はじめに
最近はオープンデータとして様々なデータが手に入ります。
タダで使わせてもらっている身でこんなことを言うのは気がひけますが、使用するまでに加工しなければならないことも結構あります。
例えば、余分な空白の除去など。
あるデータを入手したところ、都道府県名に空白が含まれていることがわかりました。
今回は、Oracle Analytics Cloud(OAC)のデータ準備機能で余分な空白を取り除いてみようと思います。
どんなデータだったか
オリジナルのデータはこんな感じでした。
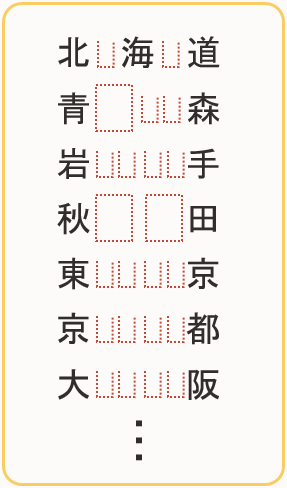
幅?を合わせるために空白で調整されています。
しかも! 半角と全角が入り乱れていました。例えば青森は「青」と「森」の間に全角空白が1つと半角空白が2つあります。
岩手は「岩」と「手」の間に半角空白4つ、秋田は「秋」と「田」の間に全角空白2つがあります。
どのようにしたいか
- 全角であれ、半角であれ空白は全部取り除きます。
- 都府県を付与します(北海道以外)。
