Intro
こちらの技術書を執筆しました。15Stepで踏破 自然言語処理アプリケーション開発入門
本稿は書籍そのものの紹介ではなく、私が技術書を執筆するために利用した技術・用意した環境についての解説です。
私が執筆を始めた当時(2017年下旬)はWebを漁ってもあまり技術書執筆のノウハウがなく、本稿の内容も割と手探りでした。今ググってみると技術書展のおかげで大量に情報が出てきますね。それらと被る部分もありそうですが、自分が1冊書いてみて得たノウハウみたいなものをここに吐き出してみたいと思います。
執筆フォーマットの決定
まずは執筆に使うツールを決めます。
商業誌の場合、出版社(編集者)がそのフォーマットでの入稿を受け付けてくれるかどうかにも依るため、執筆者の一存で決められないこともあるようです。
私の場合は幸運にも、こちらの希望に合わせてくれる編集者が入ってくれました。
色々調べて↓あたりが候補だった気がします(漏れているかも)
- Markdown
- Pandoc
- Sphinx
- TeX
- Asciidoc
- Re:VIEW
要件
その中から、以下のような要件で選んだと記憶しています。
- プレーンテキストで書けるマークアップであること
- Gitで管理したい
- WYSIWYGは使いたくない(文章の修飾にマウスを使うのはだるい)
- 環境構築が楽なこと
- プレビューが速いこと
- 書籍を執筆するのに十分な表現力・記法があること
- 本文以外にも、ソースコード、コラム、引用、脚注などの要素が必要
- インライン要素としては、太字・斜体・等幅フォントなど
- 図版の埋め込みと並べ方の制御なども
- 参照ができること
- 「○章×節で述べたように…」「nnページの図Nは…」のように、書籍中では頻繁に参照が発生する。執筆時から章番号やページを固定値で管理するのは無理なので、文章中の要素や段落を参照する記法が必要。
- import/includeができること
- ソースコードや実行結果は別ファイルに書いてimportする(後述)
- エディタに補助があること
- 数式を書けること
- コメントが書けること
採用
これらの要件から、結局asciidoc(asciidoctor)を採用しました。
例えばMarkdownはエンジニア的には馴染み深いですが、書籍執筆に十分な記法はないし、includeもできないし、参照もできません。
プレビューの速さや環境構築の楽さといった点からTeXも除外。
Re:VIEWも迷いましたが、Re:VIEWは日本ローカルっぽかったので、サポートの厚さや情報の多さに期待してasciidocにしました。
ただ、今選ぶならRe:VIEWにすると思います。
asciidoc(asciidoctor)は最終出力として書籍にあまりフォーカスしていない感じがします。HTML+CSSで出力し、組版ソフトに移して書籍化することになりますが、HTMLを挟むので、意図して入れた空行が消えてしまうなど、いくつか問題がありました。
その点、Re:VIEWは最終的に書籍として出力するようデザインされているようなので、このような問題は起きないのではないかと思います(試してはいない)。
技術書展界隈でもRe:VIEW無双らしいですね。
せっかくなので、asciidoctorで利用しためぼしい要素を挙げておきます。
- インライン修飾やコラムなどの要素: https://asciidoctor.org/docs/user-manual/#comparison-by-example
