データサイエンティストとして、ガムシャラにやってきたことを振り返り、整理していきたいと思う。
実際の実データは扱わないが、アウトプットを出すために学んできたことを書き出していく。
まずは、xgboostを扱いたいが、そもそもアンサンブル学習から。(xgboostはアンサンブル学習の1種)
予測課題に対して、xgboostは万能な手法。
アンサンブル学習とは
予測課題をデータで解決したい時に、複数の学習器を組み合わせて精度を上げて、1つの学習器を作成することである。
1つに学習器だけで作成するのではなく、その結果を踏まえながら学習器を作成したり、いくつかの学習器を総合して作成するので精度はあがっていくよね。という考え。大きく3つに分類できる。その前に基礎知識。
バイアスとバリアンス
バイアス‥実際の値と予測の値の平均
バリアンス‥予測値がどれだけ散らばっているかの度合い
④が、低バイアスであり低バリアンスなので精度が良い状態。
③は、高バリアンスの状態。モデルは過学習をしている可能性が高い。新しいデータを使って予測した場合に精度が悪くなる傾向にある。
②は、高バイアスの状態。そもそもデータに対して学習ができていない可能性が高い。
 図がとてもわかりやすいので、参考のページにある図をお借りします。
[機械学習上級者は皆使ってる?!アンサンブル学習の仕組みと3つの種類について解説します]
(https://www.codexa.net/what-is-ensemble-learning/)
図がとてもわかりやすいので、参考のページにある図をお借りします。
[機械学習上級者は皆使ってる?!アンサンブル学習の仕組みと3つの種類について解説します]
(https://www.codexa.net/what-is-ensemble-learning/)
3つの手法
バギング
一般的にモデルの予測結果のバリアンスを低くする特徴がある。バギングでは、ブーストトラップ法を用いて学習データを復元抽出することによってデータセットに多様性を持たせている。復元抽出とは、一度抽出したサンプルが再び抽出の対象になるような抽出方法。
それぞれの結果を集約して、1つの学習器を作成する。回帰だったら平均値、分類だったら多数決で決まる。
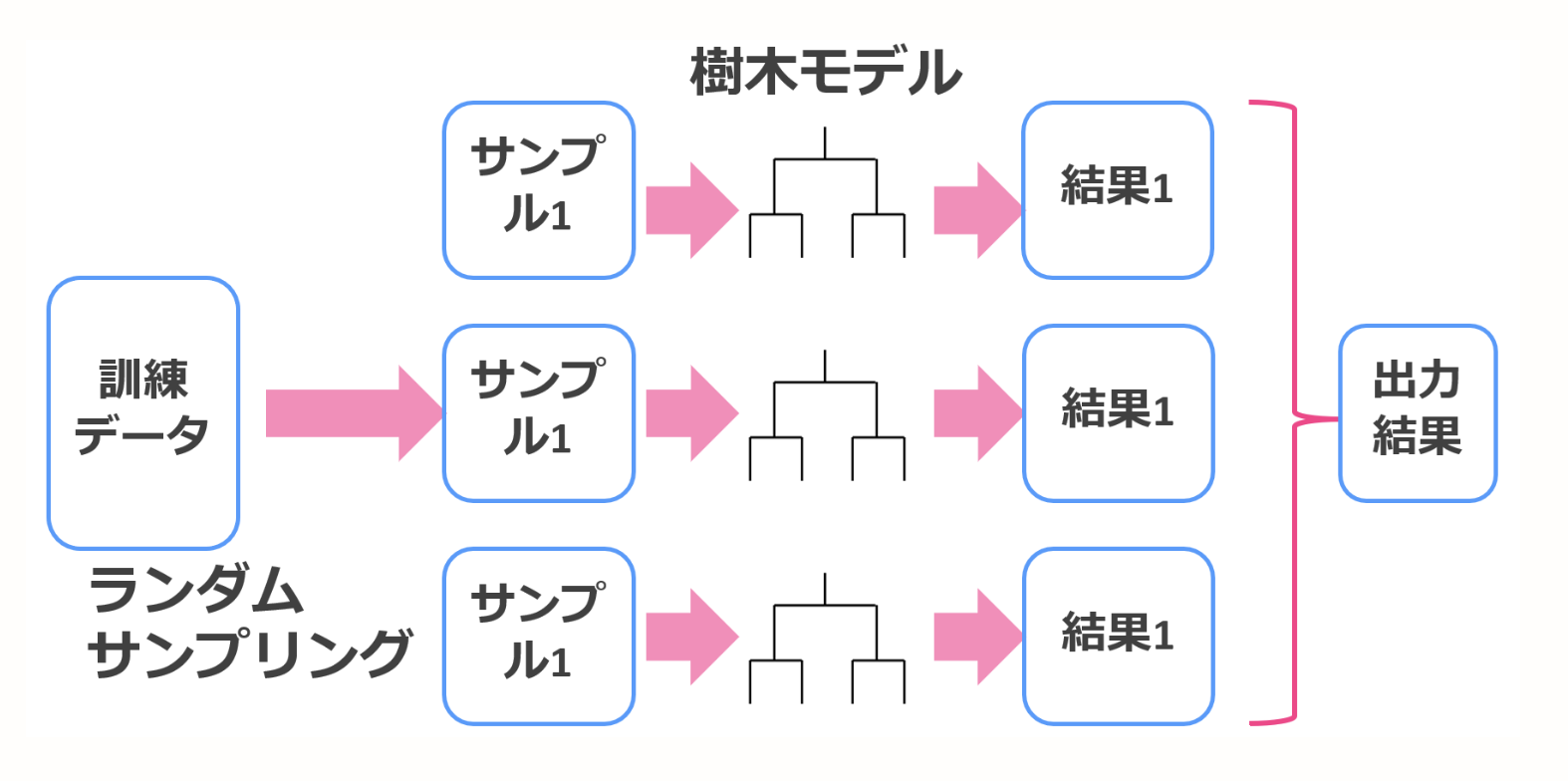 図がとてもわかりやすいので、参考のページにある図をお借りします。
[アンサンブル学習とは?バギングとブースティングの違い](https://toukei-lab.com/ensemble)
図がとてもわかりやすいので、参考のページにある図をお借りします。
[アンサンブル学習とは?バギングとブースティングの違い](https://toukei-lab.com/ensemble)
ブースティング
一般的にモデルの予測精度に対してバイアスを下げる特徴がある。ブースティングは基本となるモデルを最初に訓練してベースラインを設ける。このベースラインとした基本モデルに対して何度も反復処理を行い精度を改善していく。基本モデルの間違った予測に焦点を当てて「重み」を加味して次のモデルを改善していく。モデルを作って間違いを加味した新しいモデルを作る。最終的に全てをまとめる。xgboostはこのブースティングを利用した実装。
最初のモデルを加味しながらのせいか、学習に時間がかかる。
 図がとてもわかりやすいので、参考のページにある図をお借りします。
[アンサンブル学習とは?バギングとブースティングの違い](https://toukei-lab.com/ensemble)
図がとてもわかりやすいので、参考のページにある図をお借りします。
[アンサンブル学習とは?バギングとブースティングの違い](https://toukei-lab.com/ensemble)
スタッキング
モデルを積み上げていく方法。バイアスとバリアンスを調整して組み込むことが可能らしい...
複雑だったので、割愛。
勾配ブースティング(Gradient Boosting)
ある関数、損失関数を定義したときに損失を最小化する方向を探すことで学習するモデル。
数式でイメージをもっておく。
損失関数
予測値と実績値がどれくらいか、差分があるかを判断するためにある指標を(=関数)を使う。
その指標が最小になるようにモデルのパラメータを動かしていく。
XGBoostの損失関数は、以下。

