投稿目的
英語で書かれた深層学習に関する論文を読むことは骨が折れます。そのため、本記事を読めば内容が分かる要約したものを書きたいと思いました。しかし、要約するには全体を正確に把握する必要がありますので、まずは論文翻訳を行いたいと思います。やり方ですが、Google翻訳して、それを私になりに解釈して修正しました。そのため、読んで分かり易いように、原文には記載されていない単語も組み入れて修正している点や、私自身が内容を掴み切れずにGoogle翻訳のままの意味不明な箇所があることをご留意頂ければと思います。今回の論文選定ですが、エポックメイキングなAlexNetにしました。
論文:ImageNet Classification with Deep Convolutional Neural Networks
- タイトル:深い畳み込みニューラルネットワークを用いたイメージネットの分類
- 年代:2012年の論文
- URL:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
- 作者:Alex Krizhevsky & Ilya Sutskever & Geoffrey E. Hinton
Abstract(要旨)
ImageNet LSVRC-2010コンテストの120万の高解像度画像を1,000の異なるクラスに分類するために、大規模で深い畳み込みニューラルネットワークをトレーニングしました。テストデータでは、37.5%と17.0%のトップ1とトップ5のエラー率を達成しました。これは以前の最先端よりもかなり優れています。6,000万個のパラメータと65万個のニューロンを持つニューラルネットワークは、5つの畳み込み層から構成され、そのうちのいくつかには最大プーリング層、最後に出力層にソフトマックス関数(1,000パターン分類)を持つ3つの全結合層が続きます。訓練を早くするために、我々は非飽和ニューロン(=活性化関数にReLUを使った)と非常に効率的な畳み込み演算のGPU実装を使用しました。全結合層の過学習を減らすために、我々は非常に効果的であることが証明された「ドロップアウト」と呼ばれる最近開発された正則化方法を採用しました。また、ILSVRC-2012コンペティションにこのモデルの異形で出場し、15.3%というトップ5のテストエラー率を達成しました。ちなみに2位は26.2%でした。
1 Introduction(導入)
オブジェクト認識に対する現在のアプローチは、機械学習方法を本質的に利用しています。それらのパフォーマンスを向上させるために、より大きなデータセットを集め、より強力なモデルを学び、そして過学習を防ぐためにより良いテクニックを使うことができます。最近まで、ラベル付けされた画像のデータセットは比較的小さく、数万の画像程度であった(例えば、NORB、Caltech−101/256、およびCIFAR−10/100)。単純な認識作業は、特にラベル保存変換で強化されている場合は、このサイズのデータセットで非常にうまく解決できます。例えば、MNISTディジット認識タスクの現在のベストエラー率(<0.3%)は人間のパフォーマンスに近づきます。しかし、現実的な設定のオブジェクトはかなりの変動性を示すので、それらを認識することを学ぶためには、もっと大きなトレーニングセットを使用する必要があります。そして確かに、小さい画像データセットの欠点は広く認識されているが、最近になって数百万の画像を含むラベル付きデータセットを収集することが可能になりました。新しい大規模なデータセットには、何十万もの完全にセグメント化された画像からなるLabelMeや、22,000以上のカテゴリに分類された1,500万を超える高解像度画像からなるImageNetがあります。
何百万もの画像から何千ものオブジェクトについて学ぶためには、大きな学習能力を持つモデルが必要です。ただし、オブジェクト認識タスクが非常に複雑であるため、ImageNetほどの大きさのデータセットでもこの問題を特定できないため、我々のモデルもまた、我々が持っていないすべてのデータを補うためのたくさんの事前知識を持つべきです。畳み込みニューラルネットワーク(CNN)は、そのような1つのクラスのモデルを構成します。それらのキャパシティは、それらの深さおよび幅を変えることによって制御することができ、そしてそれらはまた、画像の性質について強くほぼ正しい推定を立てます(すなわち、統計の定常性および画素依存性の局所性)。このように、同じサイズのレイヤを持つ一般的なフィードフォワードニューラルネットワークと比較して、CNNは接続とパラメータがはるかに少ないため、トレーニングが容易です。理論的には最高のパフォーマンスはわずかに悪いけれども。。