- include: https://asciidoctor.org/docs/user-manual/#include-directive
- 脚注: https://asciidoctor.org/docs/user-manual/#user-footnotes
- 参照: https://asciidoctor.org/docs/user-manual/#automatic-anchors
- コメント: https://asciidoctor.org/docs/user-manual/#comments
- 数式: asciimath
- 参考文献: asciidoctor-bibtex
執筆環境
特に目新しいことはしていません。
エンジニアが文章を書くなら自然とこうなると思います。
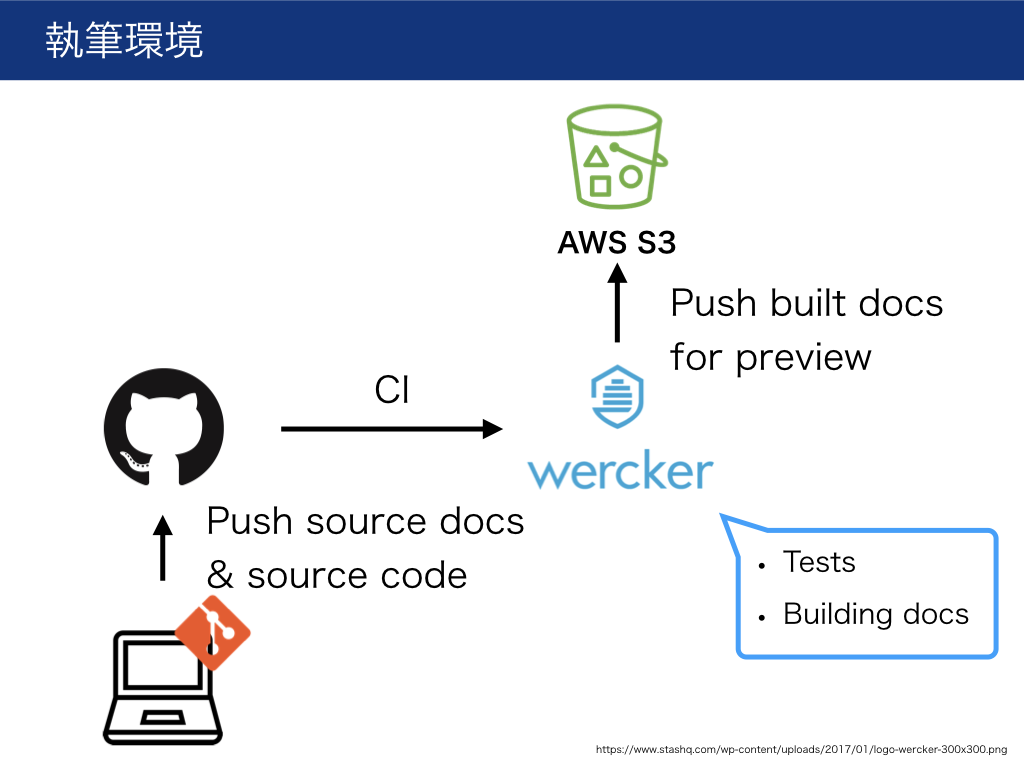
- ファイルは全てGitで管理
- CIで文章・ソースコードをチェック
- CIでHTMLをビルドしてWebサーバに置く(レビュー用)
また、サンプルコードの実行環境はdocker化しておきました。
環境を簡単に再現可能にしておくと、あとで執筆環境について書くときなどに便利です。
書籍の付録としてDockerfileをそのまま配布してしまっても良いと思います。
CIサービスは、当時はdockerが使えるものがWerckerかCircleCI2かしか無く、CircleCI2はまだリリースされたばかりだったので、Werckerを採用しました。
今なら普通にCircleCIでいいと思います。
GitHub
プロジェクトはGitHubで管理します。
ローカルで書いた文章はGitHubへPush。
書き足した文章はPRとして提出し、レビュアがチェック(これ最初はイケてる感じになるかと期待していたんですが、ダメでした。後述)。
ネタはIssueに書き溜め。
…結局、PRレビューが機能しなかったので、GitHubを使う魅力は半減でした(それでも編集者とのコミュニケーションには便利でしたが)。
ディレクトリ構成
ざっくりこんな構成でした
.
├── data // サンプルデータ
├── docs // 本文。asciidocファイルを入れる
│ ├── sec01
│ │ ├── intro.asc
│ │ ...
│ │ └── summary.asc
│ ├── sec02
│ ...
│ ├── images // 埋め込み用画像・図版など
│ └── outputs // サンプルコードの実行例を入れる
│ ├── sec01
│ │ ├── sample01.output
│ │ ...
│ │ └── sample09.output
│ ├── sec02
│ ...
├── src // サンプルコードを入れる
│ ├── sec01
│ │ ├── sample01.py
│ │ ...
│ │ └── sample09.py
│ ├── sec02
│ ...
├── tests // サンプルコードのテストコードを入れる
│ ├── sec01
│ │ ├── test01.py
│ │ ...
│ │ └── test_09.py
│ ├── sec02
│ ...
│ ├── check_runability.bats // 実行可能性チェック
│ └── check_outputs.bats // 実行結果例の整合性チェック
...
