はじめに
YOASOBIの「アイドル」がYouTubeの「music charts TOP 100 songs Global」で首位を獲得したという記事を目にして、YouTube動画やチャンネルのデータ取得と分析に興味を持ちました。
今回は、YouTubeの急上昇音楽動画についてデータの取得と各動画のコメントの言語種情報を可視化するプログラムを作成してみました。コメントの日本語以外の外国語率を見ることで、海外での関心の高さを測れます。
開発環境
*Google Colaboratory(Colab Pro.)
*Python
*事前にGoogle CloudにてAPI Keyを取得しておきます。
Install
最初に以下をインストールします。Google Colaboratoryでは頭に!をつけます。
!pip install google-api-python-client
!pip install langid # 言語種の判定
!pip install tqdm
!pip install japanize-matplotlib
Import
import pandas as pd
from tqdm import tqdm
# apiclient
from apiclient.discovery import build
from apiclient.errors import HttpError
# comment langid
import requests
import json
import langid # 言語種判定
import collections
# plot
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
YouTubeの急上昇音楽動画情報の取得
YouTube Data APIのバージョンとAPIキーを設定
API_KEY = "" # ここに自分のAPIキーを入力
YOUTUBE_API_SERVICE_NAME = 'youtube'
YOUTUBE_API_VERSION = 'v3'
youtube = build(
YOUTUBE_API_SERVICE_NAME,
YOUTUBE_API_VERSION,
developerKey=API_KEY
)
急上昇music videoデータを取得してデータフレームに
youtube.vieos().list()はAPI リクエストのパラメータに一致する動画のリストを返します。
partパラメータでは、APIレスポンスに含める1つ以上のvideoリソース プロパティのカンマ区切りリストを指定します。
今回は、snippetとstatisticsを指定します。snippetプロパティには channelId、title、description、tags、categoryId の各プロパティが含まれています。statisticsプロパティにはviewCount,likeCount,commentCountの統計情報の各プロパティが含まれています。
chart='mostPopular'、regionCode='JP'、videoCategoryId=10を組み合わせて指定すると日本で視聴できるmusic videoの急上昇動画30位までのデータを取得できます。
videos = youtube.videos().list(part='snippet,statistics,
chart='mostPopular',
regionCode='JP',
videoCategoryId=10,
maxResults=30
).execute()['items']
print(len(videos))
id_l = []
title_l = []
publishedAt_l = []
country_l = []
lang_l = []
channelTitle_l = []
categoryId_l = []
viewCount_l = []
likeCount_l = []
commentCount_l = []
for video in videos:
id_l.append(video['id'])
title_l.append(video['snippet']['title'])
publishedAt_l.append(video['snippet']['publishedAt'])
