概要
人からコメントもらえるのって嬉しいですよね.
なので, AIに簡単にコメントを貰えるプログラムを書きました.
マイク上で言葉を喋ると, 某動画サイトのように画面上にコメントが流れます
具体的に言うと, 「おはようございます」と喋った時↓のようなコメントが
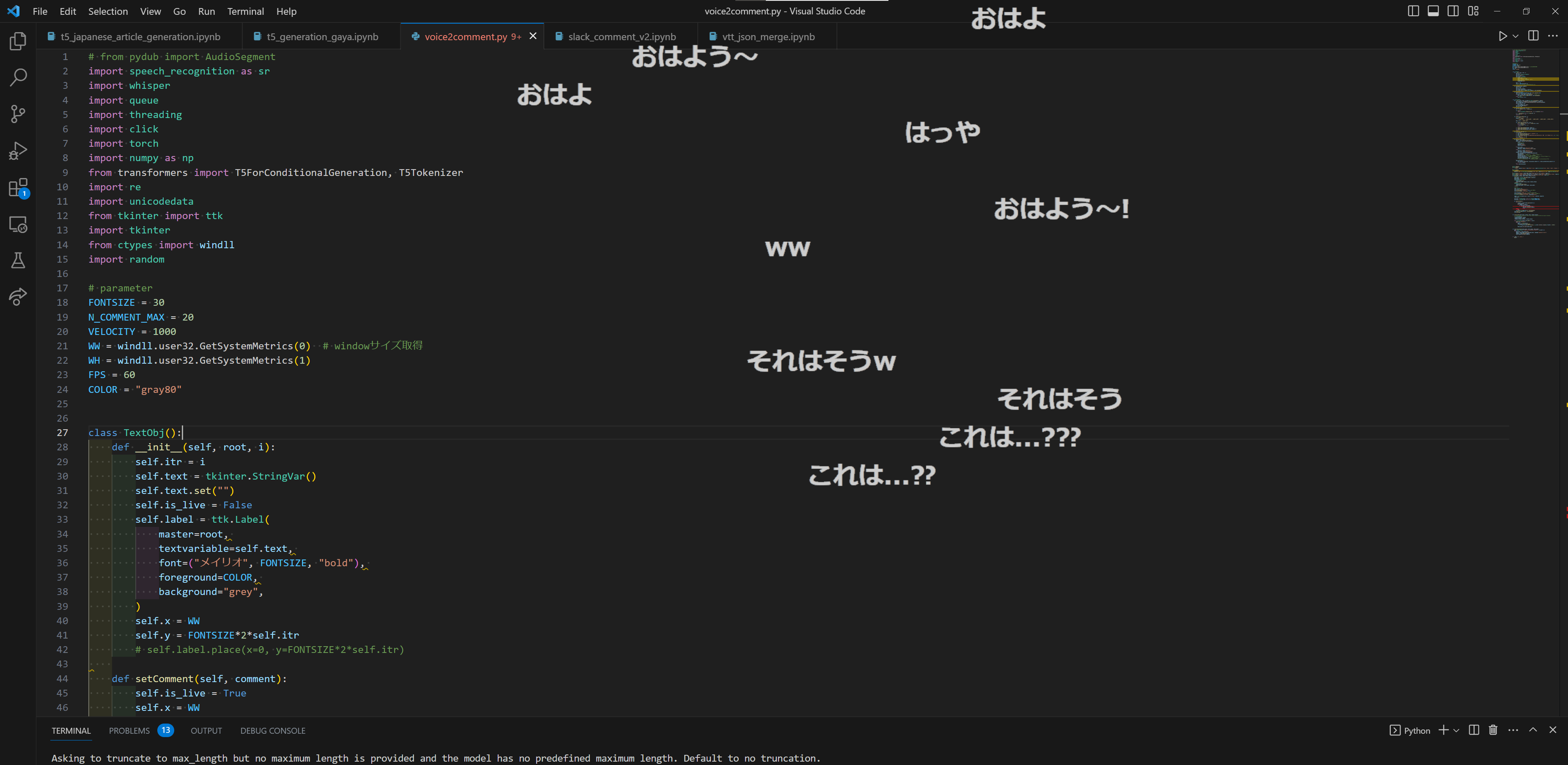
「マイクテスト聞こえていますか」と喋った時↓のようなコメントが
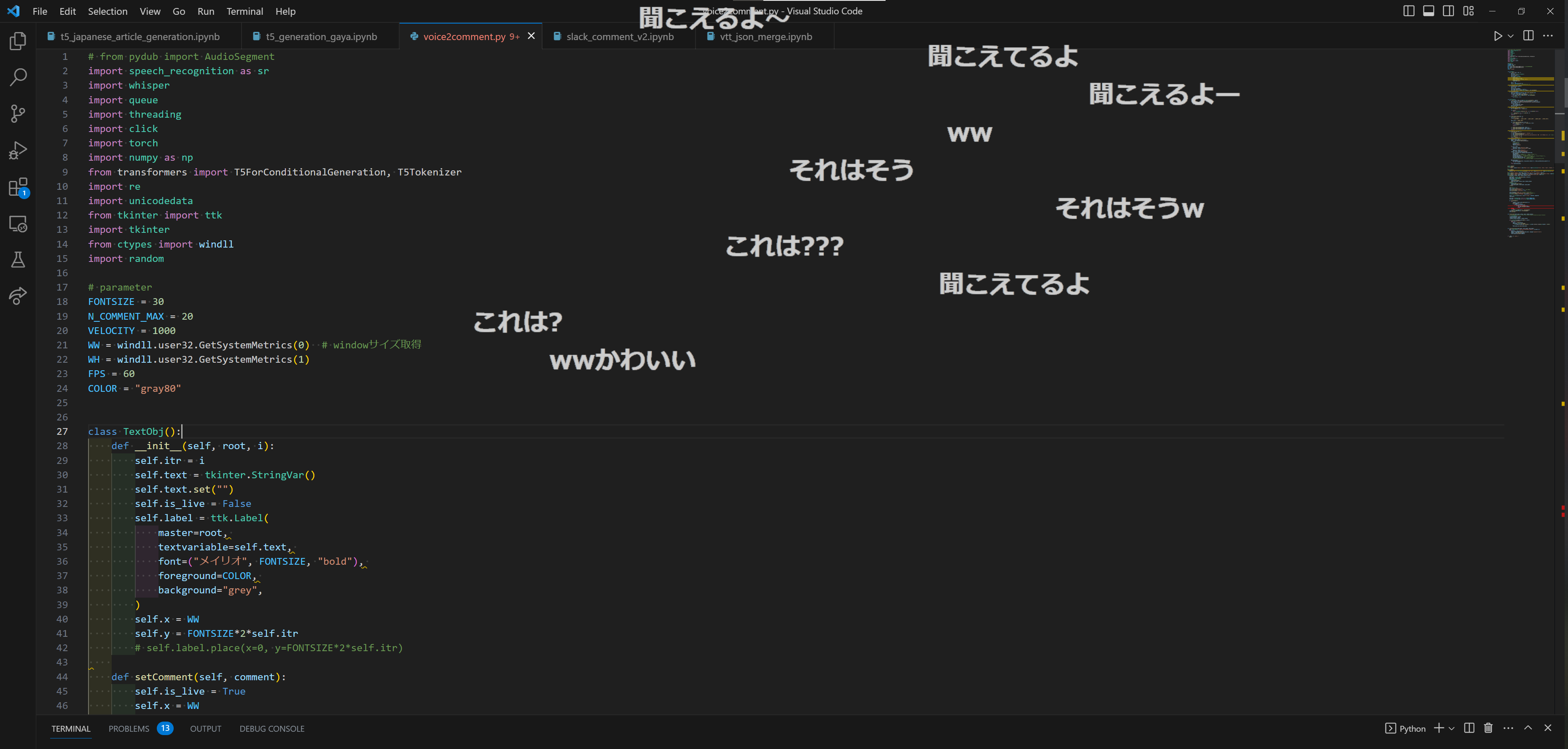
画面上に流れます
全体の流れ
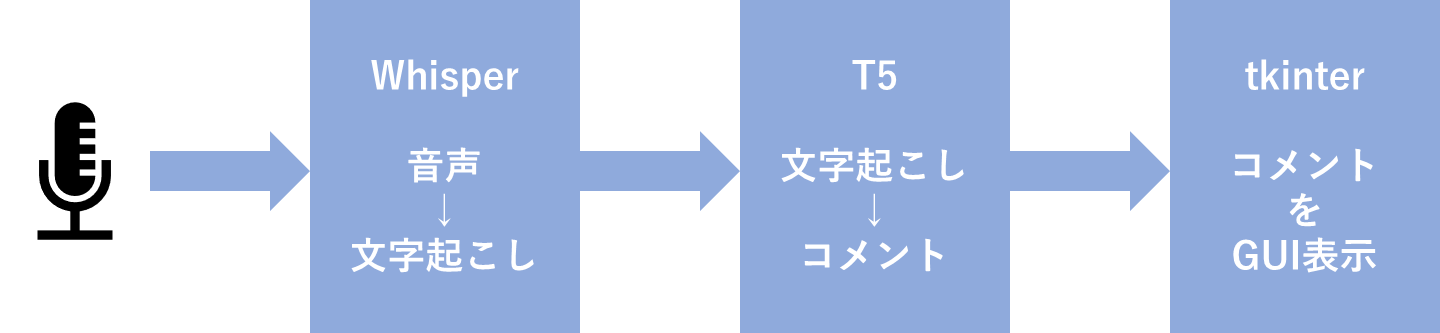
コード全体の流れについて説明します
- PCのマイクで喋った内容をwhisperを使いリアルタイム文字起こしを行います
- 次に, その内容を深層学習モデルにいれることでそれっぽいコメントを出力
- 最後にそれをtkinterで画面上にコメント表示しました
①whisper : 音声データのリアルタイム文字起こし
whisperとはopenAIが提供している文字起こし用のモデルです
whisperを用いる場合, API経由かモデルを直接動かすかの2通りの方法があります
今回はリアルタイムで文字起こしを行いたかったためモデルを使用しました.
