あらすじ
―Twitterにて―
ぼく「あ、グラブルの神絵師がRTで回ってきた!メディア欄から他のイラストも見よう!……ん?」
『スマホRPGは今これをやってるよ。今のジョブはこれ!』
『C85E2274 :参戦ID 参加者募集! Lv200 アルティメットバハムート』
『DE56A137 :参戦ID 参加者募集! Lv150 ルシファー』
……
ぼく「こいつらメディア欄に居座って邪魔だなあ、終わった救援ツイートとかいらないし、消せたら嬉しいな」
作ったもの
Twitter連携によって、上記のツイートを12時間毎に削除してくれるwebアプリ『ソシャゲツイート削除ったー』を作りました。以下のURLからTwitter連携すると使うことができました。(2022年11月27日から休止中です。)
グラブル以外にも対応したいので他のソシャゲ情報提供をいつでもお待ちしております。
仕組み
- アプリ連携したユーザーのTwitterアクセストークンを取得・DBに保存
- 各ユーザーのツイートを取得し、特定のキーワード、viaを持つツイートを抽出
- 抽出したツイートを削除する
- Herokuで定期実行する
実装
事前準備
- Twitter Developer登録
- Heroku 登録
これらについては別の方々の記事がたくさんあるのでそちらを見ていただくといいと思います.
アプリ連携したユーザーのアクセストークンの取得・DB保存
この部分はこちらの記事をがっつり参考にさせていただき,htmlの文面とDBにアクセストークンを保存するコードを追加した形です.
PythonとFlaskとHerokuでTwitterのOAuth認証ページを作った
まず,このプロジェクト全体としてPythonを使用しています.WebフレームワークとしてFlaskを使用しています.Twitterアプリに必要なコンシューマーキーやコンシューマーシークレットなどは,Herokuに環境変数を保存できる機能を利用して,os.environによって取得しています.
import os
import oauth2 as oauth
from flask import Flask, render_template, request
import psycopg2
app = Flask(__name__)
request_token_url = 'https://twitter.com/oauth/request_token'
access_token_url = 'https://twitter.com/oauth/access_token'
authenticate_url = 'https://twitter.com/oauth/authorize'
callback_url = 'https://delete-socialgames-tweets.herokuapp.com'
consumer_key = os.environ['CONSUMER_KEY']
consumer_secret = os.environ['CONSUMER_SECRET']
ユーザーがアプリのURLに飛ぶと,check_token()によって自動的にリダイレクトされてTwitterのアプリ連携認証ページが表示されます.ユーザーが認証を行うと同じURLにコールバックしてトークンが取得できるので,HerokuのDB機能がサポートしているPostgreSQLをpsycopg2を通して実行することで保存します.
@app.route("/")
def check_token():
oauth_token = request.args.get('oauth_token', default="failed", type=str)
oauth_verifier = request.args.get('oauth_verifier', default="failed", type=str)
if oauth_token != "failed" and oauth_verifier != "failed":
response = get_access_token(oauth_token, oauth_verifier).decode('utf-8')
response = dict(parse_qsl(response))
oauth_token = response['oauth_token']
oauth_token_secret = response['oauth_token_secret']
db_url = os.environ['DATABASE_URL']
conn = psycopg2.connect(db_url, sslmode='require')
cur = conn.cursor()
cur.execute("insert into token (access_token, access_token_secret) values (%s, %s) on conflict do nothing", (oauth_token, oauth_token_secret))
conn.commit()
return render_template('cer.html', url="NoNeed")
else:
# リクエストトークンを取得する
request_token = get_request_token()
authorize_url = '%s?oauth_token=%s' % (authenticate_url, request_token)
print(authorize_url)
return render_template('cer.html', url=authorize_url, res="NoParams")
各ユーザーのツイートを取得し、特定のキーワード、viaを持つツイートを抽出
各ユーザーのツイートの取得は,ユーザーの最新TL200件を取得するgetリクエストで行います.Twitter APIの無料の範囲内はこれが限界なので,一定以上古いツイートを削除することはできませんでした.
