1. はじめに
pandas.DataFrameをExcelのようにGUIで扱えたら便利だと思いませんか?
なんとStreamlitではできてしまうみたいです。
まだexperimentalな機能ですが、とても気になったので試してみました。
2. まずはお試し
こんな感じのコードを書きます。
import streamlit as st
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(12).reshape(4, 3),
columns=(f"col{i+1}" for i in range(3)))
edited_df = st.experimental_data_editor(df)
st.line_chart(edited_df)
これを実行してみると編集できました!
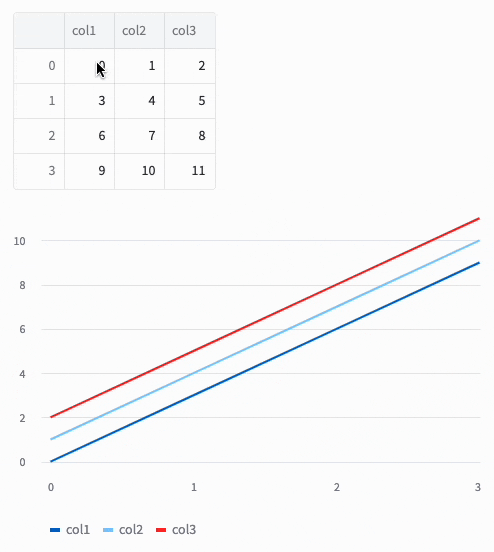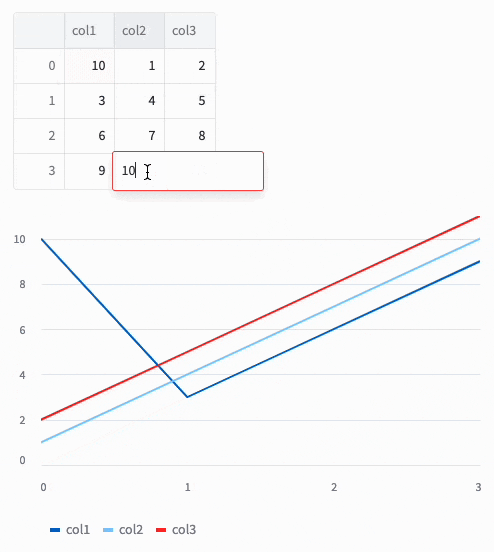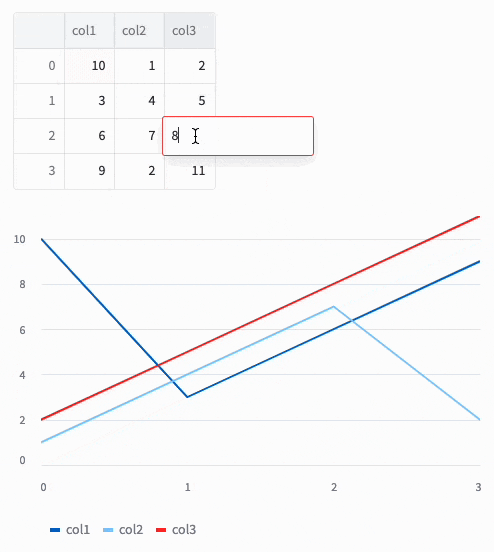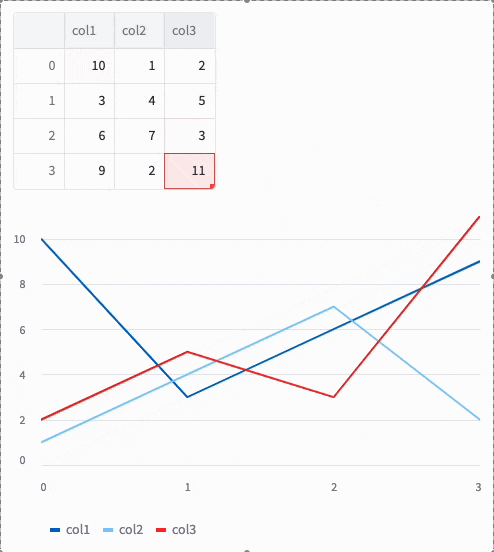
Command+v もしくは Ctrl+vでExcelのデータも貼り付けられます。

3. ドキュメントの確認
st.experimental_data_editorのドキュメントはこちらです。
Function signatureを見ると
st.experimental_data_editor(data, *, width=None, height=None, use_container_width=False, num_rows="fixed", disabled=False, key=None, on_change=None, args=None, kwargs=None)
となっていて、指定できる引数はたくさんあります。引数と戻り値を順番に見てみます。
3.1 引数
data
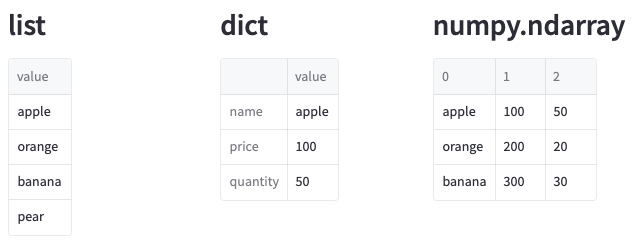
編集するデータです。渡せるデータはpandas.DataFrameだけではなく、Pyspark DataFrameやリストなども渡せます。
渡せるデータの種類はst.dataframeと同じですが、いくつか確認したコードと実行結果は以下です。
import streamlit as st
import numpy as np
col1, col2, col3 = st.columns(3)
with col1:
st.header('list')
st.experimental_data_editor(
