はじめに
エアークローゼットのエンジニアアインです。
この記事はエアークローゼット Advent Calendar 2023 17日目の記事になります。
Terraformとは?
Terraformは、コードを使用してインフラリソースを作成および管理できるInfrastructure as Code(IaC)ツールです。
Terraformには把握すべきいくつかの基本的な概念があります。
- Terraform state
- Terraform resource
- Terraform variable
- Terraform data source
次に上記の概念をざっくり説明させて頂きます。
Terraform state
これは、Terraformがメタデータを追跡し、実際のインフラリソースと現在のterraformソースの間の参照を提供するツールとして利用されます。
以下の画像と同じイメージとなります。
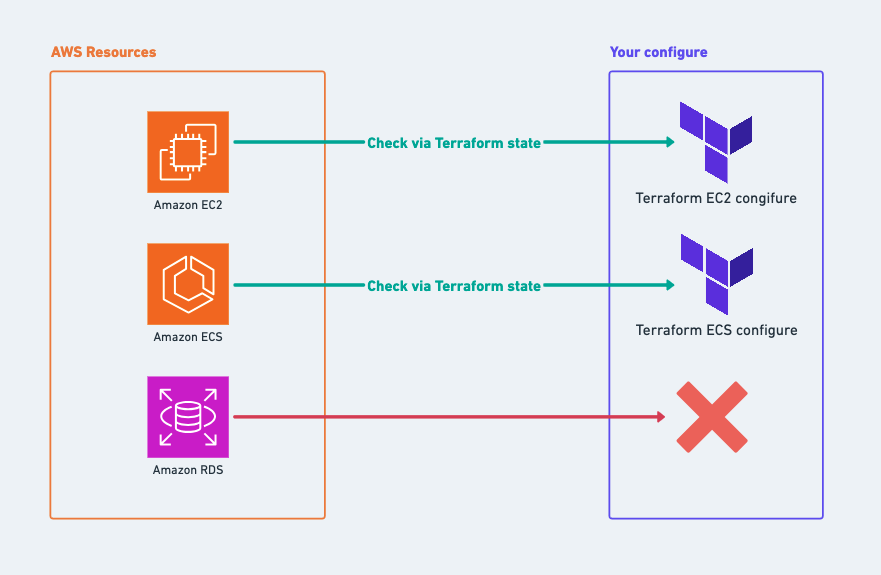
画像1
Terraform stateは単独での作業だけでなく、チームでの作業時に特に強力です。単純に言えば、Terraform stateを基に、チームのメンバーは以下を理解できる:
- 自分のローカルのTerraformソースは実際のインフラリソースとどのように「異なる」のか。
- 自分のローカルのTerraformソースは実際のインフラリソースとどのように「CONFLICT」のか。
Terraform stateはJSON形式でterraform.tfstateファイルとしてに保存されます。ただし、これをクラウド環境に保存し、ちゃんと暗号化するべきです。
Terraform resource
ResourceはTerraformの基本要素であり、各リソースブロックは仮想ネットワーク(Virtual-network)、コンピュートインスタンス(Compute-instances)などの一つまたは複数のインフラストラクチャオブジェクトを記述します。
resource "aws_vpc" "main" {
cidr_block = var.vpc_cidr
enable_dns_hostnames = true
enable_dns_support = true
tags = {
Name = "${var.app_name}-vpc"
}
}
上記の例では、名前が "main" であるaws_vpcを持っています。この中には、次のような情報が含まれてる:
- cidr_block
- tags
- dns_hostnames
- ...
各リソースはそれぞれのアウトプットを持っており(これは各リソースのpublicプロパティと認められます)。
aws_ec2インスタンスリソースが作成されると、次のような基本的なpublicプロパティがあります:
- arn
- public_ip
詳しくはここのリンクを参考してみてください: https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/instance#attribute-reference
Terraform variable
