概要
社内で川柳の催し物が開かれました
ただ出るだけでは芸がないのでせっかくなので川柳AIを作りました
具体的には, テキトーなキーワードを入れるとそのキーワードに沿った句を詠んでくれるものを作りました
学習データについて
学習データについて① 歌編
和歌についてまとめているサイトからスクレイピングしました.
その中から
- 17音になっているもの(字余りなどのないもの)
- 英数字や記号などが含まれていないもの
の条件に沿うもの20万首を選びました
575になっているかどうかは, 漢字混じり分をpykakashiをつかいひらがなに変換することで解決しました
import pykakasi
def is_hiragana(text):
if "\n" in text:
return False
hiragana_whitespace_pattern = r'^[\u3040-\u309Fー]+$'
return re.match(hiragana_whitespace_pattern, text) is not None
def to_hiragana(text):
kakasi = pykakasi.kakasi()
conv = ''.join([item['hira'] for item in kakasi.convert(text)])
return conv
def is_haiku(text):
text = to_hiragana(text)
if is_hiragana(text)==False:
return False
for i in "ゃゅょぁぃぅぇぉ":
text = text.replace(i,"")
return len(text)==17
学習データについて② キーワード編
「キーワードを元にそれに沿って一句を詠む」というコンセプト上, 和歌と紐づくキーワードが必要になってきます.
ここでは, 和歌中の名詞を抜き出し, これをキーワードにすることにしました
具体的には
「川池や蛙飛び込む水の音」
という句の場合
「川池」と「蛙」と「池」と「音」がそれぞれキーワードとなります.
名詞の抽出はsudachipyを用いて行いました
from sudachipy import dictionary
def extract_nouns(text):
tokenizer_obj = dictionary.Dictionary().create()
tokens = tokenizer_obj.tokenize(text)
nouns = []
for token in tokens:
if token.part_of_speech()[0] == '名詞':
nouns.append(token.surface())
return nouns
# 使用例
text = "川池や蛙飛び込む水の音"
nouns = extract_nouns(text)
print(nouns) # ['川池', '蛙', '水', '音']
モデルについて
モデルは以前に扱ったことのあるT5を用いることにしました.
入力側にキーワードを, 出力側に和歌をこさえファインチューニングを行いました.
詳しいことは
を参考にしてください
出力について
最後に, 出てくる文字が575にするためにモデルの出力部分を工夫しました.
はじめに, 出力トークン数を定めた上でモデルを動かします
次に, 必要文字数(5 or 7)になっている出力を正解候補としてあげます
色々な出力トークン数でそれを行い, 最もスコアの高い候補を採用します
import pykakasi
import torch
import re
class generateSenryu:
def __init__(self, model, tokenizer, is_cuda=torch.cuda.is_available()):
self.tokenizer = tokenizer
self.is_cuda = is_cuda
if self.is_cuda:
self.model = model.cuda()
else:
self.model = model.cpu()
self.model.eval()
def to_hiragana(self, text):
kakasi = pykakasi.kakasi()
conv = ''.join([item['hira'] for item in kakasi.convert(text)])
return conv
def is_japanese_only(self, text):
text = self.to_hiragana(text)
hiragana_whitespace_pattern = r'^[\u3040-\u309Fー]+$'
return re.match(hiragana_whitespace_pattern, text) is not None
def to_count_text(self, text):
text = self.to_hiragana(text)
for i in "ゃゅょぁぃぅぇぉ":
text = text.replace(i, "")
return len(text)
def get_senryu_ku(self, input_ids, word=5, decoder_start_token_id=None, top_k=10):
text_result = []
score_result = -1e30
for i in range(1, word+2):
model_result = self.model.generate(
inputs=input_ids,
max_new_tokens=i,
num_return_sequences=top_k,
num_beams=top_k,
return_dict_in_generate=True,
output_scores=True,
decoder_start_token_id=decoder_start_token_id,
)
texts = [
self.tokenizer.decode(i, skip_special_tokens=True, clean_up_tokenization_spaces=False)
for i in model_result["sequences"]
]
flgs = [(self.to_count_text(text) == word) and self.is_japanese_only(text) for text in texts]
for i in range(top_k):
if flgs[i] and score_result < model_result['sequences_scores'][i]:
text_result = model_result["sequences"][i]
score_result = model_result['sequences_scores'][i]
break
return text_result
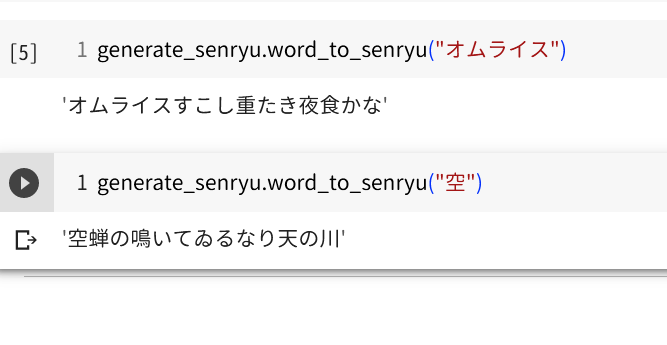
def word_to_senryu(self, word,):
input_ids = torch.tensor([self.tokenizer(word)['input_ids']])
if self.is_cuda:
input_ids = input_ids.cuda()
senryu = self.get_senryu_ku(input_ids, word=5)
senryu = self.get_senryu_ku(input_ids, word=7+5, decoder_start_token_id=senryu)
senryu = self.get_senryu_ku(input_ids, word=7+5+5, decoder_start_token_id=senryu)
text = self.tokenizer.decode(senryu, skip_special_tokens=True, clean_up_tokenization_spaces=False)
return text
まとめ
俳句も川柳もよくわかりませんが, なんとなくそれっぽいものができて満足しております.
最後に自慢がてら, いくつか気に入った川柳をのっけます
| キーワード | 俳句 |
|---|---|
| オムライス | オムライスすこし重たき夜食かな |
| 蛍 | 蛍火のうしろの闇にまぎれけり |
| 夕闇 | 夕闇のうすむらさきに鳥渡る |
| セール | 買初のセールの靴を買ひにけり |
| 独り言 | 独り言ふつふつふつと秋の暮 |