はじめに
Amazon Kinesis Data Analyticsでは、Record pre-processingをEnabledにすることで、Lambdaでレコードの事前処理ができます。
- Lambda 関数を使用したデータの事前処理
https://docs.aws.amazon.com/ja_jp/kinesisanalytics/latest/dev/lambda-preprocessing.html
Lambdaのサンプルコードはドキュメントによるとblueprintでテンプレートが用意されているはずなのですが、利用できない状態になっています。
(コンソールからリンクをクリックしても何も出てこない。。)
- 事前処理のための Lambda 関数の作成
https://docs.aws.amazon.com/ja_jp/kinesisanalytics/latest/dev/lambda-preprocessing-functions.html
今回、Lambdaの事前処理についてTwitterのツイートの頻出単語ウインドウ集計をテーマにしてサンプルを作成してみたのでまとめておきます。
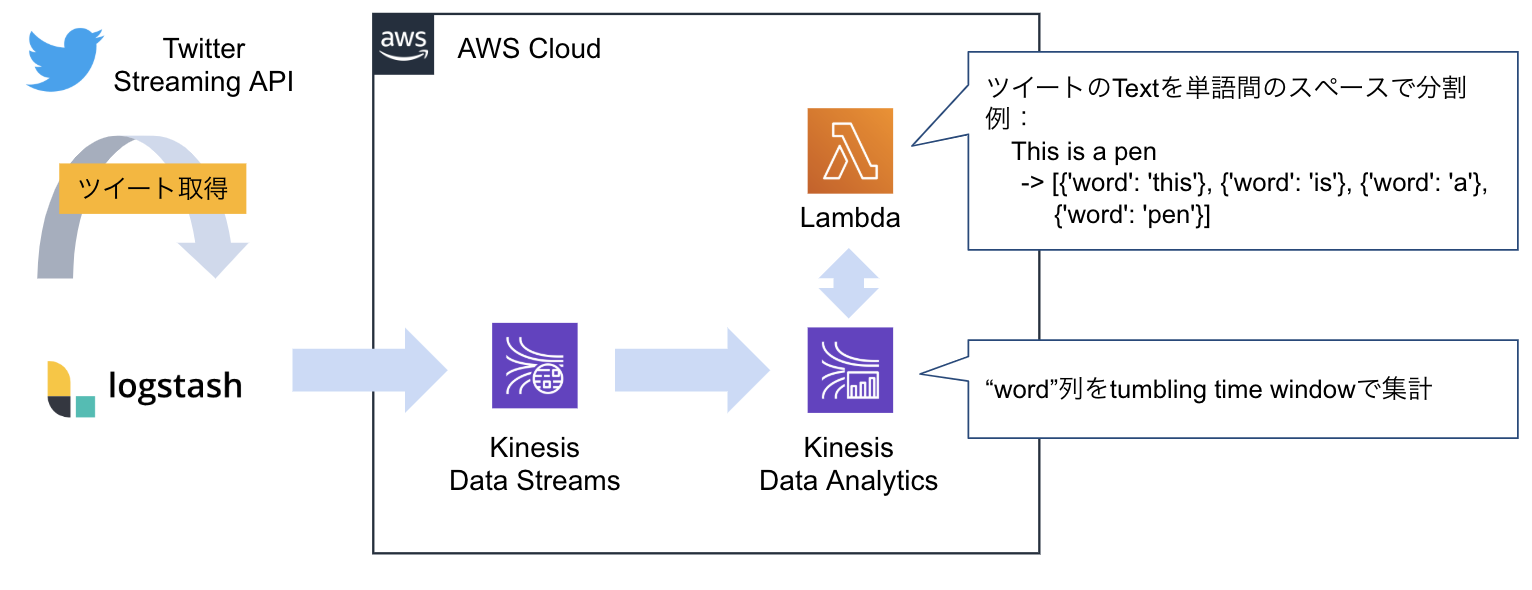
構成
以下の順番で処理をしていきます。
- LogstashでTwitter Streaming APIからツイートを取得。
- LogstashからKinesis Data Streamsにツイートを転送。
- Kinesis Data AnalyticsのData SourceをData Streamsとし、LambdaでRecord pre-processingする
- Lambdaはツイートを単語間のスペースで分割してData Analyticsに返す
- Data Analyticsは単語の出現数をウインドウ集計
Logstash
Logstashのconfファイルのサンプルです。Twitter APIからツイートを取得し、必要なフィールドのみをKinesis Data Streamsにアウトプットします。
input {
twitter {
consumer_key => ""
consumer_secret => ""
oauth_token => ""
oauth_token_secret => ""
languages => ["en"]
full_tweet => true
keywords => ["trump"]
ignore_retweets => true
codec => "json"
}
}
filter {
# "text"と"@timestamp"フィールドのみを残す
ruby {
code => "
wanted_fields = ['text', '@timestamp']
event.to_hash.keys.each { |k|
event.remove(k) unless wanted_fields.include? k
}
"
}
}
output {
kinesis {
stream_name => ""
region => "ap-northeast-1"
access_key => ""
secret_key => ""
}
}
Record pre-processing
