背景
前回の記事で、S3Proxyについて、Microsoft Azure Blob Storageで実行できるかどうか検証してみました。
今回は、その記事の中にUsage with Javaというのがありましたので、試してみることにしました。また、せっかくなので、今後Sparkでも使いたいので、Scalaで書いてみました。
実装
ポイント
実装はS3ProxyのMain.javaを参考にしました。
実装してわかったのは、ほとんどはjcluodsのコンポーネントを使っていることです。
注意すべき点は、
build.sbtのlibraryDependenciesで以下のjetty-util9.2を使っているのですが、
jettyは9.4が最新なので、jetty9.2を使おうとすると、エラーになってしまいます。
S3Proxy内でコールしているjetty Serverが9.2を使っているためですね。
"org.eclipse.jetty" % "jetty-util" % "9.2.22.v20170606"
実コード抜粋
val path = FileSystems.getDefault().getPath("conf", "s3proxy.conf")
val inputStream = Files.newInputStream(path, StandardOpenOption.READ)
val properties = new Properties
properties.load(inputStream)
Option(properties.getProperty(Constants.PROPERTY_PROVIDER)) match {
case Some(provider) => Option(properties.getProperty(Constants.PROPERTY_IDENTITY)) match {
case Some(identity) => Option(properties.getProperty(Constants.PROPERTY_CREDENTIAL)) match {
case Some(credential) => {
val context = ContextBuilder.newBuilder(provider).
credentials(identity, credential).
overrides(properties).build(classOf[BlobStoreContext])
val s3Proxy = S3Proxy.builder().blobStore(context.getBlobStore()).
endpoint(URI.create("http://127.0.0.1:8080")).build()
s3Proxy.start()
while (!s3Proxy.getState().equals(AbstractLifeCycle.STARTED)) {
Thread.sleep(1)
println("Not Start!")
}
println("Start!")
}
case None => println("$Constants.PROPERTY_CREDENTIAL is not exists.")
}
case None => println("Constants.PROPERTY_IDENTITY is not exists.")
}
case None => println("$Constants.PROPERTY_PROVIDER is not exists")
}
上記ソースを解説すると、
val context = ContextBuilder.newBuilder(provider).
credentials(identity, credential).
overrides(properties).build(classOf[BlobStoreContext])
__ContextBuilder.newBuilder__をコールしコンテキストを作ります。
providerは__Azure Blob Storage__の場合、_jclouds.provider=azureblob_を指定します。
jcloudsを使っているのが_propertieファイル_から見ても読み取れますね。
__Azure Blob Storage__の場合の_identity_と_credential_は前回の記事にも記載しましたが、
_ストレージ アカウント名_と_アクセスキー_になります。
設定ファイル(s3proxy.conf)
設定ファイル名はこの場合任意です。
ソースはハードコードしておりますが、
サンプルソースですのでご愛嬌ということでお願いいたします。

上記のようになります。
コンパイル
ScalaはJava互換のJarファイルを作ることができます。
ここではJarファイルの作り方の説明は割愛しますが、
sbt-assemblyのモジュールを使っています。
sbt assembly