CNNの魅力的な品質にもかかわらず、そしてそれらのローカルアーキテクチャの相対的な効率が良いにもかかわらず、それらは依然として高解像度画像に大規模に適用するには法外に高価でした。幸いなことに、2次元畳み込みに高度に最適化された実装と対になった現在のGPUは、面白いことに大きなCNNのトレーニングを容易にするのに十分強力です。
この論文の具体的な貢献は以下の通りです:私たちはこれまでにILSVRC-2010とILSVRC-2012のコンペティションで使用されるImageNetのサブセットで、とても大きい畳み込みニューラルネットワークの1つを今日まで訓練しました。そして、これらのデータセットについてこれまでに報告された最高の結果が達成されました。2次元畳み込みに高度に最適化されたGPU実装と、畳み込みニューラルネットワークのトレーニングに固有の他のすべての操作を書きました。私たちのネットワークには、そのパフォーマンスを向上させ、トレーニング時間を短縮するための、いくつかの新しいそして珍しい機能が含まれています。これについては、3章で詳しく説明します。私たちのネットワークの規模は、120万のラベル付けされたトレーニングサンプルでさえも、過学習を重大な問題として示しました、それで我々は過学習を防ぐためにいくつかの効果的なテクニックを使いました。こちらについては、4章で説明します。我々の最終的なネットワークは5つの畳み込み層と3つの全結合層を含んでいます、そしてこの深さは重要であると思われます:私たちはいくつかの畳み込み層(取り除くそれぞれがモデルのパラメータが、全体の内1%以下なのにも関わらず)を取り除くことが、パフォーマンス低下の原因になることがわかりました。
結局のところ、「ネットワークのサイズ」は、主に現在のGPUで利用可能なメモリの量と、私たちが許容しても構わないと思っているトレーニング時間の量によって制限されます(要するにトレードオフの関係)。私たちのネットワークは2つのGTX 580 3GB GPUでトレーニングするのに5〜6日かかります。私たちのすべての実験は、より速いGPUとより大きなデータセットが利用可能になるのを待つだけで私たちの結果が改善できることを示唆しています。
2 The Dataset(データセット)
ImageNetは、およそ22,000のカテゴリに属する1,500万以上のラベル付き高解像度画像のデータセットです。画像はWebから収集され、AmazonのMechanical Turkクラウドソーシングツールを使用して人間のラベラーによってラベル付けされました。2010年以降、Pascalビジュアルオブジェクトチャレンジの一環として、ImageNet大規模ビジュアル認識チャレンジ(ILSVRC)と呼ばれる年次大会が開催されました。ILSVRCは、おおよそ1,000種類の各カテゴリに約1,000枚の画像を含むImageNetのサブセットを使用します。全体で、およそ120万のトレーニング画像、50,000の検証画像、および150,000のテスト画像があります。
ILSVRC-2010は、テストセットラベルが利用可能な唯一のバージョンのILSVRCであるため、これが、ほとんどの実験を実行したバージョンです。私たちはILSVRC-2012コンペティションにも参加しているので、6章で、このバージョンのデータセットについても、テストセットラベルを使用できない場合の結果も報告します。ImageNetでは、トップ1とトップ5の2つのエラー率を報告するのが一般的です。ここで、トップ5のエラー率とは、正解ラベルが、そのモデルによって最も可能性が高いと考え出された5つのラベルに、1つも含まれない場合の確率です。
ImageNetは可変解像度の画像で構成されていますが、私たちのシステムは一定の入力寸法を必要とします。そのため、画像を256×256の固定解像度にダウンサンプリングしました。長方形の画像を考えて、まず短辺の長さが256になるように画像のサイズを変更し、次に中央の256×256の部分を切り取りました。各ピクセルからトレーニングセットの平均アクティビティを差し引くこと以外は、他の方法で画像を前処理することはしませんでした。そこで、ピクセルの(中央に配置された)生のRGB値で我々のネットワークをトレーニングしました。