他のプログラミング言語と同様に、Terraformも変数に独自の定義を持っています。
Terraformには2つの基本的な変数のタイプがあります:
- Input変数
- Local変数
Input変数は、次の形式で定義されます。
variable app_name {
type = string
}
variable キーワードを利用して変数のtypeも特定します。
これらの変数は、あるモジュールの「引数」として認められます。
例:
// Module A
variable app_name {
type = string
}
上記のコードでは、モジュールAを定義していて、このモジュールは 「app_name」という「引数」を必要とします。別のモジュールがこのモジュールAを使用する場合、以下のように実施しないといけません。
module "A" {
source = "./module_A"
app_name = "Sample App"
}
Local変数は、以下のような形式で定義されます:
locals {
test_variable = "test"
}
これらのLocal変数は、それが定義されたモジュールの内部でのみ有効です。
Terraform data source
Terraform data sourceは、Terraformによって定義されていないリソースを使用できるようにするものであり、例えば、システム内の既存のインフラストラクチャリソースへの参照などが挙げられます。
個人の経験から言えば、Terraform data sourceは特に以前は「手動」でインフラストラクチャのセットアップが行われていたシステムに対して非常に便利だと感じています。
Terraform data sourceを使用すると、これらの「legacy resources」への参照が可能になります。
例:
data "aws_ami" "example" {
most_recent = true
owners = ["self"]
tags = {
Name = "app-server"
Tested = "true"
}
}
上記のコードは既存にあるaws_amiに参考します。
マイクロサービスシステムのインフラストラクチャアーキテクチャ
今回は、3つのマイクロサービス(A、B、C)を展開します。それぞれのマイクロサービスに対して、基本的なアーキテクチャに基づいて実行します。
ネットワークアーキテクチャ(VPC、パブリックサブネット、プライベートサブネット)
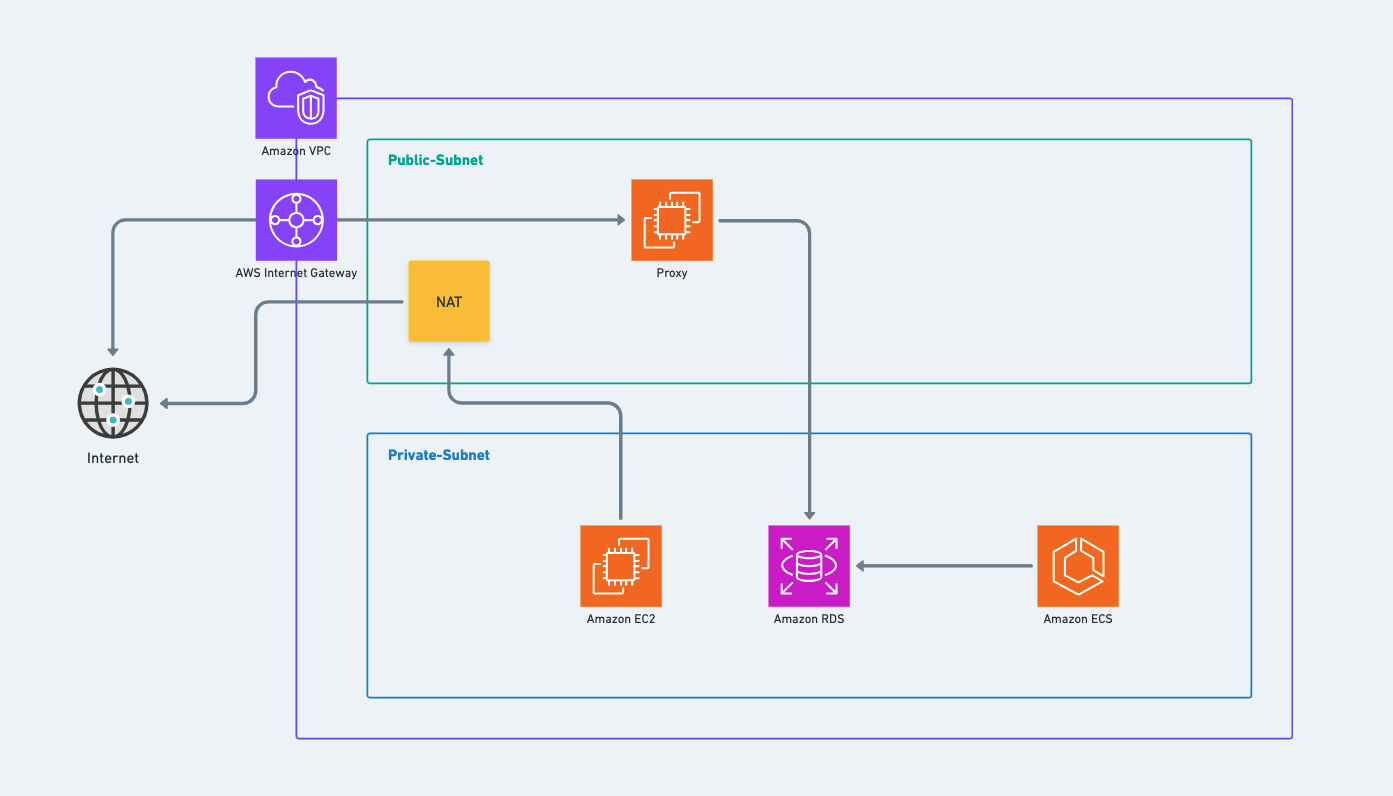
画像 2
図の各構成要素を分析します。ここでは、各サービスに対して別々のVPCを作成します。
VPCには、当然ながらpublic_subnetとprivate_subnetが欠かせません。そして、private_subnet内のリソースが外部のインターネットにアクセスできるようにするために、nat_gatewayを設定し、それをpublic_subnet内に配置します。
データベース(ここではAWS RDS)はprivate_subnet内に配置され、ただし、次の2つの入力のみを受け入れます:
- VPCの内部。
