はじめに
元AI女子高生「りんな」をご存知でしょうか![]()
LINEに突如現れたAI女子高生で話題となっていたと思いますので、ご存知の方も多いかとおもいます。
先日「りんな」の開発元であるrinna社から日本語特化の学習がされたGPT-2モデルが 商用利用可能なMITライセンス で公開されました。
rinna、人間の評価を利用したGPT言語モデルの強化学習に成功
本モデルは、 ChatGPTに用いられている学習手法である、人間の評価を利用したGPT言語モデルの強化学習に成功している とのことです。
かつ ローカル環境でも動作する ようです。
本記事では、その対話GPT言語モデルの動作を見てみようと思う![]()
目次
動作環境
- 検証環境
- google colaboratory(Colab Pro版)
- ローカル検証環境
- Windows11(WSL2(Ubuntu22.04 LTS))
- CPU:Intel(R) Core(TM) i7-9700
- RAM:16.0 GB
- GPU:NVIDIA GeForce RTX 2060 SUPER
- Windows11(WSL2(Ubuntu22.04 LTS))
モデル動作確認(GoogleColab)
huggingface(※)から対応のモデルであるjapanese-gpt-neox-3.6b-instruction-ppoの利用手順を参考に、まずは確実に動くスペックを持つ、google colaboratory上で簡単に動作を確認してみる。
※huggingfaceはtransformersをベースに機械学習モデルの開発と共有、公開をするためのプラットフォームです。
パッケージのインストール
huggingfaceからダウンロードしたモデルを扱うために追加で必要となるパッケージをインストールする
!pip install transformers sentencepiece
モデルのインストール
PyTorchとTransformersライブラリを使用して、指定されたモデルとトークナイザを読み込み、GPUが利用可能な場合にモデルをGPU上に配置します
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# トークナイザのインストール
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-ppo", use_fast=False)
# modelのインストール
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-ppo")
# モデルをGPU上に配置
if torch.cuda.is_available():
model = model.to("cuda")
プロンプトの生成
公式手順通りに会話から入力を作成する例でプロントを作成します。
prompt = [
{
"speaker": "ユーザー",
"text": "コンタクトレンズを慣れるにはどうすればよいですか?"
},
{
"speaker": "システム",
"text": "これについて具体的に説明していただけますか?何が難しいのでしょうか?"
},
{
"speaker": "ユーザー",
"text": "目が痛いのです。"
},
{
"speaker": "システム",
"text": "分かりました、コンタクトレンズをつけると目がかゆくなるということですね。思った以上にレンズを外す必要があるでしょうか?"
},
{
"speaker": "ユーザー",
"text": "いえ、レンズは外しませんが、目が赤くなるんです。"
}
]
prompt = [
f"{uttr['speaker']}: {uttr['text']}"
for uttr in prompt
]
prompt = "<NL>".join(prompt)
prompt = (
prompt
+ "<NL>"
+ "システム: "
)
print(prompt)
プロントでGPTに指示する内容は下記となります。
対話形式で最後の「システム:」の返答を推論させるような形式となっています。
1. ユーザー: コンタクトレンズを慣れるにはどうすればよいですか?
2. システム: これについて具体的に説明していただけますか?何が難しいのでしょうか?
3. ユーザー: 目が痛いのです。
4. システム: 分かりました、コンタクトレンズをつけると目がかゆくなるということですね。思った以上にレンズを外す必要があるでしょうか?
