概要
- はじめに
- 手順
- 使用するデータ
- 形態素解析とはなにか
- 形態素解析に関する実装
- word2vecとはなにか
- word2vecに関する実装
- ニューラルネットワークの学習
- 実験
- 改善点
- おわりに
- 参考
はじめに
僕はよく生放送を見るのですが、嫌なコメントが多いため、コメントを非表示にして見ることが多いです。それで、自分のさじ加減で悪意のあるコメントを取り除くことができる機能があればいいなと思いました。
以下で間違っているところがあれば、教えていただければ幸いです
手順
コメントを取り除くまでの手順は以下の通りです。
- コメントを形態素解析で分解
- 分解された単語をword2vecでベクトル化
- 全てのベクトルの平均を求める
- 求めたベクトルをニューラルネットワークに渡し、感情分析を行う
- 求めた感情分析とユーザーが決めたパラメータを基に表示するコメントを決める
使用するデータ
使用するデータは二つあります。一つ目はニューラルネットワークの学習に使用するデータです。二つ目は生放送でよく見られるコメントをまとめたデータです。
一つ目のニューラルネットワークの学習に使用するデータは[1]からお借りしました。以下のようにコメントと感情ラベルがセットになっています。学習に使うtrainデータ、評価に使うdevデータ、テストに使うtestデータがあります。

ラベル[0,1,2,3,4,5]は["happy", "sad", "disgust", "angry", "fear", "surprise"]に対応しています。
二つ目の生放送でよく見られるコメントをまとめたデータは自分で作成しました。このデータを使ってフィルターがうまく機能しているかのテストをします。