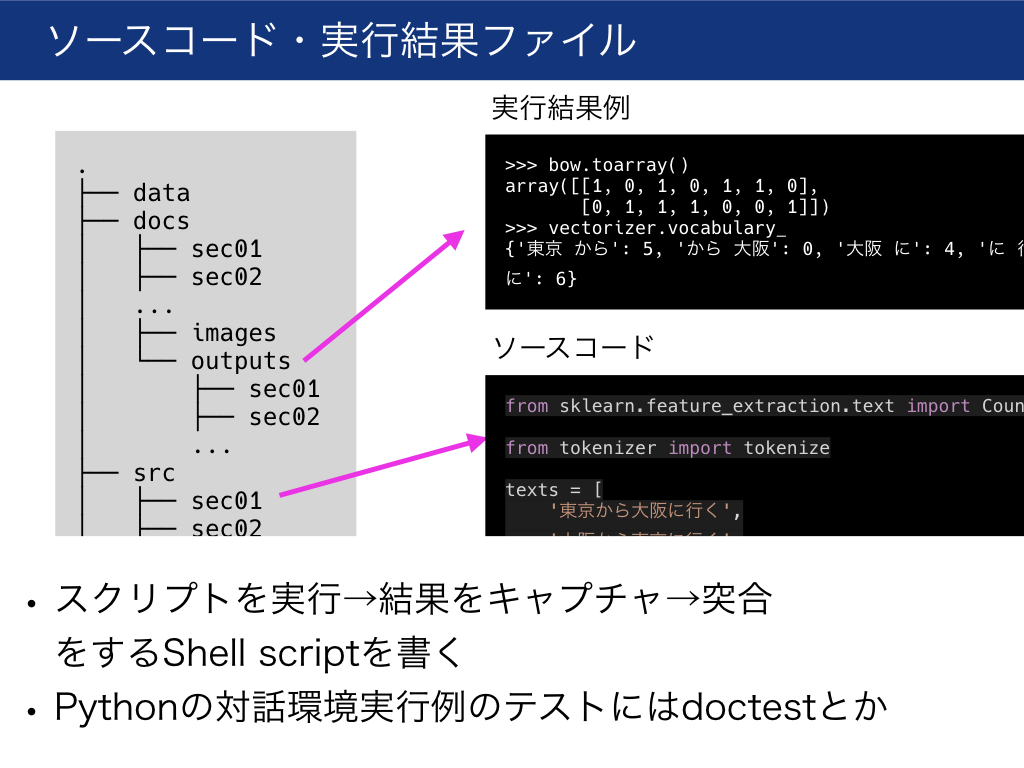
文章はasciidocで書き、docsに入れます。
サンプルコードはasciidoc中にそのまま書くのではなく、src以下に入れてasciidocにはinclude文で埋め込みます。
サンプルコードの実行結果例を載せる場合は、実行結果例をプレーンテキストに書いてdocs/outputsに入れ、includeで埋め込みます。
サンプルコードのテストはtestsに入れます。
これらの意味については次の章で解説します。
テスト
サンプルコードを文章と分けてあるため、サンプルコードに対してテストを容易に実行できます。
執筆中はサンプルコードの手直しが結構発生するので、以下のようなテストを書いて実行可能性や内容の整合性を保証しておくと安心です。修正のたびに手でチェックするより、確実に安全で、楽ができます。
実行可能性テスト
基本的に全てのコードをテストします。
といっても、(扱う内容にもよると思いますが、)一般的なソフトウェア開発におけるテストとは若干毛色が異なります。
今回の書籍の場合、サンプルコードはほとんどが数十行で完結し、単体で実行可能な小規模なものでした。小さな関数に別れているようなものでもありません。
なので、ユニットテストというより、とりあえず実行可能であることを担保するためのスモークテストを全サンプルコードに対して行いました。(アサーションを伴うようなユニットテストも必要に応じて追加します。後述。)
これを行うのが tests/check_runability.batsです。
.batsファイルは特殊な記法のshell scriptです。Batsというテストランナーで実行します(Bats: Bash Automated Testing System)。
そして、check_runability.batsは、ひたすら全てのサンプルコードを「ただ実行するだけ」です。
エラーで落ちたサンプルコードがあれば、テストが失敗してくれます。全て正常終了したらテスト成功です。
とりあえずこれで「サンプルコードを写経したらエラーが出て実行できない」という最悪の事態だけは避けられます。
また、本書の場合、機械学習モデルの学習など、実行に数十分かかるサンプルコードは適宜スキップできるようにしておきました。
実行結果整合性テスト
「このサンプルコードを実行した結果は次のようになります」のように、実行結果例もサンプルコードに併記することがあります。
この実行結果例の正しさもテストで担保しておきます。
「サンプルコードを写経して実行してみたけど、載っている例の通りの出力にならない」という事態を回避します。
これも、サンプルコードに加えて実行結果例も単体のファイルに切り出しておくことで、容易にテスト可能になります。
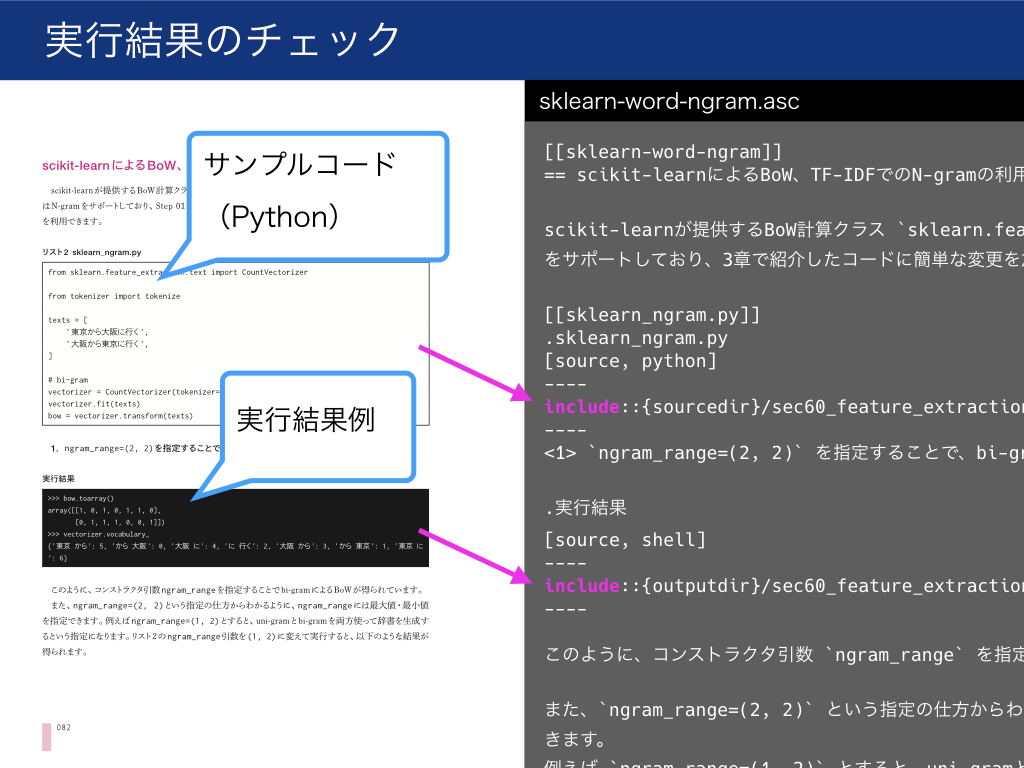
こちらの実行結果テストは、outputに対するassertionを定義しているという点で、一般的なユニットテストに似ていると言えそうです。
通常のソフトウェア開発では、関数の出力を他で使い回すような作りになるため、ユニットテストも自然と関数の出力に対するassertionになります(というかテストしやすく関数化する=TDD)。
しかし、書籍のサンプルコードは「とりあえずパッと写経して結果を確認しやすい」ように書くことも多いため、
”関数化されないベタ書きコードからprintされた結果”を無理矢理テストするように頑張る必要があり、その結果がこの出力結果テストです。
標準出力
あるサンプルコードsample.pyを実行した結果、標準出力にHello worldと出力されたとします。
print('Hello world')
この出力をsample.outputに書いておきます(拡張子は決まっていません。なんでもいいです)。