3 The Architecture(構造)
私たちのネットワークのアーキテクチャは図2に要約されています。それは8つの学習された層(5つの畳み込み層と3つの全結合層)からなります。以下では、私たちのネットワークのアーキテクチャの斬新なまたは珍しい機能のいくつかを説明します。3.1節〜3.4節は、最も重要なものから順に、重要度の観点でソートされています。
3.1 ReLU Nonlinearity(非線形関数であるReLU)
ニューロンの出力fをその入力xの関数としてモデル化する標準的な方法は、f(x)=tanh(x)またはf(x)=(1+eの-x乗)の-1乗です。勾配降下を用いたトレーニング時間に関しては、これらの飽和非線形性は、非飽和非線形性f(x)= max(0、x)よりはるかに遅いです。NairとHintonに続いて、我々はこの整流線形ユニット(ReLUs)の非線形性を持つニューロンをについて言及します。ReLUを使ったディープ畳み込みニューラルネットワークは、tanhユニットを使った同等のニューラルネットワークよりも数倍速くトレーニングされます。これは図1に示されており、特定の4層の畳み込みネットワークでCIFAR-10データセットで25%のトレーニングエラーに達するのに必要なイテレーション回数を示しています。このプロットは、もし我々が伝統的な飽和ニューロンモデルを使っていたら、この仕事のためにそのような大きなニューラルネットワークで実験することができなかったであろうことを示しています。
CNNで従来のニューロンモデルに代わるものを検討するのは、私たちが最初ではありません。例えば、Jarrett等は、非線形性f(x)=|tanh(x)|は、Caltech-101データセットでの局所平均プーリングが後に続くそれらのタイプのコントラスト正規化で特にうまく機能すると主張します。ただし、このデータセットでの主な関心事は過学習を防ぐことです。したがって、彼らが観察している効果は、我々がReLUを使用したときに報告されるトレーニングセットに適合する加速した能力とは異なります。高速学習は、大規模データセットで訓練された大規模モデルのパフォーマンスに大きな影響を与えます。
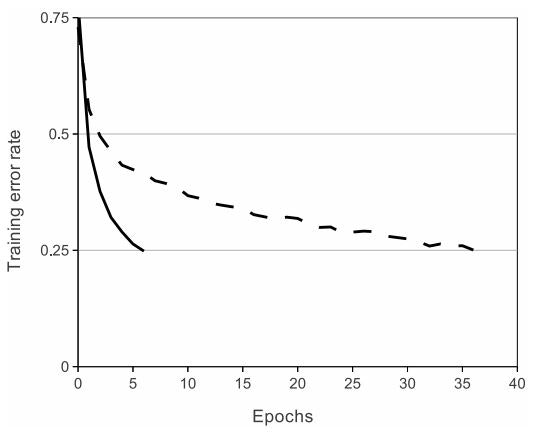
**図1:**ReLUを使用した4層の畳み込みニューラルネットワーク(実線)は、tanhニューロンを使用した同等のネットワーク(破線)の6倍の速さでCIFAR-10で25%のトレーニングエラー率に達します。各ネットワークの学習率は、トレーニングをできるだけ速くするために独立して選択されました。いかなる種類の正則化は行っていません。ここで示されている効果の大きさはネットワークアーキテクチャによって異なりますが、ReLUを持つネットワークは飽和しているニューロンと同等のものより一貫して数倍早く学習します。
3.2 Training on Multiple GPUs(マルチGPUで学習)
単一のGTX580GPUには3GBのメモリしかないため、トレーニングできるネットワークの最大サイズが制限されます。1 GPUに収まるには大きすぎるネットワークをトレーニングするには、120万のトレーニング例で十分です。そのため、2つのGPUにネットを広げました。現在のGPUは、ホストマシンのメモリを経由せずに、互いのメモリから直接読み書きできるため、GPU間の並列化に特に適しています。私たちが採用している並列化スキームは、1つの追加トリックと共に、本質的にカーネル(またはニューロン)の半分を各GPUに置きます:GPUは特定の層でのみ通信します。これは、たとえば、レイヤ3のカーネルがレイヤ2のすべてのカーネルマップから入力を受け取ることを意味します。ただし、レイヤ4のカーネルは、同じGPUに存在するレイヤ3のカーネルマップからのみ入力を受け取ります。接続性のパターンを選択することは相互検証の問題ですが、これにより、計算量の許容範囲内に収まるまで通信量を正確に調整できます。
結果として得られるアーキテクチャは、CiresÁanらによって採用された「柱状」CNNのアーキテクチャといくらか似ています。ただし、列が独立していない点が異なります(図2を参照)。この方式では、1つのGPUでトレーニングされた各畳み込み層でカーネルの半分の数のカーネルを持つネットと比較して、トップ1およびトップ5のエラー率がそれぞれ1.7%および1.2%減少します。2つのGPUネットは、1つのGPUネットよりもトレーニングに要する時間がわずかに短くなります。
