追記
python2で実行できるコードをpython3で実行できるように変換するツール
https://docs.python.org/ja/3/library/2to3.html
2to3 - Python 2 から 3 への自動コード変換
インストール(ubuntuの場合)
$ sudo apt install 2to3
実行
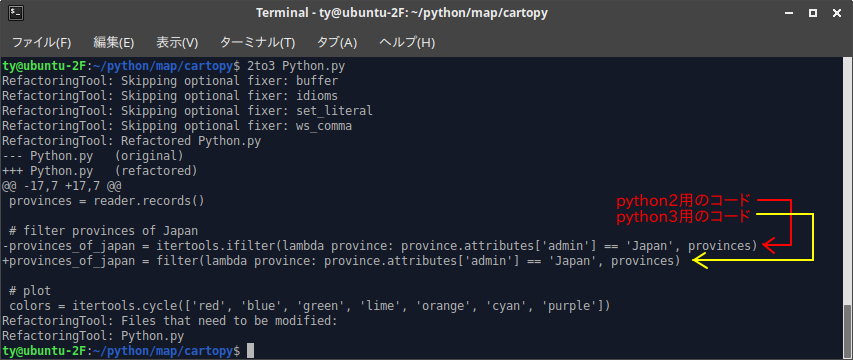
これで完全にpython3で動くようにならないようです。
python2からpython3に変更になった所の部分で変換できるものだけを変換している?
残りは自分でコードを変更しなくてはいけないようです。
HelpをGoogle翻訳で翻訳
$ 2to3 --help
Usage: 2to3 [options] file|dir ...
Options:
-h, --help このヘルプメッセージを表示して終了する
-d, --doctests_only doctestsだけを修正する
https://docs.python.org/ja/3/library/doctest.html
-f FIX, --fix=FIX 各FIXは変換を指定します。 デフォルト:all
-j PROCESSES, --processes=PROCESSES
2to3を同時に実行する
-x NOFIX, --nofix=NOFIX
変換が実行されないようにする
-l, --list-fixes 利用可能な変換を一覧表示する
-p, --print-function print()が関数になるように文法を修正する
-v, --verbose より詳細なログ記録
--no-diffs リファクタリングの差分を表示しない
-w, --write 変更したファイルを書き戻す
-n, --nobackups 変更されたファイルのバックアップを書き込まない
-o OUTPUT_DIR, --output-dir=OUTPUT_DIR
入力ファイルを上書きするのではなく、このディレクトリに出力ファイルを置きます。 -nが必要です。
-W, --write-unchanged-files
変更が不要な場合でもファイルを書き込みます(--output-dirを使用すると便利です)。 -wを意味します。
--add-suffix=ADD_SUFFIX
この文字列をすべての出力ファイル名に追加します。 空でない場合は-nが必要です。 例:--add-suffix = '3'は.py3ファイルを生成します。
Python2のファイルをPython3のファイルに変換する場合(バックアップファイルが不要の場合、 -n を追加)
print 'asdf'
$ 2to3 -w test.py
Python3用のコードに変更される
print ('asdf')
元のファイルは.bakファイルとして保存される(不要の場合、 -n)
print 'asdf'
参考にしたいコードをネットで良く探しますが、Python2のコードの方が多いような気がします。
私は、Python3で動作しないもの以外はPython2を使用しないので、対比表を作ろうと思いました。
わかった時に追加していきたいと思います。
これは、関係ありませんが便利なので、
コードの1行目に(#は全角で記入しています。)
#!/usr/bin/python3
#!/usr/bin/python
等を入れると、実行する時に、「./test.py」のようにpython3を入力しなくてもプログラムを実行することが出来る。
Python2でコメントに日本語を使用すると、エラーになりますが、(#は全角で記入しています。)
# -- coding: utf-8 --
# coding: utf-8
等をコードの2行目に入れるとエラーにならない。
Python3を使うことが多くエラーにならないので入れて無かったのですが、入れるように癖をつけようと思います。
海外のサイトでこんな便利な使い方を見つけました。
python2でもpython3でも、どちらでも使える
try:
# for Python2
import Tkinter as tk
import ScrolledText as tkst
except ImportError:
# for Python3
import tkinter as tk
import tkinter.scrolledtext as tkst
次は、ライブラリがtkinterに統合されているものです。
# import tkMessageBox # for python2
from tkinter import messagebox as tkMessageBox # for python3
# import tkFileDialog # for python2
from tkinter import filedialog as tkFileDialog # for python3
# root=Tkinter.Tk() # for python2
root=tkinter.Tk() # for python3
| Python2 | Python3 | 備考 |
|---|---|---|
| import cStringIO | 存在しない | 「2to3」を実行する |
| import StringIO | 存在しない | 「2to3」を実行する |
| long 型と int 型 | long 型と int 型は 1 つの型に統合され、末尾に付けられていた L はなくなりました。 | |
| True、False、None がキーワードになりました。 | ||
| >>> 1/2 | >>> 1//2 | |
| 0 | 0 | |
| >>> 1./2. | >>> 1/2 | |
| 0.5 | 0.5 | |
