はじめに
Oracle Analytics Cloud(OAC)では、データセットをインプットとして機械学習モデルを構築するためのデータフローを作成できます。
構築した機械学習モデルは、別のデータセットに適用できます。
この一連の流れを紹介します。
データの準備
手元の環境にSQLDeveloperをインストールしているのですが、Oracle Data Miner用のサンプルデータをロードするためのスクリプトがあることを知りました。
これを使ってみようと思います。
場所は、sqldeveloper/dataminer/scripts です。
ここにある instInsurCustData.sql を流用します。
顧客リストが作成され、保険に加入したかどうかを示すデータが含まれます。
Autonomous Data Warehouse(ADW)に専用のユーザーを作成し、SQLを実行します。
データフローの作成
ここから先は、OACでの作業です。
サンプルデータをデータセットとして定義して、データフローを作成していきます。
データセットの作成
INSUR_CUST_LTV_SAMPLE表を使用しますが、この表をトレーニング用とテスト用に分けて使います。
まずは、トレーニング用のデータセットを作成します。
普通にINSUR_CUST_LTV_SAMPLE表を使ってデータセットを作ります。
INSUR_CUST_LTV_SAMPLE表を右クリックして「定義の編集」をクリックします。

フィルタアイコンをクリックしてメニューを表示させ、「式フィルタの作成」をクリックします。

CUSTOMER_IDに格納されている値の長さが5バイト以上の列だけを抽出します。
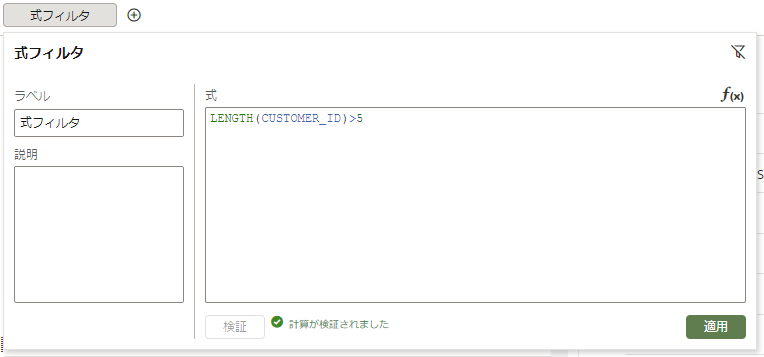
乱暴ですが、これで全データの90%程度を抽出できます。
保存アイコンをクリックして、データセットを保存します。

名前は「INSUR_CUST_LTV_TRAIN」にします。

続いて、テスト用のデータセットを作成します。
全く同じ要領で、式フィルタの内容だけを変えます。
(今度はCUSTOMER_IDの長さが5バイト未満のものだけを抽出)

「INSUR_CUST_LTV_TEST」という名前で保存します。
トレーニングのためのデータフローを作成
「作成」をクリックして、新しいデータフローを作成します。

「INSUR_CUST_LTV_TRAIN」データセットをクリックして選択し、「追加」をクリックします。

ステップを追加するために「+」をクリックして、「二項分類子のトレーニング」をクリックします。

今回は、アルゴリズムとしてサポートベクターマシンを選択します(後で変更も可能です)。

ターゲットを「BUY_INSURANCE」列とします。

この列には、保険に加入したかどうかを「Yes」「No」のいずれかのデータで入っています。
従って「Positive Class in Target」の値はデフォルトの「Yes」のままにしておきます。
その他のパラメータも全部デフォルトのままにしました。
モデルの保存ステップで、任意の名前のモデル名を入力します。

データフローを保存します。

任意の名前を入力します。

データフローを実行します。

作成した機械学習モデルの評価
機械学習モデルが作成できたら、モデルの評価を見てみます。
「機械学習」メニューを見てみると、データフローで作成した機械学習モデルがあるのがわかります。