できあがりイメージです。

データセットから空白を削除
問題のデータが含まれるデータセットを開きます。
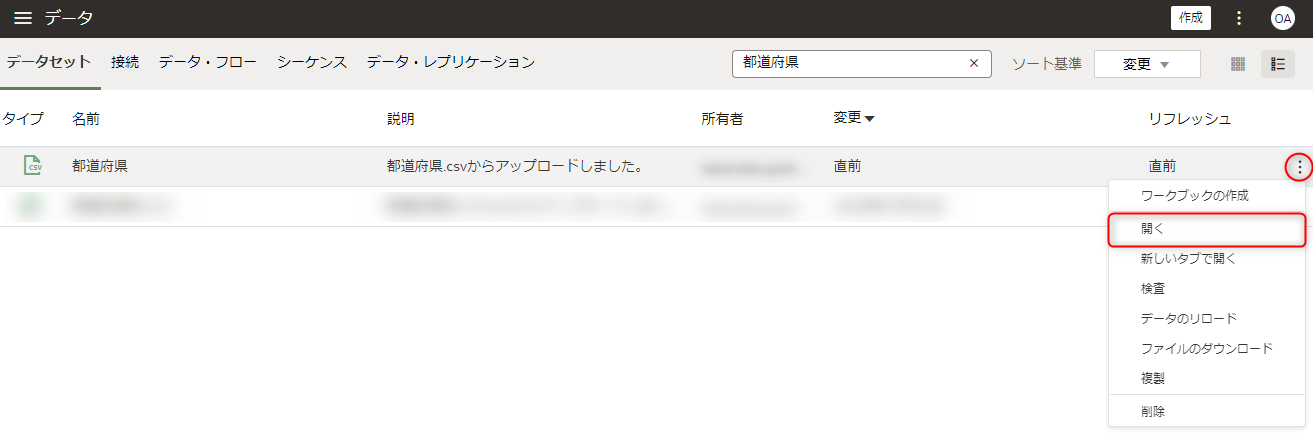
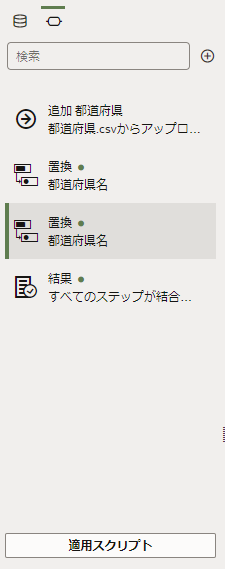
列名の「オプション」メニューから「置換」を選択します。
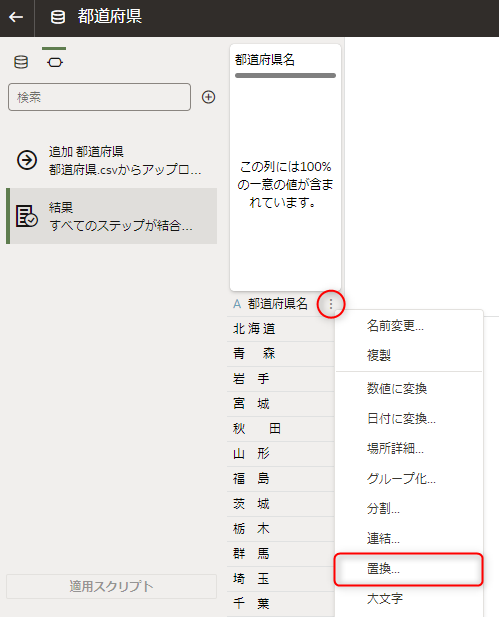
「置換する文字列」として全角空白を入力し、「新規文字列」には何も入力しません。
「一部の値と一致」オプションが選択されているのを確認します。
「秋 田」は全角空白が取り除かれて、「秋田」になっているのがわかります。「青 森」は「青 森」になりました。
確認できたら「ステップの追加」をクリックします。
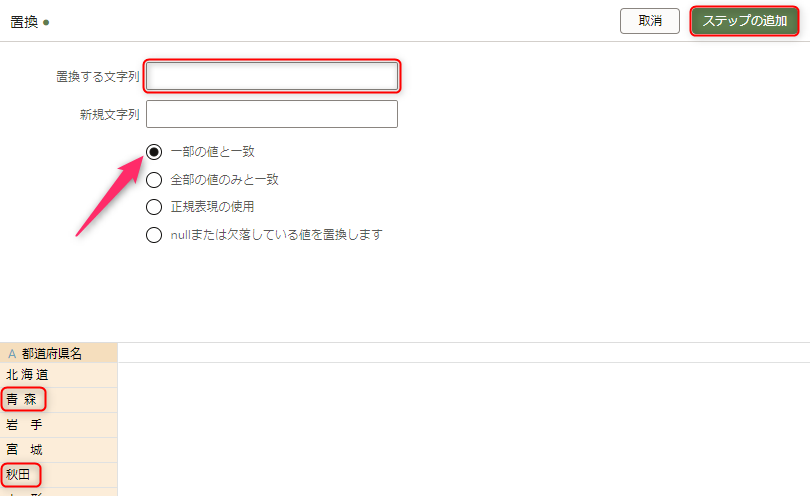
続いて、もう一度同じ列のオプションメニューから「置換」を選択します。
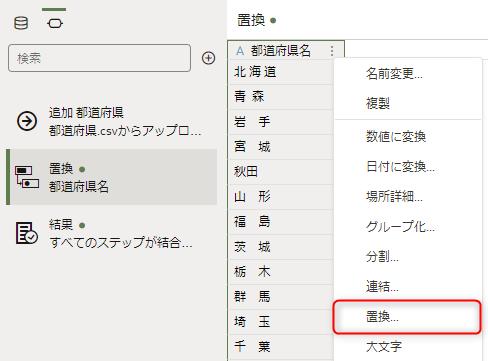