['apple', 'orange', 'banana', 'pear']
)
with col2:
st.header('dict')
st.experimental_data_editor({
"name": "apple",
"price": 100,
"quantity": 50
})
with col3:
st.header('numpy.ndarray')
st.experimental_data_editor(
np.array([
["apple", 100, 50],
["orange", 200, 20],
["banana", 300, 30]
])
)
width
表示される表の幅をピクセルで指定します。指定しない場合はデフォルトのNoneが使われて幅は自動的に決まります。
height
表示される表の高さをピクセルで指定します。指定しない場合はデフォルトのNoneが使われて高さは自動的に決まります。
widthとheightを指定したときのコードと実行結果は以下です。
import streamlit as st
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(12).reshape(4, 3),
columns=(f"col{i+1}" for i in range(3)))
col1, col2 = st.columns(2)
col3, col4 = st.columns(2)
with col1:
st.header('width=100')
st.experimental_data_editor(df, width=100)
with col2:
st.header('height=100')
st.experimental_data_editor(df, height=100)
with col3:
st.header('width=100, height=100')
st.experimental_data_editor(df, width=100, height=100)
with col4:
st.header('width=None, height=None')
st.experimental_data_editor(df)

指定した幅や高さに収まらないときはスクロールバーが表示されます。
use_container_width
Trueを指定すると表の幅が親コンテナの幅に設定されます。widthが指定されていてもuse_container_widthの方が優先されます。何も指定しない場合はデフォルトのFalseになります。
use_container_widthを試したコードと実行結果は以下です。
import streamlit as st
