目次
1.はじめに
2.自己紹介
3.本テーマに至った経緯
4.モデル制作
5.HTML,CSS制作
1. はじめに
AIプログラミングに興味を持ちスクールで学ぶことにしました。
そこで学んだことの一部をまとめたいと思います。
2. 自己紹介
私はAIプログラマーへの転職を考えておりAidemyさんで学ぶことを決めました。プログラミングをそれほどしたことがなかったのでほぼゼロから学んでみました。
3. 本テーマに至った経緯
ディープラーニングでは音声や画像の認識、自然言語処理などの分野で発展がめざましく、これらの技術は企業のDX、セキュリティー、自動運転、医療など様々な応用の可能性があります。私にとってはどれも魅力的でありいろいろやってみたいのですが、今回は画像処理のセマンティックセグメンテーションについてその手法も探りながら開発してみたいと思います。セグエンテーションの例を示します。

4. モデル製作
a. 開発環境
・pythonバージョン:3
・学習データ:coco detaset
・モデル構築:Google Colaboratory
・HP構築、実行環境:Visual Studio Code
b. U-net
医用画像のセマンティックセグメンテーション向けに提案された畳み込みニューラルネットワーク(CNN)構造をもとに、転置畳み込みやスキップ接続を用いて構築されたものである。CNNは下図に示すように畳み込み層プーリング層からなるユニットを繰り返すことで画像認識において省モデル化と高認識精度化を実現している。

U-netはCNNに転置畳み込みやスキップ接続を追加し「U」の形をした構造となっている
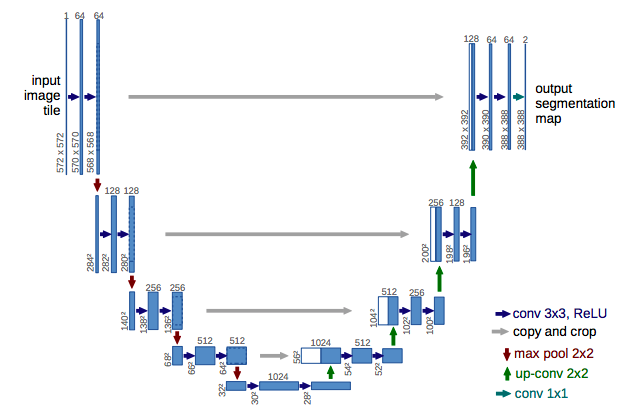
U-netの図中緑の矢印で示されているup-convは転置畳み込みでありpooling層で小さくなった画像サイズを、畳み込みと逆の操作をすることによってアップサンプリングしている。

U-netの図中グレーの矢印で示されているcopy and cropはスキップ接続であり前半で計算した特徴マップを後半ブロックにそのまま受け渡して結合している。前半のブロックでは画像データのどの位置に何があるのかを読み取っていますが、poolingにより画像が小さくなり物体の詳細な形状情報が失われています。後半では画像を元のサイズに戻す作業をしていますが、スキップコネクションで前半部分のより解像度が高いデータを与えることで物体の細かい形状の情報を持たせることができています。
最終出力のチャンネル数は分類したいカテゴリー数に設定します。例えば、道路とそれ以外に分類したければチャンネル数は2であり、チャンネル1は道路、2はその他を表すようにします。各ピクセルにおいて画像とセグメンテーションの正解マスクにより画像中の道路の部分ではチャンネル1がそれ以外では2の値がより大きくなるように学習します。その後予測では各ピクセルで最大値をとっているチャンネルのインデックスを取得し予測セグメンテーション画像として出力します。
c. coco dataset
COCO(Common Object in Context)データセットは、Microsoft社が提供しているアノテーション付き画像のデータセットです。バウンディングボックス、セマンティックセグメンテーション、画像キャプションなど様々な用途に使用できます。私が使用したのはcoco2017であり約4万枚のtest、12万枚のtrain、5000枚のvalidationの画像データとannotationからなっていました。
必要なものを用意しておきます。
from pycocotools.coco import COCO
import numpy as np
import skimage.io as io
import random
import os
import pandas as pd
import cv2
import imageio
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import tensorflow as tf
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import concatenate
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
%matplotlib inline
以下のコードを実行しますと画像は90カテゴリーあることがわかります。
annFile='instances_train2017.jsonのパス'
coco=COCO(annFile)
catIDs = coco.getCatIds()
cats = coco.loadCats(catIDs)
print(cats)
loading annotations into memory...
Done (t=17.87s)
creating index...
index created!
[{'supercategory': 'person', 'id': 1, 'name': 'person'}, {'supercategory': 'vehicle', 'id': 2, 'name': 'bicycle'}, {'supercategory': 'vehicle', 'id': 3, 'name': 'car'}, .......... {'supercategory': 'indoor', 'id': 90, 'name': 'toothbrush'}]
このデータセットでは選択したカテゴリーでフィルタリングをし該当する画像とセグメンテーション用のマスクを抽出できます。マスクはannotationフォルダの中にあるjsonファイルから生成されるようです。
filterClasses = ['cat','car']
catIds = coco.getCatIds(catNms=filterClasses)
imgIds = coco.getImgIds(catIds=catIds)
print("Number of images containing all the classes:", len(imgIds))
img = coco.loadImgs(imgIds[np.random.randint(0,len(imgIds))])[0]
print(img['file_name'])
I = io.imread('/content/train2017/{}'.format(img['file_name']))/255.0
plt.axis('off')
plt.imshow(I)
plt.show()
Number of images containing all the classes: 164
000000368371.jpg