5. ユーザー: いえ、レンズは外しませんが、目が赤くなるんです。
6. システム:
推論
先ほど作成したプロンプトで推論処理を実行します。
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
max_new_tokens=128,
temperature=0.7,
repetition_penalty=1.1,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
output = output.replace("<NL>", "\n")
print(output)
推論された結果は下記のようになります。(見にくいため改行は手作業で入れてます)
それはコンタクトレンズによる目の刺激が原因である可能性が高いです。
コンタクトレンズを長時間つけないようにしたり、コンタクトレンズを頻繁に外して目を休めたりすることで改善されることがあります。
また、コンタクトレンズを着用したまま寝ないようにすることも大切です。
これにより、目に継続的な刺激を与えることが少なくなります。
さらに、コンタクトレンズケースやコンタクトレンズ用クリーナーなどのケア用品を使用することで、コンタクトレンズの汚れを減らすことができます。</s>
ChatGPTユーザも納得するような上々の出力結果ではないでしょうか![]()
ローカル環境で実行
冒頭でも記載しましたが、私の手元の環境は下記のようなスペックとなります。
- ローカル実行環境
- Windows11(WSL2(Ubuntu22.04 LTS))
- CPU:Intel(R) Core(TM) i7-9700
- RAM:16.0 GB
- GPU:NVIDIA GeForce RTX 2060 SUPER