- Proxy (外部のインターネットから来れば)。
サービスのサーバーコードを実行するAWS ECSはprivate_subnet内に配置されます。
アプリケーションアーキテクチャ(ECS、ロードバランサー)
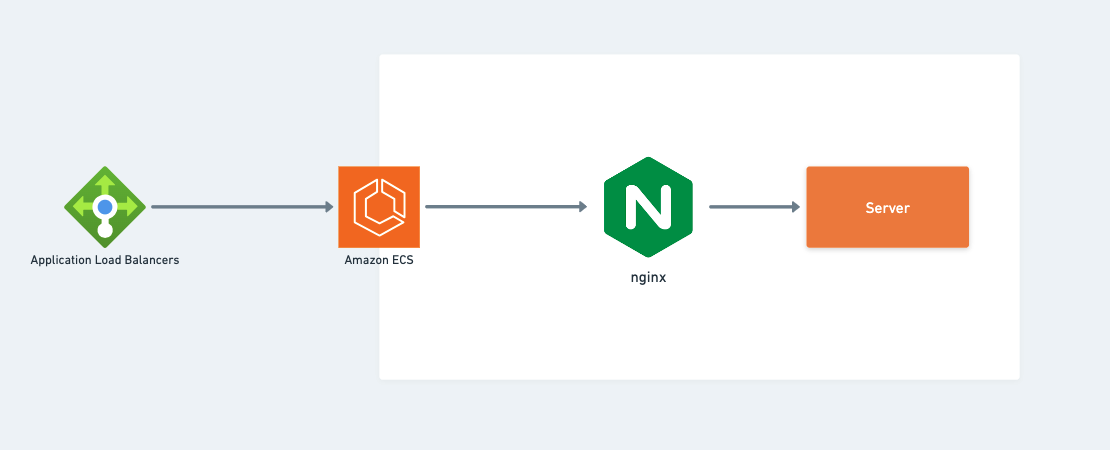
画像 3
ここでは、ECSの前にApplication Load Balancerを配置し、ECS内部ではnginx load balancerを配置して、ECSサービス内で実行されるサーバーコードを保護するリバースプロキシとしての役割を果たします。
コードを参照する
フルソースコードは下記のリンクまで参考してみてください。
https://github.com/tuananhhedspibk/NewAnigram-Infrastructure
Folder構築
モジュール単位で各リソースを管理します。
- network: vpc, public_subnet, private_subnet
- ecs_api: ecs_task_definition, ecs_service
- ecs_cluster: cluster
- proxy: database proxy
- rds: database
一番外側は、以下のようなmain.tfファイルになります:
module "network" {
source = "./network"
// ...
}
module "proxy" {
source = "./proxy"
// ...
}
module "rds" {
source = "./rds"
// ...
}
module "ecs_cluster" {
source = "./ecs_cluster"
// ...
}
module "ecs_api" {
source = "./ecs_api"
// ...
}
Network Module
このモジュールでは、次のものを定義します:
- vpc
- public_subnet
- private_subnet
- nat_gateway
vpcは
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
enable_dns_hostnames = true
enable_dns_support = true
tags = {
Name = "${var.app_name}-vpc"
}
}
vpcを定義する際に最も重要なのは、それにcidr_blockを指定することです。cidr_blockはVPCのネットワークアドレス(仮想アドレス)と認められます。
public_subnetは以下のようになります:
resource "aws_subnet" "public" {
vpc_id = aws_vpc.main.id // id của vpc resource
count = length(var.public_subnets_cidr) // public_subnetの数
cidr_block = element(var.public_subnets_cidr, count.index) // cidr_block設定 - サブネットのネットワークアドレスつまりサブネット分けること