Hello world
これを、以下のようなbatsファイルでテストします。 check_python_output関数で、スクリプトの実行結果とsample.outputの内容を比較しています。
# !/usr/bin/env bats
setup() {
IFS=""
}
check_python_output() {
SRCFILE=$1
REFOUTPUTFILE=$2
TIMEOUT=${3:-1s}
OUTPUT=`cd $(dirname ${SRCFILE}) && timeout ${TIMEOUT} python ${SRCFILE}` &&:
REFOUTPUT=$(<${REFOUTPUTFILE})
echo '>>> OUTPUT <<<'
echo $OUTPUT
echo '>>> REFOUTPUT <<<'
echo $REFOUTPUT
test "${OUTPUT}" = "${REFOUTPUT}"
}
@test "secX_some_sample_code" {
SRCFILE=${BATS_TEST_DIRNAME}/../src/secX/some_sample.py
REFOUTPUTFILE=${BATS_TEST_DIRNAME}/../docs/outputs/secX/some_sample.output
check_python_output $SRCFILE $REFOUTPUTFILE
}
Python対話環境
本書はサンプルコードにPythonを使いました。
Pythonには対話環境があり、対話環境での実行結果も例として載せています。
幸いPythonにはdoctestというパッケージが標準ライブラリにあり、これがピッタリだったので利用しています。
Python実行環境の出力をそのままsample.pyoutに書いておきます(拡張子は決まっていません。なんでもいいです)
>>> v = 42
>>> print(v)
42
doctestはこれをそのまま読み込んで、対話環境での実行結果として正しいかをテストしてくれます。
例えば↓こんなスクリプトを実行すると、docs/outputs/secX/**/*.pyoutを全てdoctestでテストできます。
また、globs引数を使えば、実行時にグローバル空間に定義されるべきシンボルを渡すこともできます。
例えば↓の例では、docs/outputs/secY/**/*.pyoutは、あらかじめimport numpy as npされていることを前提としていますが、globsにnpを渡すことで、必要な実行時環境を用意できています。
import doctest
import unittest
from pathlib import Path
import numpy as np
BASEPATH = Path().parent.absolute()
testdir_python = BASEPATH / './docs/outputs/secX'
testfiles_python = testdir_python.glob('**/*.pyout')
testsuite_python = doctest.DocFileSuite(*[str(path) for path in testfiles_python],
module_relative=False)
testdir_numpy = BASEPATH / './docs/outputs/secY'
testfiles_numpy = testdir_numpy.glob('**/*.pyout')
testsuite_numpy = doctest.DocFileSuite(*[str(path) for path in testfiles_numpy],
module_relative=False, globs={'np': np}) # numpyが必要な場合
