更新履歴:
(2020/6/10) JobのログをAPI取得する方法を一番下に追記
(2020/7/27) URLパラメータのproject_idをspace_idに変更することで、デプロイメントスペースのJob(バッチ型デプロイメントの実行設定)にも対応可能であることを確認。
Cloud Pak for Data (以下CP4D)の分析プロジェクトでは、NotebookやData Refinery FlowをJob化してバッチ実行することができます。今回やりたいことは、以下の2点です。
- Jobに引数を与えて実行時に挙動を変えられるようにしたい
- JobをCP4D外部からAPIで実行したい
厳密に言うとJobは「実行時に引数を渡す」と言うよりは「環境変数をセットして起動」という表現のほうが正確のようです。おそらく内部的にはOpenShiftのPodとして起動するため、環境変数をOpenShiftのConfigMapとして扱っているのだと推測します。
JobをAPIで起動し、その際に環境変数を与えて処理ロジックに渡す、ということを実際にやってみます。
Notebookを作成
Notebookを作成し、それをJob化します。
今回扱う環境変数として「MYENV1」「MYENV2」「MYENV3」を想定し、値をpandasのデータフレームに加工して、CSVとして分析プロジェクトのデータ資産に出力します。
これらの環境変数はもちろんデフォルトでは定義されていないので、os.getenvのdefaultでデフォルト値をセットしておきます。
import os
myenv1 = os.getenv('MYENV1', default='no MYENV1')
myenv2 = os.getenv('MYENV2', default='no MYENV2')
myenv3 = os.getenv('MYENV3', default='no MYENV3')
print(myenv1)
print(myenv2)
print(myenv3)
# -output-
# no MYENV1
# no MYENV2
# no MYENV3
次に、これらの3つの値をpandasでデータフレーム化して、
import pandas as pd
df = pd.DataFrame({'myenv1' : [myenv1], 'myenv2' : [myenv2], 'myenv3' : [myenv3]})
df
# -output-
# myenv1 myenv2 myenv3
# 0 no MYENV1 no MYENV2 no MYENV3
分析プロジェクトのデータ資産として書き出します。ファイル名にはタイムスタンプを付けておきます。分析プロジェクトへのデータ資産の出力は、こちらの記事を参照。
from project_lib import Project
project = Project.access()
import datetime
now = datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9))).strftime('%Y%m%d_%H%M%S')
project.save_data("jov_env_test_"+now+".csv", df.to_csv(),overwrite=True)
Jobを作成
Notebookのメニューから、File > Save Versionsでバージョンを保存します。Jobを作成する際には必須です。
次に、Notebook画面右上の「ジョブ」ボタン > ジョブの作成をクリックします。