\s3proxy-scala-project\target\scala-2.12\Hello-assembly-0.1.0-SNAPSHOT.jar
上記のようにjarファイルが出力されました。
\s3proxy-scala-project\target\scala-2.12\Hello-assembly-0.1.0-SNAPSHOT.jar
>java -jar target\scala-2.12\Hello-assembly-0.1.0-SNAPSHOT.jar
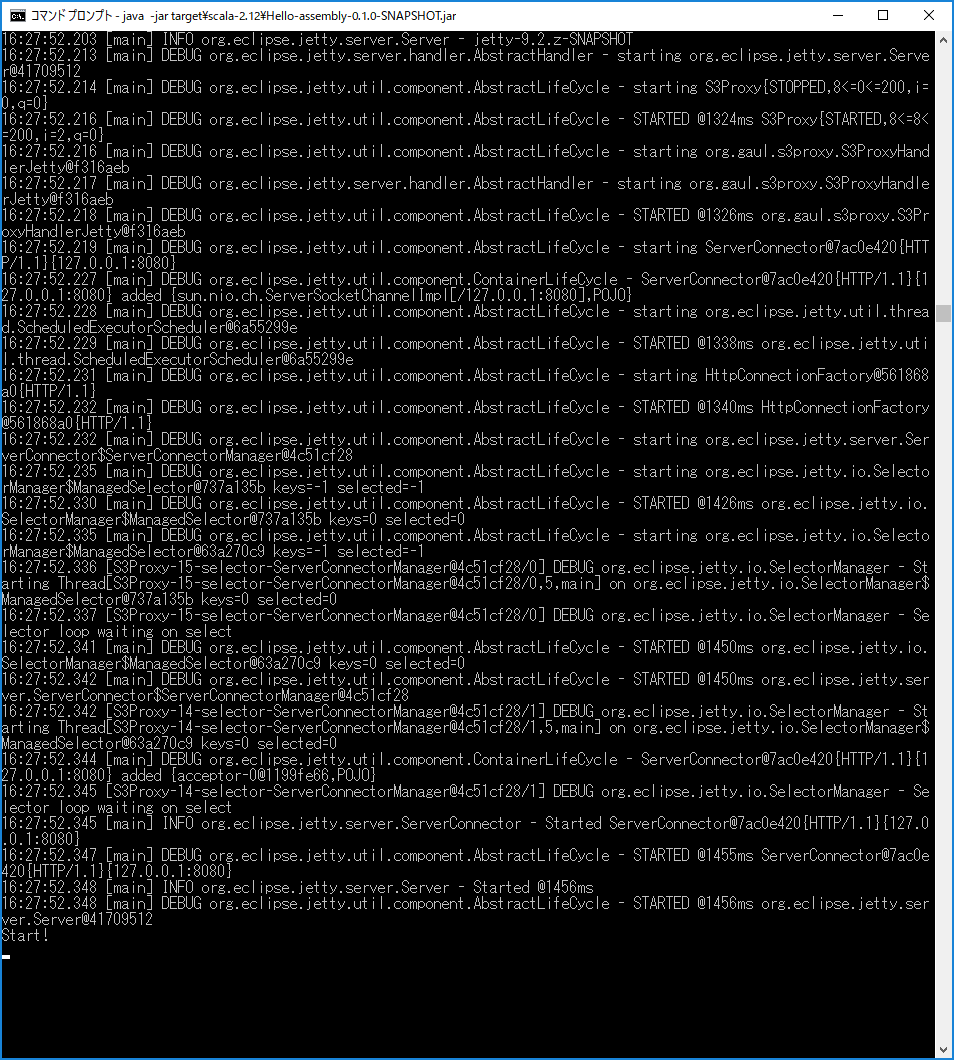
Start !
問題なく実行されました。
実行
前回の記事と同様に、curlコマンドを使って新しいフォルダを作ってみます。
testfolderというコンテナを作ってみましょう。
curlを叩いて実行してみます。
$ curl -X PUT http://localhost:8080/testfolder

成功したようですね。
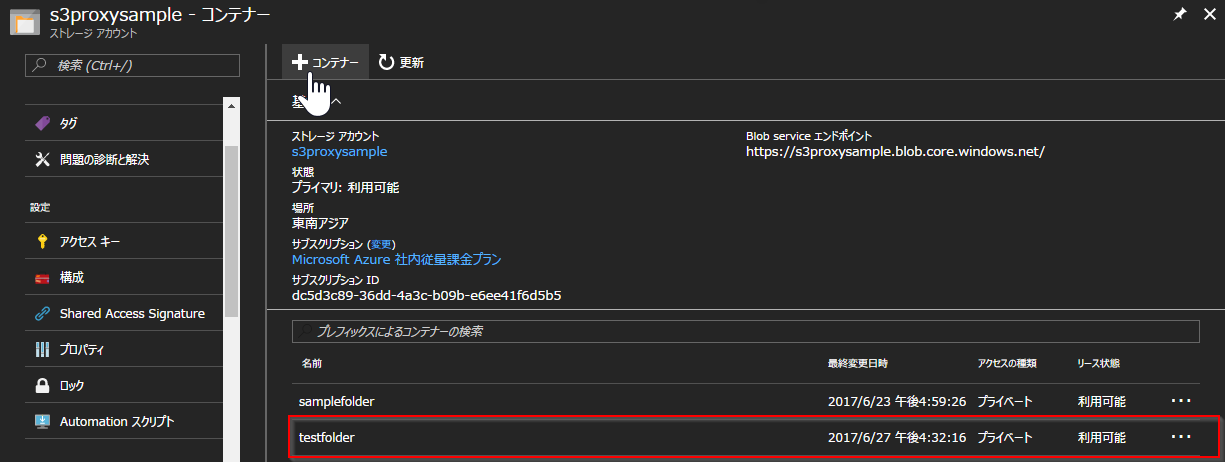
__testfolder__が作成されていることが確認できました!
まとめ
実際にS3Proxyライブラリを使ってS3Proxyを実装してみました。
Java互換の言語という意味でも簡単に実装することができました。
特に各クラウドサービス独特の設定はミドルウェア吸収されており、
インターフェースを変えることなく__Azure Blob Storage__へアクセスすることができ、
大変有用はミドルウェアであることが分かりました。
次の展開としては__Azure HDInsight__の__Spark__と連携して、__Azure Blob__への読み書きの実装をためして、マルチクラウドへの実行可能性の検証をすすめようと考えております。