- Windows11(WSL2(Ubuntu22.04 LTS))
マウスコンピューターのG-Tuneシリーズで二世代くらい前の一般的なゲーミングPCです。
実行環境の構築
本記事では下記の状態まで環境構築ができている状態から記載します。
- NVIDIA Driverのインストール
- WSL2の有効化
- WSL2にubuntu22.04 LTSのインストール
- WSL2にDockerのインストール
Cudaのバージョン
WSL2(Ubuntu22.04 LTS)からCudaのバージョンを確認する。
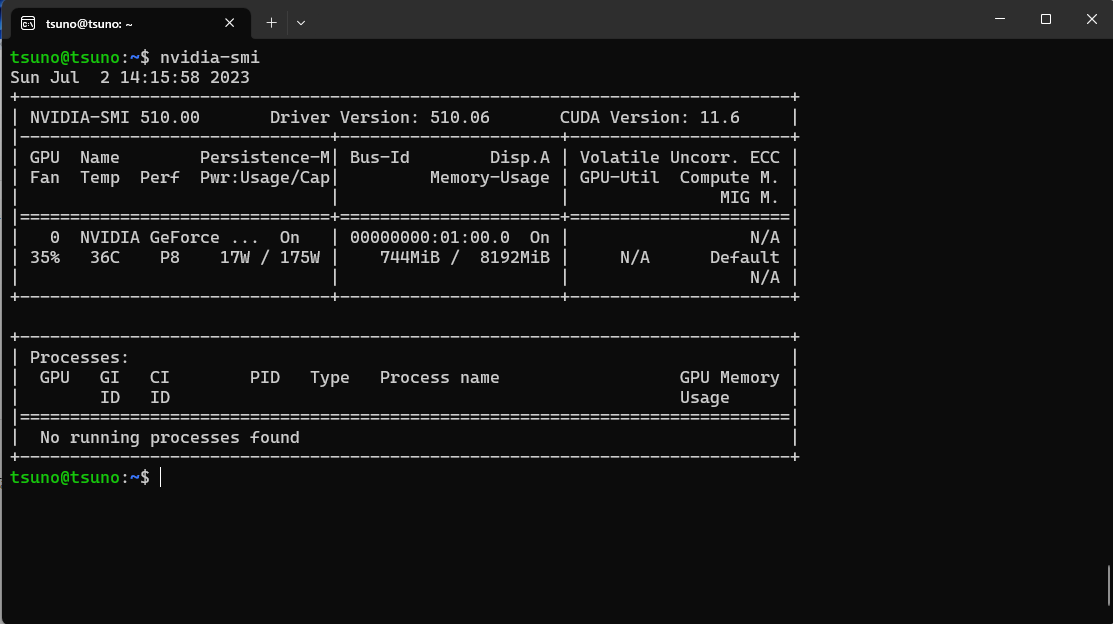
ホストにCuda11.6がインストールされていることを確認。
nvidia-dockerのインストール
DockerコンテナからNvidiaのGPUにアクセスするためには、「Nvidia Docker」のインストールが必要であるため、WSL2にNvidia-Dockerをインストールする。
「nvidia-docker」とは、NVIDIAのGPUとドライバがインストールされたマシン上で稼働するように開発された、Dockerコンテナプラグインです。
コンテナ内にCUDAやcuDNNなどのライブラリがインストールされており、「nvidia-docker」の拡張により、コンテナ内からGPUを使用することが可能です。
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
# nvidia-dockerのインストール
sudo apt-get update
sudo apt-get install -y nvidia-docker2
DockerからGPUへアクセスできるか確認する