(実際の1つのGPUネットは、最終的な畳み込みレイヤの2つのGPUネットと同じ数のカーネルを持っています。これは、ネットのパラメータの大部分が最初の全結合レイヤーにあり、最後のたたみ込みレイヤーを入力として使用するためです。そのため、2つのネットがほぼ同じ数のパラメータを持つようにするために、最終的な畳み込み層のサイズを半分にすることはしませんでした(それに続く全結合層も)。したがって、この比較は2GPUネットの「半分のサイズ」よりも大きいため、1GPUネットの方が有利です。)
3.3 Local Response Normalization(LRN)
ReLUには、飽和を防ぐための入力正規化を必要としないという望ましい特性があります。少なくともいくつかのトレーニングサンプルがReLUへの肯定的な入力を生成するならば、学習はそのニューロンで起こります。しかしながら、次の局所正規化スキームが一般化を補助することがわかります。カーネルiを位置(x、y)に適用し、次にReLU非線形性を適用することによって計算されたニューロンの活動をaix、yで表すと、応答正規化活動bix、yは次式で与えられます。
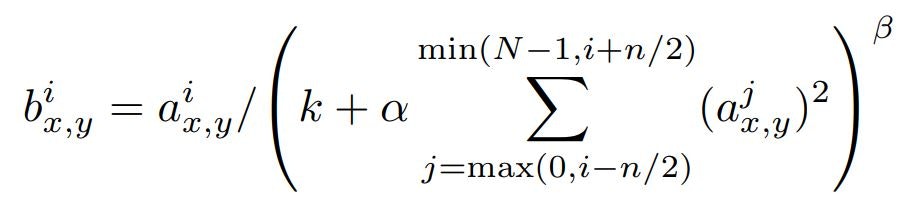
ここで、合計は、同じ空間位置でn個の「隣接する」カーネルマップにまたがります。Nは、レイヤ内のカーネルの総数です。カーネルマップの順序はもちろん任意であり、トレーニングが始まる前に決定されます。この種の応答正規化は、実際のニューロンに見られるタイプに着想を得た横方向抑制の形式を実装しており、異なるカーネルを使用して計算されたニューロン出力間で大きな活動の競合を引き起こします。定数k、n、α、およびβは、値が検証セットを使用して決定されるハイパーパラメータです。我々はk=2、n=5、α=10の-4乗、そしてβ=0.75を使用した。特定のレイヤにReLUの非線形性を適用した後で、この正規化を適用しました(3.5節を参照)。このスキームは、Jarrettらの局所コントラスト正規化スキームといくらか似ています。しかし、我々は平均輝度を差し引かないので、我々はより正確に「明るさ正規化」と呼ばれるでしょう。応答正規化により、トップ1とトップ5のエラー率はそれぞれ1.4%と1.2%減少します。また、CIFAR-10データセットに対するこの方式の有効性を検証しました。4層のCNNでは、正規化なしで13%、正規化ありで11%のテストエラー率を達成しました。
3.4 Overlapping Pooling(重複プーリング)
CNNのプーリングレイヤは、同じカーネルマップ内の隣接するニューロングループの出力をまとめたものです。慣習的に(伝統的に)、隣接するプーリング単位によってサマライズされた近傍は重なリません。より正確には、プールリング層は、それぞれがプール単位の位置を中心とするサイズz×zの近傍を要約する、sピクセル間隔で配置されたプールリング単位の格子からなると考えることができます。s=zと設定すると、CNNで一般的に使用されているような従来のローカルプーリングが得られます。s<zに設定すると、重複プーリングが得られます。これは、我々のネットワーク全体でs=2(スライド2×2)とz=3(プーリングウィンドウサイズ3×3)を使用した方法です。この方式では、オーバーラップしない方式s=2(スライド2×2)、z=2(プーリングウィンドウサイズ2×2)と比較して、上位1と上位5のエラー率がそれぞれ0.4%と0.3%減少します。これは同次元の出力を生成します。重複プーリングのモデルでは、過学習しづらいことがトレーニング中に一般的に観察されました。
3.5 Overall Architecture(全体の構造)
これで、CNNの全体的なアーキテクチャを説明する準備が整いました。図2に示すように、ネットには重み付きの8つのレイヤーが含まれています。最初の5つは畳み込みで、残りの3つは全結合されています。最後の全結合層の出力は、1,000クラスのラベルにわたって分布を生成する1,000方向のソフトマックスに供給されます。我々のネットワークは、多項ロジスティック回帰の目的関数を最大にすることです。これは、予測分布の下で正しいラベルの対数確率のトレーニングケースにわたる平均を最大にすることと同じです。