if __name__ == '__main__':
runner = unittest.TextTestRunner()
runner.run(testsuite_python)
runner.run(testsuite_numpy)
ユニットテスト
内部で関数・クラスを定義するようなサンプルコードでは、その粒度で通常のユニットテストを書けます。
必要に応じて書いておきました。
Linter
サンプルコードにはもちろんlinterをかけます。
これは普段のソフトウェア開発と変わりませんが、書籍の場合は特に人目に触れる、お手本となるコードなので、ある意味でより重要と言えるかもしれません。
本書の場合はflake8 + isortでした。
文章に対するテスト
ソースコードに対するテストだけではなく、文章に対しても実行できる自動テストがあります。
Textlint
textlintで文章の問題を自動検出できます。
幸いasciidoc用プラグインもありました。感謝。 textlintでAsciidoc/Asciidoctorをサポートするプラグイン
例えば、以下のような問題を検出します。
- 表記揺れ・誤表記の排除(「識別機」→「識別器」)
- 表記揺れ辞書に基づいて表記揺れを検出するprhというツールがtextlintから使えます。詳しくはこちら: textlint + prhで表記ゆれを検出する
- 冗長な表記の排除(「考えることができる」→「考えられる」)
- 弱い表現の排除(「と思います」)
他にも大量のルールがプラグインとして提供されています。
ビルド生成物に対するチェック
CIで文章をビルドした後、生成物に対して、簡単なブラックリストワードチェックをかけました。
- サンプルコード中の不要なコメントが紛れ込んでいないことをテスト
- linter用の制御コメントや、asciidocのinclude文用の制御コメント(28. Include Directive - 28.6. Select Portions of a Document to Include - 28.6.1. By tagged regionstag)などは、最終出力に含まれてほしくない。
- 不要な制御文字が紛れ込んでいないことをテスト
これらは雑にgrepベタ書きになってしまいましたが、ちゃんと書いても良かったかも。
test-blacklist-word:
box: tuttieee/asciidoctor-cjk
steps:
- script:
name: Assert the compiled file does not contain 'noqa'
code: |
asciidoctor docs/index.asc -o - | grep 'noqa' &&:
test "$?" != "0"
CI
ここまで挙げたテスト・linterは全てCIで実行します。
また、CIでは文書のビルドを行い、プレビューサイトにアップロードします。
同僚・友人にレビューを依頼するときに、プレビューサイトのURLだけ教えればいいので楽です。
私はAmazon S3にファイルを上げ、cloudfront経由で公開しました(cloudfrontでBASIC認証をかける)。
その他Tips
図版(グラフ)
グラフはプログラムで生成し、全て再現可能にしておきます。私はmatplotlibで書きました。
編集段階で見栄え変更の依頼や、高解像度版の出力の依頼などがあるので、再現性がないと死にます。
ちなみに、イラスト的な図版は、本書の場合は私がスケッチを書いたら出版社の方でデザイナーがカッコよく清書してくれるフローだったので、あまり力入れて書かずに済みました。スケッチのスキャン画像やパワポでの下書きなどは全てGitリポジトリに突っ込んで保管しておきました(これは差分管理にはならないので、単なるストレージとしての利用です)。