下記のコマンドnvidia/cudaのイメージを使ってコンテナをビルドしてnvidia-smiのコマンドを実行する。
nvidia-docker run --rm nvidia/cuda:12.1.0-base-ubuntu20.04 nvidia-smi
下記のように先ほどホストで確認したGPUリソースと同様の情報が確認できた。
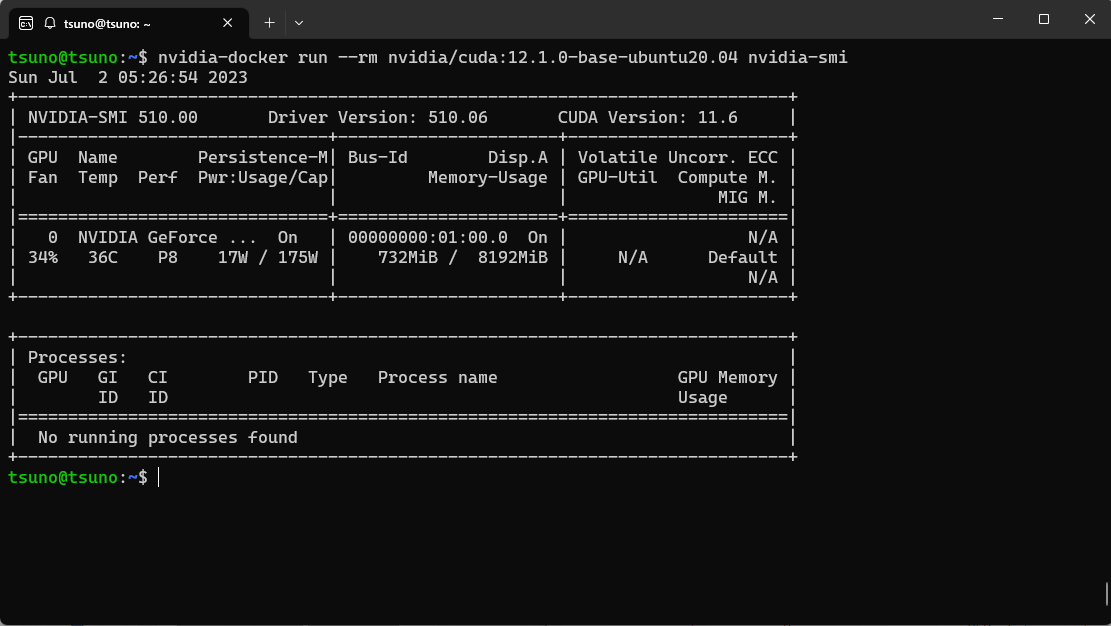
ここまでで、ローカル実行環境の下準備は完了。
PytochのGPU実行環境を構築する
今回検証するのは、NVIDIA GeForce RTX 2060 SUPERのGPUで対話GPT言語モデルの動作を見てみる。
Cudaが実行可能なJupyterLabサーバを起動する
Dockerfileを作成する
下記のように、必要なパッケージをインストールする記述をしたDockerFileを準備する。
Nvidiaではなくpytorchから配布されているベースイメージが楽なのでそちらを利用します。
$ cat Dockerfile
FROM pytorch/pytorch:1.12.1-cuda11.3-cudnn8-devel
USER root
RUN apt-get update && apt-get -y upgrade
RUN apt install -y curl python3 python3-distutils
RUN curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py && python3 get-pip.py
RUN pip install \
jupyter \
jupyterlab \
numpy \
pandas \
matplotlib \
scikit-learn \
scikit-image \