availability_zone = element(var.availability_zones, count.index)
map_public_ip_on_launch = true
tags = {
Name = "${var.app_name}-public-subnet-${element(var.availability_zones, count.index)}"
}
}
public_subnetはパブリックなサブネットであり、つまりグローバルなインターネットから見ることができるものです。したがって、map_public_ip_on_launch属性をtrueに設定して、このサブネットにパブリックIPアドレスがあるようにし、グローバルなインターネットから見えるようにします。
private_subnetは
resource "aws_subnet" "public" {
vpc_id = aws_vpc.main.id // id của vpc resource
count = length(var.private_subnets_cidr) // private_subnetの数
cidr_block = element(var.private_subnets_cidr, count.index) // cidr_block設定 - サブネットのネットワークアドレスつまりサブネット分けること
availability_zone = element(var.availability_zones, count.index)
map_public_ip_on_launch = false
tags = {
Name = "${var.app_name}-public-subnet-${element(var.availability_zones, count.index)}"
}
}
private_subnetはプライベートであり、つまり外部のインターネットから見えないものとなり、map_public_ip_on_launch属性falseに設定してプライベートサブネットはpublic_ipアドレスをアサインされないはずです。
nat_gatewayに対しては
// NATにアサインするElasticIp定義
resource "aws_eip" "nat" {
vpc = true
depends_on = [aws_internet_gateway.main]
}
// NAT gateway
resource "aws_nat_gateway" "main" {
allocation_id = aws_eip.nat.id
subnet_id = element(aws_subnet.public.*.id, 0) // nat_gatewayをpublic_subnetに配置すること
tags = {
Name = "${var.app_name}-nat"
}
}
nat_gatewayはprivate_subnet内のインスタンスが外部インターネットに接続できることを許可するんですが、外部インターネットからprivate_subnet内のインスタンスに接続を禁止します。
