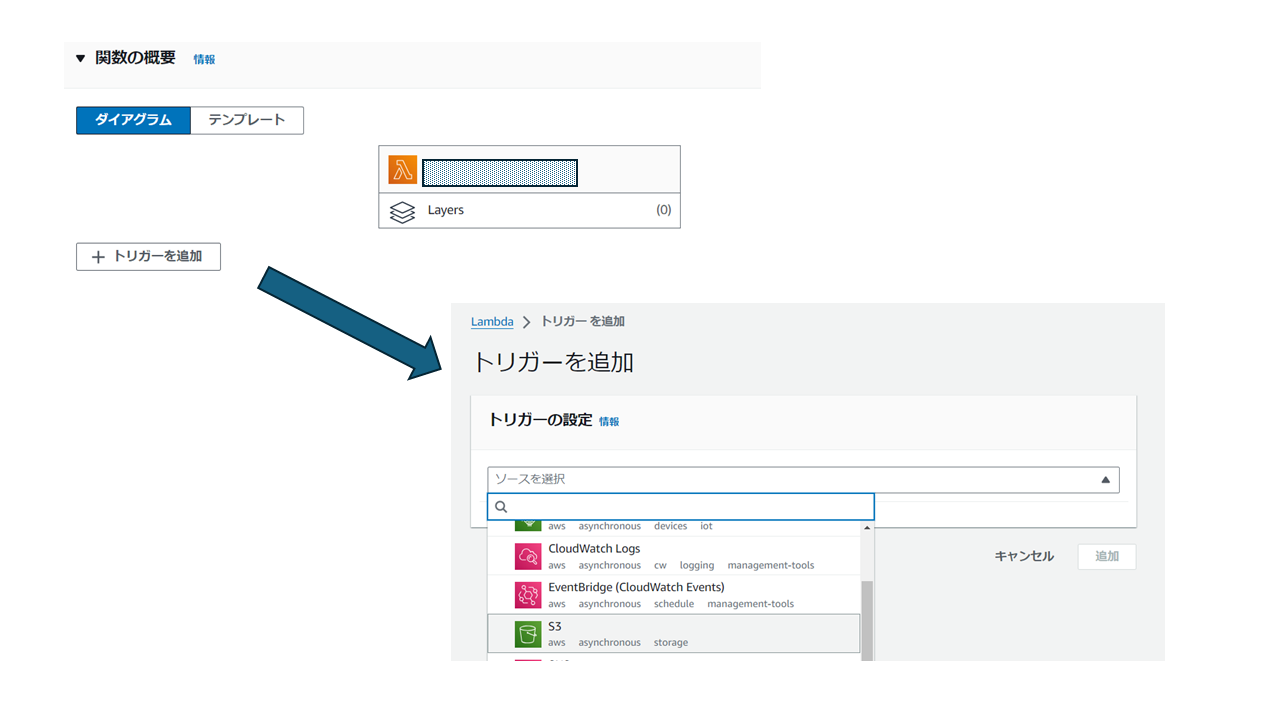
「Bucket」のとことで手順①で設定したS3バケットを選択し、Event Typesは「All pbject create events」を選択します。Suffixのところは今回JPGファイルをアップする予定なので、".jpg"を記載します。
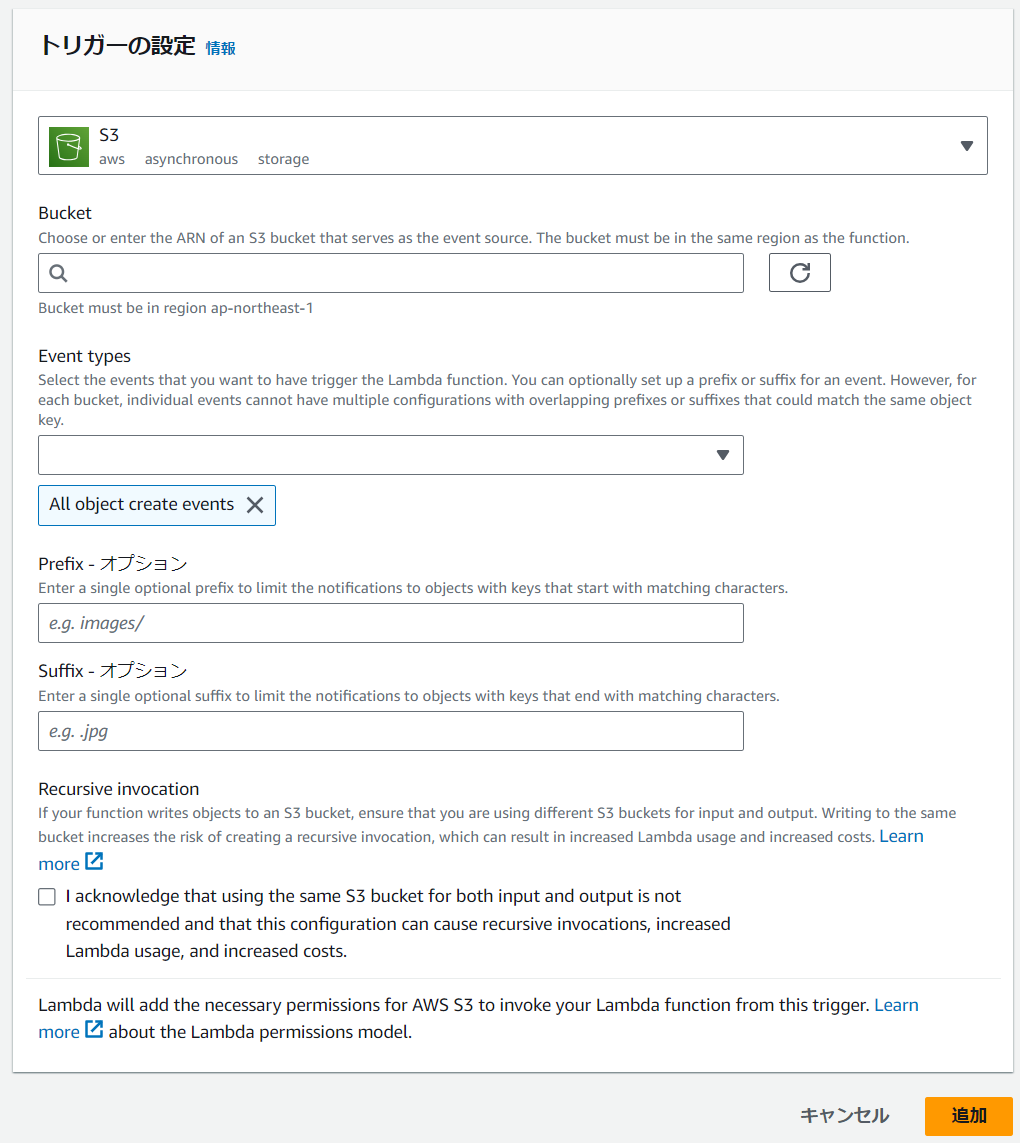
トリガー追加後はこんな感じになります。

②-3 ソースコードの記述
ここからはpythonで処理を記述していきます。コードタブをクリックし、「lambda_function.py」に記述していきます。
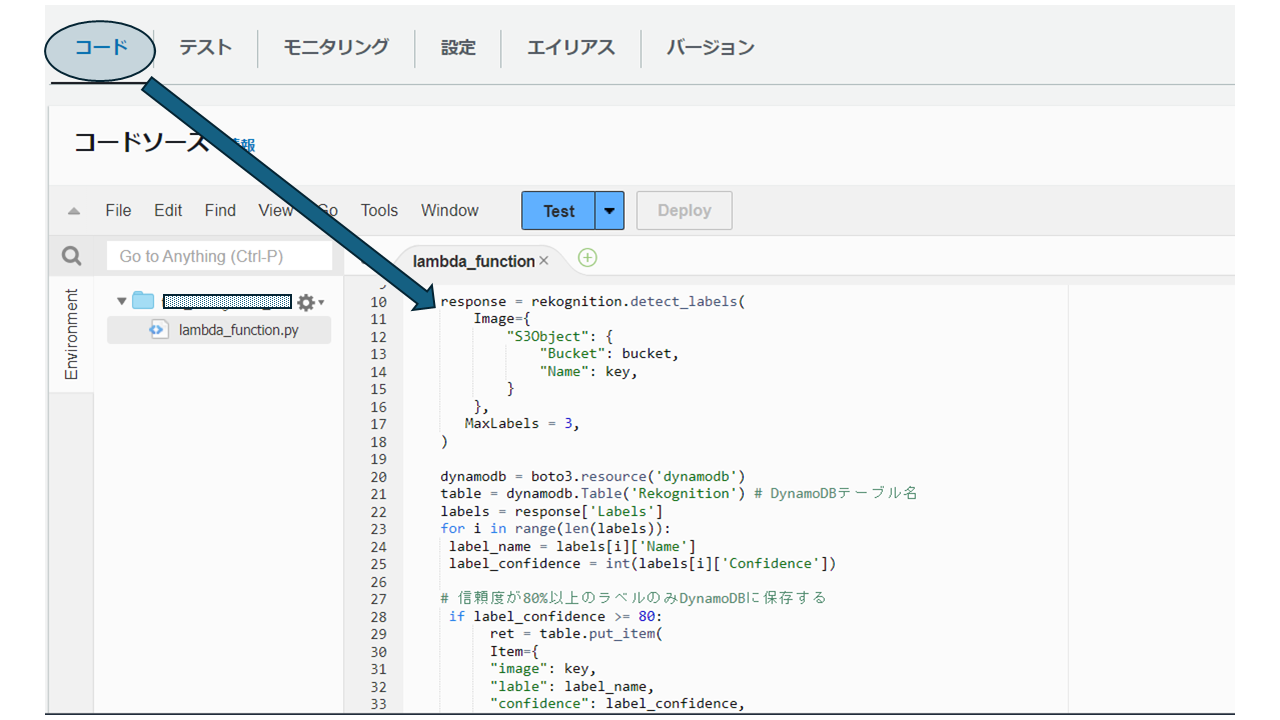
Lambdaの処理コード内容は以下です。
次のパラーメータはご自身の環境の合わせて変更してください。
- "作成したS3バケット名"
- "モナリザ.jpg"
- ”DynamoDBテーブル名”
import boto3
import json
