CubieTruckでHadoop クラスタ構築してみた。

■ハード構成
・自作無線ルータ(Raspberry Pi)
・CubieTruck (Fedora 19)
・NameNode 1台
・DataNode 4台
■ミドル構成
・Oracle JDK 1.7 for ARM
・Hadoop 2.2.0
インスール手順 (全ノードで実施)
/etc/hostsの設定(DNSの場合は省略)
# vi /etc/hosts
※以下を追記
192.168.100.2 master00 master00.localdomain
192.168.100.3 slave01 slave01.localdomain
192.168.100.4 slave02 slave02.localdomain
192.168.100.5 slave03 slave03.localdomain
JDKのインストール
HadoopはJavaベースで動いているので、JDKのインストールします。 ※OpenJDKでも動くみたいです。# cd /usr/local/src
# wget --no-check-certificate --no-cookies - --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/7u67-b01/jdk-7u67-linux-i586.tar.gz
# tar zxvf jdk-7u67-linux-i586.tar.gz
# mv jdk1.7.0_60 /opt/
Hadoop実行ユーザの準備
hadoop起動ユーザを作成します。# groupadd hadoop
# useradd -g hadoop hduser
# passwd hduser
New UNIX password: ← 適当
Retype new UNIX password: ← 同じ
sshの準備
HadoopはNode間をssh接続(パスワードなし)で接続するので、パスワードなしで接続できるように設定します。# su - hduser
$ ssh-keygen -t rsa -P ''
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hduser/.ssh/id_rsa): (※)
Created directory '/home/hduser/.ssh'.
:
(※)そのままReturn
$ cd
$ cat ./.ssh/id_dsa.pub >> ./.ssh/authorized_keyschmod 600
$ ./.ssh/authorized_keys
$ ssh localhost
※ノンパスワードでsshアクセスできることを確認。
(初回アクセス時のみyesが必要)
NameNodeで設定したカギを各ノードに配布してノード間も
パスワード無しでアクセス可能としておきます。
Hadoop 2.2.0のインストール
http://www.apache.org/dyn/closer.cgi/hadoop/core/ ※適当なミラーから「hadoop-2.2.0.tar.gz」ダウンロード$ exit ← hduser から抜けます。
# cd /usr/local.src
# wget http://ftp.riken.jp/net/apache/hadoop/core/hadoop-2.2.0/hadoop-2.2.0.tar.gz
# tar zxvf hadoop-2.2.0.tar.gz
# mv hadoop-2.2.0 /opt/hadoop
※所有権を実行ユーザに変更
# chown -R hduser:hadoop /opt/hadoop
Hadoop用の環境変数設定
hadoopの起動に必要な環境変数を設定します。# su - hduser
$ vi ~/.bashrc
※以下を追記
export JAVA_HOME=/opt/jdk1.7.0_60
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_INSTALL=/opt/hadoop-2.2.0
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
設定の確認
$ source ~/.bashrc
$ hadoop version
Hadoop 2.2.0
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4
This command was run using /opt/hadoop-2.2.0/share/hadoop/common/hadoop-common-2.2.0.jar
pathが取っていればversionが表示されます。
Hadoop設定ファイルの編集
設定ファイル・${HADOOP_INSTALL}/etc/hadoop/core-site.xml
・${HADOOP_INSTALL}/etc/hadoop/yarn-site.xml
・${HADOOP_INSTALL}/etc/hadoop/mapred-site.xml
・${HADOOP_INSTALL}/etc/hadoop/hdfs-site.xml
・${HADOOP_INSTALL}/etc/hadoop/slave
