作ったwebアプリについて
左右に表れる2つの本から1つを選ぶことを繰り返すことで, 新しい本に出逢えるwebアプリを作りました.
宣伝です.
↑web版
↑androidアプリ版
概要
本を買う際に, amazonなどのECサイトで買うことも多いですが, ときどき本屋にも行きたくなります.
......と言うのは, ECサイトの本と触れる箇所は, 検索(ほしい本)・レコメンド(類似本)・ランキング(人気本)がほとんどで, 本屋で得られる「本棚を眺め, なんとなく出逢った本を手に取る」という出逢いの経験が得らないからです.
なので, web上で類似本でも人気本でもない新しい本と出逢えるwebアプリを作りました.
2つの本の中から「どちらが手に取りたいか」を何回か選ぶことで, ユーザーの趣味嗜好を深掘りし, オススメの本をピックアップするサービスです.
名前の由来は「深掘り」+「akinatorっぽい」ということでhorinatorにしました(知人につけてもらった).
アルゴリズムについて
このwebアプリは
- 本を二択から選択
- オススメの本紹介
の2ステップで構成されてます.
それぞれについて説明していきます.
本を二択から選択 - 階層クラスタリング
まずはじめに, 本の利用傾向の近さから埋め込み表現を作ります.
(ここのところは, すでに色々と解説があると思うので省略します)
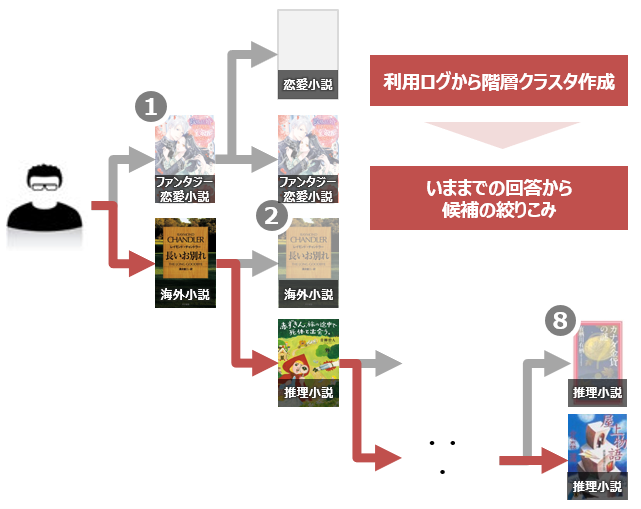
次に, 各書籍間で階層クラスタリングを行います.
ユーザーの二択は, 階層クラスタリングでできた木構造の, 片側を選ぶか, もう片側を選ぶかで表現されます.
そして選択が終わると, 木構造の深さを一つ進めることで, ユーザーの興味を深掘りしていきます.
一般的な階層クラスタリング手法は, クラスタリングをボトムアップで行います.
しかし今回の場合では
- 全部を完全にクラスタリングするには計算量が多すぎること
- 木構造の深い階層の情報は不要なこと
から階層クラスタリングをトップダウンで行いました.
手法は, クラスタ数2のK-meansを繰り返し行うことで実装しました.
(「統計的学習の基礎」いわくそれがよく使われる手法のようです)
オススメの本紹介 - spectral relaxation
「オススメの本紹介」では選択された本のクラスターを一覧表示させています.
ここで大事になってくるのが, 「本の並び方をどうするか」という問題です.
「本の人気順でソートする」というのも一つの手だとは思いますが, 「人気本でもない新しい本と出逢う」というコンセプトに反します.
なので今回は本のバリエーションが極力豊かになるようにソートしました.
ただ, これを愚直に計算するとなると, かなりの計算量が必要になるため, spectral relaxationを用いることで近似解を計算しました.
具体的な手法に関してはかなり込み入った話になるので「Novelty and Diversity in Top-N Recommendation -- Analysis and Evaluation」を読んでいただければ幸いです.
(いつか別途解説の記事を書くかも)
実装について
実装は, Fletというpython×flutterなライブラリで実装しました.
pythonに慣れているかたなら, 簡単にそれなりの見栄えのものができるのでオススメです.
筆者はpythonぐらいしかできる言語がないのでこれを選択.
結果としてまあよかったかなと思っています.
webアプリ以外にもマルチプラットフォームでつくれるので, ちょっとしたツールならば, これで作るのが良さそうです.
今後改良したいこと
- 事前に「小説」「新書・実用書」「マンガ」などのジャンルフィルターを設けたい
- マンガやライトノベルは冊数が多いため, 一つにまとめて学習したい
- ただ, 結構表記揺れがあるのでどうしようか......
- 今は, 「本を二択から選択」段階と「オススメの本紹介」段階の切り替えを冊数で行っているが, これをよりラインナップに即した形で決定したい
- X-meansを応用すればいけるかも