詳しくは https://docs.aws.amazon.com/vpc/latest/userguide/vpc-nat-gateway.html にてご確認ください。
上記のnat_gateway構築コートには
- nat_gatewayのElasticIp設定する
- private_subnet内のインスタンスが外部インターネット接続するためnat_gatewayをpublic_subnetに配置する
Proxy module
ここのProxyはただのEC2インスタンスとなっており、Proxyセットアップするの真の目的は
- RDSは
private_subnet内に配置されるからエンジニアがRDS接続するため - RDSに接続することを制限すること
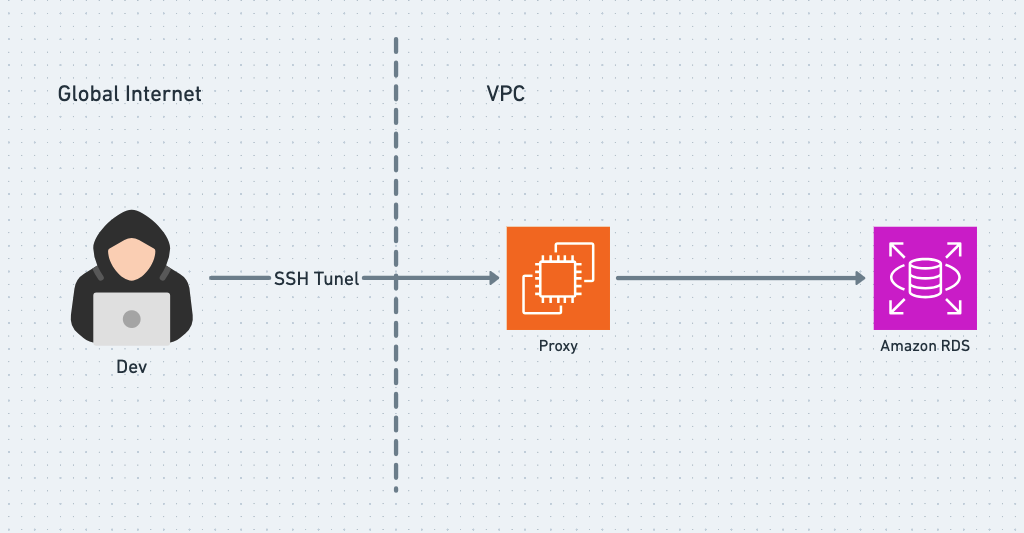
画像 4
画像4を見るとエンジニアがSSH Tunel通じてProxyに入り、ProxyからRDSに行くというイメージとなります。
だからこそ、ProxyはRDS守るためのシールドとして利用されるようにします。
Proxyの設定は
resource "aws_security_group" "proxy" {
name = "${var.app_name}-proxy-sg"
description = "Allow ssh connect to db proxy"
vpc_id = var.vpc_id
// Inbound rule
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
// Outbound rule
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
tags = {
Name = "${var.app_name}-proxy-sg"
}
}
resource "aws_instance" "proxy" {
instance_type = "t2.micro"
ami = local.ami
subnet_id = var.subnet_id // public_subnet id
security_groups = [aws_security_group.proxy.id]
key_name = "key_pair_name"
tags = {
Name = "${var.app_name}-db-proxy"
}
}
上記のコードのように、SSHを介してプロキシへのアクセスを制限するために、Proxyのセキュリティグループのインバウンドを設定して、ポート22だけを許可します。
ProxyはRDSの前にある「バッファー領域」としての役割しか果たさないため、マイクロインスタンスが1つあれば十分です。そしてもちろん、Proxyを外部インターネットからアクセスできるようにするために、それをpublic_subnetに配置する必要があります。
RDS Module
RDSインスタンスと、そのインスタンスを含むクラスターを定義しています。主な目的はデータを保存することです(言い換えれば、これはサービスのデータベースです)。