2番目、4番目、5番目の畳み込み層のカーネルは、同じGPU上にある前の層のカーネルマップにのみ接続されています(図2を参照)。3番目の畳み込み層のカーネルは、2番目の層のすべてのカーネルマップに接続されています。全結合層のニューロンは、前の層のすべてのニューロンに接続されています。応答正規化レイヤは、1番目と2番目の畳み込みレイヤの後に続きます。3.4節で説明した種類の最大プーリング層は、応答正規化レイヤと5番目の畳み込みレイヤの両方で実施されます。ReLUの非線形性は、すべての畳み込み層と全結合層の出力に適用されます。
第1の畳み込み層は、4ピクセルのストライド(これは、カーネルマップ内の隣接ニューロンの受容野中心間の距離である)を有するサイズ11×11×3の96個のカーネルで、224×224×3入力画像をフィルタリングします。第2の畳み込み層は、入力として第1の畳み込み層の(応答正規化されプールされた)出力を受け取り、それをサイズ5×5×48の256個のカーネルでフィルタリングします。第3、第4、および第5の畳み込み層は互いに接続されません。介在するプール層または正規化層。第3の畳み込み層は、第2の畳み込み層の(正規化されプールされた)出力に接続された3×3×256のサイズの384個のカーネルを有します。第4の畳み込み層は、サイズ3×3×192の384個のカーネルを有し、第5の畳み込み層は、サイズ3×3×192の256個のカーネルを有します。全結合層は、それぞれ4,096個のニューロンを有します。
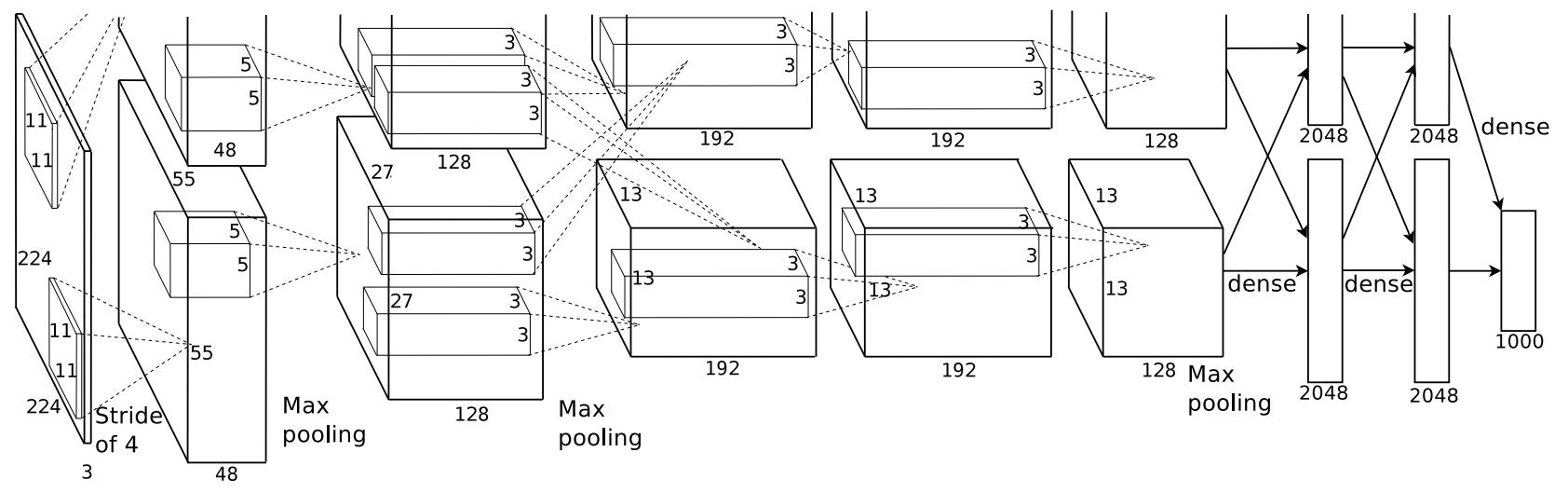
**図2:**CNNのアーキテクチャの図。2つのGPU間の責任の概要を明確に示しています。 1つのGPUが図の上部のレイヤ部分を実行し、もう1つが下部のレイヤ部分を実行します。GPU間は特定のレイヤでのみ通信します。ネットワークの入力は150,528次元であり、ネットワークの残りの層にあるニューロンの数は253,440–186,624–64,896–64,896–43,264–4096–4096–1000で与えられます。
4 Reducing Overfitting(過学習の減少)
私たちのニューラルネットワークアーキテクチャには6,000万のパラメータがあります。1,000クラスのILSVRCでは、各トレーニングサンプルで画像からラベルへのマッピングに10ビットの制約が課せられていますが、これは、相当な過学習なしに、非常に多くのパラメータを学習するには不足していることが分かります。以下では、私たちが過学習と闘った2つの主な方法について説明します。
4.1 Data Augmentation(データ拡張)
画像データの過学習を減らすための最も簡単で最も一般的な方法は、ラベル保存変換(label-preserving transformations)を使用してデータセットを人為的に増大することです。2つの異なる形式のデータ拡張を採用しています。どちらも、元の画像から変換された画像を非常に少ない計算量で生成できるため、変換された画像をディスクに保存する必要はありません。私たちの実装では、GPUが前のバッチの画像についてトレーニングしている間に、変換された画像はCPU上のPythonコードで生成されます。そのため、これらのデータ拡張方式は、事実上、計算コストはかかりません。
データ増強の第1の形態は、画像の並行移動と水平方向の反射を生成することからなる。これを行うには、256×256の画像からランダムな224×224※の切れ端(およびそれらの水平方向の反射)を抽出し、これらの抽出された切れ端でネットワークをトレーニングします。結果として得られるトレーニングサンプルは、もちろん相互依存性が高いですが、これによりトレーニングセットのサイズが2,048倍に増加します。この方式がなければ、私たちのネットワークはかなりの過学習に陥り、私たちはるかに小さなネットワークを使わざるをえなかったでしょう。テスト時に、ネットワークは5つの224×224部分(4つのコーナー断片と中央の断片)とそれらの水平反射(したがって全部で10個の画像)を抽出し、ネットワークのsoftmaxレイヤによって行われた10つの画像の予測値を平均した値を予測値とします。(※これが、図2の入力画像が224×224×3次元の理由です)
データ増強の第2の形態は、トレーニング画像中のRGBチャンネルの強度を変えることからなリます。具体的には、ImageNetトレーニングセット全体を通して、RGBピクセル値のセットに対してPCA(主成分分析)を実行します。各トレーニング画像に、対応する固有値に次の式から得られた確率変数を掛けたものに比例した大きさで、見つかった主成分の倍数を追加します。平均ゼロ、標準偏差0.1のガウス分布。 それ故、各RGB画像画素Ixy=[IRxy、IGxy、IBxy]Tに次の量を加える。
