#はじめに
Beautiful Soupを使用してWebスクレイピングを行う手順を記述します。
サンプルアプリケーションはgithubに公開しています。
##前提事項
- サンプルアプリケーションの詳細はバッチアプリケーション(django)を参照ください
- BeautifulSoupは4.6.0を使用します
#Beautiful Soupとは
Beautiful SoupはHTMLやXMLファイルからデータを取得するPythonのライブラリです。
パーサーを使用してhtml要素(タグやクラス等)の検索や修正を行います。
#Webスクレイピング(Beautiful Soup)
バッチアプリケーション(django)をベースにWebスクレイピングを行う手順を説明します。
##アプリケーション構成
アプリケーション構成は以下のようになります。
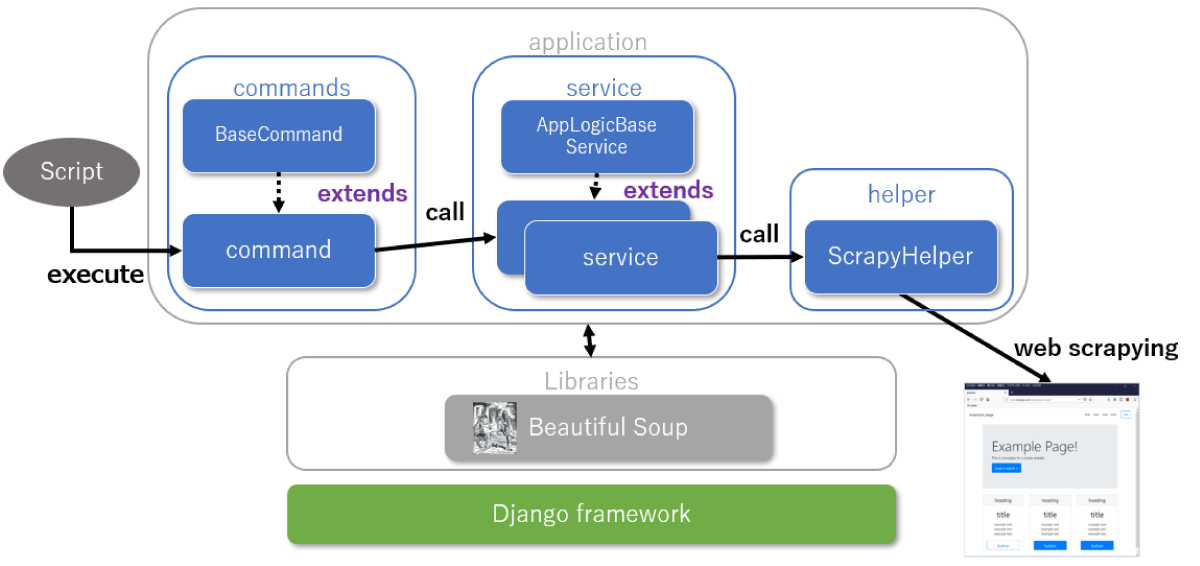
##Webスクレイピング実行
Webスクレイピングは以下のように実現しています
| No | 項目 | 説明 |
|---|---|---|
| 1 | webアクセス | サービスからHelperを呼び出してwebアクセスする htmlテキストはDBに格納する |
| 2 | データ抽出 | DBのhtmlテキストを取得してパースを行い要素を抽出する |
###Helper
Scrapy関連の共通的な処理を行います
| メソッド | 処理説明 |
|---|---|
| get_html | webアクセスしてhtmlテキストを取得する |
| is_exists_class_name | htmlテキストに指定されたclassが存在するかをチェックする |
| get_url_parameter | URLから指定されたパラメータ名の値を取得する |
# coding:utf-8
import logging
import socket
import urllib.request
from urllib.error import HTTPError, URLError
from urllib.parse import urlparse, parse_qs
from bs4 import BeautifulSoup
from django.utils.translation import gettext
from pypeach_django.app_config import AppConfig
"""
Scrapy関連の共通処理を定義する
"""
class ScrapyHelper:
@staticmethod
def get_html(url, parse_flag=None):
"""
scrapyを行いhtmlを取得する
"""
# User-Agentを定義する
ua = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) ' \
'AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/55.0.2883.95 Safari/537.36 '
# アクセスのリトライ回数を指定する
retry_max_count = AppConfig.get_properties("url_request_retry_max_count")
response_html = None
for i in range(0, retry_max_count):
try:
# Webアクセス時のUser-Agentを指定する
logging.debug("request settings")
req = urllib.request.Request(url, headers={'User-Agent': ua})
# Webアクセスの読み込みを行う
logging.debug("request read start")
with urllib.request.urlopen(req, timeout=AppConfig.get_properties("url_request_read_timeout")) as f:
html = f.read().decode('utf-8')
logging.debug("request read end")
# レスポンスをHTMLパーサーでパースする
logging.debug("request parse start")
if parse_flag is True:
response_html = BeautifulSoup(html, 'lxml')
else:
response_html = html
logging.debug("request parse end")
# レスポンスを取得した場合はループを抜ける
if response_html is not None and len(response_html) > 0:
break
except HTTPError as e:
# HTTPError時のメッセージを出力する
logging.info(gettext("I801"), url, e.code, e.msg)
except URLError as error:
# タイムアウトを判定する
if isinstance(error.reason, socket.timeout):
logging.info(gettext("I802"), url)
else:
logging.info(gettext("E991"), error.reason)
raise URLErrorException(gettext("E990") % url)
except socket.timeout:
logging.info(gettext("I802"), url)
except ConnectionResetError as error:
# [Errno 104] Connection reset by peerを回避する
logging.info(gettext("I802"), url)
except Exception as error:
logging.info(gettext("E991"), error)
raise ScrapyIllegalException(gettext("E990") % url)
# レスポンスがない場合はExceptionにする
if response_html is None:
error_msg = "{}:{}".format(gettext("E803"), url)
raise HttpErrorException(error_msg)
return response_html
@staticmethod
def is_exists_class_name(html, class_name):
"""
html内のクラス有無をチェックする
"""
is_exists_flag = False
try:
# class有無を判定する
if len(html.select('.' + class_name)) > 0 or class_name in html["class"]:
is_exists_flag = True
except (KeyError, AttributeError):
# エラーの場合はfalseを返却する
pass
return is_exists_flag
@staticmethod
def get_url_parameter(url, parameter_name):
"""
URLのパラメータ値を取得する
"""
try:
# URLをパースして指定されたパラメータ名を取得する
url_parse = urlparse(url)
url_query = parse_qs(url_parse.query)