形態素解析とはなにか
形態素解析とは文章を意味を持つ最小単位(形態素)に分解し、各形態素に品詞情報を付与するものです。
形態素解析に関する実装
Mecabを使用しました。辞書としてはmecab-ipadic-NEologdを使用しました[2]。コードは以下のとおりです。[3]を参考にして実装しました。
形態素解析の結果のうち、形態素だけをword_classに格納しています。
import MeCab
def mecab_list(text):
tagger = MeCab.Tagger('/usr/local/src/mecab-ipadic-neologd')
tagger.parse('')
node = tagger.parseToNode(text)
word_class = []
while node:
word = node.surface
word_class.append(word)
node = node.next
return word_class
返り値は以下のようになります。各形態素が","によって区切られています。
['', '▁', 'さんぽ', 'さ', 'ーー', 'ん', '!', '御祝い', 'の', '言葉', '嬉しい', 'です', '、', 'ありがとう', 'ござい', 'ます', '!▁', 'これから', 'も', 'イベント', 'とか', '内田', 'さん', 'の', 'ライブ', 'とか', 'お', '会い', 'する', 'こと', 'あれ', 'ば', 'どうぞ', 'よろしく', 'お願い', 'し', 'ます', '...!!', '']
word2vecとはなにか
単語をベクトル化する技術です。先程取得した形態素解析の結果をword2vecに入力し、ベクトル化を行います。[4]にて学ぶことができます。
word2vecに関する実装
word2vecの学習済み日本語モデルとして[5]を使用させて頂きました。それ以外にも色々とあって、例えば[6]があります。
まずword2vecを今回のデータを用いて再学習させます。その手順は以下のようになります。
- コメントデータをmecab-ipadic-NEologdで分かち書き
- 分かち書きされたコメントデータで再学習
手順1のコードは以下のようになります。元々データが分かち書きされていたので、それをなくして、改めてmecab-ipadic-NEologdで分かち書きしました。Mymecab.mecab_listは先程お見せした関数です。
def mecabWakati(tsvPath,txtPath):
dataPandas = pd.read_csv(tsvPath, delimiter='\t')
dataPandas["text"] = dataPandas["text"].str.replace(' ', '')
f = open(txtPath, 'w')
textList = []
for column_name, item in dataPandas["text"].iteritems():
mecabSplitText = Mymecab.mecab_list(item)
textList.append(' '.join(mecabSplitText))
dataPandas["text"] = textList
dataPandas["text"].to_csv(txtPath,index=False, sep='\n')
手順2のコードは以下のようになります
from gensim.models import word2vec
from gensim.models.word2vec import Word2Vec
model_path = './word2vec.gensim.model'
model = Word2Vec.load(model_path)
# コーパスの読み込み
sentences = word2vec.Text8Corpus("./JAS/mecabTrain.txt")
model.build_vocab(sentences, update=True)
model.train(sentences, total_examples=model.corpus_count, epochs=model.iter)
sentences = word2vec.Text8Corpus("./JAS/mecabDev.txt")
model.build_vocab(sentences, update=True)
model.train(sentences, total_examples=model.corpus_count, epochs=model.iter)
sentences = word2vec.Text8Corpus("./JAS/mecabTest.txt")
model.build_vocab(sentences, update=True)
model.train(sentences, total_examples=model.corpus_count, epochs=model.iter)
そして、再学習したモデルを使ってコメントをベクトル化します。ここでは、以下のように単語ベクトルの平均を求めます。この関数は[7]を参考にしています。ポイントは2つあります。一つ目は単語辞書に登録されていない単語の場合は0ベクトルを格納している点です。二つ目はnum_featuresに格納される50は[5]に合わせている点です。他のモデルを使用する場合はこの値を変更する必要がある可能性が高いです。
def avg_feature_vector(sentence,num_features):
feature_vec = np.zeros((num_features,), dtype="float32") # 特徴ベクトルの入れ物を初期化
for word in sentence:
try:
feature_vec = np.add(feature_vec, model[word])
except KeyError:
feature_vec = np.add(feature_vec, np.zeros((num_features,), dtype="float32"))
if len(sentence) > 0:
feature_vec = np.divide(feature_vec, len(sentence))
return feature_vec
trainX = []
devX = []
testX = []
for text in mecabTrainSplitTextList:
trainX.append(avg_feature_vector(text,50))
for text in mecabDevSplitTextList:
devX.append(avg_feature_vector(text,50))
for text in mecabTestSplitTextList:
testX.append(avg_feature_vector(text,50))
これでコメントをベクトル化することができました。
ニューラルネットワークの学習
ニューラルネットワークにベクトル化されたコメントが表す感情ラベルを答える分類問題を学習させます。再掲になりますが、ラベル[0,1,2,3,4,5]は["happy", "sad", "disgust", "angry", "fear", "surprise"]に対応しています。損失関数として交差エントロピー誤差、勾配法としてSGDを使用しました。ニューラルネットワークの構造は以下の通りです。
class MLPNet (nn.Module):
def __init__(self):
super(MLPNet, self).__init__()
self.fc1 = nn.Linear(50, 400)
self.fc2 = nn.Linear(400, 400)
self.fc3 = nn.Linear(400, num_classes)
self.dropout1 = nn.Dropout2d(0.2)
self.dropout2 = nn.Dropout2d(0.2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.dropout1(x)
x = F.relu(self.fc2(x))
x = self.dropout2(x)
return F.relu(self.fc3(x))
学習結果は以下のようになりました。
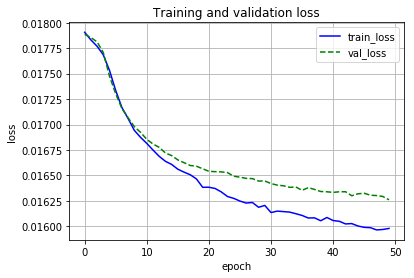
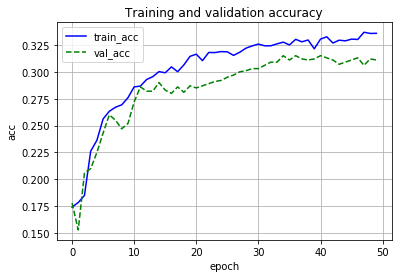
テストデータでは以下のような結果になりました。
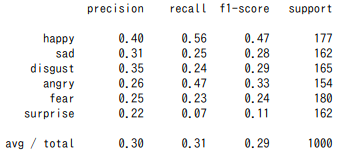
精度は低いです。これは改善点になります。嫌悪と怒りといった感情が両方が含まれているコメントもあると思われるので、とりあえずよしとします。
実験
まずニューラルネットワークの出力をsoftmaxで確率にし、プロットしてみます。
mecabText = Mymecab.mecab_list(text)
vector = avg_feature_vector(mecabText,50)
vector = torch.from_numpy(vector)
vector = vector.to(device)
softmax = []
with torch.no_grad():
outputs = net(vector)
softmaxOutput = F.softmax(outputs)
softmaxOutput = softmaxOutput.cpu().numpy()
label = emotions
plt.pie(softmaxOutput,labels=label)
plt.show()
text = 楽しい!最高です!
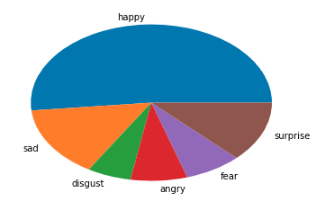
text = 疲れた仕事休みたい
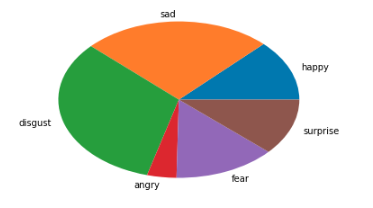
text = 人が嫌い
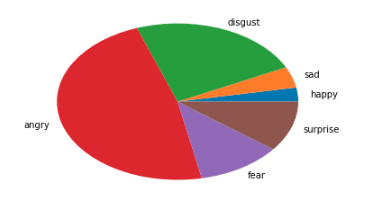
text = お化けが怖い
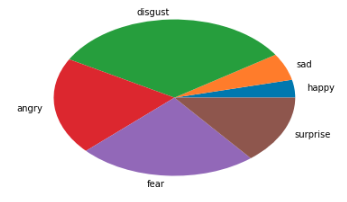
嫌悪と怒りの確率が高すぎる気がしますね...
次に目標としていた生放送のコメントのフィルターを行ってみます。
ファイルからコメントを読み取って、嫌悪が0.30以上または怒りが0.35以上だとファイルに書き込まないようにします。
count = 0
for text in file_text:
mecabText = Mymecab.mecab_list(text)
vector = avg_feature_vector(mecabText,50)
vector = torch.from_numpy(vector)
vector = vector.to(device)
softmax = []
with torch.no_grad():
outputs = net(vector)
softmaxOutput = F.softmax(outputs)
softmaxOutput = softmaxOutput.cpu().numpy()
if softmaxOutput[2] >= 0.30 or softmaxOutput[3] >= 0.35:
print(text)
else:
writefile.write(text)
averageSoftmaxOutput += softmaxOutput
count += 1
averageSoftmaxOutput = averageSoftmaxOutput / count
この条件の時に表示してほしいコメントを0、してほしくないコメントを1にしました。表示してほしくないコメントを真とします。