ジョブの名前をつけて、作成をクリックします。
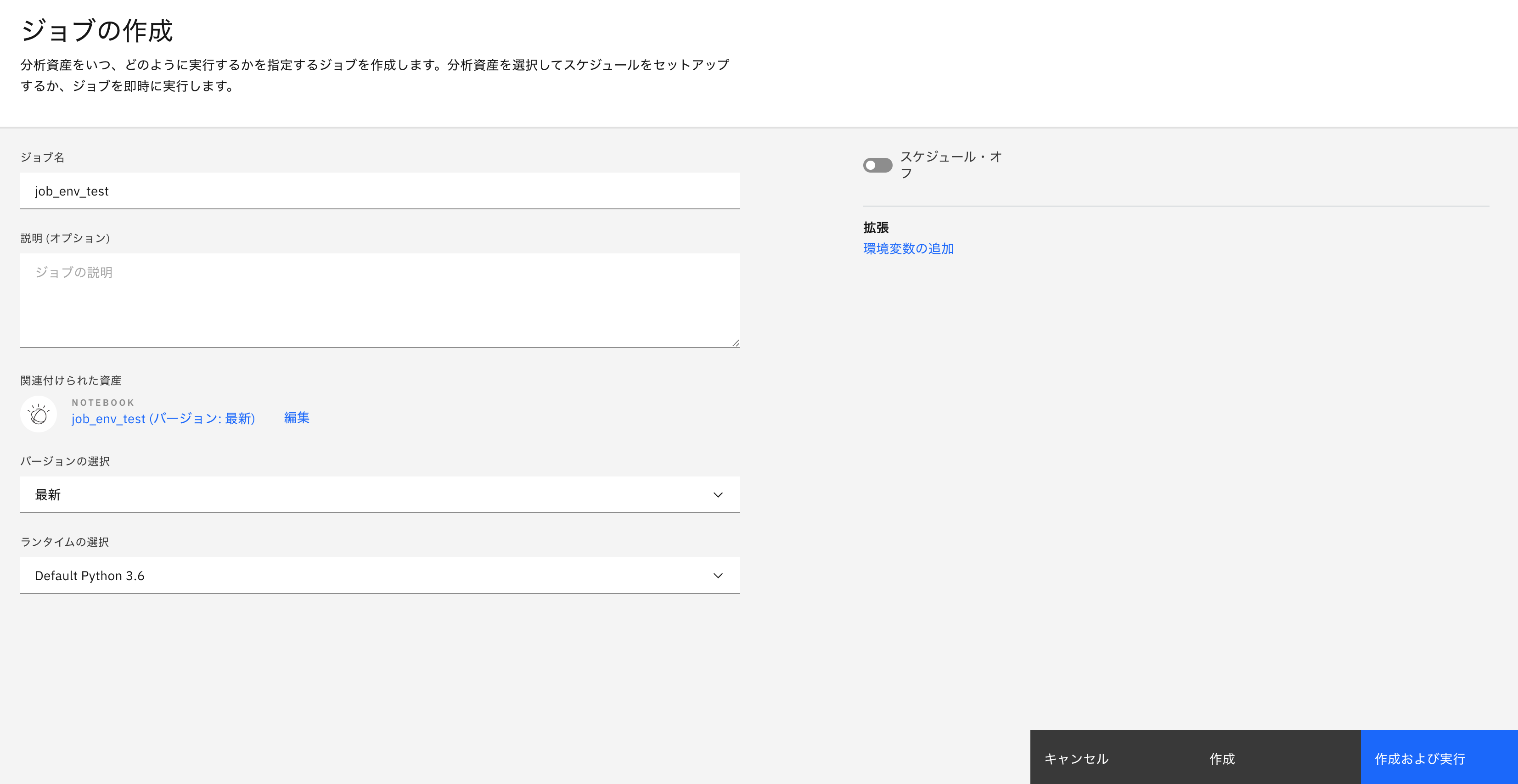
Jobを実行
作成したJobをCP4D画面上で実行してみます。
まずはそのまま、環境変数を全く定義しない状態で、そのまま「ジョブの実行」ボタンをクリックして実行。