def lambda_handler(event, context):
rekognition = boto3.client("rekognition")
bucket = "作成したS3バケット名"
key = "モナリザ.jpg" #ファイル名
response = rekognition.detect_labels(
Image={
"S3Object": {
"Bucket": bucket,
"Name": key,
}
},
MaxLabels = 3,
)
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('DynamoDBテーブル名) # DynamoDBテーブル名
labels = response['Labels']
for i in range(len(labels)):
label_name = labels[i]['Name']
label_confidence = int(labels[i]['Confidence'])
# 信頼度が80%以上のラベルのみDynamoDBに保存する
if label_confidence >= 80:
ret = table.put_item(
Item={
"image": key,
"lable": label_name,
"confidence": label_confidence,
}
)
# ログ出力
return ret
③DynamoDBのテーブル作成
Lambdaがデータを書き込むDynamoDBを作成していきます。管理コンソールにアクセスして、「テーブルの作成」をクリックして、テーブル名は任意の値を入力し、「パーティションキー」=「image」、「ソートキー」=「lable」と記載します。タイプは2つとも「文字列」とします。

作成後のテーブル項目はこんな感じになります。

④動作確認
Lambdaの設定画面でコードのテストを実行して、実行StatusがSuccessになっていればOKです。
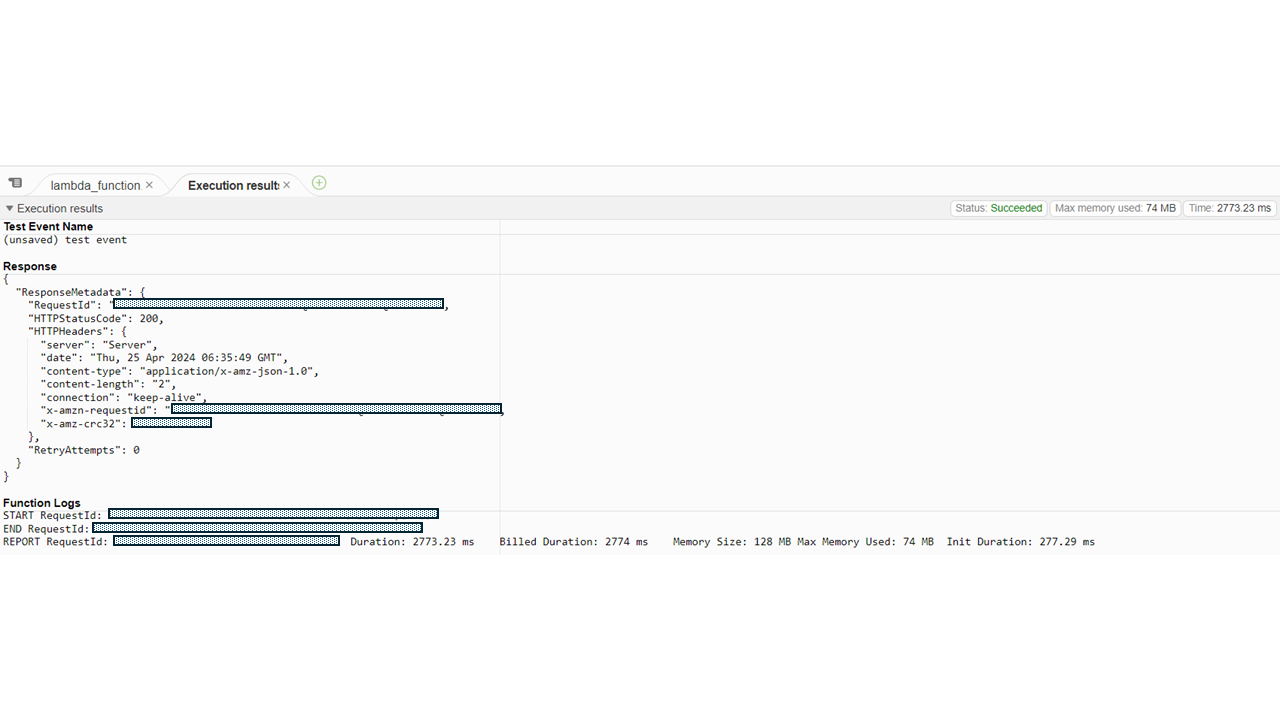
実行Statusがエラーになる場合はエラーメッセージにエラー原因が書かれていますので確認しましょう。私はインデントがおかしかったりや処理分の最後に":"がないという凡ミスがよくあります。
エラーメッセージ内容がAccessDenyとなっている場合はLambdaの実行ロールの権限の問題です。いったん付与ポリシーを「AdministratorAccess」にして実行して切り分けしてもよいと思います。実行ロールを「AdministratorAccess」に変更した場合、強力な権限になっているので注意してください。
設定したS3バケットに指定ファイル名(私の環境ではモナリザ.jpg)をアップすると画像解析結果のラベリング情報がDynamoDBに格納されているか確認しましょう。

DynamoDBで作成したテーブルを選択して、「テーブルアイテムを検索」を実行すると格納されたデータが確認できます。
おわりに
サンプル画像がモナリザなので解析結果はそれなりの精度でした。でも犬・猫以外の動物の判別は微妙だったりします笑。Pythonコード内に個別ファイル名を記載していますが、書き方を工夫すればもっと自動化できるようになると思います。Pythonコードスキルが上がればそのうち書いてみようかな...
参考サイト