作成した機械学習モデルを右クリックし「検査」をクリックします。
「品質」タブで、モデルの精度等を確認することができます。
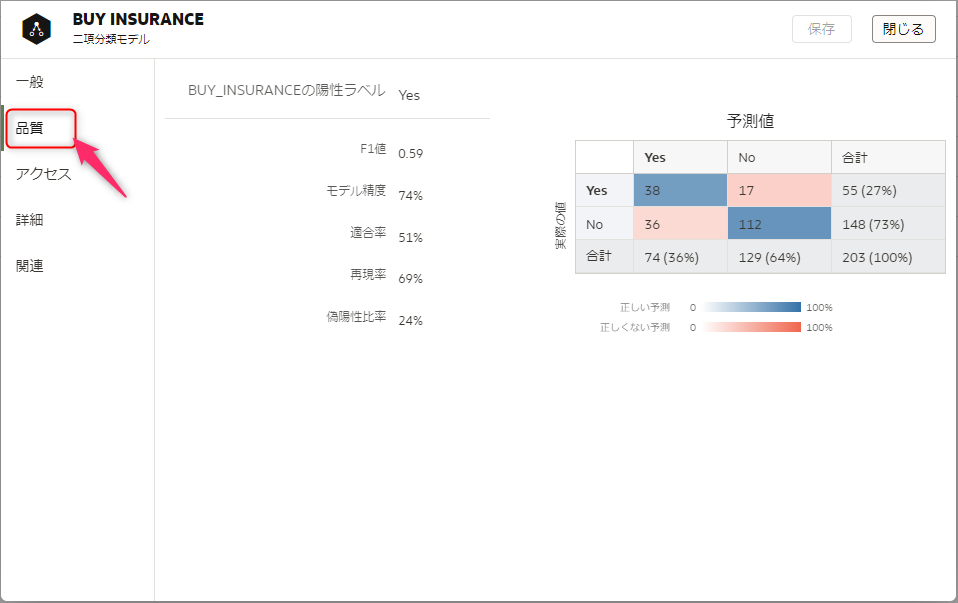
機械学習モデルを適用するためのデータフローを作成
新規にデータフローを作成します。
使用するデータセットは「INSUR_CUST_LTV_TEST」を選択します。
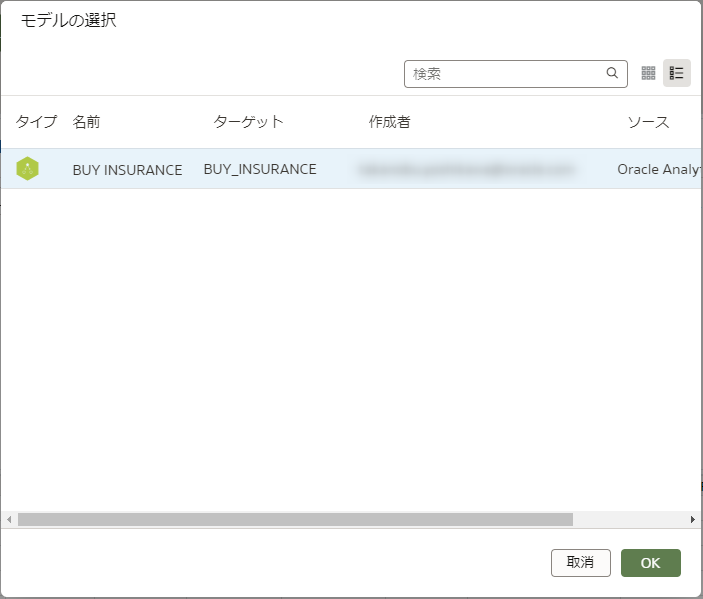
ステップを追加するために「+」をクリックして、「モデルの適用」をクリックします。

先程作成した機械学習モデルをクリックして選択します。
さらに「データの保存」ステップを追加します。

データセット名とデータセット表に任意の名称を入力します。

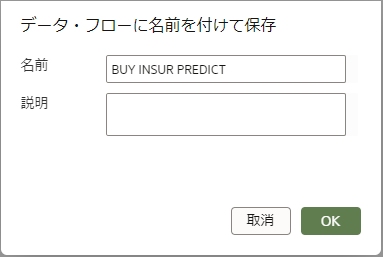
データフローを保存します。

データフローの名前を入力します。
データフローを実行します。
予測したデータセットでワークブックを作成
データフローの実行が完了したら、データメニューでデータセットの一覧を確認します。
指定した名前のデータセットが作成されていたら、クリックしてワークブックを作成します。

ワークブックで可視化の体裁を整えたら完成です。
PredictiveValue列が予測結果で、BUY_INSURANCE列が実際の値です。

おわりに
1行もコードを書かずに機械学習モデルを作成し、それをデータに適用することができました。
トレーニングのためのデータフローで、機械学習アルゴリズムを変更したり、パラメータを変更したりして、結果がどうなるかを試してみてください。