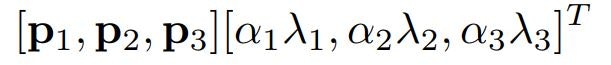
ここで、piとλiはそれぞれRGB画素値の3×3共分散行列のi番目の固有ベクトルと固有値であり、αiは前述の確率変数です。各αiは、特定のトレーニング画像のすべてのピクセルについてその画像が再度トレーニングに使用されるまで一度だけ描画され、その時点でその画像は再描画される。この方式は、自然画像の重要な特性、すなわち、オブジェクトの同一性が照明の強度および色の変化に対して不変であるということをほぼ捉えている。この方式では、トップ1のエラー率が1%以上減少します。
4.2 Dropout(ドロップアウト)
多くの異なるモデルの予測を組み合わせることはテストエラーを減らすための非常に成功した方法ですが、すでに訓練するのに数日かかる大きなニューラルネットワークにとってはあまりにも費用が掛かります。ただし、トレーニング中に約2倍のコスト増だけで済む、非常に効率的なモデルの組み合わせがあります。ドロップアウトと呼ばれる最近導入された技術は、確率50%で各隠れニューロンの出力をゼロに設定することから成ります。このようにして「ドロップアウト」されたニューロンは、フォワードパスに寄与せず、バックプロパゲーションにも関与しません。そのため、入力が提示されるたびに、ニューラルネットワークは異なるアーキテクチャをサンプリングしますが、これらすべてのアーキテクチャは重みを共有します。ニューロンは特定の他のニューロンの存在に頼ることができないので、この技術はニューロンの複雑な共適応を減少させる。それゆえ、それは他のニューロンの多くの異なるランダムサブセットと共に有用であるよりロバストな特徴を学ぶことを余儀なくされている。テスト時には、すべてのニューロンを使用しますが、それらの出力に0.5を掛けます。これは、指数関数的に多数のドロップアウトネットワークによって生成された予測分布の幾何平均をとるための合理的な近似です。
図2にある、最初の2つの全結合層でドロップアウトを使用します。ドロップアウトがなければ、私たちのネットワークはかなりの過学習となってしまいます。ドロップアウトは、収束に必要なイテレーション回数をおよそ2倍にします。
5 Details of learning(学習の詳細)
私たちは、サンプルバッチサイズ128、モーメンタム0.9、および0.0005の荷重減衰で、確率的勾配降下法を使用してモデルをトレーニングしました。モデルが学ぶためには、この少量の荷重減衰が重要であることがわかりました。言い換えれば、ここでの荷重減衰は単なる正則化ではありません。それはモデルのトレーニングエラーを減らします。重みwの更新ルールは
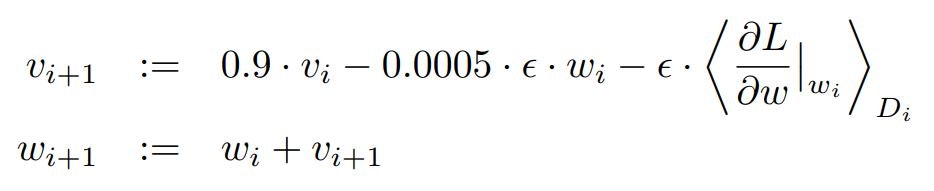
ここで、iはイテレーション指標、vはモーメント変数、εは学習率、そして<∂L/∂w |wi>はwiで評価された、wに関する目的の導関数のi番目のバッチDiにわたる平均である。
標準偏差0.01でゼロ平均ガウス分布から各層の重みを初期化しました。2番目、4番目、5番目の畳み込み層、および全結合隠れ層のニューロンバイアスを定数1で初期化しました。この初期化により、ReLUに正の入力を提供することで学習の初期段階が加速されます。残りの層のニューロンバイアスを定数0で初期化しました。
私たちはすべての層に同じ学習率を使用しましたが、これはトレーニングを通して手動で調整しました。我々が従った発見的方法は、バリデーションエラー率において、現時点の学習率で改善がなされなくなったときに、学習率を10で割ることでした。学習率は0.01に初期化され、訓練が終了する前までに3回減少した。2台のNVIDIA GTX 580 3GB GPUで5〜6日かかった120万枚の画像を使用して、ネットワークを約90サイクルトレーニングしました。
6 Results(結果)
ILSVRC-2010に関する当社の結果を表1にまとめています。我々のネットワークは、37.5%および17.0%5というトップ1およびトップ5のテストセットエラー率を達成しています5。ILSVRC-2010の競技期間中に達成された最高のパフォーマンスは、異なる特徴について学習した6つのスパースコーディングモデルから生成された予測を平均したアプローチで47.1%と28.2%であり、それ以来の最高の公表結果は、2種類の密にサンプリングされた特徴から計算されたFisher Vector(FV)で訓練された2つの分類の予測を平均するアプローチで45.7%と25.7%です。