resource "aws_rds_cluster" "this" {
cluster_identifier = "${var.app_name}-mysql-cluster"
engine = local.rds_engine
engine_version = "8.0.mysql_aurora.3.02.0" // エンジン定義: mysql または postgreSQL
db_cluster_parameter_group_name = aws_rds_cluster_parameter_group.default.name
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group.name
vpc_security_group_ids = [aws_security_group.this.id]
port = var.port
database_name = var.database_name // DB名
master_username = var.master_username
master_password = var.master_password
skip_final_snapshot = false
final_snapshot_identifier = "${var.app_name}-mysql-final-snapshot"
}
resource "aws_rds_cluster_instance" "this" {
identifier = "${var.app_name}-mysql-identifier"
cluster_identifier = aws_rds_cluster.this.id
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group.name
db_parameter_group_name = aws_db_parameter_group.default.name
engine = local.rds_engine
instance_class = "db.t3.medium" // rdsインスタンスのキャパシティ
}
基本的にはrdsインスタンスの設定は複雑作業が特にないと思って、詳しくは https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/rds_cluster_instance にてご参考ください。
ただ一つ注意すべき点があります。master_username および master_password は実際の運用では使用しないでください。厳密に言うと、使用してはいけないというわけではありませんが、むしろ、代わりに以下のような方法をご検討ください:
- エンジニアごとに特定アカウントと紐付ける権限を指定する
- サービスも前に指定したアカウントでDBに接続する
上の作業はシステムが落ちるまたは事故がある時に原因調査またはだれか何のSQLを実行したのを明確するためなんです。
ecs_clusterとecs_api modules