組版・DTP化の前になるべく修正しておく
出版社によってこの辺のフローは違うと思いますが、私の場合、最後の最後で組版に入ると、マスタがasciidocでなく出版社の手元にあるDTPデータになりました。
すると差分管理が一気にアナログ化します。
こうなると文章の差し替えが辛くなります。
おそらくどうしてもギリギリまで修正は発生してしまいますが、Gitで管理できている間になるべく修正しきることで後の苦しみを減らせると思います。
また、私の場合は索引の作成が組版後だったので、原稿を全て読み返して目grepで重要単語を拾うという地獄を見ました(初出の重要単語は太字化してあったのが不幸中の幸い…)。この辺りも組版前にやれると良かったなと反省です。
あと、ディスプレイで見て気づけなかった間違いも紙で見ると気付けたりするので、Git管理ができている間になるべく紙に印刷してチェックすることをお勧めします。
その他反省点
文章のレビューはGitHubだと不十分
最初は「Gitで原稿管理・GitHubでレビュー!モダン!」とか思ってましたが、GitHubをレビュー・校正に使うのは正直厳しいです。
- 文字単位でコメントできないので誤字の指摘などがしづらい。1行に複数指摘箇所があると、コメントが混ざる。
- PRしないとコメントできない。
- 執筆者が新しく追加した文章(PRとして出す)をレビュアがチェックする、という用途には問題ないですが
- すでにmasterに入っている文章に間違いを見つけた場合、指摘するのが超面倒です。レビュアがIssue立てるかPR出すか。そんな面倒なことレビュアにさせられません。
- 結局、共有google docsに指摘点をまとめてもらう / slackで送りつけてもらう→私があとでまとめて反映する、というフローになりました
後からこんな↓Gitベースのレビューツールを見つけたので、次の執筆機会がもしあれば利用を検討するかもしれません。
penflip
公開用サンプルコードを出力しやすくしておく
出版前にサンプルコードの提供を求められました。
srcに分けて管理していたのは良かったものの、前述した通り、コード中には制御用のコメントやあまり外には出したくない汚い部分もあったりします。
この辺も書いてるうちからちゃんと整理しておけば・出力しやすくしておけばよかったと思います。
まとめ
本稿の内容は結局、「執筆にもコーディング時のテクニックを応用しよう」というものです。
せっかくエンジニアとして文章を書くので、普段やっているCI・自動テストなどのテクニックを執筆にも活用して、質の高い文章を目指したいものです。
(商業誌では)もちろん編集者がチェックしてくれるのですが、
機械的に品質を担保できる部分はこちらで巻き取り、編集者には高レベルなレビューに集中してもらえるとお互いに幸せかと思います。これもチーム開発におけるコードレビューのプラクティスと同じですね。
さいごに

自然言語処理(特に日本語)、機械学習について扱う、ソフトウェアエンジニア向けの入門書です。この分野では初心者のエンジニアが、日本語自然言語処理・機械学習に入門して実用的なレベルで開発できるようになるための解説書です。
キーワード:自然言語処理、日本語、機械学習、深層学習(Deep Learning)
数学的な議論などは極力控えた構成になっています(難解な・高度な手法は扱っていません)が、上記に定めたスコープの内容については、真剣に、比喩で誤魔化すようなことは避けつつ、なるべく平易な解説を心がけたつもりです。
興味のある方はぜひ手に取っていただけると幸いです。
参考情報・類似情報
-
世の中の小説作家と編集者は今すぐ Word や G Suite を窓から投げ捨てて Git と GitHub の使い方を覚えるべきだ
- GitHubを組み込んだ執筆フローについて