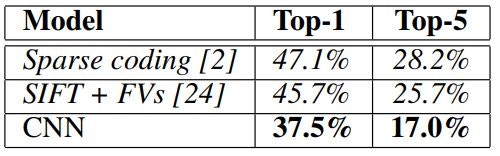
**表1:**ILSVRC2010テストセットの結果の比較 イタリック体で他の人によって達成された最高の結果です。
我々はILSVRC-2012コンペティションにも参加し、結果を表2に報告しました。ILSVRC-2012からテストセットのラベルは公開されていないため、我々がトライしたモデルについてテストエラー率を報告することはできません。この段落の残りの部分では、検証とテストのエラー率は、経験上0.1%以上異ならないため、同じ意味で使用します(表2を参照)。この論文で説明しているCNNは、18.2%というトップ5のエラー率を達成しています。5つの似ているCNNの予測結果を平均すると、16.4%のエラー率が得られます。2011秋にリリース(15M画像、22Kカテゴリ)したImageNet全体を分類するために、最後のプーリング層の上に6番目の畳み込み層を追加した1つのCNNをトレーニングし、それをILSVRC-2012で「ファインチューニング」すると16.6%のエラー率が得られます。前述の5つのCNNを使用して2011年秋のリリース全体で事前トレーニングされた2つのCNNの予測を平均すると、15.3%のエラー率が得られます。2番目に優秀なコンテストのエントリーは、異なる種類の密にサンプリングされた特徴から計算されたFVについてトレーニングされたいくつかの分類器の予測を平均化するアプローチで26.2%のエラー率を達成しました。
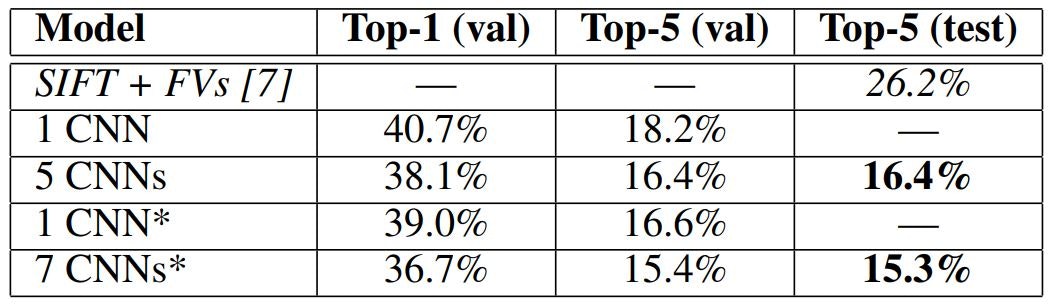
**表2:**ILSVRC-2012検証とテストセットのエラー率の比較。イタリック体で他の人によって達成された最高の結果です。アスタリスク*のモデルは、ImageNet全体を分類するために2011秋リリースされた「事前トレーニング」されたものです。詳細は6章を参照してください。
最後に、2009年秋バージョンのImageNetのエラー率を10,184カテゴリと890万枚の画像で報告します。このデータセットでは、トレーニング用に半分のイメージを使用し、テスト用に半分のイメージを使用するという文献の規約に従います。確立されたテストセットがないので、我々の分割は前の著者によって使用された分割と必然的に異なります、しかしこれは結果にそれほど影響を与えません。このデータセットの上位1と上位5のエラー率は67.4%と40.9%で、上記のネットによって達成されましたが、最後のプーリング層の上に6番目の畳み込み層が追加されています。このデータセットに関する最も公表されている結果は78.1%と60.9%です。
6.1 Qualitative Evaluations(定性評価)
図3は、ネットワークの2つのデータ接続層によって学習された畳み込みカーネルを示しています。ネットワークは、さまざまな色のブロブ(輪郭がぼやけているもの、おぼろげなもの)だけでなく、さまざまな周波数および方向を選択するカーネルを学習しました。3.5節で説明されている制限された接続性の結果として、2つのGPUが示す特殊化・専門家に注目してください。GPU1のカーネルは主に色に依存しませんが、GPU2のカーネルは主に色固有です。この種の特殊化は、すべての実行中に発生し、特定のランダム重み初期化(モジュロGPUの再番号付け)とは無関係です。

**図3:**224×224×3の入力画像によって最初の畳込み層で学習したチャネル11×11×3の96個の畳み込みカーネルを表しています。下段の48個のカーネルがGPU2で学習されている間、GPU1で上段の48個のカーネルが学習された。詳細は6.1節をご覧ください。

図4 :(左)8つのILSVRC-2010テスト画像と、このモデルで最も可能性が高いと考えられた5つのラベル。正しいラベルは各画像の下に書かれており、正しいラベルが割り当てられている場合は赤いバーで表示されます(それが偶然トップ5にある場合)。
(右)最初の列に5つのILSVRC-2010テスト画像。残りの列は、テスト画像の特徴ベクトルから最小のユークリッド距離で最後の隠れ層に特徴ベクトルを生成する6つのトレーニング画像を示しています。