結果は次のようになりました。

表示してほしくないコメントがちゃんと表示されていないかに着目したいので、再現率で評価します。再現率は9/11で約81%になりました。
改善点
草といった単語はword2vecでベクトル化するときに問題があるために、陽性として判断されたのだと思われます。草の類義語を調べてみます
results = model.most_similar('草')
for result in results:
print(result)

やっぱり笑いに関する単語は類義語として上がってません。生放送のコメントフィルターとして使用するのであれば、インターネットスラングに関するコーパスをword2vecに学習させるのが重要だと思われます。
おわりに
この手法の良さはユーザーで条件を決めれることです。例えば、炎上を楽しみたい人はhappy度が高いコメントを表示しないという使い方もできます。なので、このフィルターをユーザーが決めた条件に沿ったフィルターになっているかという点に着目して評価してみたいです。
参考
[1]https://github.com/sugiyamath/bert/tree/master/JAS
[2]https://github.com/neologd/mecab-ipadic-neologd
[3]https://qiita.com/menon/items/2b5ad487a98882289567
[4]ゼロから作るDeep Learning 2ーー自然言語処理編
[5]http://aial.shiroyagi.co.jp/2017/02/japanese-word2vec-model-builder/
[6]https://www.hottolink.co.jp/blog/20190304-2
[7]https://qiita.com/yoppe/items/512c7c072d08c64afa7e