先ほどと同じ要領で、今度は「置換する文字列」に半角空白を入力し、「ステップの追加」をクリックします。
左の準備スクリプトのリストが、このようになります。
データに「都府県」を付与します
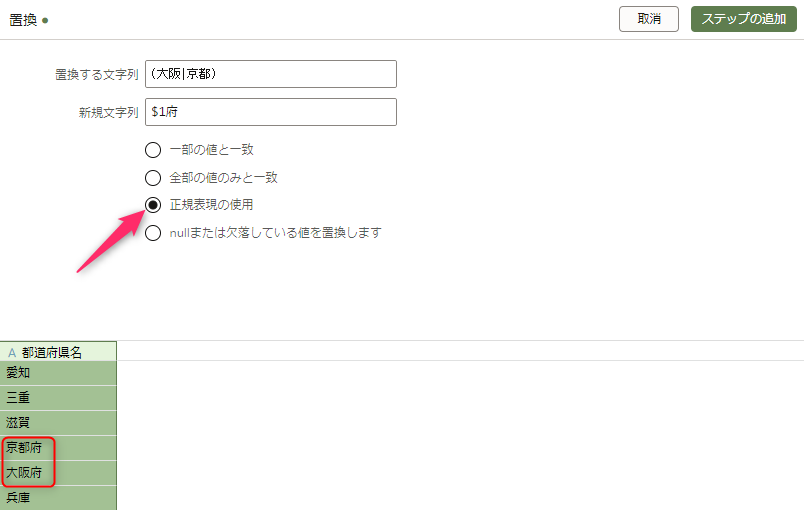
大阪か京都の場合は「府」を付与します
これまでと同じ手順で、列のオプションメニューから「置換」を選択します。
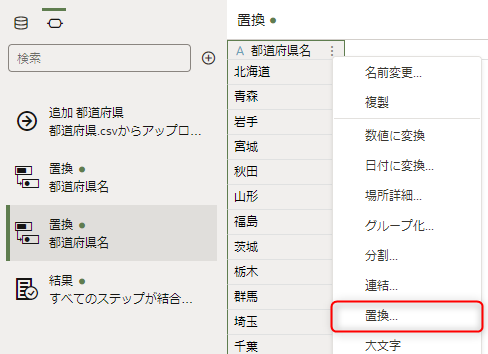
「置換する文字列」は「(大阪|京都)」と入力します。
「新規文字列」は「$1府」と入力します。
「正規表現の使用」オプションを選択し、プレビューで大阪と京都のみ「府」が付与されているのを確認したら、「ステップの追加」をクリックします。
東京に「都」を付与します
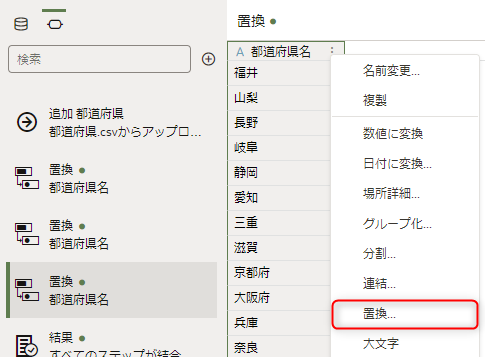
「置換する文字列」は「(東京)」、新規文字列は「$1都」、「正規表現の使用」オプションを選択します。