# 自分のツイート取得
def get_timeline(session):
url = "https://api.twitter.com/1.1/statuses/user_timeline.json"
params = {'count': 200, 'include_rts': 'false'}
req = session.get(url, params=params)
if req.status_code == 200:
timeline = json.loads(req.text)
return timeline
else:
print("ERROR: %d" % req.status_code)
exit()
削除対象のキーワードやviaの設定は単純ですがtxtファイルに手動で追加してプログラムで読み込む形にしました.グラブルくんはお行儀が良いので,ツイートのviaがグランブルーファンタジーになります.これによってユーザーの手動ツイートにキーワードが含まれていても削除されなくなります.他のソシャゲはいちいちTwitterアプリを経由してツイートさせる形式だったりするので,それをどう扱うかは今後の課題ですね.
search_words
スマホRPG
参加者募集
source_strings
<a href="http://granbluefantasy.jp/" rel="nofollow">グランブルー ファンタジー</a>
こうして取得したツイートから,上記のsearch_wordsが含まれ,かつviaがsource_stringsに含まれるツイートを抽出して,ツイートを削除する関数に渡します.
# グラブルから送信されたツイートの削除
def delete_gbf_tweets(tweets, session):
for tweet in tweets:
if tweet['source'] in source_strings:
for word in search_words:
if word in tweet['text']:
print(tweet['text'])
delete_tweet(tweet, session)
break
抽出したツイートを削除する
ツイートを削除するためのpostリクエストには,URLにツイート自体のIDを指定する必要があります.Twitter APIではご丁寧にint型のidというキーとstr型のid_strというキーを用意してくれています.これにて無事メディア欄をすっきりさせることができました.
# 指定したツイートの削除
def delete_tweet(tweet, session):
url = "https://api.twitter.com/1.1/statuses/destroy/"+tweet['id_str']+".json"
req = session.post(url)
if req.status_code == 200:
print("delete success!")
else:
print("ERROR: %d" % req.status_code)
Herokuで定期実行する
前述の通り一度に200件しかツイートを取得することができないので,ツイ廃のみなさんに対応するために12時間ごとに削除プログラムを実行することにしました.そのためにHeroku Schedulerというプラグインを使用しました.これは無料プラグインですが,クレジットカードの登録は必要です.また,HerokuのサーバーはUTCで動いているようなので,日本の私たちは9時間未来を生きていることを考慮しましょう.
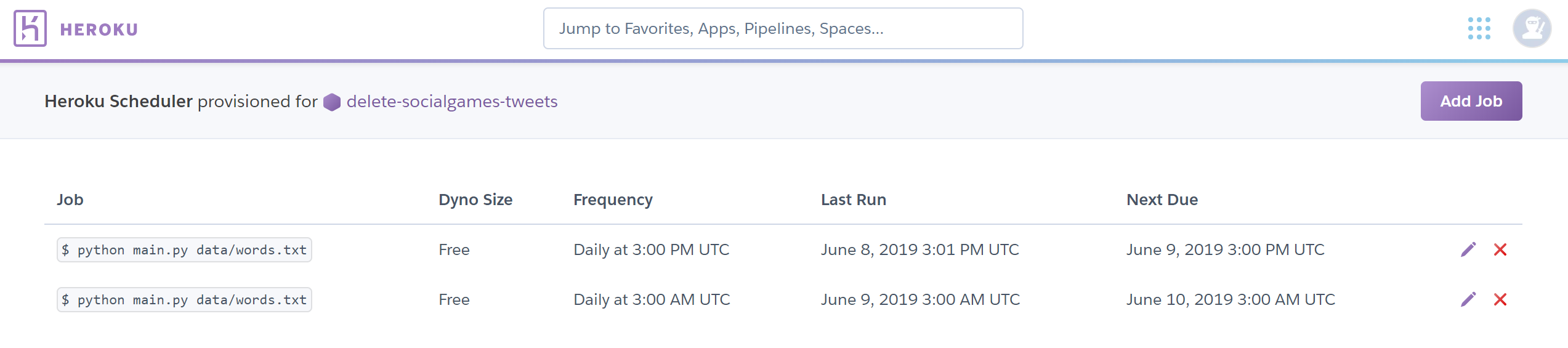
まず,手元で試験的に実行する場合はローカルのconfig.pyをimportしてそこに書いておいたコンシューマーキーなどを読み込んで,ローカルホストのDBを使います.
main関数ではまず各ユーザーのスクリーンネーム(@がつく方)の取得とアップデートを行います.これはDB上で誰がこのアプリを使っているのか確認するのと,アプリ認証を取り消したユーザーをDBから削除するためです.DBから取得した各ユーザーのアクセストークンを使ってセッションオブジェクトを作成してTwitterにアクセスします.ここで401が返ってくる場合,そのユーザーはアプリ認証を取り消しています.