Record pre-processingをEnabledにして、対象のLambdaを設定します。
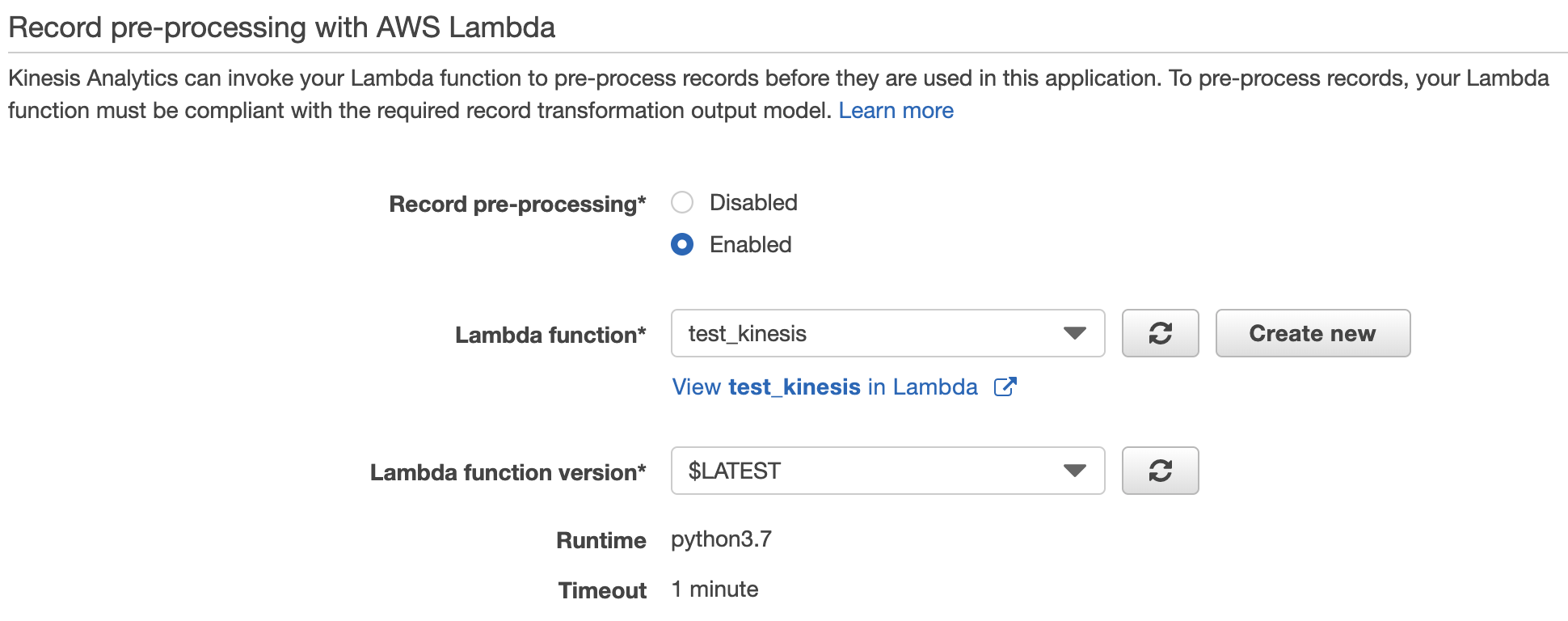
Lambda
Kinesis Streamsからレコードを受け取り、受け取ったレコードのTextを単語間のスペースで分割していきます。
ポイントは以下です。
dataフィールドはbase64エンコードが必要
受け取る時はデコード、アウトプットはエンコードしなければなりません。
また、Kinesisをデータソースとした場合に限った話ではありませんが、Lambdaハンドラーのeventは辞書型に変換が必要です。(以下の記事参照)
- 【Tips】Lambda(Python)でハンドラーのeventを全て辞書型だと思っていたらハマったこと
https://dev.classmethod.jp/cloud/aws/lambda-python-tips-all-events-are-not-dict/
import json
import base64
import logging
import re
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
response = []
for record in event['records']:
wordlist = []
try:
# Base64で送られてきたレコードをデコードする
data = base64.b64decode(record['data']).decode(encoding='utf-8', errors='replace')
# dataを辞書型に変換
data_json = json.loads(data)
logger.info(data_json)
# ツイートの分割
splited_words = re.split(" +", data_json['text'])
for word in splited_words:
wordlist.append({"word" : word})
logger.info(wordlist)
# Base64にエンコード
wordlist_json = json.dumps(wordlist)
wordlist_byte = wordlist_json.encode('utf-8')
wordlist_base64 = base64.b64encode(wordlist_byte)
wordlist_base64_str = wordlist_base64.decode()
# 戻り値のdataの生成
response.append(
{
"recordId" : record['recordId'],
"result" : "Ok",
"data": wordlist_base64_str
}
)
# 処理に失敗した場合の戻り値の生成
except:
response.append(
{
"recordId" : record['recordId'],
"result" : "Dropped"
}
)
return_dict = {
"records": response
}
logger.info(return_dict)