これらの2つのモジュールを1つにまとめる理由は、それらが両方ともECSに関連しているからです。2つのサブモジュール、クラスターとAPIに分割する主な目的は、単にecs_clusterの定義とecs_serviceを分離することです。
ecs_clusterに対しては
resource "aws_ecs_cluster" "this" {
name = "${var.app_name}"
}
ecs_apiは
resource "aws_ecs_service" "this" {
depends_on = [aws_lb_listener_rule.this]
name = var.app_name
desired_count = 1
launch_type = "FARGATE"
// fargate使用する目的はAWSが各サーバインスタンスを管理してくれる。
cluster = var.cluster_name
task_definition = aws_ecs_task_definition.this.arn // task_defintionに参照する
network_configuration {
subnets = var.subnet_ids
security_groups = [aws_security_group.this.id]
}
load_balancer {
container_name = "nginx"
container_port = local.port_nginx
target_group_arn = var.lb_target_group_arn
}
}
追跡できるようにECSサービスのアーキテクチャの一部を再掲します。
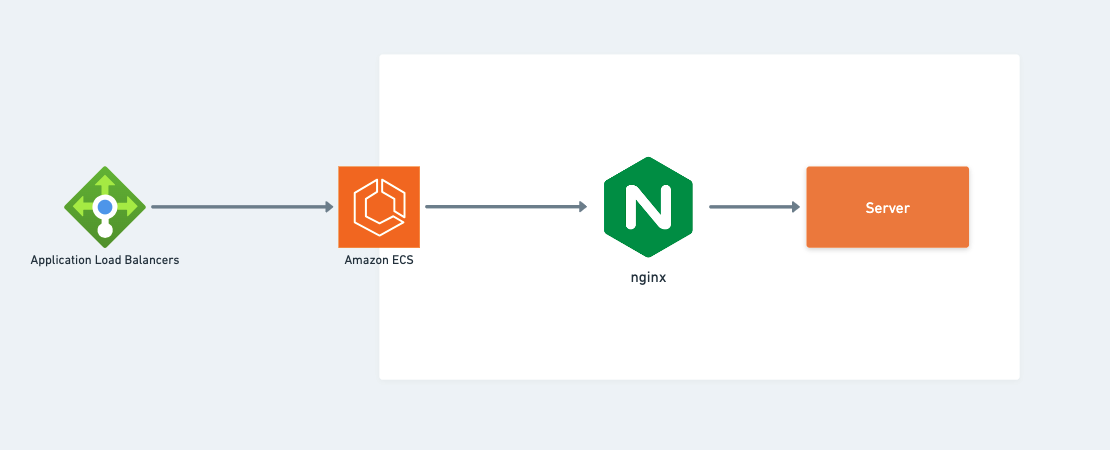
画像 5
load_balancer {
container_name = "nginx"
container_port = local.port_nginx
target_group_arn = var.lb_target_group_arn
}
上記のコードは、nginxリバースプロキシを作成します。この場合、すべてのサービスへのリクエストは、サービスに入る前にnginxを通過します。
ECSに関する概要は、以下の図を参照してください。
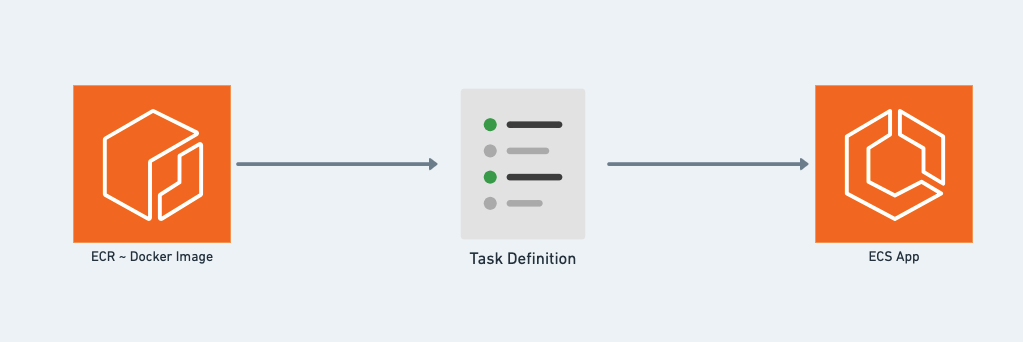
画像 6
画像 6は、ECSの動作方法を示しています。その中には:
- ECRはサービスに対応するdockerイメージを保存する
- task_definitionは、サービスのブループリント(JSONファイルでパラメータやコンテナなどが定義されている)です。
基本的に、ここでECSでサービスを運用する場合、次の手順が必要です:
- サービスをDocker化して、それをDockerイメージに変換する
- このDockerイメージをregistryにアップロードしする(ここではECRを使用)
- registryから、task_definitionを構築します
- task_definitionからECS内に実施されるサービスを構築する
task_definitionの設定は
resource "aws_ecs_task_definition" "this" {