プレビューを確認したら「ステップの追加」をクリックします。
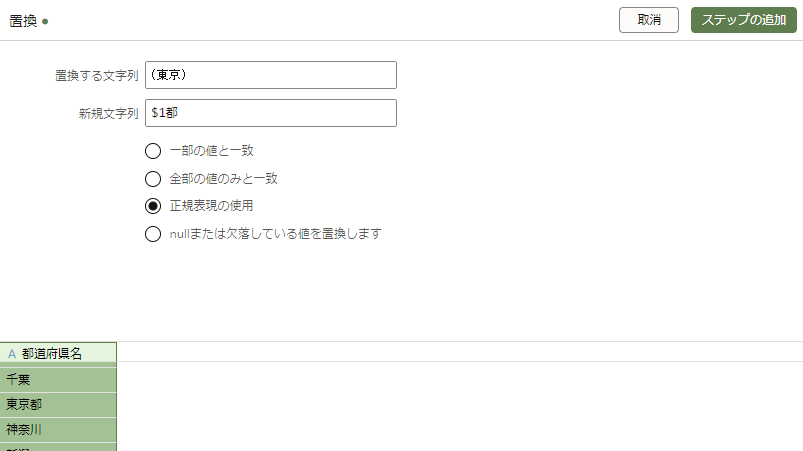
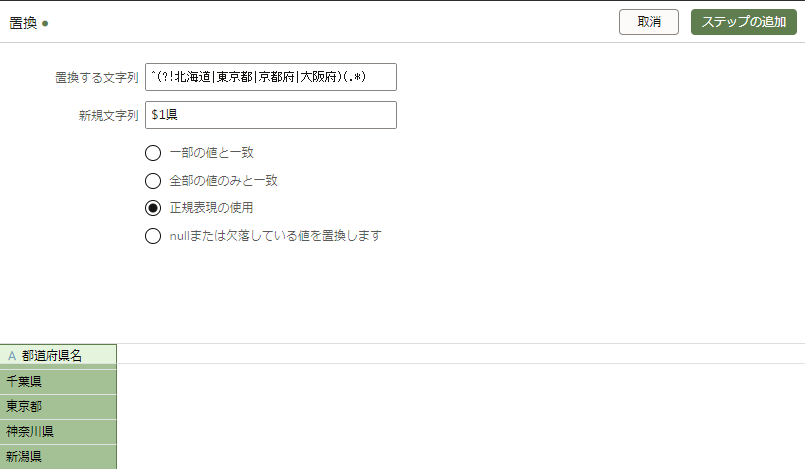
北海道、東京都、京都府、大阪府以外に「県」を付与します
列のオプションメニューから「置換」を選択します。
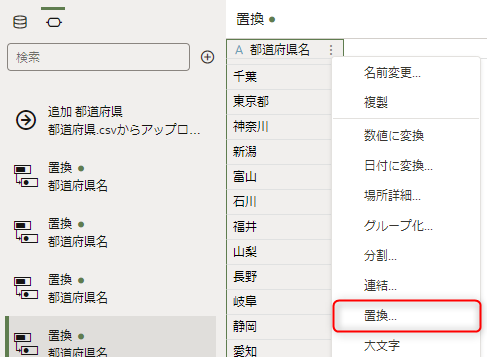
「置換する文字列」は「^(?!北海道|東京都|京都府|大阪府)(.*)」と入力します。
「新規文字列」は「$1県」と入力します。
「正規表現の使用」オプションを選択し、プレビューを確認します。
問題なければ、「ステップの追加」をクリックします。
スクリプトを適用
左の準備スクリプトのリストがこのようになります。

「適用スクリプト」ボタンをクリックします。
これにより、これまでのステップがデータセットに反映されます。
ワークブックを作って確認
動作確認できました。完成!