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(12).reshape(4, 3),
columns=(f"col{i+1}" for i in range(3)))
st.header('use_container_width=False')
st.experimental_data_editor(df)
st.header('use_container_width=True')
st.experimental_data_editor(df, use_container_width=True)
st.header('width=100, use_container_width=True')
st.experimental_data_editor(df, width=100, use_container_width=True)

num_rows
fixedもしくはdynamicを指定します。dynamicを設定すると行の追加や削除ができるようになります。何も指定しない場合はデフォルトのfixedになります。
dynamicを指定したときのコードと実行結果は以下です。
import streamlit as st
import pandas as pd
df = pd.DataFrame([
["apple", 100, 50],
["orange", 200, 20],
["banana", 300, 30]
], columns=["name", " price", "quantity"])
st.experimental_data_editor(df, num_rows="dynamic")
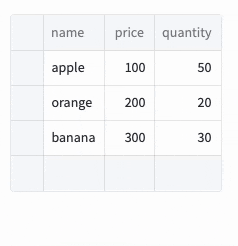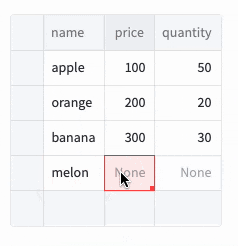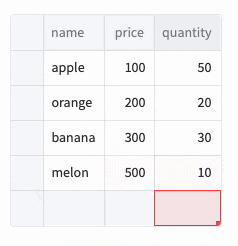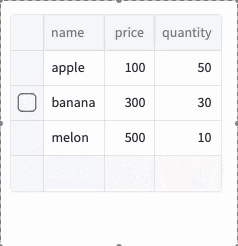
表内の+を押すと行が追加され、Deleteキーで行が削除されます。
disabled
Trueを指定すると編集ができなくなります。何も指定しない場合はデフォルトのFalseになります。
key
Session Stateに登録するキーです。Session Stateを使うとどのセルが変更されたかを確認できます。
試したコードと実行結果は以下です。
import streamlit as st
import pandas as pd
df = pd.DataFrame([
["apple", 100, 50],
["orange", 200, 20],