value = url_query[parameter_name][0]
except KeyError as e:
# エラーの場合はログを出力してNoneを返却する
logging.debug(gettext("W801"), e)
return None
return value
class HttpErrorException(Exception):
"""
Exception(httpエラー)を定義する
"""
pass
class URLErrorException(Exception):
"""
Exception(サーバ接続エラー)を定義する
"""
pass
class ScrapyIllegalException(Exception):
"""
Exception(その他エラー)を定義する
"""
pass
Helperに関する特記事項は以下のとおり
- HTMLパース指定
Webアクセスして取得したhtmlはそのまま解析したり、リクエストの重複を回避するため一旦DBに蓄積するケースがあります
その点を考慮してget_htmlメソッドはHTMLパース有無を引数で指定します
- Webアクセスエラー
Webアクセスを行う際、サーバの接続エラーが多々あります
その点を踏まえてget_htmlメソッドは以下のようにします
| 項目 | 処理説明 |
|---|---|
| タイムアウト時間 | タイムアウト時間は設定ファイルから取得する |
| リトライ | エラー発生時はリトライを行う リトライ回数は設定ファイルから取得する |
| エラーハンドリング | リトライ可能なエラーのみリトライする リトライ不可のエラーはExceptinをスローして処理を中断する |
Webアクセス時に発生するエラーとリトライ有無は以下の関連になります
| エラー | エラー内容 | リトライ有無 |
|---|---|---|
| HTTPError | Httpエラー(404や500等) | × |
| URLError | 接続エラー | △ (socket.timeoutのみリトライする) |
| socket.timeout | ソケットタイムアウト | ○ |
| 上記以外 | エラー | × |
###サービス
htmlテキストのDB登録や要素の抽出を行う
import logging
from bs4 import BeautifulSoup
from django.db import transaction
from django.utils import timezone
from django.utils.timezone import localtime
from app_pypeach_django.application.helper.date_helper import DateHelper
from app_pypeach_django.application.helper.scrapy_helper import ScrapyHelper
from app_pypeach_django.application.service.app_logic_base_service import AppLogicBaseService
from app_pypeach_django.models import ScrapyHtml
"""
Scrapyを行うクラスです。
"""
class ScrapyService(AppLogicBaseService):
def __init__(self):
super().__init__()
# URLの定数
url = 'http://mocjax.com/example/scrape/'
@staticmethod
@transaction.atomic()
def create_scrapy_html():
"""
Webページにアクセスしてデータを作成する
"""
service = ScrapyService()
service._regist_scrapy_html(service.url)
@staticmethod
@transaction.atomic()
def parse_scrapy_html():
"""
Webページの結果から要素を抽出する
"""
service = ScrapyService()
for item_scrapy_html in ScrapyHtml.objects.filter(request_url=service.url, delete_flag=0):
# html→lxmlに変換して構文解析を行う
html_text = item_scrapy_html.html_text
html_lxml = BeautifulSoup(html_text, 'lxml')
# selectを使用してheadingをすべて抽出する
for item_header in html_lxml.select('div.card-header > h4'):
logging.debug("header_text={}".format(item_header.text))
# select_oneを使用してbody内のタイトルを先頭1件のみ抽出する
first_body = html_lxml.select_one('div.card-body > h1')
logging.debug("item_header_text={}".format(first_body.text))
# ボタンのクラス有無を判定する
if ScrapyHelper.is_exists_class_name(html_lxml.select_one('a.btn.btn-primary'), 'btn-lg'):
logging.debug("exists class:btn-lg")
# アンカーのパラメータを取得する
for item_anchor in html_lxml.select('a'):
href = item_anchor.get('href')
logging.debug("item_href={}".format(href))
# アンカー内のパラメータ(id)の値を取得する。パラメータがない場合はNoneになる
logging.debug("id={}".format(ScrapyHelper.get_url_parameter(href, 'id')))
def _regist_scrapy_html(self, url):
"""
Webスクレイピングした結果をテーブルに登録する
"""
# 同一URLが存在する場合はレコードを削除する
if ScrapyHtml.objects.filter(request_url=url).count() > 0:
ScrapyHtml.objects.filter(request_url=url).delete()
self.regist_model = ScrapyHtml()
self.regist_model.execute_dt = DateHelper.get_today(DateHelper.format_ymd)
self.regist_model.request_url = url
self.regist_model.html_text = ScrapyHelper.get_html(url)
self.regist_model.delete_flag = 0
self.regist_model.regist_dt = localtime(timezone.now())
self.regist_model.update_dt = localtime(timezone.now())
self.regist_model.save()
return self.regist_model.id
#参考情報