図4の左パネルでは、8つのテスト画像で上位5つの予測を計算することによってネットワークが何を学習したかを定性的に評価します。左上のダニなど、中心を外れたオブジェクトでもネットで認識できることに注意してください。トップ5のラベルのほとんどは妥当と思われます。たとえば、他の種類の猫だけがヒョウのもっともらしいラベルと見なされます。いくつかのケース(グリル、チェリー)では、わざと焦点をずらして、あいまいさを持った写真となっています。
ネットワークの視覚的な知識を精査するもう1つの方法は、最後の4,096次元の隠れ層で画像によって引き起こされた特徴アクティベーションを検討することです。2つの画像が、小さなユークリッド分離で特徴活性化ベクトルを生成する場合、ニューラルネットワークの上位レベルはそれらが類似していると言えます。図4は、テストセットからの5つの画像と、トレーニングセットからこの尺度でそれぞれに最もよく似ている6つの画像を示しています。ピクセルレベルでは、検索されたトレーニング画像は一般に、L2では最初の列のクエリ画像に近くありません。たとえば、取り出された犬や象はさまざまなポーズで登場します。補足資料に、さらに多くのテスト画像の結果を示します。
2つの4,096次元の実数値ベクトル間のユークリッド距離を使用して類似性を計算することは非効率的ですが、これらのベクトルを短いバイナリコードに圧縮するように自動エンコーダをトレーニングすることによって効率的になります。これは生のピクセルにオートエンコーダを適用するよりもはるかに優れた画像検索方法を生成するはずであり、これは画像ラベルを利用せず、したがってそれらが意味論的にであろうとなかろうと類似のエッジパターンを持つ画像を検索する傾向があります。
7 Discussion(ディスカッション)
我々の結果は、大規模で深い畳み込みニューラルネットワークが純粋に監視された学習を使用して非常に挑戦的なデータセット上で記録破りの結果を達成することができることを示しています。単一の畳み込みレイヤを削除すると、ネットワークのパフォーマンスが低下することは注目に値します。たとえば、中間層を削除すると、ネットワークのトップ1のパフォーマンスで約2%の損失が発生します。だから深さは私たちの結果を達成するために本当に重要です。
実験を簡単にするために、特にラベル付きデータ量の対応する増加を得ることなくネットワークのサイズを大幅に増加させるのに十分な計算能力を得る場合、それが役立つと期待しても教師なし事前訓練を用いなかった。これまでのところ、私たちのネットワークをより大きくし、それをより長く訓練するにつれて、私たちの結果は改善されましたが、人間の視覚システムの時空間の経路に合わせるためにはまだ何桁もあります。究極的には、静止画像では明らかではなく、または欠落している、非常に有用な情報を提供するビデオシーケンス(=連続画像データ)において、非常に大きくて深い畳み込みネットを使用したいと思います。
ここまでが論文の翻訳となります。
私自身が感じたこと
・この論文は過学習との闘いを綴ったものでした。
・活性化関数ReLUは、tanhよりも数倍高速に学習可能であること。
・パディングについて言及されていないことが気になりました。
・最後の結論で述べていることが、未来が見えている感じがします。この後に、YOLOやSSDなどのビデオシーケンスの物体検出などの手法が登場してきます。
・重複プーリングでやった方が(若干ですが)精度も良くなるし、過学習にも効果があるのであれば、今のデファクトスタンダードは重複プーリングになっていても良さそうなものですが、Kerasデフォルトはストライドがpool_sizeである。
keras.layers.MaxPooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)
# strides: ストライド値.2つの整数からなるタプル,もしくはNoneで指定します. Noneの場合は,pool_sizeの値が適用されます
参考
🔹画像解析関連コンペティションの潮流
http://www.nlab.ci.i.u-tokyo.ac.jp/pdf/ieice201705cvcomp.pdf
🔹Imagenetのサイト
http://image-net.org/index
🔹畳み込みニューラルネットワークの研究動向
https://www.slideshare.net/ren4yu/ss-84282514