try:
lang_l.append(video['snippet']['defaultLanguage'])
except KeyError:
lang_l.append('ja')
channelTitle_l.append(video['snippet']['channelTitle'])
categoryId_l.append(video['snippet']['categoryId'])
viewCount_l.append(video['statistics']['viewCount'])
try:
likeCount_l.append(video['statistics']['likeCount'])
except KeyError:
likeCount_l.append('')
try:
commentCount_l.append(video['statistics']['commentCount'])
except KeyError:
commentCount_l.append('')
df = pd.DataFrame({'id':id_l, 'title':title_l, 'published':publishedAt_l,
'defaultLanguage': lang_l,
'channelTitle':channelTitle_l, 'categoryID':categoryId_l,
'viewCount':viewCount_l, 'likeCount':likeCount_l, 'commentCount':commentCount_l})
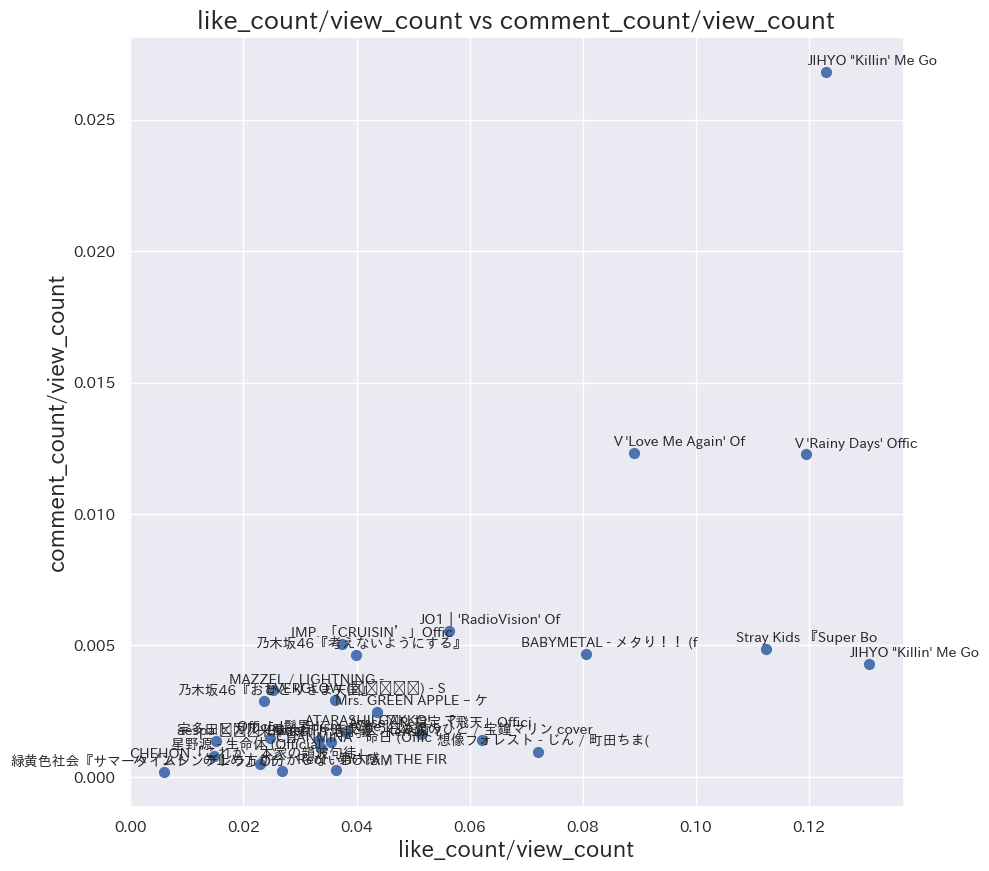
likeCount/viewCount vs commentCount/viewCount の2次元散布図
df_nd = df.dropna(subset=['likeCount', 'commentCount'])
x = df_nd['likeCount'].astype(float)/df_nd['viewCount'].astype(float)
y = df_nd['commentCount'].astype(float)/df_nd['viewCount'].astype(float)
plt.figure(figsize=(10,10))
plt.scatter(x, y, s=50)
plt.title('like_count/view_count vs comment_count/view_count', fontsize=18)
plt.xlabel("like_count/view_count", fontsize=16)
plt.ylabel("comment_count/view_count", fontsize=16)
# 散布図の各点にラベルを追加します。
for i, title in enumerate(df_nd['title']):
title = title[:20]
plt.annotate(title, xy=(x[i:i+1], y[i:i+1]),
xytext=(80, 5), textcoords='offset points', ha='right', size=10)
plt.show()
各MVのコメントの外国語率(日本語以外)を計算
各mvのコメントを取得するための、関数定義
パラメータ 'order': 'relevance' として評価の高いコメント取得します。取得するコメントが2000を超えないので、時間が短いことと、RecursionError が起きにくくなります。多くのコメントを取得したい場合は、'order': 'time'とします。時系列順でコメントが取得できますが、時間がかかることと、RecursionErrorが起きる場合があります。
URL = 'https://www.googleapis.com/youtube/v3/'
# ここにAPI KEYを入力
API_KEY = ''
def video_comment(no, video_id, next_page_token):
params = {
'key': API_KEY,
'part': 'snippet',
'videoId': video_id,