family = "newanigram-api"
container_definitions = data.template_file.task_definition.rendered // task_definition定義JSONファイルに参照する
cpu = "256"
memory = "512"
network_mode = "awsvpc"
task_role_arn = aws_iam_role.ecs_iam_role.arn
execution_role_arn = aws_iam_role.ecs_iam_role.arn
}
// task_definition定義JSONファイル
data "template_file" "task_definition" {
template = file("./ecs_api/task_definition.json")
vars = {
account_id = local.account_id
region = local.region
repository_api = "api"
}
}
task_definitionのメインな内容は
[
{
"name": "api",
"image": "${account_id}.dkr.ecr.${region}.amazonaws.com/${repository_api}:${api_tag}",
"cpu": 0,
"memory": 128,
"portMappings": [
"containerPort": ${port_api},
"hostPort": ${port_api}
}
],
}
]
Execution
terraform実行ため terraform applyコマンドで行きます。実行される前にこれから新規作成・変更ある・削除されるリソースがプレビューできます。
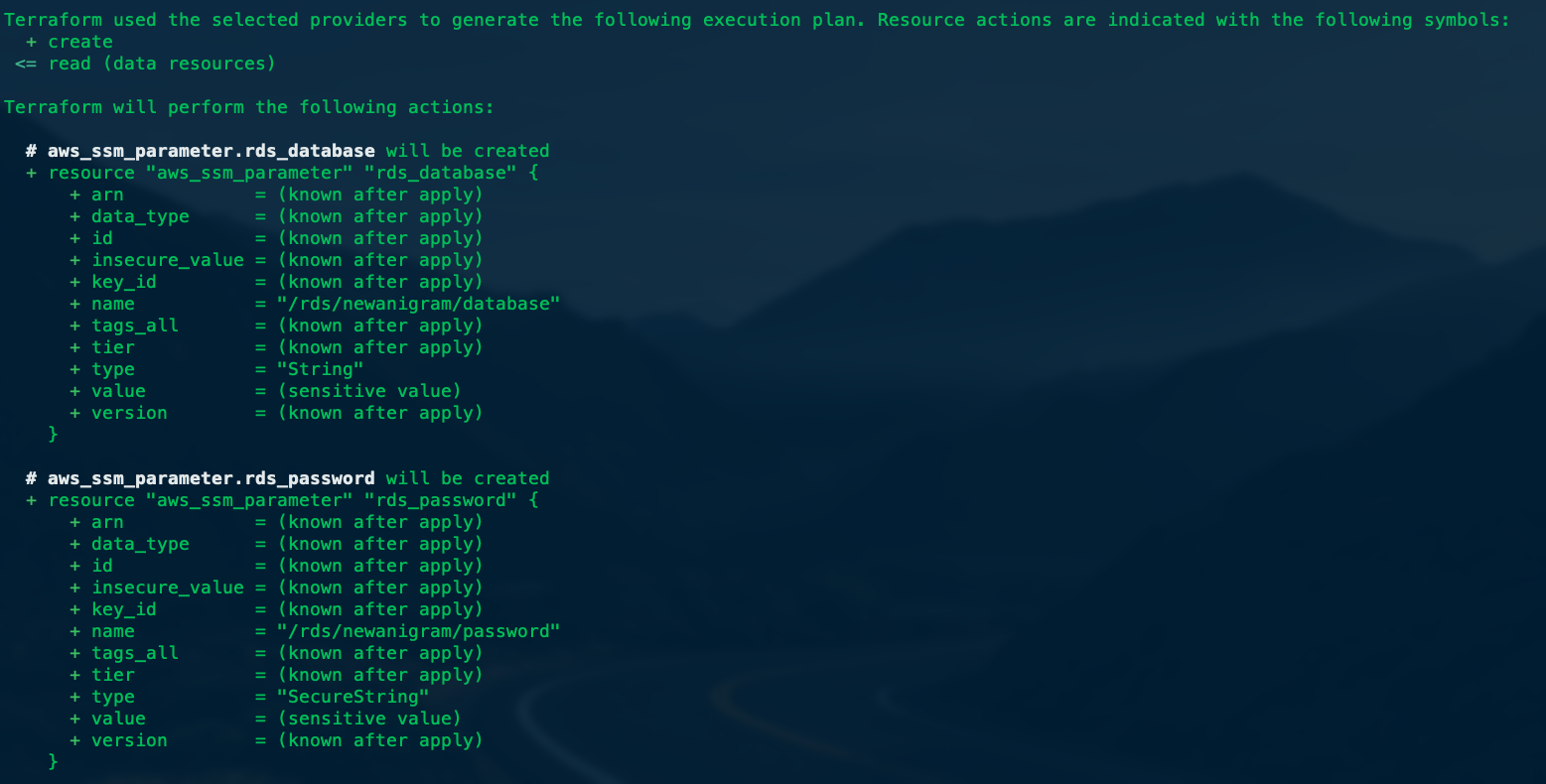
実行後にAWSコンソール上にこんな感じな結果がもらえます。
vpc:
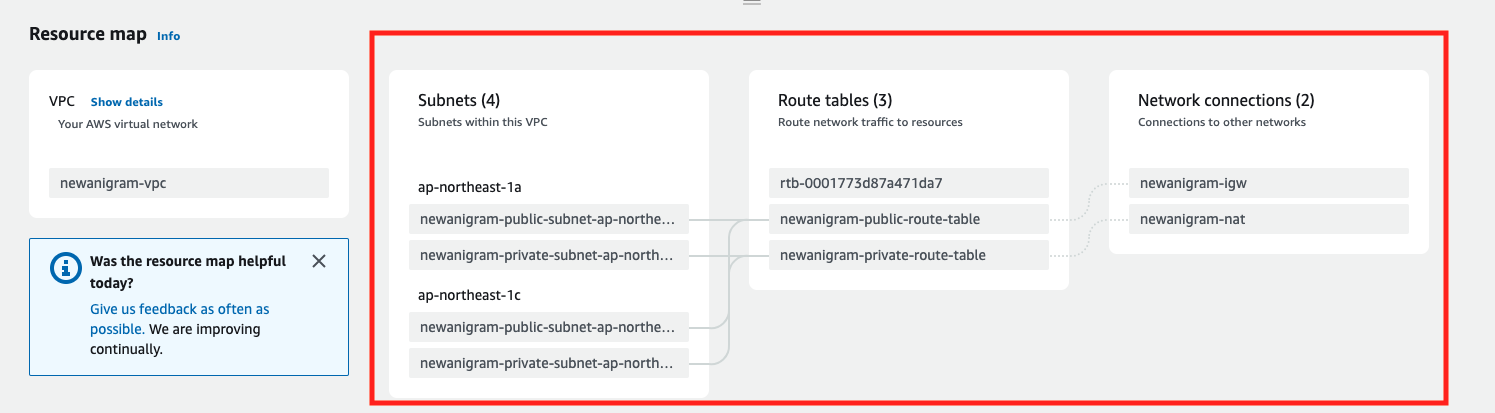
rds:
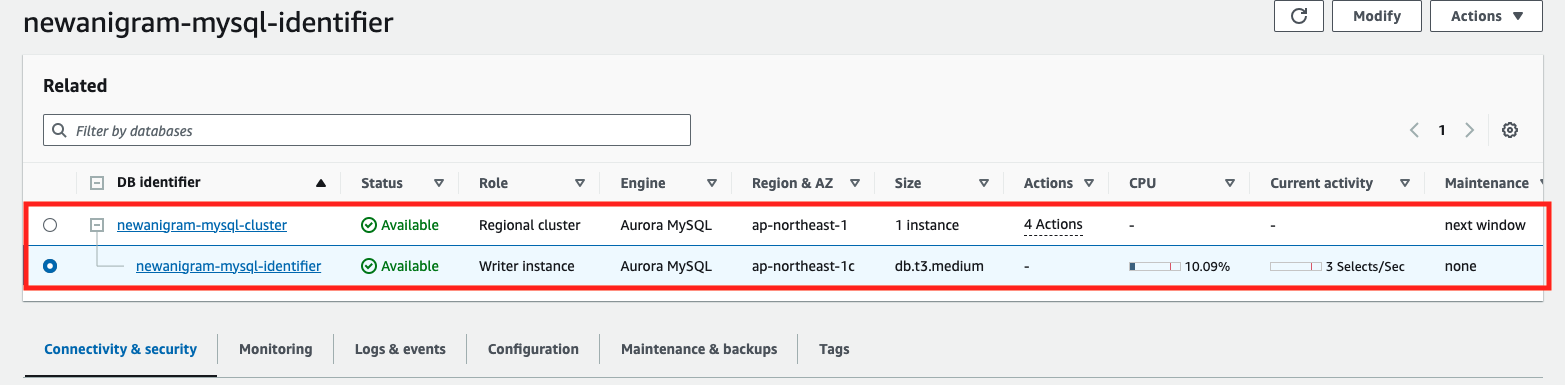
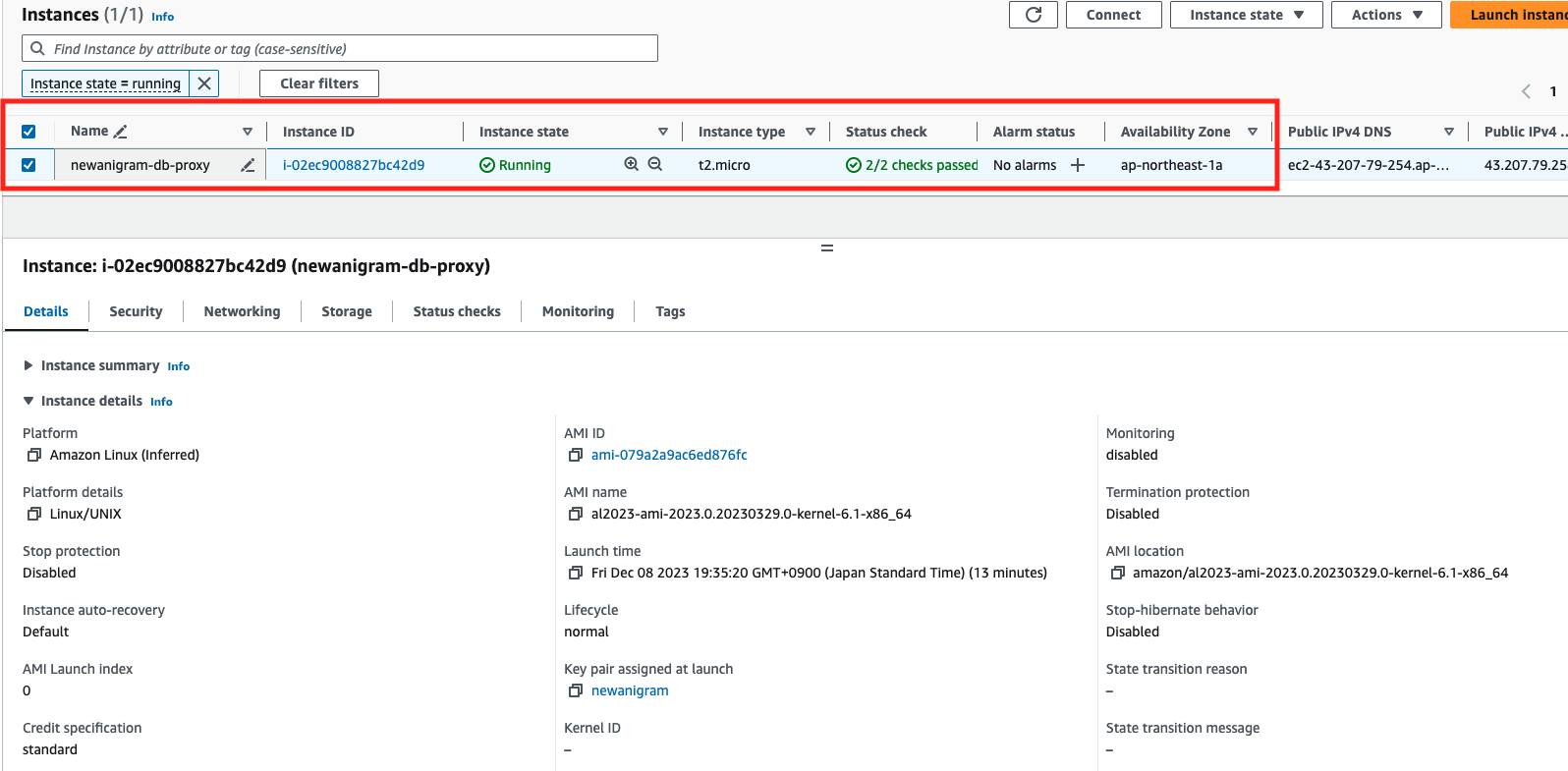
proxy:
ecs:
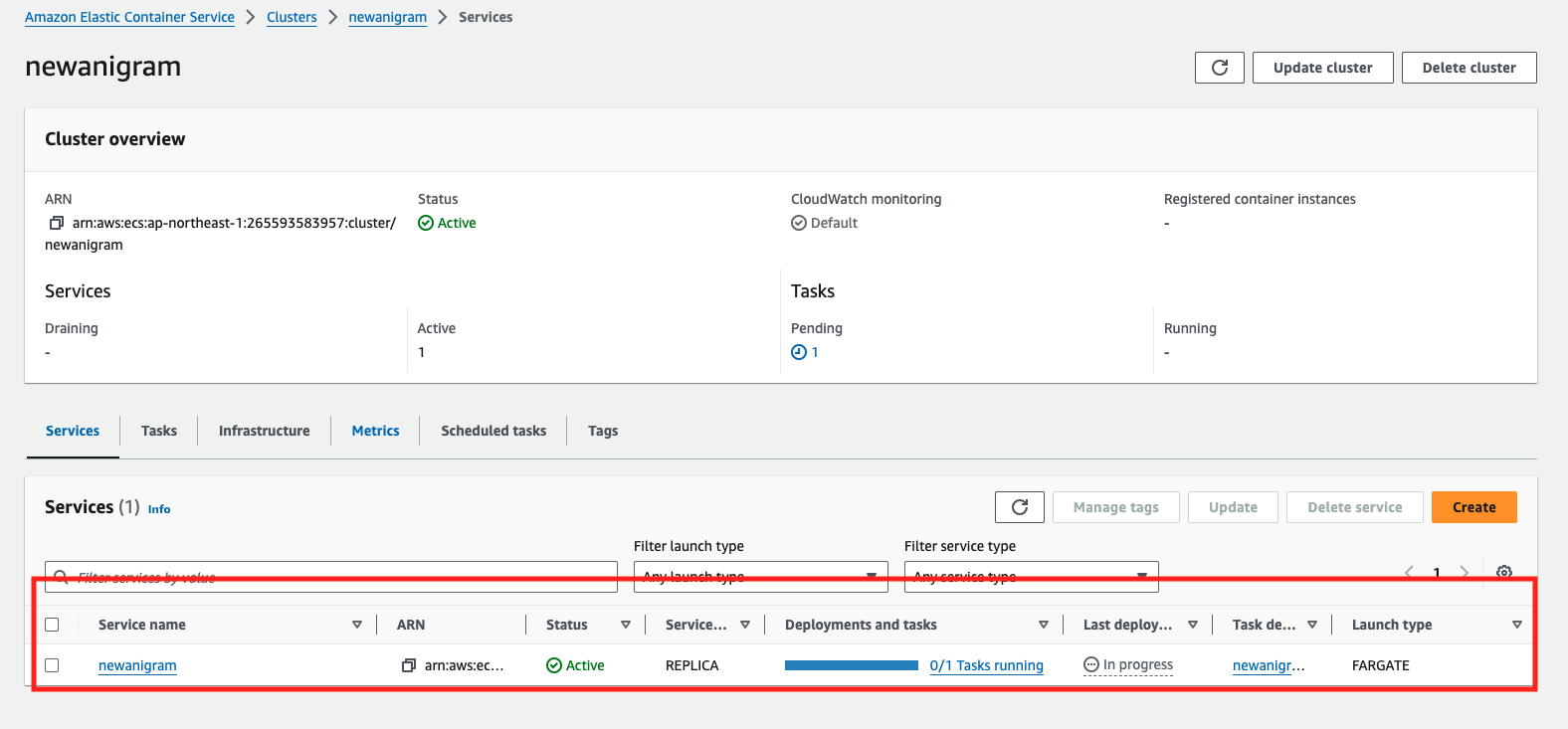
terraformコードでのすべての設定情報は、AWSコンソール上で正確に反映されています(赤く囲まれた部分を見て詳細を確認できます)。
まとめ
それでは、どのようにしてterraformを使用してAWS上でゼロからマイクロサービスのためのインフラストラクチャを構築したかを簡単に紹介しました。
読者が基本的なマイクロサービスのインフラストラクチャアーキテクチャやterraformでインフラストラクチャを展開する方法について、より視覚的な理解を得ることができることを期待しています。
次の記事を楽しみにしています。どうもありがとうございます。
また、エアークローゼットはエンジニア採用活動も行っておりますので、興味のある方はぜひご覧ください!