Fisher情報量の定義
そもそもFisher情報量とはなんだろう。
大抵の教科書にはこんな定義が書いてあります。
I = \rm E_{\theta}
\left[
\left(
\frac{\partial}{\partial\theta}
log \it f(X; \theta)
\right)^2
\right]
これを説明するのに、Cramer-Raoの不等式という不等式から考えると、スムーズです。このCramer-Raoの不等式というのは不偏推定量の分散の下限を与えるものです。
この不等式を証明するためには、微分と積分が交換可能だよ、とかまぁ色々難しい仮定が必要ですが、その結論だけを観てみましょう。
詳しく知りたい人はこちら。証明はWikipediaに書いてあります。
Cramer-Raoの不等式
概要(というか結論)
いま、ある$X_1, X_2, ..., X_n$は、確率関数$f(x; \theta)$によって発生する確率分布に従うとします。$T(X_1,X_2,...,X_n)$を$g(\theta)$の不偏推定量とすると、下記のような不等式が成り立つ。これがCramer-Raoの不等式です。
V_\theta{T(X_1, X_2, ..., X_n)}\geqq\frac{g'(\theta)^2}{nI_X(\theta)} \\
I_X = \rm E_{\theta}
\left[
\left(
\frac{\partial}{\partial\theta}
log \it f(X; \theta)
\right)^2
\right]
なんだか難しいですが、$T(X)$が$g(\theta)$の不偏推定量であるということは、$E[T(X)]=g(\theta)$ということです。
正規分布の場合
具体例で考えてみましょう。みんな大好き正規分布です。
正規分布の場合のパラメータは、$\theta=(\mu, \sigma^2)$と考え、不偏推定量は下記と計算できます。
$$
T(X_1, X_2, ..., X_n) = (T_1, T_2) = (\overline{X}, \frac{1}{n-1}\Sigma(X_i - \overline{X})^2)
$$
さて、ここでサンプリングしたデータで与えられる$T_1$, $T_2$は、どの程度信頼のおけるデータとなるのでしょうか。もう少し良い言い方をすると、どの程度良い統計量なのでしょうか。
当然、サンプリングするデータによって統計量はばらつきを持ちます。ばらつきは小さい方が良いですよね。ですので、統計量の分散を考える必要があるわけです。
細かい計算は割愛しますが、$I_X$を頑張って計算していくと、こんな式になります。
I_X(\mu)=E_\theta[\frac{\partial}{\partial\mu}log\Pi f(x_i; \theta)]^2=\frac{n}{\sigma^2} \\