ジョブが実行され、「完了」になればOK。

分析プロジェクトのデータ資産を見ると、CSVファイルが生成されており、

ファイル名をクリックしてプレビューを見ると、Notebook内でセットしたdefault値が格納されたことがわかります。

次に、環境変数をセットして実行してみます。
Jobの画面で「環境変数」の「編集」をクリックし、以下の3行を設定します。
MYENV1=1
MYENV2=hoge
MYENV3=10.5
こんな感じです。
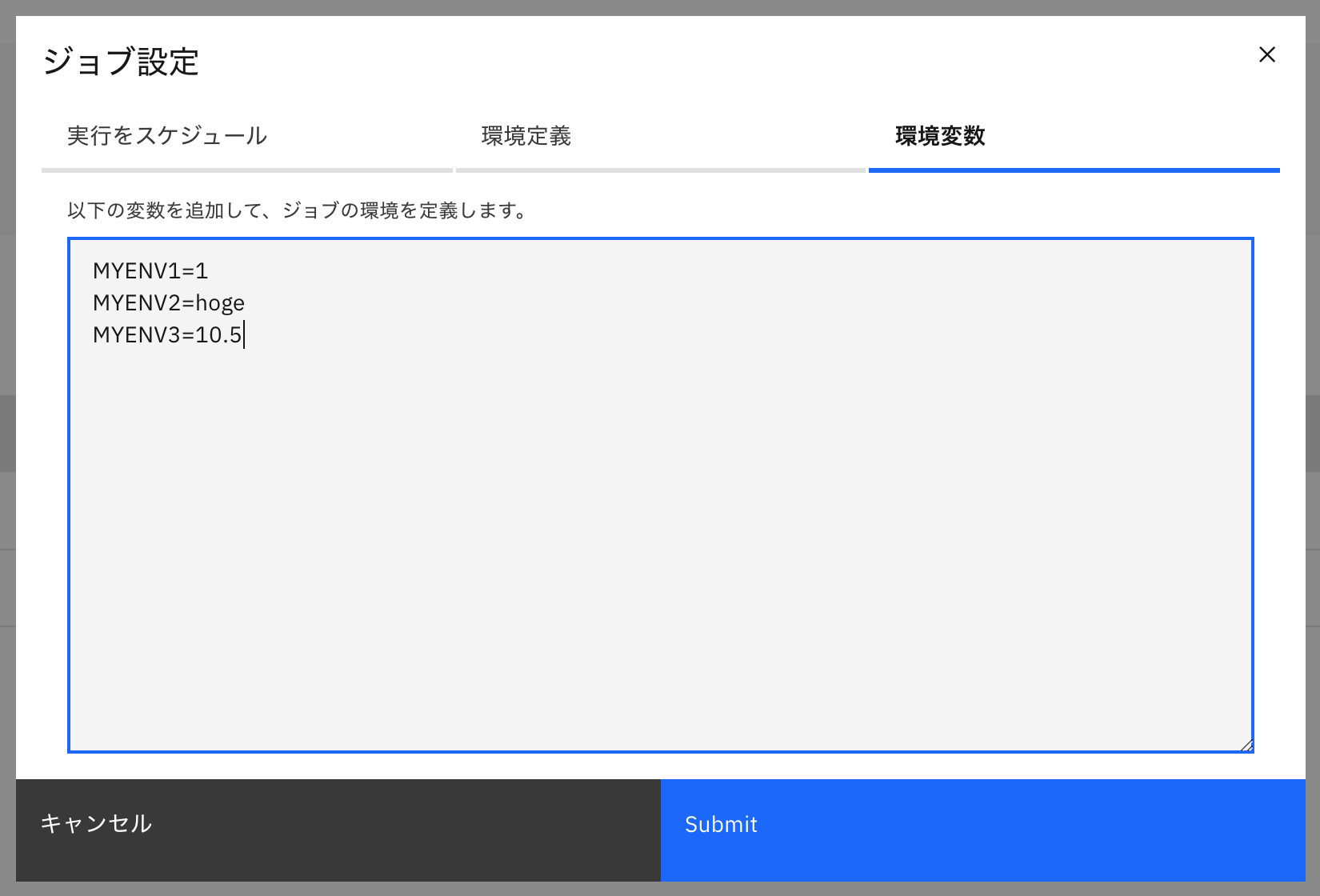
設定内容をSubmitしたら、再度Jobを実行してみます。
結果のCSVファイルの内容は、こうなりました。