マスクをかけます。
plt.imshow(I)
plt.axis('off')
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns)

猫と車の場合trainデータは16201枚あることがわかります。
classes = ['cat','car']
images = []
if classes!=None:
# iterate for each individual class in the list
for className in classes:
catIds = coco.getCatIds(catNms=className)
imgIds = coco.getImgIds(catIds=catIds)
images += coco.loadImgs(imgIds)
else:
imgIds = coco.getImgIds()
images = coco.loadImgs(imgIds)
unique_images = []
for i in range(len(images)):
if images[i] not in unique_images:
unique_images.append(images[i])
dataset_size = len(unique_images)
print("Number of images containing the filter classes:", dataset_size)
Number of images containing the filter classes: 16201
学習で使用するマスクはこのようになります。
filterClasses = ['cat','car']
mask = np.zeros((img['height'],img['width']))
for i in range(len(anns)):
className = getClassName(anns[i]['category_id'], cats)
pixel_value = filterClasses.index(className)+1
mask = np.maximum(coco.annToMask(anns[i])*pixel_value, mask)
plt.imshow(mask)

200行当たりに注目すると左から車、猫、車、背景の順となっていて200行のピクセルの値を出力すると
mask[200]
array([0., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2.,2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1. ,1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
ピクセルの値は背景が0、猫が1、車が2であることがわかります。
学習用データを生成するための関数を定義していきます。
def filterDataset(classes=None, mode='train'):
annFile='instances_train2017.jsonのパス'
coco = COCO(annFile)
images = []
if classes!=None:
for className in classes:
catIds = coco.getCatIds(catNms=className)
imgIds = coco.getImgIds(catIds=catIds)
images += coco.loadImgs(imgIds)
else:
imgIds = coco.getImgIds()
images = coco.loadImgs(imgIds)
unique_images = []
for i in range(len(images)):
if images[i] not in unique_images:
unique_images.append(images[i])
random.shuffle(unique_images)
dataset_size = len(unique_images)
return unique_images, dataset_size, coco
images, dataset_size, coco = filterDataset(classes = ['cat','car'], mode='train')
def getClassName(classID, cats):
for i in range(len(cats)):
if cats[i]['id']==classID:
return cats[i]['name']
return None
def getImage(imageObj, img_folder, input_image_size):
train_img = io.imread('/content/train2017' + '/' + imageObj['file_name'])/255.0
train_img = cv2.resize(train_img, input_image_size)
if (len(train_img.shape)==3 and train_img.shape[2]==3): # If it is a RGB 3 channel image
return train_img
else:
stacked_img = np.stack((train_img,)*3, axis=-1)
return stacked_img
def getNormalMask(imageObj, classes, coco, catIds, input_image_size):
annIds = coco.getAnnIds(imageObj['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
cats = coco.loadCats(catIds)
train_mask = np.zeros(input_image_size)
for a in range(len(anns)):
className = getClassName(anns[a]['category_id'], cats)
pixel_value = classes.index(className)+1
new_mask = cv2.resize(coco.annToMask(anns[a])*pixel_value, input_image_size)
train_mask = np.maximum(new_mask, train_mask)