I_X(\sigma^2)=E_\theta[\frac{\partial}{\partial\sigma^2}log\Pi f(x_i; \theta)]^2=\frac{n}{2\sigma^4}
最初のCramer-Raoの不等式に代入してやれば、下記が得られます。
$$
V_\theta(T_1)\geqq\frac{\sigma^2}{n},V_\theta(T_2)\geqq\frac{2\sigma^4}{n}
$$
ここで$I_X$にはデータ数$n$が含まれていますので、直感に合います。つまり、データが沢山とれてないと、最低でもそれなりに分散が大きくなってしまい、ろくな推定量になりません、ということです。ただし、これは下限を述べるものであり、上限を述べるものではありませんので、注意が必要です。
有効推定量
1式目($T_1$に関する式)の左辺はどうなるでしょうか。下記はとても簡単に算出ができます。
$$
V_\theta(T_1)=V_\theta(\overline{X})=\frac{\sigma^2}{n}
$$
ここで、左辺と右辺が一致しているのがわかります。つまり$T_1$に関しては、Cramer Raoの不等式の下限を表しています。これは一様最小分散不偏推定量(UMVUE)と呼ばれ、良い推定量です。
$T_2$についてはどうなるでしょうか。実はこちらは計算していくとCramer Raoの下限にはなりません。しかしそれでも$T_2$の推定量はUMVUEになります。その解説はまた気が向いたら。Cramer Raoの不等式は下限を与えるだけで、その下限設定は少し甘いこともあるということになります。
実験
本当に正気分布の平均値や分散の不偏推定量は、上記のFisher情報量の逆数で表される程度の分散を持つのか実験してみましょう。
下記は実験結果です。正規分布$N(0, 5^2)$でデータを沢山作成し、その中から2~30個までサンプリングの数を変えたときの、"平均"の"分散"を描きました。
薄いオレンジの色が、Fisher情報量の逆数です。
青いX印が、データを複数回サンプリングし平均の分散を計算したものです。
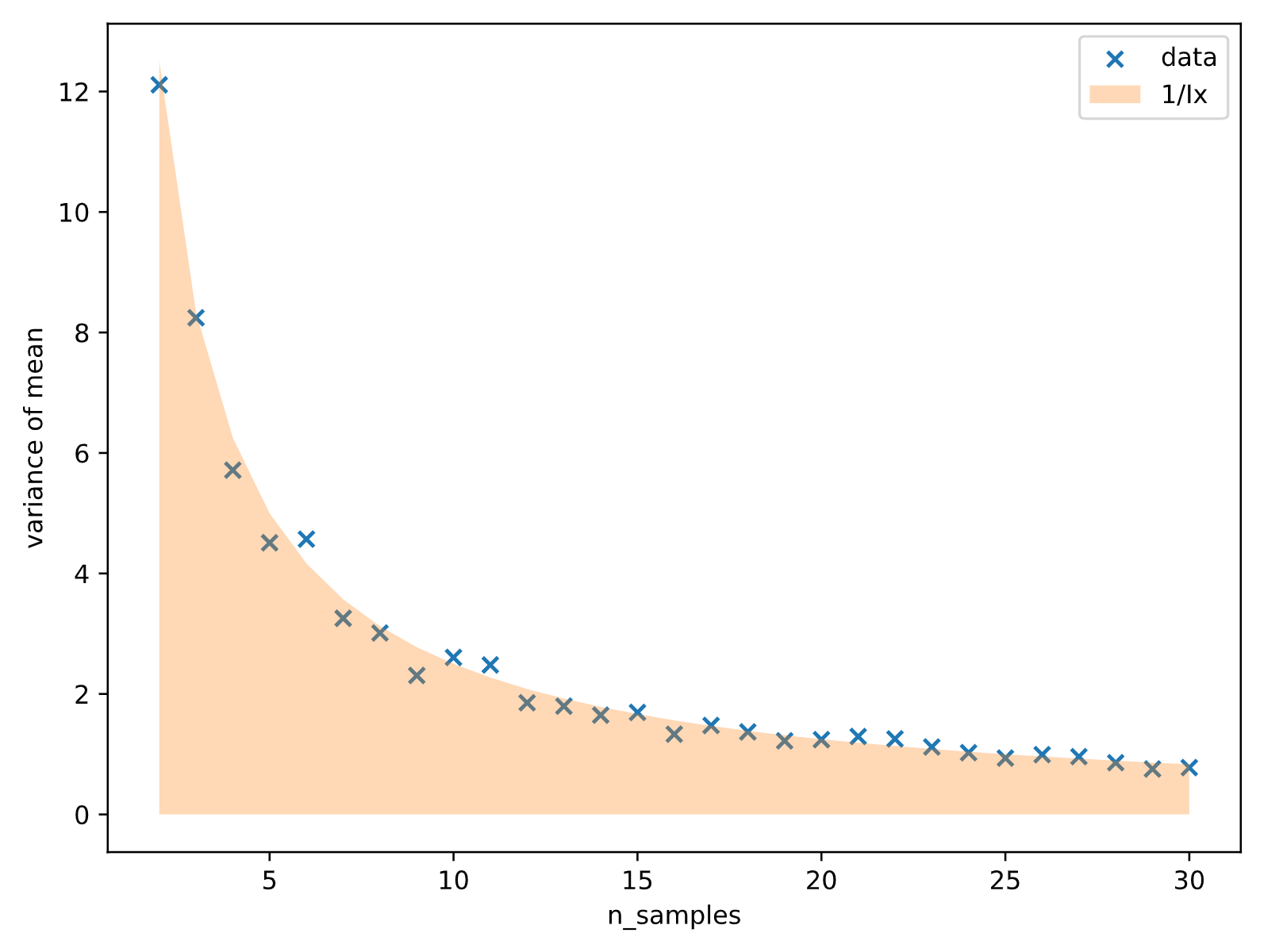
今回はCramer Raoの不等式の下限と、データから求める平均の分散が等しくなるので、だいたい同じラインに乗ってきます。データを増やせば、平均の分散は小さくなっていきます。
おわりに
僕らが観測している不偏推定量も、平均的に良いというだけで、分散を持つことを少しだけ考えることができました。自分たちが観測しているデータがいったい何者なのか、よく考えながらモデリングなどを進めていけると良いなぁと思います。