scipy \
tqdm \
albumentations \
transformers \
sentencepiece
Dockerイメージをビルドする
$ nvidia-docker build . -t my-nvidia-cuda
コンテナをビルドし、JupyterLabサーバ起動する
「--gpus all」オプションをつけることにより、GPUへのアクセスが可能になる。
$ nvidia-docker run -it --rm --gpus all -v `pwd`/src:/code -p 8888:8888 --name my-jupyter my-nvidia-cuda sh -c 'jupyter-lab --allow-root --ip=*'
起動したJupyterLabからGPUを認識するか確認する
jupyterから下記のコマンドを実行し、GPU確認する。
!nvidia-smi
実行後、下記のようにGPUが認識できていることを確認。
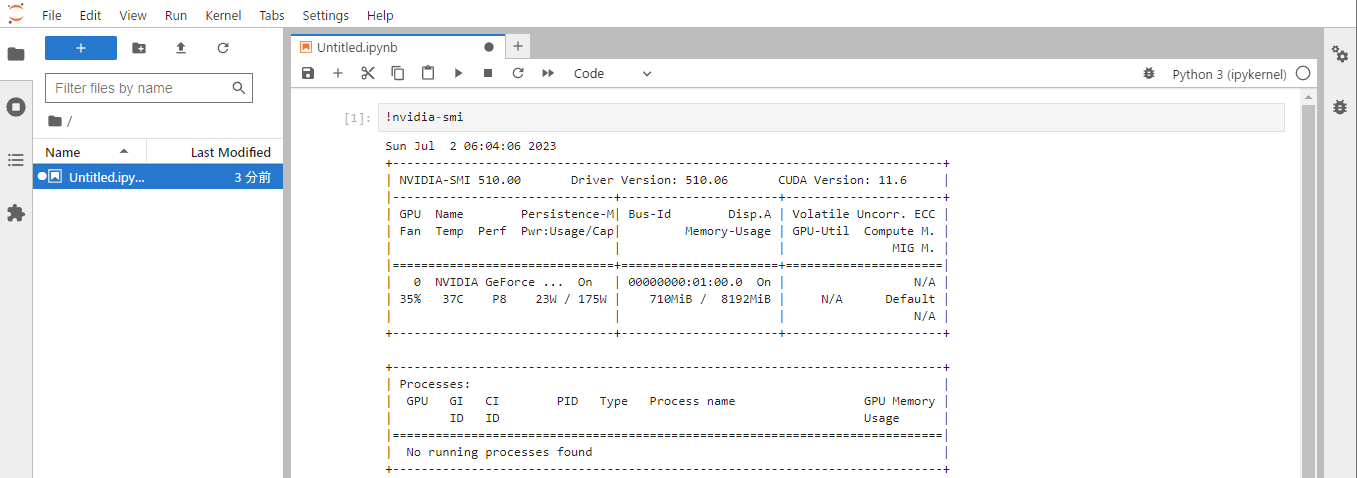
PytorchからGPUを利用できるかを確認する
下記のようにPytochからGPUが認識できているかを確認する
import torch
# バージョン
print(torch.__version__)
# GPUの利用可能かどうか
print(torch.cuda.is_available())
# PyTorchで使用できるGPU
print(torch.cuda.device_count())
# デフォルトのGPU番号(インデックス)
print(torch.cuda.current_device())
# GPUの名称
print(torch.cuda.get_device_name())