train_mask = train_mask.reshape(input_image_size[0], input_image_size[1], 1)
return train_mask
def getBinaryMask(imageObj, coco, catIds, input_image_size):
annIds = coco.getAnnIds(imageObj['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
train_mask = np.zeros(input_image_size)
for a in range(len(anns)):
new_mask = cv2.resize(coco.annToMask(anns[a]), input_image_size)
new_mask[new_mask >= 0.5] = 1
new_mask[new_mask < 0.5] = 0
train_mask = np.maximum(new_mask, train_mask)
train_mask = train_mask.reshape(input_image_size[0], input_image_size[1], 1)
return train_mask
def dataGeneratorCoco(images, classes, coco,
input_image_size=(224,224), batch_size=4, mask_type='normal'):
#img_folder = '{}/images/{}'.format(folder, mode)
img_folder = '/content/sample_data/val2017'
dataset_size = len(images)
catIds = coco.getCatIds(catNms=classes)
random.shuffle(images)
c = 0
while(True):
img = np.zeros((batch_size, input_image_size[0], input_image_size[1], 3)).astype('float')
mask = np.zeros((batch_size, input_image_size[0], input_image_size[1], 1)).astype('float')
for i in range(c, c+batch_size): #initially from 0 to batch_size, when c = 0
imageObj = images[i]
### Retrieve Image ###
train_img = getImage(imageObj, img_folder, input_image_size)
### Create Mask ###
if mask_type=="binary":
train_mask = getBinaryMask(imageObj, coco, catIds, input_image_size)
elif mask_type=="normal":
train_mask = getNormalMask(imageObj, classes, coco, catIds, input_image_size)
img[i-c] = train_img
mask[i-c] = train_mask
c+=batch_size
if(c + batch_size >= dataset_size):
c=0
random.shuffle(images)
yield img, mask
学習データのジェネレーターを作ります。バッチサイズを64、インプットサイズを224×224、マスクタイプは選んだカテゴリーひとまとめとそれ以外に分ける場合はbinary、そうでない場合はnormalで今回はnormalです。
batch_size = 64
input_image_size = (224,224)
mask_type = 'normal'
train_gen = dataGeneratorCoco(images, classes, coco,
input_image_size, batch_size, mask_type)
d. モデルの構築
u-net前半部分の畳み込み、ドロップアウト、Maxpooling、スキップコネクションをconv_block関数として定義します。畳み込みのフィルター数、ドロップアウト率、Maxpoolingを行うかどうかそれぞれ選択できます。今回は畳み込みのフィルター数を32、活性化関数をRelu,パディングをsame、カーネルの初期化をHeNormalに設定しました。この畳み込みを2回行った後、ドロップアウトをしMaxpoolingを行います。そしてMaxpooling後の値と前の値(スキップコネクション用)を返しています。この流れを5回繰り返すので1回分をconv_blockとしてまとめています。
def conv_block(inputs=None, n_filters=32, dropout_prob=0.0, max_pooling=True):
conv = Conv2D(n_filters, # Number of filters
3, # Kernel size
activation='relu',
padding='same',
kernel_initializer='HeNormal')(inputs)
conv = Conv2D(n_filters,
3,
activation='relu',
padding ='same',
kernel_initializer='HeNormal')(conv)
if dropout_prob > 0:
conv = Dropout(rate = dropout_prob)(conv)
if max_pooling:
next_layer = MaxPooling2D(2,2)(conv)
else:
next_layer = conv
skip_connection = conv
return next_layer, skip_connection
u-net後半部分のトランスポーズ畳み込み、スキップコネクション、畳み込みをupsampling_block関数として定義します。
def upsampling_block(expansive_input, contractive_input, n_filters=32):
up = Conv2DTranspose(
n_filters, # number of filters
3, # Kernel size
strides=2,
