類似画像について書き残したいが、まずはK-NN法の説明から。
K-NN法
あるデータから近いデータk個のデータから識別していく。
数が多いものデータのクラスと同じクラスと判断していく。
ex)
k=3の場合、四角1個と三角2個のため、三角のグループとみなす。
k=5の場合、四角3個と三角2個のため、四角のグループとみなす。

どのkをとるかによって、解はバラバラなので適切なkを見つける必要がある。
crossvalidationを使い、k毎の汎化誤差を求めて、最小のものを最適なkとする。
汎化誤差(=テストデータによる実績との誤差)
これらを全てk毎の計算をするのは、画像によるベクトル変換をした時膨大な処理時間となる。
そこで、近似最近傍検索。
近似最近傍検索
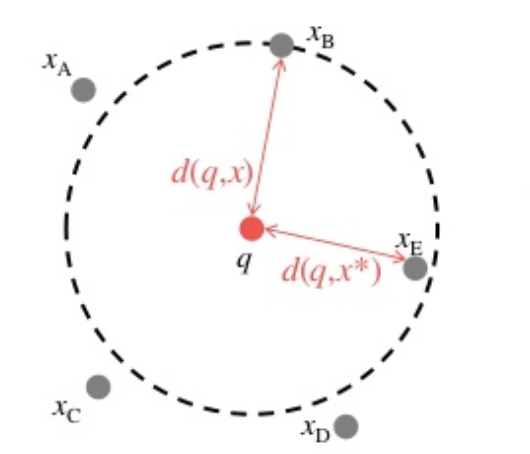
最近傍が遠くても、許容して採用する。
d(q,x) <= (1+ε)d(q,x)*
d(q,x) が近似解までの距離
d(q,x*)が最近傍までの距離
近似解は、最良優良探索で決める
最良優良探索は、何らかの規則に従って次に探索する最も望ましいノードを選択するようにした探索アルゴリズム。
 # サンプルを動かしてみる
データセットには Iris データセットを使う。
# サンプルを動かしてみる
データセットには Iris データセットを使う。
pip install annoy scikit-learn
from collections import Counter
from sklearn import datasets
from annoy import AnnoyIndex
from sklearn.base import BaseEstimator
from sklearn.base import ClassifierMixin
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_validate
from sklearn.utils import check_X_y
from sklearn.utils import check_array
class AnnoyClassifier(BaseEstimator, ClassifierMixin):
#近似最近傍検索モデル作成部分、ここが肝。
def __init__(self, n_trees, metric='angular', n_neighbors=1, search_k=-1):
# k-d tree の数
self.n_trees_ = n_trees
# 計算に用いる距離
self.metric_ = metric
# 近傍数
self.n_neighbors_ = n_neighbors
# 精度に使われるパラメータ
self.search_k_ = search_k
# モデル
self.clf_ = None
# 学習データのクラスラベルをつける
self.train_y_ = None
def fit(self, X, y):
# 入力部分
check_X_y(X, y)
# 学習データのクラスラベルを保存しておく
self.train_y_ = y
# Annoy のモデルを用意する
self.clf_ = AnnoyIndex(X.shape[1], metric=self.metric_)
# 学習させる
for i, x in enumerate(X):
self.clf_.add_item(i, x)
# k-d tree部分
self.clf_.build(n_trees=self.n_trees_)
return self
def predict(self, X):
check_array(X)
# 結果を返す
y_pred = [self._predict(x) for x in X]
return y_pred
def _predict(self, x):
# 近傍を見つける
neighbors = self.clf_.get_nns_by_vector(x, self.n_neighbors_, search_k=self.search_k_)
# インデックスをクラスラベルに変換する
neighbor_classes = self.train_y_[neighbors]
# 最頻値を取り出す
counter = Counter(neighbor_classes)
most_common = counter.most_common(1)
# 最頻値のクラスラベルを返す
return most_common[0][0]
def get_params(self, deep=True):
# 分類器のパラメータ
return {
'n_trees': self.n_trees_,
'metric': self.metric_,
'n_neighbors': self.n_neighbors_,
'search_k': self.search_k_,
}
def main():
# Iris データセットを読み込み
dataset = datasets.load_iris()
X, y = dataset.data, dataset.target
# 分類器
clf = AnnoyClassifier(n_trees=10)
# 3-fold CV
skf = StratifiedKFold(n_splits=3, shuffle=True, random_state=42)
# 精度を評価指標にして汎化性能を計測する
score = cross_validate(clf, X, y, cv=skf, scoring='accuracy')
mean_test_score = score.get('test_score').mean()
print('acc:', mean_test_score)
if __name__ == '__main__':
main()
結果
acc: 0.98
参考
[機械学習_k近傍法_理論編]
(https://dev.classmethod.jp/machine-learning/2017ad_20171218_knn/#sec4)