["banana", 300, 30]
], columns=["name", " price", "quantity"])
st.experimental_data_editor(df, num_rows="dynamic", key="fruits")
st.write(st.session_state["fruits"])

on_change
データが更新されたときに呼び出す関数を指定します。
試したコードと実行結果は以下です。
import streamlit as st
import pandas as pd
def df_callback():
st.session_state["count"] += 1
if "count" not in st.session_state:
st.session_state["count"] = 0
df = pd.DataFrame([
["apple", 100, 50],
["orange", 200, 20],
["banana", 300, 30]
], columns=["name", " price", "quantity"])
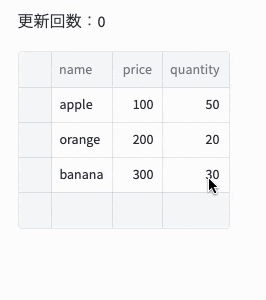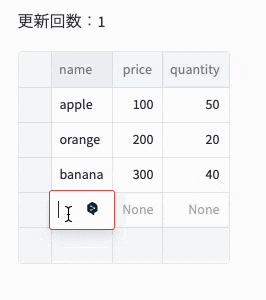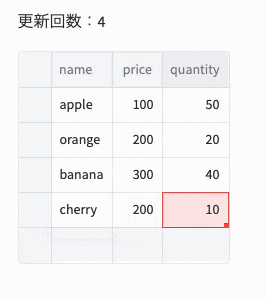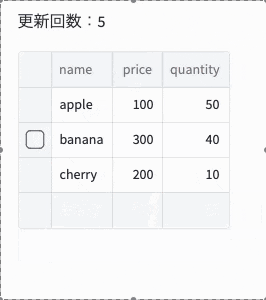
st.write(f"更新回数:{st.session_state['count']}")
st.experimental_data_editor(df, num_rows="dynamic", on_change=df_callback)
args, kwargs
2つまとめてしまいますが、どちらもon_changeで呼び出すコールバック関数へ渡す引数です。argsはタプルで、kwargsは辞書です。
3.2 戻り値
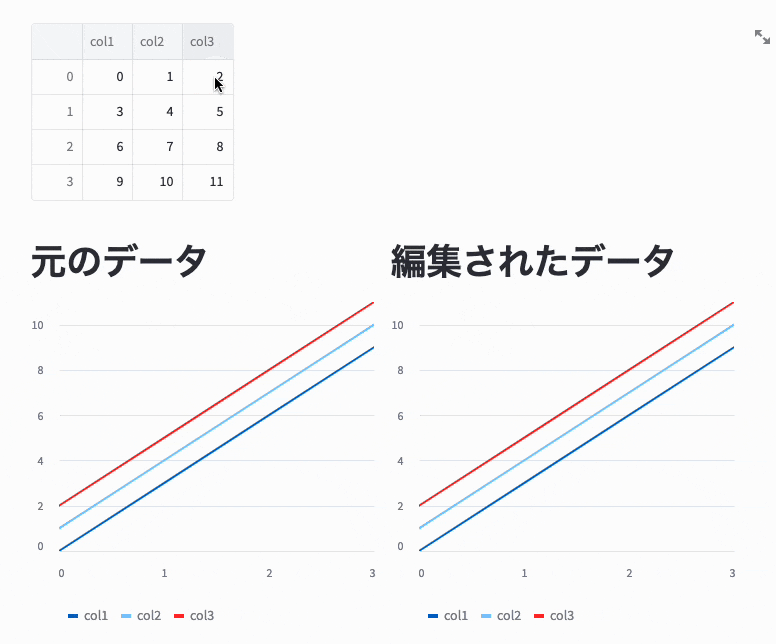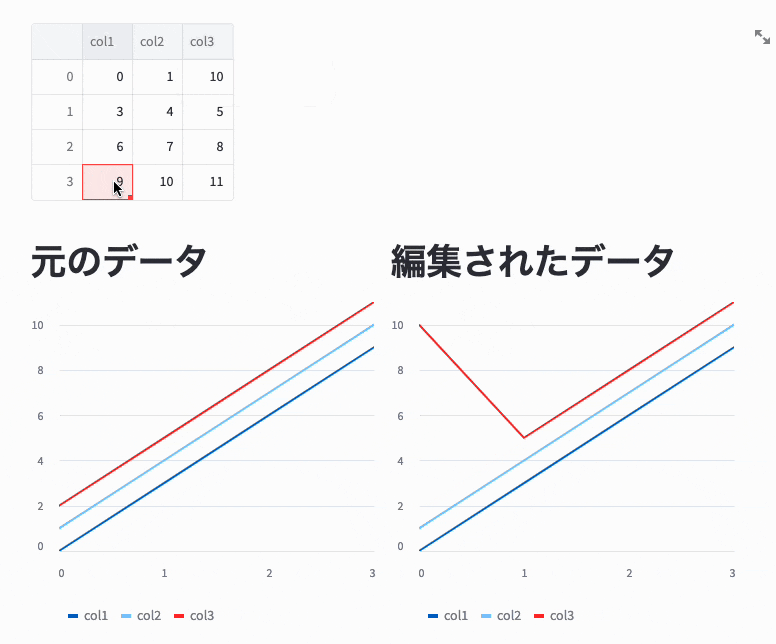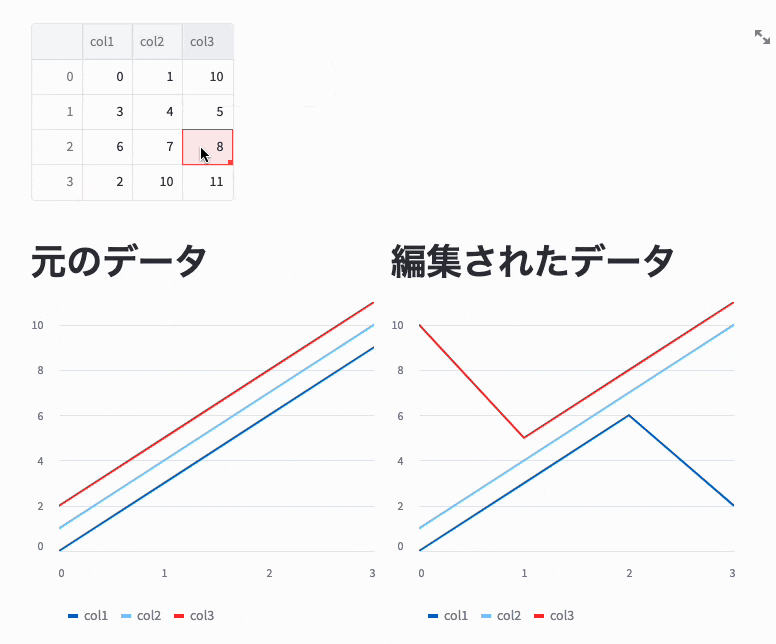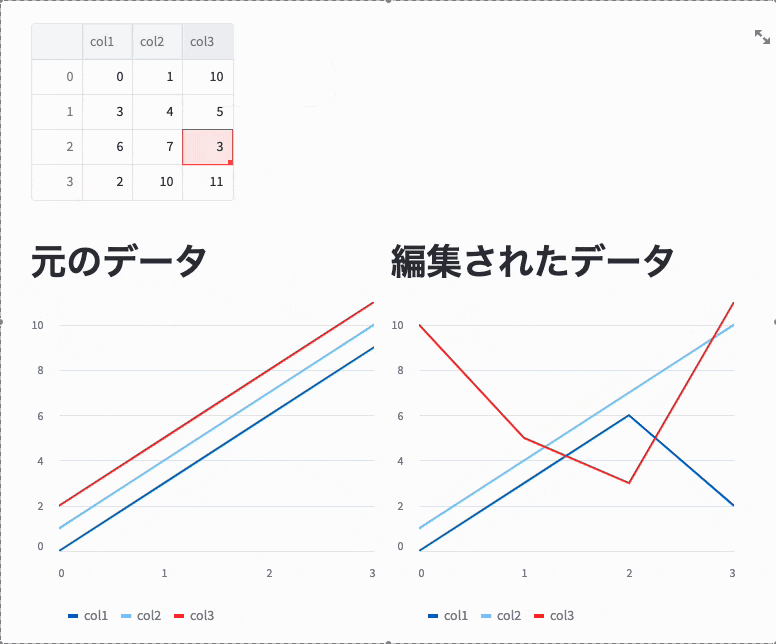
戻り値は編集されたデータで、引数で渡したデータとは別物です。
以下のコードの実行結果を見るとわかりますが、左側のグラフはst.line_chartに元のDataFrameを渡しているためグラフは変更されていませんが、右側のグラフはst.experimental_data_editorの戻り値をst.line_chartに渡しているため、値が変更されたときにグラフも変更されています。
