多次元配列についてのテクニック
CPU上では、大域変数として多次元配列を使える
– short int h_array[MAX1][MAX2][MAX3][MAX4];
のように定義できる
利用方法(1): cudaMallocによる方法
利用方法(2): __device__による方法
(1) 大域変数の定義に__device__をつけると、GPUメモリ上に確保される
__device__ int d_array[MAX1][MAX2][MAX3][MAX4];
(2) ただしこのままだと「CPU側から」コピーできない。
cudaGetSymbolAddressで変換しておく必要あり
例:
cudaGetSymbolAddress(&d_array_ptr, d_array);
cudaMemcpy (d_array_ptr, h_array, sizeof(int)*MAX1*MAX2*MAX3*MAX4, cudaMemcpyHostToDevice);
cudaMemcpy (h_array, d_array_ptr,
sizeof(int)*MAX1*MAX2*MAX3*MAX4, cudaMemcpuDeviceToHost);```
(3) これなら、GPUカーネル関数内でもd_array[i][j][k][l] のように使えてちょっと便利!
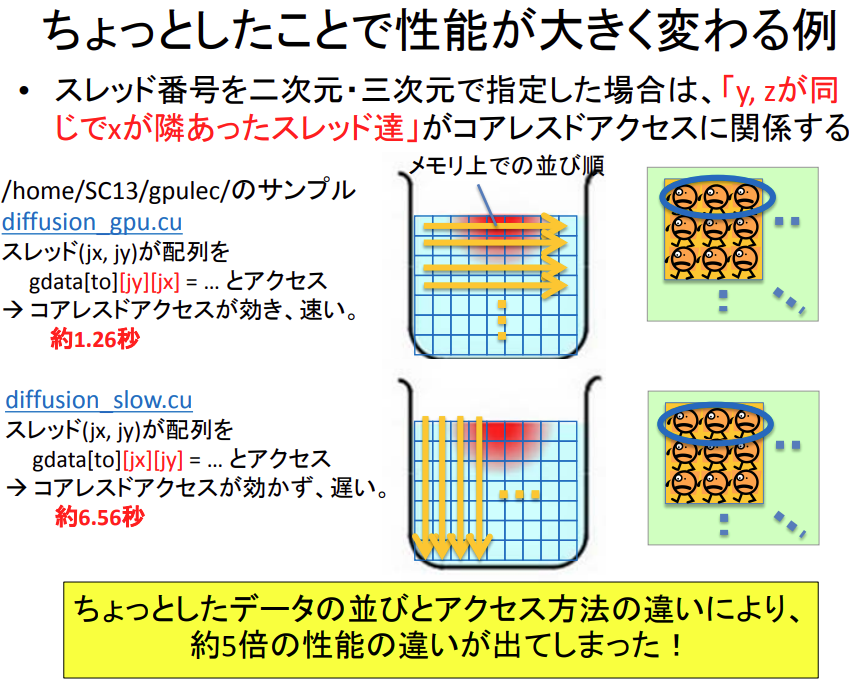
## 「コアレスド・アクセス」によるメモリアクセス効率化
## ifを避ける
## Stream