LLMを使ったアプリ開発での課題
LangChain入門3ヶ月目のtubone24です。よろしくお願いします。
皆さん、LangChainとLLMを使ったアプリケーション作ってますか?
LLMを使ったアプリケーションを開発しているとしばしばLLMのトークン使用料に悩まされて月末の請求に震え上がる日々を過ごすことがあるかと思います。
プロンプトを調整したり、LLMの出力を調整するだけでなく、ちょっとUIを直したり、LLMに関係ない機能を追加するときにも実装中・テストなどでたくさんLLMを叩いたりすることでしょう。
すると....
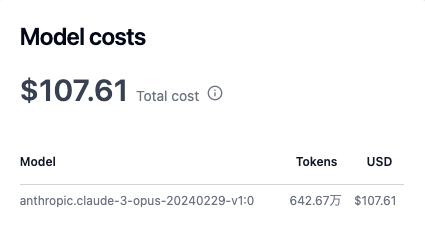
「ぎゃーーーーーー!」
大変なことになってしまいます。LLM怖い。
また、コストだけでなく、一回あたりの実行時間もかかってしまうので、開発のイテレーションが上がらず、生産性爆下がりでこれまた困ってしまいます。
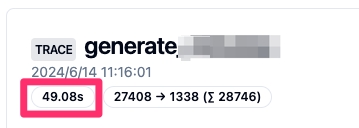
「うーん!命短し恋せよ乙女なのに、1分近くも待てないよぉー!」
この課題を解決するべく、FakeLLMを使っていきましょう、というのが今回の記事のお話です。
FakeLLMとは
FakeLLMとは、その名の通り、LLMの出力を模擬した偽物のLLMのことです。
テストコードを書いたことがある人なら、LLMのMockという表現がしっくりくるかと思います。
実はFakeLLM自体は、LangChainが提供してるもの(FakeListLLM)もあるので、多くの場合はこちらで十分だと思います。
使い方は簡単で、今LLM Modelとして定義してる箇所をそっくりFakeLLMに置き換えてしまえばOKです。
from langchain.llms.fake import FakeListLLM
responses=[
"あのイーハトーヴォのすきとおった風",
"夏でも底に冷たさをもつ青いそら",
"うつくしい森で飾られたモリーオ市"
"郊外のぎらぎらひかる草の波"
]
llm = FakeListLLM(responses=responses)
chain = prompt | llm
response = chain.invoke({"input": "ポラーノの広場を朗読して"})
print(response.content)
> あのイーハトーヴォのすきとおった風
response = chain.invoke({"input": "続きを朗読して"})
print(response.content)
> 夏でも底に冷たさをもつ青いそら
とっても簡単ですね。
Callbacks(Streaming)と絡めたときの扱いにくさ
ここまでとても便利なツールとしてLangChain提供のFakeListLLMを紹介しましたが、残念ながら実用するにはあと少し足りないのです。
それは、Streaming処理をCallbackで対応してるアプリケーションだとStreaming処理が全く再現できないということです。
ChainやAgentを組んでるとき、invokeメソッドを実行してresponseを取るかと思うのですが、特にStreamlitなどを使う場合や、主処理とは別でLLMのStreamingを記録する場合など、Streamingの生成テキストはresponseとは別にCallbackで扱うことが多いと思います。
例として次のような実装があるとしましょう。
from typing import Text
from langchain.callbacks.base import BaseCallbackHandler
from langchain_community.chat_models import BedrockChat
import streamlit as st
# Streamlitのcontainerを受け取り、受け取ったcontainerに生成テキストを書き出す
class StreamHandler(BaseCallbackHandler):
def __init__(self, container: st.container, init_text: Text = ""):
self.init_text = init_text
self.container = container
def on_llm_new_token(self, token: Text, **kwargs) -> None:
st.session_state.text += token
self.container.markdown(st.session_state.text)
container = st.container()
stream_handler = StreamHandler(container)
model = BedrockChat(
model_id="anthropic.claude-3-opus-20240229-v1:0",
region_name="us-west-2",
streaming=True,
callbacks=[stream_handler],
model_kwargs={"max_tokens": 4096},
)
model.invoke({"input": "あのイーハトーヴォのすきとおった風の続きを出して"})
Bedrock Chat(LLM)からStreamlingで生成テキストができるたびに、StreamHandlerのon_llm_new_tokenが呼び出されるため、st.containerにテキストが記録されていきます。Streamlitを用いた実装でよくある方式だと思います。

(Claude3 Opusのガードレールが優秀で、例の文章をそのまま出力しませんね...。)
これをFakeListLLMに置き換えてしまうと、Fake LLMからon_llm_new_tokenが呼び出されないので、Streamlingが一切動きません。
これだと、生成されたテキストがStreamingしながら表示されるようなLLMアプリケーション特有の動きが確認できないので不便極まりないです。
LangChainのLLM ModelはBaseModelがある
ちょっと脱線しますが、LangChainのChatModel(例えばBedrockChat)はBaseChatModelを継承して作られてます。
これにより、様々なモデル間の違いをうまく吸収し、共通のメソッドを実行することで出力を得ることができるので、実装が容易になってるのですがこれはFakeLLMにも活かせます。
CallbackでStreaming処理ができるように改造したFakeLLMを作ってあげることで対処できそうです。
ということで作ってみた
全体の実装は下記のGistを見ていただければと思いますが、次のようにBaseChatModelを継承してFakeLLMを作ります。
_streamがstreamingの処理を定義したメソッドなのですが、Callbackで渡されるCallbackManagerForLLMRunに対して直接on_llm_new_tokenを呼んであげるだけです。
一応、それっぽく、sleepを入れたりテキストをchankに分割して出力したりする処理も入れてます。
このあたりは、いくつかLangChainのModelソースコードを見てみるとヒントが散りばめられてます。
from langchain_core.language_models import BaseChatModel
from typing import List, Dict, Optional, Any, Iterator
from collections import defaultdict
from langchain_core.callbacks import (
CallbackManagerForLLMRun,
)
from langchain_core.messages import (
AIMessage,
AIMessageChunk,
BaseMessage,
)
from langchain_core.outputs import ChatGeneration, ChatGenerationChunk, ChatResult
from time import sleep
class FakeListChatModelWithStreaming(BaseChatModel):
model_id: str = "fake-chat-model-with-streaming"
streaming: bool = True
responses: List[str] = []
sleep_time: int = 0
(中略)
def _stream(
self,
messages: List[BaseMessage],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> Iterator[ChatGenerationChunk]:
for response in self.responses:
for chunk in [char for char in response]:
sleep(self.sleep_time)
run_manager.on_llm_new_token(chunk)
delta = response
yield ChatGenerationChunk(message=AIMessageChunk(content=delta))
model = FakeListChatModelWithStreaming(
sleap_time=0.01,
callbacks=[stream_handler],
responses=["あのイーハトーヴォのすきとおった風〜(省略)"]
streaming=True)
model.invoke({"input": "あのイーハトーヴォのすきとおった風の続きを出して"})

うまくいきましたね!
結論
Fake LLMを使いたい際、StreamingをCallbackを実装しているとうまくいかない問題がありましたが、LangChainの実装に従って新しいLLM Classを作ることで解決できます。
LangChainのコードはPythonを書いたことがある人なら、比較的読みやすいコードになっていると思いますので、ドキュメントに載ってないようなニッチなことも実装できる気がします。
Let's LangChain!