import streamlit as st
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(12).reshape(4, 3),
columns=(f"col{i+1}" for i in range(3)))
edited_df = st.experimental_data_editor(df)
col1, col2 = st.columns(2)
with col1:
st.header('元のデータ')
st.line_chart(df)
with col2:
st.header('編集されたデータ')
st.line_chart(edited_df)
4. まとめ
この記事の執筆時点(2023/03/22)ではexperimentalな機能なため、今後どのようになるかはわかりませんが、とても良い機能だと思いました。
そして、冒頭で紹介したブログ記事には、これからもっと新機能が実装される予定とあります。これは期待大ですね!
仲間募集中!
NTTデータ Data&Intelligence事業部 では、以下の職種を募集しています。
1. 「クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)」の募集
クラウド/プラットフォーム技術の知見に基づき、ITアーキテクトまたはPMとして、DWH、BI、ETL領域における、ソリューション開発の推進や、コンサルティング工程のシステムグランドデザイン策定時におけるアーキテクト観点からの検討を行う人材を募集しています。2. AI/データ活用を実践する「クラウド・ソリューションアーキテクト」
AI/データ活用を実践する「クラウド・ソリューションアーキテクト」として、クラウド先進テクノロジーを積極活用し、お客様のビジネス価値創出活動を実践。AI/データ活用の基本構想立案コンサルティングからクラウドプラットフォーム提供・活用を支援しています。お客様のAI・データ活用を支援するクラウド・ソリューション提案、アーキテクチャ設計・構築・継続活用支援(フルマネージドサービス提供)、および最新クラウドサービスに関する調査・検証で、クラウド分析基盤ソリューションのメニュー拡充を実施する人材を募集します。また、取り扱う主なソリューションについては、以下のページも参照ください。
ソリューション紹介
1. NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。2. Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。