環境変数なので、数値を入れても全て文字列Stringとして扱われています。
JobをAPIで実行
pythonのrequestsを使って、作成したJobをAPI経由でキックします。
CP4D外のPython環境から、以下のコードを実行していきます。
認証
tokenを取得するため、ユーザー名とパスワードでBasic認証し、accessTokenを取得します。
認証については、CP4D v2.5の製品マニュアルにcurlでの実行例があります。
url = "https://cp4d.hostname.com"
uid = "username"
pw = "password"
import requests
#Authentication
response = requests.get(url+"/v1/preauth/validateAuth", auth=(uid,pw), verify=False).json()
token = response['accessToken']
requestsのverify=Falseオプションは、CP4Dが自己署名証明書を使用している場合の証明書チェック回避策です。
Job一覧を取得
分析プロジェクトのJob一覧を取得します。
準備として、使用する分析プロジェクトのIDは予めCP4D上で調べておきます。分析プロジェクト内のNotebookで、環境変数PROJECT_IDを表示して確認します。
import os
os.environ['PROJECT_ID']
# -output-
# 'f3110316-687e-450a-8f17-57296c907973'
上で調べたプロジェクトIDをセットして、ジョブ一覧をAPIで取得します。
APIはWatson Data APIを使います。APIリファレンスは、Jobs / Get list of jobs under a projectです。
(2020/7/27追記) URLパラメータproject_idの代わりにspace_idを使うことで、デプロイメントスペースのジョブを実行可能です。
project_id = 'f3110316-687e-450a-8f17-57296c907973'
headers = {
'Authorization': 'Bearer ' + token,
'Content-Type': 'application/json'
}
# Job list
# 分析プロジェクトのJobの場合
response = requests.get(url+"/v2/jobs?project_id="+project_id, headers=headers, verify=False).json()
# デプロイメントスペースのJobの場合。space_idは別途調査しておく。
# response = requests.get(url+"/v2/jobs?space_id="+space_id, headers=headers, verify=False).json()
response
# -output-
#{'total_rows': 1,
# 'results': [{'metadata': {'name': 'job_env_test',
# 'description': '',
# 'asset_id': 'b05d1214-d684-4bd8-b1fa-cc05a8ccee81',
# 'owner_id': '1000331001',
# 'version': 0},
# 'entity': {'job': {'asset_ref': '6e0b450e-2f9e-4605-88bf-d8a5e2bda4a3',
# 'asset_ref_type': 'notebook',
# 'configuration': {'env_id': 'jupconda36-f3110316-687e-450a-8f17-57296c907973',
# 'env_type': 'notebook',
# 'env_variables': ['MYENV1=1', 'MYENV2=hoge', 'MYENV3=10.5']},
# 'last_run_initiator': '1000331001',
# 'last_run_time': '2020-05-31T22:20:18Z',
# 'last_run_status': 'Completed',
# 'last_run_status_timestamp': 1590963640135,
# 'schedule': '',
# 'last_run_id': 'ebd1c2f1-f7e7-40cc-bb45-5e12f4635a14'}}}]}
上記のasset_idが、Job "job_env_test" のIDです。
変数に格納しておきます。
job_id = "b05d1214-d684-4bd8-b1fa-cc05a8ccee81"
Jobを実行
上記のJobをAPIで実行します。APIリファレンスは、Job Runs / Start a run for a jobです。
実行時にはjsonでjob_runという値を与える必要があり、実行時の環境変数もここに含めます。
jobrunpost = {
"job_run": {
"configuration" : {
"env_variables" : ["MYENV1=100","MYENV2=runbyapi","MYENV3=100.0"]
}
}
}
上記のjob_runをjsonで与えて、ジョブを実行します。
実行IDは、レスポンスの'metadata'の'asset_id'に格納されています。
(2020/7/27追記) URLパラメータproject_idの代わりにspace_idを使うことで、デプロイメントスペースのジョブを実行可能です。
# Run job
# 分析プロジェクトのJobの場合
response = requests.post(url+"/v2/jobs/"+job_id+"/runs?project_id="+project_id, headers=headers, json=jobrunpost, verify=False).json()
# デプロイメントスペースのJobの場合
# response = requests.post(url+"/v2/jobs/"+job_id+"/runs?space_id="+space_id, headers=headers, json=jobrunpost, verify=False).json()
# Job run id
job_run_id = response['metadata']['asset_id']
job_run_id
# -output-
# 'cedec57a-f9a7-45e9-9412-d7b87a04036a'
Job実行ステータスを確認
実行したら、ステータスを確認します。APIリファレンスは、Job Runs / Get a specific run of a jobです。
(2020/7/27追記) URLパラメータproject_idの代わりにspace_idを使うことで、デプロイメントスペースのジョブを実行可能です。
# Job run status
# 分析プロジェクトのJobの場合
response = requests.get(url+"/v2/jobs/"+job_id+"/runs/"+job_run_id+"?project_id="+project_id, headers=headers, verify=False).json()
# デプロイメントスペースのJobの場合
# response = requests.get(url+"/v2/jobs/"+job_id+"/runs/"+job_run_id+"?space_id="+space_id, headers=headers, verify=False).json()
response['entity']['job_run']['state']
# -output-
# 'Starting'
何度かこのrequests.getを実行すると、結果は 'Starting' -> 'Running' -> 'Completed' と変化します。
'Completed'となれば実行完了です。
実行結果
CP4D画面に戻り、分析プロジェクトのデータ資産に生成されたCSVファイルの中身を確認します。

job_runに指定した環境変数が、ちゃんと結果データ内に格納されていることが確認できました。
(おまけ)
job_runの環境変数の値には、ダブルバイト文字も使えました。
jobrunpost = {
"job_run": {
"configuration" : {
"env_variables" : ["MYENV1=あいうえお","MYENV2=アイウエオ","MYENV3=アイウエオ"]
}
}
}
実行結果:

あとは、JobのNotebook内で受け取った環境変数の値(文字列)を煮るなり焼くなり好きなように使えばOK。
(参考資料)
https://github.ibm.com/GREGORM/CPDv3DeployML/blob/master/NotebookJob.ipynb
このリポジトリには、CP4Dで使えるNotebookの有用なサンプルが置いてありました。
(2020/6/10) JobのログをAPI取得する方法を追記します。
APIリファレンスは、Job Runs / Retrieve runtime log of a runです。
# get job log
response = requests.get(url+"/v2/jobs/"+job_id+"/runs/"+job_run_id+"/logs?project_id="+project_id, headers=headers, verify=False).json()
response['results']