まず、HDFSのディレクトリを作成します。
$ exit ← hduser から抜けます。
# mkdir -p /export/hdfs/namenode
# mkdir -p /export/hdfs/datanode
# chown -R hduser:hadoop /export/hdfs
設定ファイルを作っていきます。
すべてのファイルに共通してconfigurationタグの間を修正します。
□core-site.xml
# su - hduser
$ vi ${HADOOP_INSTALL}/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
:省略
<configuration>
<!-- ここから追記 -->
<property>
<name>fs.default.name</name>
<value>hdfs://master00:9000</value>
</property>
<!-- ここまで -->
</configuration>
□yarn-site.xml
$ vi ${HADOOP_INSTALL}/etc/hadoop/yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); :省略
<configuration>
<!-- ここから追記 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>
yarn.nodemanager.aux-services.mapreduce.shuffle.class
</name>
<value>
org.apache.hadoop.mapred.ShuffleHandler
</value>
</property>
<!-- ここまで -->
</configuration>
□mapred-site.xml
$ cd ${HADOOP_INSTALL}/etc/hadoop/
$ cp mapred-site.xml.template mapred-site.xml
$ vi mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- Licensed under the Apache License, Version 2.0 (the "License");
:省略
<configuration>
<!-- ここから追記 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- ここまで -->
</configuration>
□hdfs-site.xml
$ vi ${HADOOP_INSTALL}/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- Licensed under the Apache License, Version 2.0 (the "License");
:省略
<configuration>
<!-- ここから追記 -->
<property>
<name>dfs.replication</name>
<value>4</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/export/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/export/hdfs/datanode</value>
</property>
<!-- ここまで -->
</configuration>
□slave(Namenodeのみ)
master00
slave01
slave02
slave03
これで設定完了です。
NameNodeのフォーマット
最初にNameNodeをフォーマットする必要があります。 master00にsshで接続します。# su - hduser
$ hdfs namenode -format
実行ログが出力され、完了です。
Hadoop起動
master00にsshで接続します。# su - hduser
$ start-all.sh
これで起動が完了です。
起動後に各ノードでプロセスチェックを行います。
□master00
# su - hduser
$ jps
549 NameNode
920 ResourceManager
1023 NodeManager
755 SecondaryNameNode
1349 Jps
640 DataNode
□slave0x
# su - hduser
$ jps
654 Jps
380 DataNode
539 NodeManager
Web UIで確認
http://master00:50070/
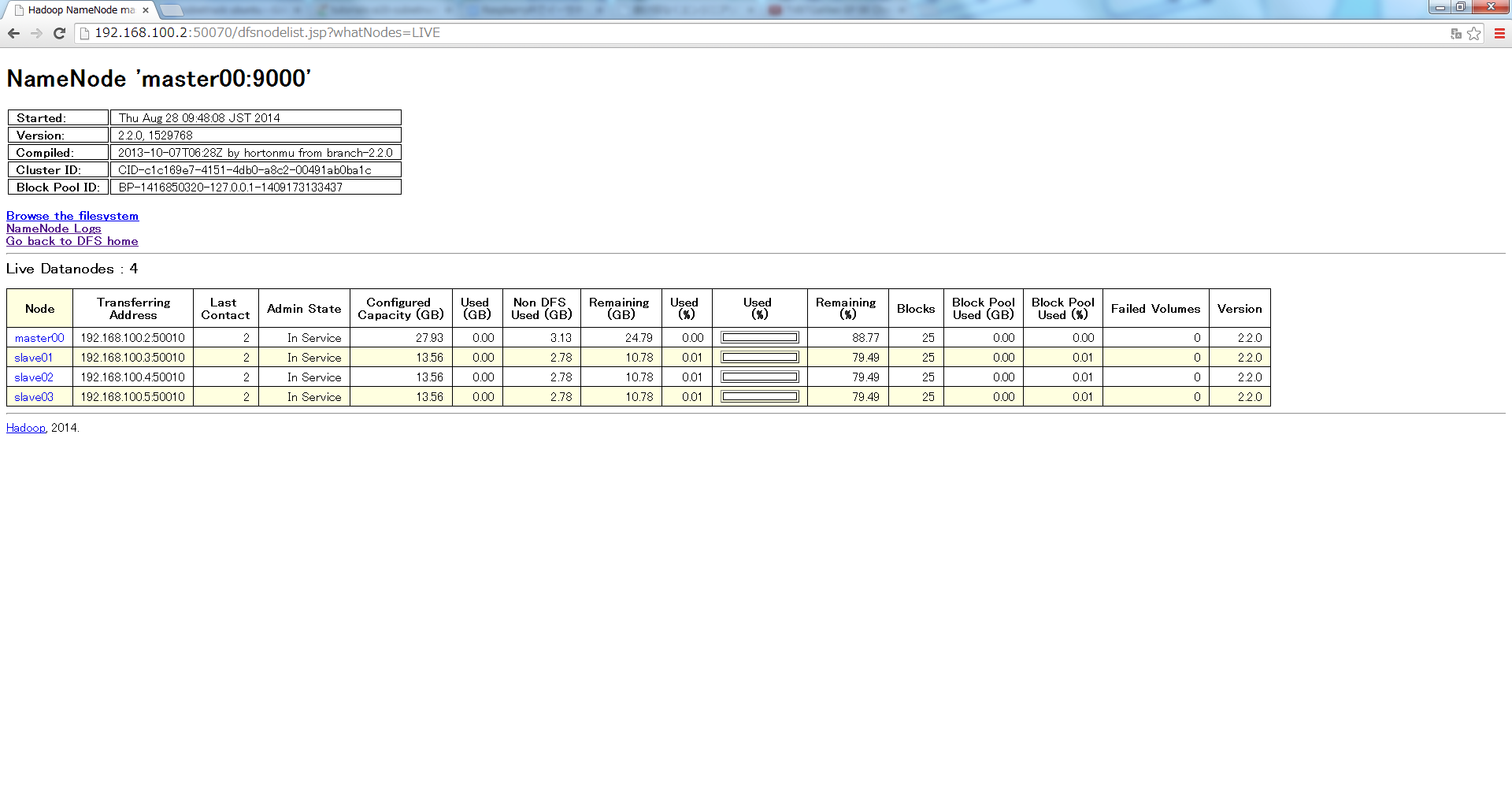
構築は以上、exampleなどで実行可能な状態となりました。
【補足】
ARM系でのHadoop利用はコスト面ではいいかも知れませんが、Map Reduceは、各ノードの処理速度が遅いため実用的でないと感じました。
以下の参考記事に、Apache Sparkにすれば、メモリ不足も解消できるそうなので、そちらも試したいと思います。