'order': 'relevance',
#'order': 'time',
'textFormat': 'plaintext',
'maxResults': 100,
}
if next_page_token is not None:
params['pageToken'] = next_page_token
response = requests.get(URL + 'commentThreads', params=params)
resource = response.json()
for comment_info in resource['items']:
# コメント
text = comment_info['snippet']['topLevelComment']['snippet']['textDisplay']
nos.append(no)
text_rep = text.replace('\r', '\n').replace('\n', ' ')
texts.append(text_rep)
no = no + 1
if 'nextPageToken' in resource:
video_comment(no, video_id, resource["nextPageToken"])
コメントの取得と、言語判定、日本語以外の外国語率の計算
関数vidio_commentの実行ではエラーへの対処で例外処理をしています。
ja_counts_l = []
langid_all = []
f_lang_l = []
f_lang_rate_l = []
error_l = []
eno = 0
for video_id in tqdm(df['id']):
# コメントの取得
no = 1
nos =[]
texts = []
try:
video_comment(no, video_id, None)
except RecursionError:
error_l.append(video_id)
continue
except KeyError:
error_l.append(video_id)
eno = eno + 1
continue
# データフレームに
df_com = pd.DataFrame({'no': nos, 'text': texts})
# 言語種別
comment_l = df_com['text'].tolist()
langid_l = []
for comment in comment_l:
result = langid.classify(comment)
langid_l.append(result[0])
c = collections.Counter(langid_l)
f_count = len(langid_l) - c['ja']
f_lang_l.append(f_count)
langid_all.append(len(langid_l))
f_lang_rate = f_count/len(langid_l)
f_lang_rate_l.append(f_lang_rate)
print()
print('error',error_l)
df = df[~df['id'].isin(error_l)]
df['f_count'] = f_lang_l
df['langid_count'] = langid_all
df['f_rate'] = f_lang_rate_l
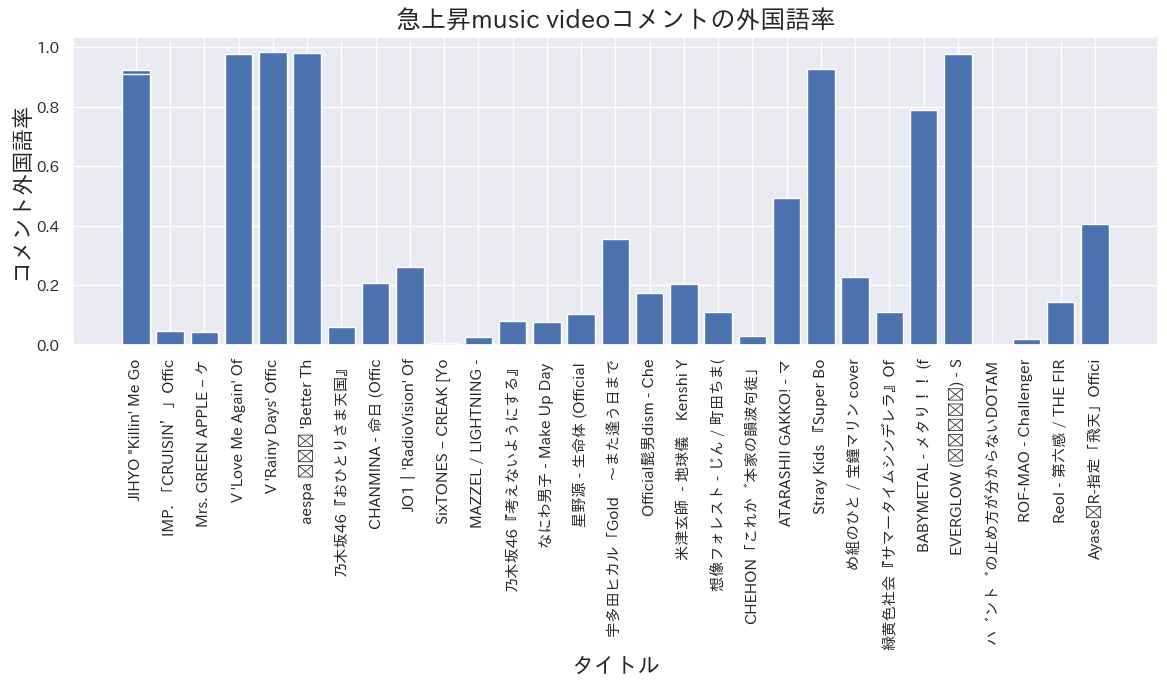
各MVコメントの外国語率をbar plotで
#各MVタイトルの文字数を制限
title20 = []
for title in df['title']:
title = title[:20]
title20.append(title)
# barplot
plt.figure(figsize=(14,4))
plt.bar(title20, df['f_rate'])
plt.title('急上昇music videoコメントの外国語率', fontsize=18)
plt.xlabel("タイトル", fontsize=16)
plt.ylabel("コメント外国語率", fontsize=16)
plt.xticks(rotation=90)
plt.show()