予測値と目的値の誤差の合計に正則化項を足したもの。
2つ目の式は正則化項を表す。回帰木の重みwがあることで、損失関数の最小化時にwによって考慮され、過学習になることを防ぐ。
各変数の説明は以下。

関数最適化
損失関数が出来上がったので、あとは損失関数を最適化するだけです。
上記損失関数を変形してwで微分すると

となる。
この式を0とした時のwが、損失関数を最小化する。(高校数学レベル)

となる。
これを近似した損失関数に代入すると最小の損失値が求まる。
ここで、XGBoostの構造をq。
これがxgboostを評価する数式。
サンプルを動かす
乳がんデータセットを使う。
import xgboost as xgb
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
def main():
# 乳がんデータセットの読み込み
dataset = datasets.load_breast_cancer()
X, y = dataset.data, dataset.target
# 学習用と検証用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
shuffle=True,
random_state=42,
stratify=y)
# データセットの形式を変更
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# 学習用のパラメータ
xgb_params = {
# 二値分類
'objective': 'binary:logistic',
# 評価指標
'eval_metric': 'logloss',
}
# xgboostによる学習を行う
bst = xgb.train(xgb_params,
dtrain,
num_boost_round=100,
)
# 検証用データで計算
y_pred_proba = bst.predict(dtest)
# 閾値 0.5 で 0, 1 に変換
y_pred = np.where(y_pred_proba > 0.5, 1, 0)
# 精度をみる
acc = accuracy_score(y_test, y_pred)
print('Accuracy:', acc)
if __name__ == '__main__':
main()
結果
acc: 0.96
まとめ
xgboostは、ブースティングによってモデルの作成と学習、学習時に勾配情報でパラメータを決定し更新していくモデル。
参考
機械学習上級者は皆使ってる?!アンサンブル学習の仕組みと3つの種類について解説します
アンサンブル学習とは?バギングとブースティングの違い
XGBoostのアルゴリズムを論文を読んで解説