| print’文字列’ | print(‘文字列’) | 比較的に多い。Python3では( )が必要。例. |
| print は命令 | print は関数 | |
| ー | print(f'{year} / {month} / {day}') | Python3.6以降、 f を頭につけることで変数を直接指定できる(参考参照) |
| >>> b = (b'\xc3\x9f\x65\x74\x61') | >>> b = (b'\xc3\x9f\x65\x74\x61') | バイト・リテラルは、 |
| >>> print(b) | >>> print(b) | 先頭に b が付いた |
| ßeta | b'\xc3\x9feta' | ストリングです |
| a = raw_input("何か入力してください: ") | a = input("何か入力してください: ") | |
| print(a) | print(a) | |
| >>> repr('é') | >>> repr('é') | |
| "'\xc3\xa9'" | "'é'" | |
| for i in xrange(0, 10000) | for i in range(0, 10000) | 巨大な数列のループはPython2ではxrange()、Python 3ではxrangeはrangeに統合 |
| map()は[100, 200, 300]というリストを返す | map()はリストではなくmapオブジェクトを返す | |
| GUI----Tkinter関係 | ||
| import Tkinter | import tkinter | |
| import tkMessageBox | from tkinter import messagebox as tkMessageBox | Python3ではtkinterに統合。例. |
| import tkFileDialog | from tkinter import filedialog as tkFileDialog | Python3ではtkinterに統合。例. |
| import ScrolledText | from tkinter import scrolledtext as ScrolledText | Python3ではtkinterに統合。例. |
| root=Tkinter.Tk() | root=tkinter.Tk() | 例 |
| シェルにコマンドを送ってその出力を取得 | ||
| import commands | import os | Python3ではcommandsモジュール削除。例. |
| result = commands.getoutput(‘ls -la’) | result = os.system("ls -la") | 例 |
| import subprocess | 例 | |
| result = subprocess.run(["ls", "-l"]) | Python 3.5 で追加。例. | |
| from StringIO import StringIO | from io import StringIO | |
| cmp(a,b) | 削除されました | この表の下を参照 |
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, cwd=None, timeout=None, check=False, encoding=None, errors=None)(原文)
args で指定されたコマンドを実行します。コマンドの完了を待って、CompletedProcess インスタンスを返します。
Ubuntu Stdio 17.10から18.04LTSにアップグレードしたら、今迄Python2で動作していたプログラムが実行時に'ascii'codec can't・・・が出ました。(全てではなく、ほんの一部だけなのです。)
Python3の方は問題ありません。
検索していたら、次のコードで解決しました。
try:
#Python2の場合
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
except NameError:
pass #Python3
cmp()関数
https://qiita.com/norioc/items/cb533d009aa63453df40
Python 3のsorted関数と比較関数 を参考にさせていただきました。
# Python2の場合
print "cmp(80, 100) : ", cmp(80, 100)
cmp(80, 100) : -1 # 結果
# Python3の場合
def cmp_python3(a,b):
if a == b : return 0
return -1 if a < b else 1
print ("cmp(80, 100) : ", cmp_python3(80, 100))
# ------結果
cmp(80, 100) : -1
参考
Pythonでたまに使いたくなるもの
Python2と3のパッケージの違い( cPickle:_pickle 、xrange:range、from StringIO import StringIO:from io import StringIO)
https://qiita.com/yoyoyo_/items/934400bc2d1b738be865
Python3.6から使用できるprint文
https://qiita.com/Rendlire/items/18a7d23f8fd953a34e2e
minus9d's diary
http://minus9d.hatenablog.com/entry/20131015/1381849395