実行結果問題なく認識できていることを確認
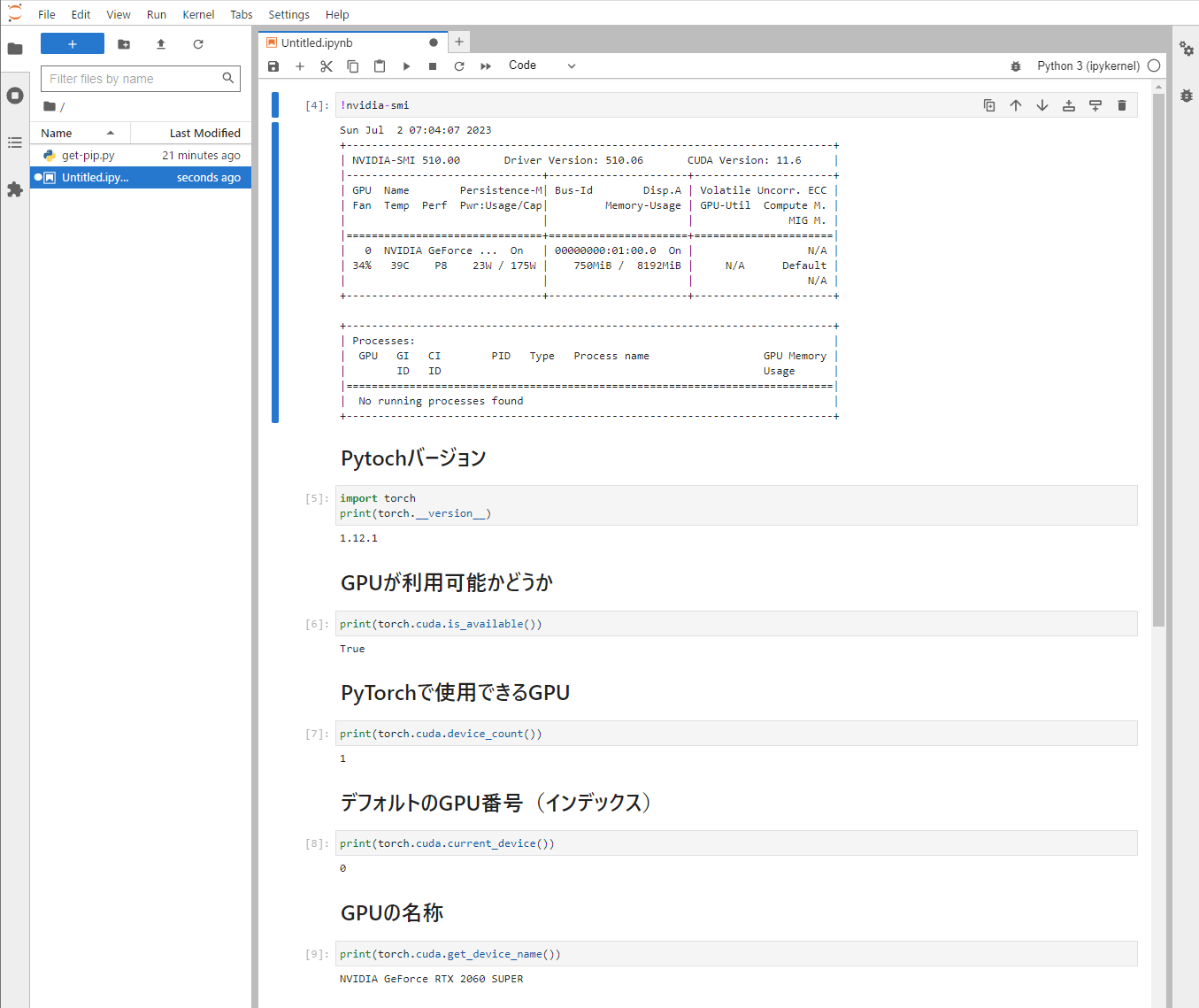
ローカル環境で対話GPT言語モデルの実行
ここから、本題、GoogleColabで動作確認したコードがローカルで実行可能か検証する。
おそらく、RAM上にモデルが乗りきらなく途中でエラーとなってランタイムが落ちてしまいました![]()
4bitに量子化
ただ、ここまで記事を書いてきてあきらめきれない・・・なんとかしたい・・・・
そこで、モデルを4Bitに量子化することでなんとかメモリ上に乗らないかチャレンジしてみる。
量子化のためにパッケージを追加でインストールする
!pip install accelerate bitsandbytes
「load_in_4bit=True」のオプションを与えることでモデルの量子化が可能。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"rinna/japanese-gpt-neox-3.6b-instruction-ppo",
use_fast=False
)
model = AutoModelForCausalLM.from_pretrained(
"rinna/japanese-gpt-neox-3.6b-instruction-ppo",
load_in_4bit=True,
device_map="auto",
)
実行!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
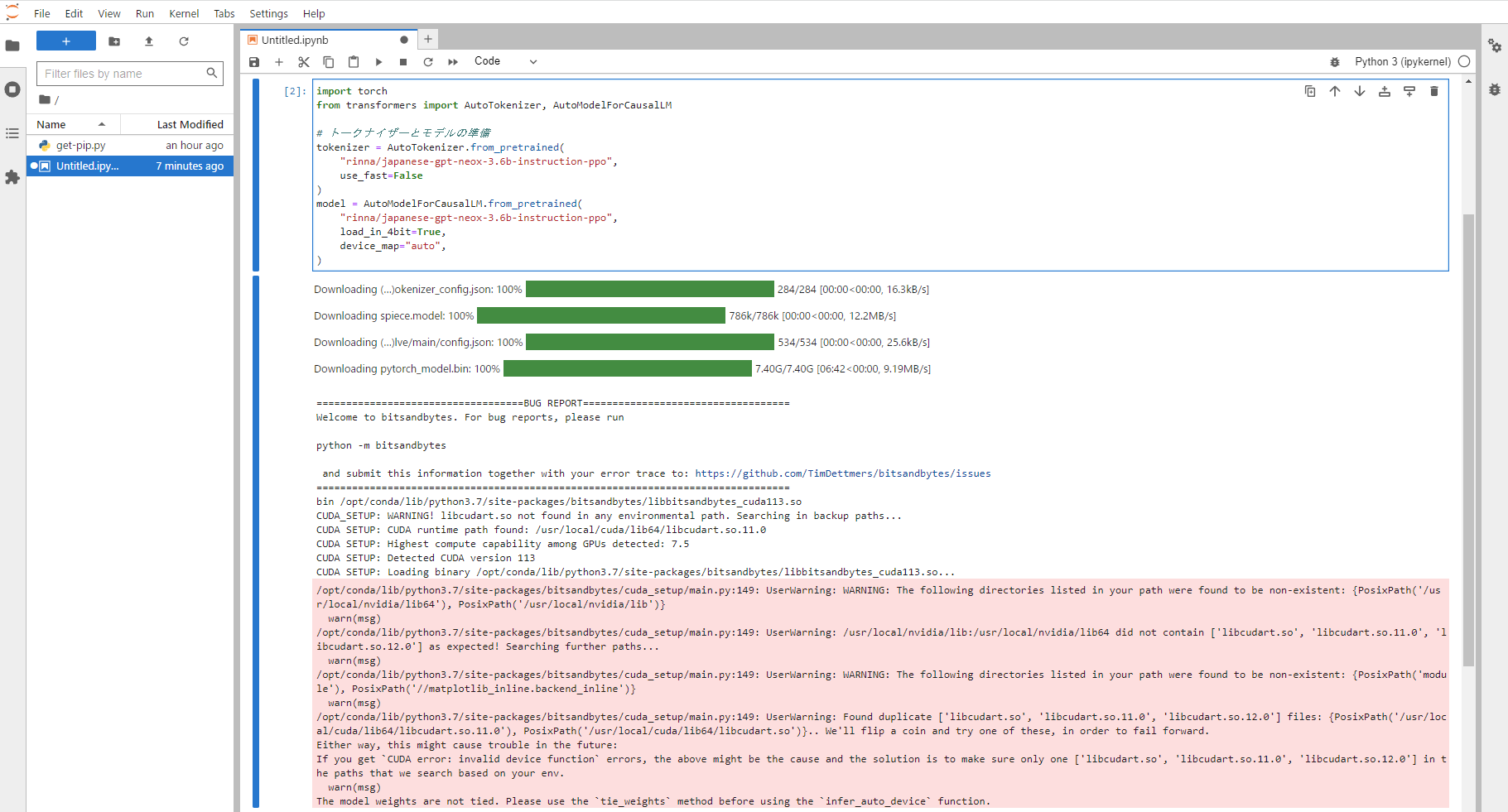
行けたー!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