その後はセッションが生きている各ユーザーについて前述の削除プログラムを実行するだけです.おまけに自分のアカウントに確認ツイートをさせています.
# -*- coding:utf-8 -*-
import json
import os
import sys
from requests_oauthlib import OAuth1Session
import psycopg2.extras
import datetime
def main():
cur_select = conn.cursor(cursor_factory=psycopg2.extras.DictCursor)
cur_update = conn.cursor(cursor_factory=psycopg2.extras.DictCursor)
cur_select.execute("select * from token")
for row in cur_select:
at = row['access_token']
ats = row['access_token_secret']
session = OAuth1Session(ck, cs, at, ats)
status_code, screen_name = get_user_screen_name(session)
if screen_name is None:
if status_code == 401:
cur_update.execute("delete from token where id = %s", (row['id'],))
continue
cur_update.execute("update token set screen_name = %s where id = %s", (screen_name, row['id']))
tweets = get_timeline(session)
delete_gbf_tweets(tweets, session)
if screen_name == owner:
post_check_tweet(session)
conn.commit()
conn.close()
# ユーザーのスクリーンネーム取得
def get_user_screen_name(session):
url = "https://api.twitter.com/1.1/account/verify_credentials.json"
req = session.get(url)
if req.status_code == 200:
user_info = json.loads(req.text)
print(user_info['screen_name'])
return req.status_code, user_info['screen_name']
else:
print("ERROR: %d" % req.status_code)
return req.status_code, None
# 自分のツイート取得
def get_timeline(session):
url = "https://api.twitter.com/1.1/statuses/user_timeline.json"
params = {'count': 200, 'include_rts': 'false'}
req = session.get(url, params=params)
if req.status_code == 200:
timeline = json.loads(req.text)
return timeline
else:
print("ERROR: %d" % req.status_code)
exit()
# グラブルから送信されたツイートの削除
def delete_gbf_tweets(tweets, session):
for tweet in tweets:
if tweet['source'] in source_strings:
for word in search_words:
if word in tweet['text']:
print(tweet['text'])
delete_tweet(tweet, session)
break
# 指定したツイートの削除
def delete_tweet(tweet, session):
url = "https://api.twitter.com/1.1/statuses/destroy/"+tweet['id_str']+".json"
req = session.post(url)
if req.status_code == 200:
print("delete success!")
else:
print("ERROR: %d" % req.status_code)
# ツイートをする
def post_tweet(sentence, session):
url = "https://api.twitter.com/1.1/statuses/update.json"
params = {"status": sentence}
req = session.post(url, params=params)
if req.status_code == 200:
print("Succeed!")
else:
print("ERROR : %d" % req.status_code)
# 削除確認ツイートをする
def post_check_tweet(session):
post_tweet("削除成功 at " + str(datetime.datetime.today()), session)
# 検索文字列ファイルの読み込み
def read_search_words(txt_path):
with open(txt_path, 'r') as f:
text_list = f.read().split('\n')
search_words_list = []
source_strings_list = []
mode = 0
for s in text_list:
if s == 'search_words':
mode = 0
elif s == 'source_strings':
mode = 1
elif mode == 0:
search_words_list.append(s)
elif mode == 1:
source_strings_list.append(s)
return search_words_list, source_strings_list
if __name__ == "__main__":
# 手元かどうか判定
if len(sys.argv) > 2:
import config
ck = config.CONSUMER_KEY
cs = config.CONSUMER_SECRET
conn = psycopg2.connect("dbname=%s host=localhost user=%s" % (config.DB_NAME, config.DB_USER))
else:
ck = os.environ['CONSUMER_KEY']
cs = os.environ['CONSUMER_SECRET']
db_url = os.environ['DATABASE_URL']
conn = psycopg2.connect(db_url, sslmode='require')
words_txt_path = sys.argv[1]
search_words, source_strings = read_search_words(words_txt_path)
owner = 'gikolarge'
print(search_words)
print(source_strings)
main()
#あとがき
簡単にまとめると,多くの人が作っているTwitter botの削除版を作ってみたという感じですが,誰かの参考になれば幸いです.今後は別のソシャゲや商品のRTキャンペーンとかにも対応したいなと考えているので,こんなソシャゲのこれは削除したいだとかの情報提供お待ちしております.
私のツイッターアカウント