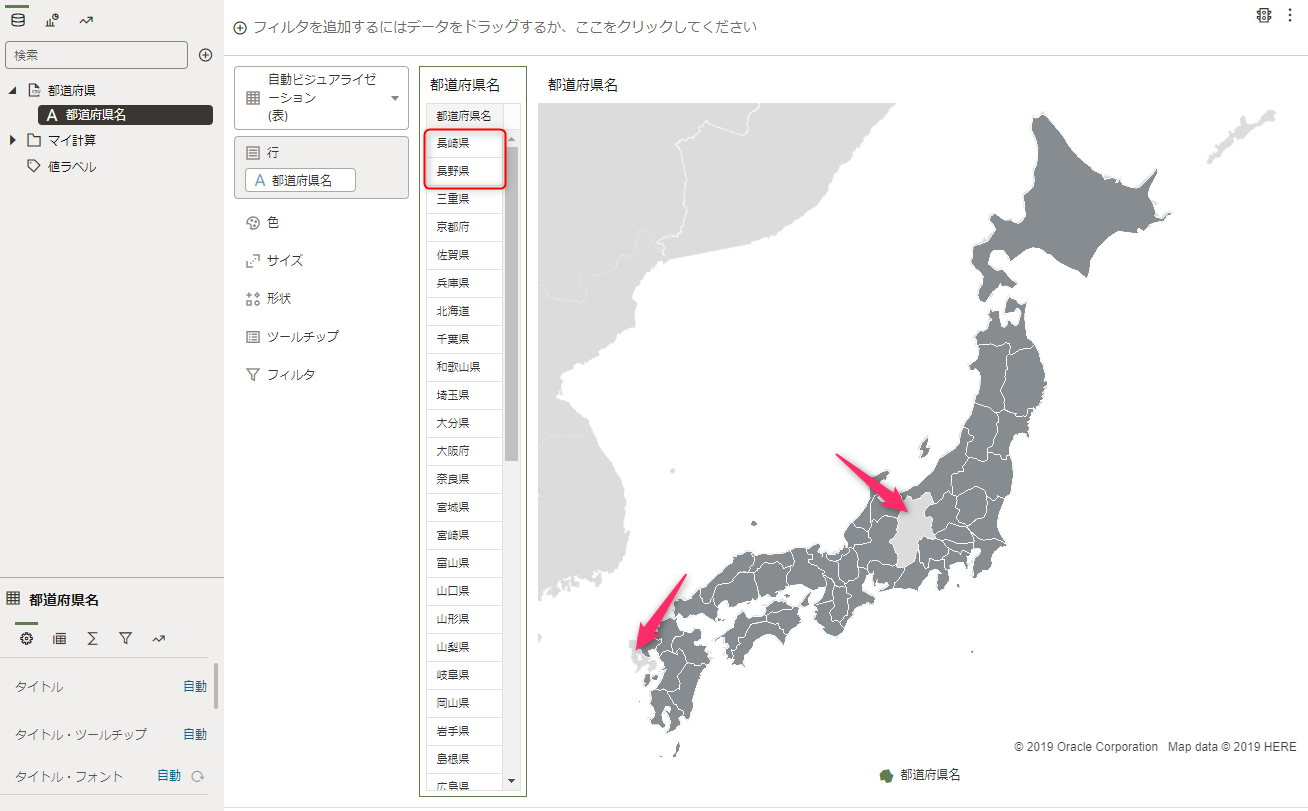
と、思ったらおかしなところを見つけてしまいました。
「長野県」と「長崎県」のデータがありません。
いやいや、そんなことはないはず。表にはありますよね?
ちょっと修正
というわけで、元データをメモ帳で読み込んでみました。
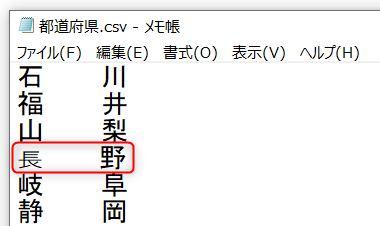
「長」の字が普通の「長」ではありませんでした。
「あるある」です。
データセットにもう一つ「置換」を追加します。
ぱっと見、「置換する文字列」と「新規文字列」に同じ「長」が入力されているように見えますが違います。
「置換する文字列」はメモ帳からコピペしてきた奇妙な方の「長」で、「新規文字列」は通常の「長」です。
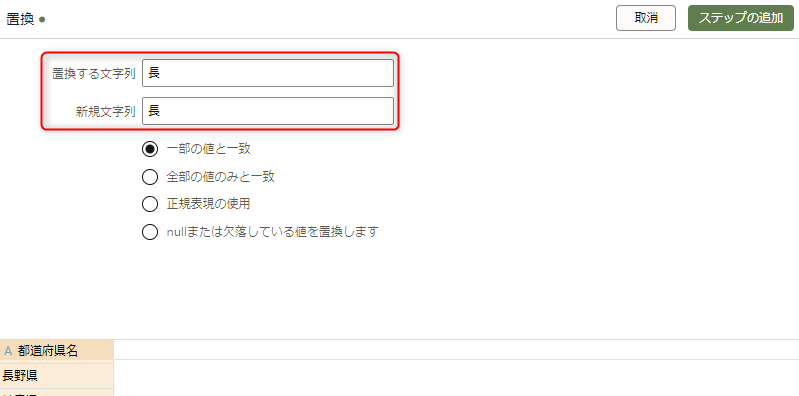
「ステップの追加」をクリックして、「適用スクリプト」ボタンをクリックします。
ふたたび確認
今度は、全部の都道府県をちゃんと認識できました。(カラフルにしてみました)