padding='same')(expansive_input)
# Merge the previous output and the contractive_input
merge = concatenate([up, contractive_input], axis=3)
conv = Conv2D(n_filters,
3,
activation='relu',
padding='same',
kernel_initializer='HeNormal')(merge)
conv = Conv2D(n_filters,
3,
activation='relu',
padding='same',
kernel_initializer='HeNormal')(conv)
return conv
conv_blockとupsampling_blockを組み合わせてU-netを構築する関数を定義します。
def unet_model(input_size=(224, 224, 3), n_filters=32, n_classes=3):
inputs = Input(input_size)
cblock1 = conv_block(inputs, n_filters)
cblock2 = conv_block(cblock1[0], n_filters*2)
cblock3 = conv_block(cblock2[0], n_filters*4)
cblock4 = conv_block(cblock3[0], n_filters*8, dropout_prob=0.3)the max_pooling layer
cblock5 = conv_block(cblock4[0], n_filters*16, dropout_prob=0.3, max_pooling=False)
ublock6 = upsampling_block(cblock5[0], cblock4[1], n_filters*8)
ublock7 = upsampling_block(ublock6, cblock3[1], n_filters*4)
ublock8 = upsampling_block(ublock7, cblock2[1], n_filters*2)
ublock9 = upsampling_block(ublock8, cblock1[1], n_filters)
conv9 = Conv2D(n_filters,
3,
activation='relu',
padding='same',
kernel_initializer='he_normal')(ublock9)
conv10 = Conv2D(n_classes, 1, padding='same',activation='softmax')(conv9)
model = tf.keras.Model(inputs=inputs, outputs=conv10)
return model
U-netモデルを作ります。背景、猫、車を分類するのでチャンネル数は3です。
img_height = 224
img_width = 224
num_channels = 3
unet = unet_model((img_height, img_width, num_channels))
モデルの形状を確認します。
unet.summary()
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 224, 224, 3 0 []
)]
conv2d_20 (Conv2D) (None, 224, 224, 32 896 ['input_2[0][0]']
)
conv2d_21 (Conv2D) (None, 224, 224, 32 9248 ['conv2d_20[0][0]']
)
max_pooling2d_4 (MaxPooling2D) (None, 112, 112, 32 0 ['conv2d_21[0][0]']
)
conv2d_22 (Conv2D) (None, 112, 112, 64 18496 ['max_pooling2d_4[0][0]']
)
conv2d_23 (Conv2D) (None, 112, 112, 64 36928 ['conv2d_22[0][0]']
)
max_pooling2d_5 (MaxPooling2D) (None, 56, 56, 64) 0 ['conv2d_23[0][0]']
conv2d_24 (Conv2D) (None, 56, 56, 128) 73856 ['max_pooling2d_5[0][0]']
conv2d_25 (Conv2D) (None, 56, 56, 128) 147584 ['conv2d_24[0][0]']
max_pooling2d_6 (MaxPooling2D) (None, 28, 28, 128) 0 ['conv2d_25[0][0]']
conv2d_26 (Conv2D) (None, 28, 28, 256) 295168 ['max_pooling2d_6[0][0]']
conv2d_27 (Conv2D) (None, 28, 28, 256) 590080 ['conv2d_26[0][0]']
dropout_2 (Dropout) (None, 28, 28, 256) 0 ['conv2d_27[0][0]']
max_pooling2d_7 (MaxPooling2D) (None, 14, 14, 256) 0 ['dropout_2[0][0]']
conv2d_28 (Conv2D) (None, 14, 14, 512) 1180160 ['max_pooling2d_7[0][0]']
conv2d_29 (Conv2D) (None, 14, 14, 512) 2359808 ['conv2d_28[0][0]']
dropout_3 (Dropout) (None, 14, 14, 512) 0 ['conv2d_29[0][0]']
conv2d_transpose_4 (Conv2DTran (None, 28, 28, 256) 1179904 ['dropout_3[0][0]']
spose)
concatenate_4 (Concatenate) (None, 28, 28, 512) 0 ['conv2d_transpose_4[0][0]',
'dropout_2[0][0]']
conv2d_30 (Conv2D) (None, 28, 28, 256) 1179904 ['concatenate_4[0][0]']