コードはこのサイトの内容を参考に書き換えました.
②T5 : 喋った内容→コメント
学習データのダウンロードについて
「文字起こしデータ」と「チャット欄」がテキストデータとして残っているyoutube-liveを学習データとしました
各動画に対する, 「文字起こしデータ」や「チャット欄」のダウンロードとしてyt-dlpを使用しました
具体的に「文字起こしデータ」と「チャット欄」をダウンロードするコードは下記のようになります
from yt_dlp import YoutubeDL
def get_youtube_subtitles(url):
ydl_video_opts = {
'outtmpl' : '%(id)s'+'_.mp3',
'format' : 'bestaudio',
'writesubtitles' : True,
'skip_download' : True,
"ignoreerrors":True,
"overwrite":False,
"writeautomaticsub":True,
"subtitleslangs":['ja', 'live_chat']
}
with YoutubeDL(ydl_video_opts) as ydl:
result = ydl.download([url])
urls = [ ここにダウンロードするurl書く ]
[get_youtube_subtitles(url) for url in urls]
学習データの整形について
ダウンロードした「チャット欄」のjsonファイルは, 各行がjsonファイルとなっているので注意
ダウンロードした「文字起こしデータ」は実際に表示される字幕形式となっているため冗長です
このサイトを参考に冗長さを取り除きました
そして, 「チャット欄」の投稿とその30秒前の「文字起こしデータ」の内容を学習用のデータセットとしてひとまとめにしました.
モデルについて
入れた文字を元にそれっぽいコメントを出力するモデルを作成しました.
学習済み自然言語処理モデルをファインチューニングすることをします
深層学習をつかった学習済み自然言語処理モデルは
- エンコーダーデコーダーモデル
- 入力が文字列 出力が文字列
- 例:transformer T5
- エンコーダーモデル
- 入力が文字列 出力がベクトル
- 例:BERT
- デコーダーモデル 例:GPT
- 入力文の続きを書く
- 例:GPT
の三種類があります
今回は, 「文字起こしデータ」=入力と「チャット欄」=出力の関係に当たるので「エンコーダーデコーダーモデル」を選ぶのが筋が良さそうです
そのため, エンコーダーデコーダーモデルの一つであるT5をモデルとして選びました.
ファインチューニングは以下のサイトを参考に行いました
③tkinter : コメント表示
喋った内容を画面上に描画するためにtkinterというライブラリを使用しました.
コメントを描画するところだけ抜粋してコードを書きます
class TextObj():
def __init__(self, root, i):
self.itr = i
self.text = tkinter.StringVar()
self.text.set("")
self.is_live = False
self.label = ttk.Label(
master=root,
textvariable=self.text,
font=("メイリオ", FONTSIZE, "bold"),
foreground=COLOR,
background="grey",
)
self.x = WW
self.y = FONTSIZE*2*self.itr
# self.label.place(x=0, y=FONTSIZE*2*self.itr)
def setComment(self, comment):
self.is_live = True
self.x = WW
self.text.set(comment)
self.label.place(x=self.x, y=self.y)
self.label.after(int(2000*random.random()), self.moveComment)
def moveComment(self):
self.x -= VELOCITY/FPS*(WW+self.label.winfo_reqwidth())/WW
self.label.place(x=self.x, y=self.y)
if self.x > -self.label.winfo_reqwidth(): # スクロール中
self.label.after(int(1000/FPS+0.5), self.moveComment)
else: # 左端
self.is_live = False
def main(model, energy, pause, dynamic_energy, device):
# model設定
# ここでバックグラウンドでリアルタイム文字起こし&コメント取得する処理を書く
# result_queue=コメント内容
# gui設定
root = tkinter.Tk()
root.title("CommentScroll")
root.wm_attributes("-topmost", True) # 最前面表示
root.wm_attributes("-fullscreen", True)
root.attributes("-alpha", 1) # 透明度(機能してない?)
root.wm_attributes("-transparentcolor", "grey") # 透過色設定
ttk.Style().configure("TP.TFrame", background="grey")
frame = ttk.Frame(master=root, style="TP.TFrame", width=WW, height=WH)
frame.pack()
text_objs = [TextObj(root, n) for n in range(N_COMMENT_MAX)]
def refreshComment():
try:
comments = result_queue.get(block=False)
for comment in comments:
for text_obj in text_objs:
if (text_obj.is_live)==False:
text_obj.setComment(comment)
break
except:
# コメントがない場合
pass
root.after(int(1000/FPS+0.5), refreshComment)
root.after(int(1000/FPS+0.5), refreshComment)
root.mainloop()
感想
簡単な挨拶などはちゃんとコメントを貰えるのですが, ちょっと難しい話をすると全部「草」とか「ww」とかになってしまいます
かなしい
極力, レスポンスがしっかりしがちな雑談系の動画に絞って学習すればもっと質が良くなったのではないかと反省してます