ちょっと怪しげなログ出てますが、疲れたので無視です。
推論処理を実行
ここで、GoogleColabでの検証したプロントで同じ入力を与えて結果を見てみる。
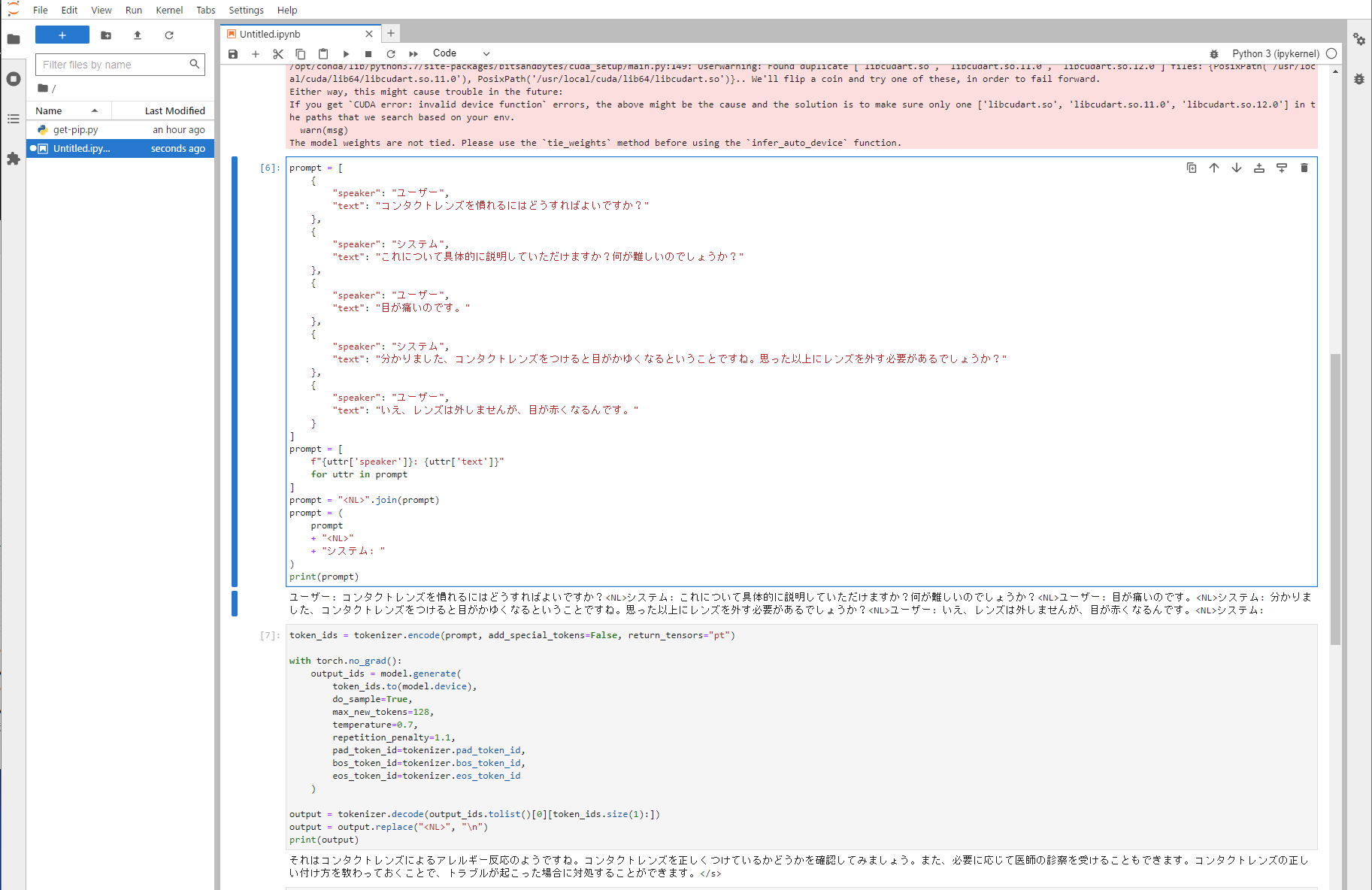
推論時間はレスポンスまで10秒程度かかり遅めですが、出力は下記のような文章となりました。
それはコンタクトレンズによるアレルギー反応のようですね。
コンタクトレンズを正しくつけているかどうかを確認してみましょう。
また、必要に応じて医師の診察を受けることもできます。
コンタクトレンズの正しい付け方を教わっておくことで、トラブルが起こった場合に対処することができます。</s>
32bitモデルから、量子化4Bitまで落としているのにかかわらず、違和感ない回答で驚きです![]()
GPU利用率は推論中は100%使い切っていることも確認できているため、GPUで演算できているようです。
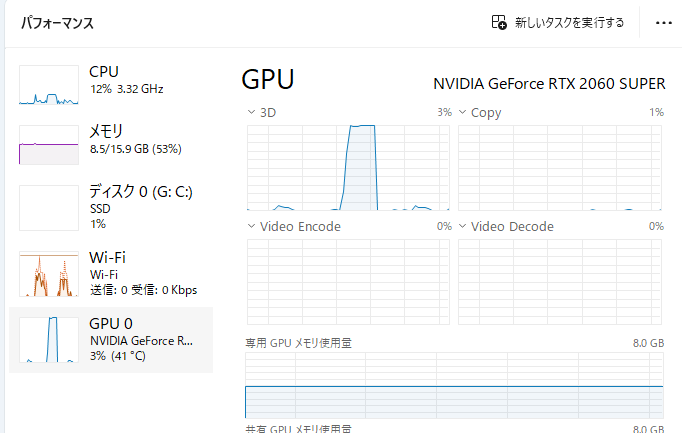
さいごに
今回はrinna社が公開している日本語特化の対話GPTモデルについて触ってみました。
僕のPCでは強引な手段を取るしかなかったですが、
RAMが32GB以上でGeForce RTX 30系のGPUを使えば、32bitのモデルでも動かすことは叶うかと思います。
また、セキュリティ要求が高くChatGPTが使えないなどで自社サーバで対話型AIを構築したい等の要求があれば、
有効的な手段として使えるモデルなのではないかと思います。
本記事では動作確認までとしましたが、本当は僕にPCで「俺の嫁」を起動させたかったのです・・・
ローカル環境で動かすのに苦戦しすぎました![]()
もし参考になったとかご指摘等あれば、コメントやいいねをいただけると幸いです。