# 戻り値は辞書型(JSONではない点に注意!)
return return_dict
Kinesis Analytics
SQL
"word"フィールドを10秒毎に集計するSQLです。
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (word VARCHAR(32), word_count INTEGER);
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM "word", COUNT(*) AS "word_count"
FROM "SOURCE_SQL_STREAM_001"
GROUP BY "word", FLOOR(("SOURCE_SQL_STREAM_001".ROWTIME - TIMESTAMP '1970-01-01 00:00:00') SECOND / 10 TO SECOND);
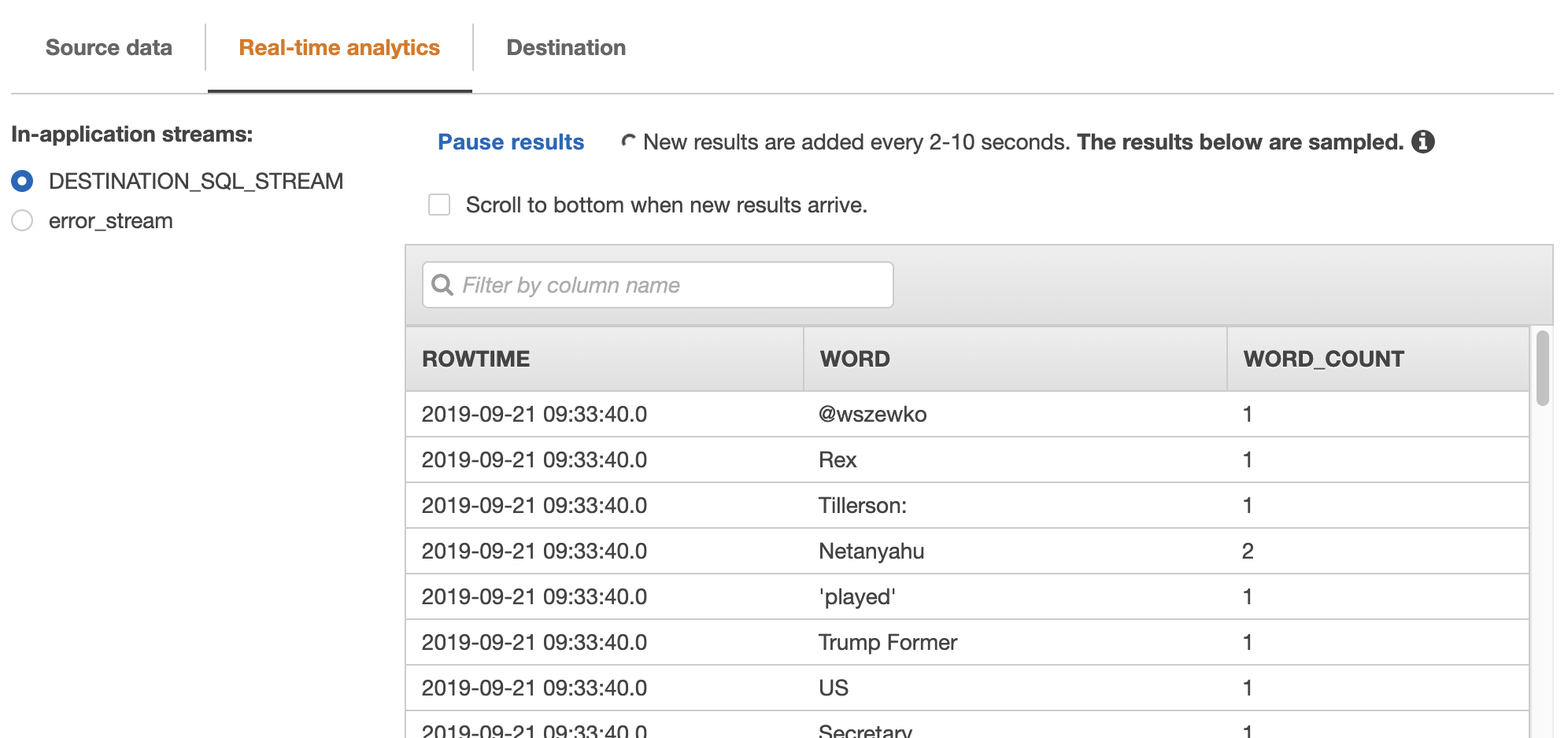
集計結果
集計結果が確認できます。
"WORD_COUNT"列に集計した数が表示されています。
最後に
Lambdaの事前処理を紹介しました。
Base64の処理のところに手こずるかもしれませんが、事前処理がLambdaで手軽にできるのは便利かと思います。
誰かのお役に立てれば幸いです!