概要
Go で rand.Float64() を使ったアプリケーションを実装したのですが、goroutine を用いて並列処理をしたときにパフォーマンスが出ませんでした。
pkg/profile でプロファイリングをすると math/rand.Float64 の呼び出しに時間がかかっていることがわかりました。
プロファイリング結果
以下 pprof を用いたプロファイリングの解析結果です。
(pprof) top -cum
Showing nodes accounting for 112.74s, 62.62% of 180.04s total
Dropped 67 nodes (cum <= 0.90s)
Showing top 10 nodes out of 45
flat flat% sum% cum cum%
0 0% 0% 155.60s 86.43% github.com/d-tsuji/tpsa.(*TPSA).Solve.func1
7.12s 3.95% 3.95% 155.59s 86.42% github.com/d-tsuji/tpsa.(*TPSA).sa
0.45s 0.25% 4.20% 127.90s 71.04% math/rand.Float64
0.56s 0.31% 4.52% 127.45s 70.79% math/rand.(*Rand).Float64
0.22s 0.12% 4.64% 126.89s 70.48% math/rand.(*Rand).Int63
5.10s 2.83% 7.47% 126.67s 70.36% math/rand.(*lockedSource).Int63
23.06s 12.81% 20.28% 91.43s 50.78% sync.(*Mutex).Lock
66.98s 37.20% 57.48% 66.98s 37.20% runtime.procyield
0.20s 0.11% 57.59% 52.11s 28.94% sync.runtime_doSpin
9.05s 5.03% 62.62% 25.93s 14.40% sync.(*Mutex).Unlock
svg ファイルを生成して確認するとよりわかりやすいです。

全体の実行時間の約 7 割の時間が rand.Float64 に費やされていることが分かります。
実装の詳細は本質的ではないのですが、参考までに一部を載せておきます。温度並列シミュレーテッドアニーリングの並行処理の実装の一部です。
コード全体は d-tsuji/tpsa で見れます。なお、温度並列シミュレーテッドアニーリングの自体の話は Go Conference 2019 Autumn で話しています。
rand.Float64() は sa のメソッドの中で呼び出しています。
func (t *TPSA) sa(threadNumber int) {
cnt := 0
n := t.Size
for cnt < t.Period {
for i := 0; i < n-2; i++ {
for j := i + 2; j < n; j++ {
current := t.getCost(&t.Tours[threadNumber], i, i+1) + t.getCost(&t.Tours[threadNumber], j, j+1)
next := t.getCost(&t.Tours[threadNumber], i, j) + t.getCost(&t.Tours[threadNumber], i+1, j+1)
// ここで乱数を取得するためにrand.Float64()を呼び出す
p := rand.Float64()
q := t.exchange(next-current, t.Temperatures[threadNumber])
force := p <= q
if next < current || force {
for k := 0; k < (j-i)/2; k++ {
t.flip(threadNumber, i+1+k, j-k)
}
}
}
}
cnt++
}
}
原因
rand.Float64 は全体で 127.90 s 費やしていることが分かります。そのうち Lock と Unlock の処理がそれぞれ全体で 91.43 s と 25.93 s 費やしており、合わせると 117.36 s 費やしています。rand.Float64 の処理における約 9 割の時間が Lock と Unlock に費やされていることが分かりました。
Go のmath/randパッケージのコードを見ると明らかです。math/rand のトップレベルの関数は関数の呼び出す際に共有ロックを取得します。goroutine safe ということでもあります。このあたりの話は open になっている go の issue にもあります。
/*
* Top-level convenience functions
*/
var globalRand = New(&lockedSource{src: NewSource(1).(Source64)})
// ...
// Float64 returns, as a float64, a pseudo-random number in [0.0,1.0)
// from the default Source.
func Float64() float64 { return globalRand.Float64() }
// ...
type lockedSource struct {
lk sync.Mutex
src Source64
}
対応
対応としては The Hidden Dangers of Default Rand を参考にしました。
つまり、goroutine で並行処理する関数内で rand インスタンスを生成し、そのインスタンスを用いて疑似乱数を取得 するようにしました。sa の関数は以下のようになりました。
func (t *TPSA) sa(threadNumber int) {
cnt := 0
n := t.Size
+ random := rand.New(rand.NewSource(time.Now().UnixNano()))
for cnt < t.Period {
for i := 0; i < n-2; i++ {
for j := i + 2; j < n; j++ {
current := t.getCost(&t.Tours[threadNumber], i, i+1) + t.getCost(&t.Tours[threadNumber], j, j+1)
next := t.getCost(&t.Tours[threadNumber], i, j) + t.getCost(&t.Tours[threadNumber], i+1, j+1)
- p := rand.Float64()
+ p := random.Float64()
q := t.exchange(next-current, t.Temperatures[threadNumber])
force := p <= q
if next < current || force {
for k := 0; k < (j-i)/2; k++ {
t.flip(threadNumber, i+1+k, j-k)
}
}
}
}
cnt++
}
}
改善結果
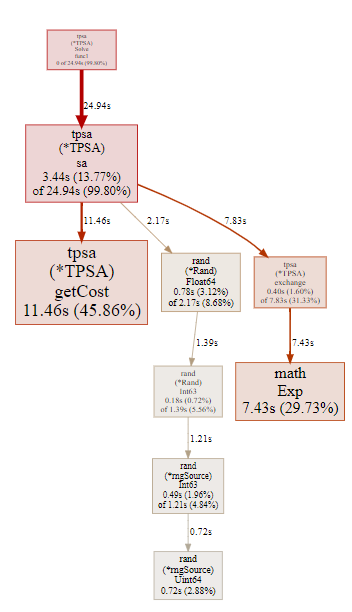
改善後の pprof の結果は以下のようになりました。
(pprof) top -cum
Showing nodes accounting for 24.90s, 99.64% of 24.99s total
Dropped 21 nodes (cum <= 0.12s)
flat flat% sum% cum cum%
0 0% 0% 24.94s 99.80% github.com/d-tsuji/tpsa.(*TPSA).Solve.func1
3.44s 13.77% 13.77% 24.94s 99.80% github.com/d-tsuji/tpsa.(*TPSA).sa
11.46s 45.86% 59.62% 11.46s 45.86% github.com/d-tsuji/tpsa.(*TPSA).getCost
0.40s 1.60% 61.22% 7.83s 31.33% github.com/d-tsuji/tpsa.(*TPSA).exchange
7.43s 29.73% 90.96% 7.43s 29.73% math.Exp
0.78s 3.12% 94.08% 2.17s 8.68% math/rand.(*Rand).Float64
0.18s 0.72% 94.80% 1.39s 5.56% math/rand.(*Rand).Int63
0.49s 1.96% 96.76% 1.21s 4.84% math/rand.(*rngSource).Int63
0.72s 2.88% 99.64% 0.72s 2.88% math/rand.(*rngSource).Uint64
svg で確認してみても rand.Float64 の処理時間は全体の 10 % 程度になっており、大幅に改善されていることが分かりました。
結論
math/rand を並行処理で扱う場合は、並行処理する関数/メソッドごとに rand インスタンスを生成するのがよいのではないでしょうか。