conv2d_31 (Conv2D) (None, 28, 28, 256) 590080 ['conv2d_30[0][0]']
conv2d_transpose_5 (Conv2DTran (None, 56, 56, 128) 295040 ['conv2d_31[0][0]']
spose)
concatenate_5 (Concatenate) (None, 56, 56, 256) 0 ['conv2d_transpose_5[0][0]',
'conv2d_25[0][0]']
conv2d_32 (Conv2D) (None, 56, 56, 128) 295040 ['concatenate_5[0][0]']
conv2d_33 (Conv2D) (None, 56, 56, 128) 147584 ['conv2d_32[0][0]']
conv2d_transpose_6 (Conv2DTran (None, 112, 112, 64 73792 ['conv2d_33[0][0]']
spose) )
concatenate_6 (Concatenate) (None, 112, 112, 12 0 ['conv2d_transpose_6[0][0]',
8) 'conv2d_23[0][0]']
conv2d_34 (Conv2D) (None, 112, 112, 64 73792 ['concatenate_6[0][0]']
)
conv2d_35 (Conv2D) (None, 112, 112, 64 36928 ['conv2d_34[0][0]']
)
conv2d_transpose_7 (Conv2DTran (None, 224, 224, 32 18464 ['conv2d_35[0][0]']
spose) )
concatenate_7 (Concatenate) (None, 224, 224, 64 0 ['conv2d_transpose_7[0][0]',
) 'conv2d_21[0][0]']
conv2d_36 (Conv2D) (None, 224, 224, 32 18464 ['concatenate_7[0][0]']
)
conv2d_37 (Conv2D) (None, 224, 224, 32 9248 ['conv2d_36[0][0]']
)
conv2d_38 (Conv2D) (None, 224, 224, 32 9248 ['conv2d_37[0][0]']
)
conv2d_39 (Conv2D) (None, 224, 224, 3) 99 ['conv2d_38[0][0]']
==================================================================================================
Total params: 8,639,811
Trainable params: 8,639,811
Non-trainable params: 0
モデルをコンパイルします。
unet.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
重みをロードします。今回の開発環境はGoogle Colaboratoryなので長時間学習することができません。ですから、学習時間を分割して実行します。学習後はモデルを保存し次の学習の前にロードします。
unet.load_weights('保存したモデルのパス')
モデルを学習させます。
history = unet.fit(x = train_gen,
steps_per_epoch =254,
epochs = 20,
verbose = True)
Google colaboratolyでモデルを保存する場合
from google.colab import files
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
unet.save(os.path.join(result_dir, 'unet.h5'))
files.download( '/content/results/unet.h5' )
e. 結果の出力
学習には1エポックあたりやく5分かかります。今回は200エポック学習させたので13時間ほどかかりました。予測を出力してみます。
I = cv2.imread(filepath)/255.0
input_mask = tf.image.resize(I, (224, 224), method='nearest')
input_mask = tf.expand_dims(input_mask,axis = 0,)
pred_mask = unet.predict(input_mask)
def create_mask(pred_mask):
g = list(range(224))
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def display(display_list):
plt.figure(figsize=(10, 10))
title = [ 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.preprocessing.image.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
display([create_mask(pred_mask)])


学習用画像ではそこそこうまくいっているようです。
学習に使用していない画像ではどうでしょうか。


猫はなんとなく認識できていますが、車はまだまだのようです。
5. HTML,CSS制作
アプリの外観は以下のようになります。シンプルに作ったので特徴はありません。今後はスマートフォンで使いやすかったり、動きのあるようなサイトを作れるようにしたいと思います。

Semantic Segmentation
6. 反省・課題
自分でモデルを作り実行させると様々な問題が出ました。まずcoco datasetの扱いが思っていたよりも難しくなかなかマスクデータを取り出せませんでした。27GBのデータの扱いも不慣れで失敗をしました。今回は13時間ほど学習させましたが精度はあまり良くならなかったなと思います。今後の課題としては、より大きなデータセットを使用したりU-netに限らず様々なモデルで検討し精度向上を目指したいと思います。
7. 後書き
ここまで読んでいただきありがとうございいました。上手くいかなかったことがありますがディープラーニングの技術は非常に強力で魅力的だと感じました。今後様々なタスクにおいて精度向上に挑戦していきたいです。