テレビで素敵なサイトが紹介されていたのでアクセスしてみたら、なかなかレスポンスが返ってこなかったりステータスコード503になったりすることってありますよね。
テレビで紹介されたことで多くの人がサイトにアクセスした結果、そのサービスのキャパシティを超えてしまったわけです。
どうなるとキャパシティを超えるのでしょうか? また、いつからレスポンスが遅くなるのでしょう。
効果的にリクエストをさばくにはどうしたらいいのでしょう。

Photo by Roman Arkhipov on Unsplash
待ち行列理論を使って理想的なモデルからこれらを考えてみたいと思います。
待ち行列理論はコンピュータサイエンスをやってきた人はみんな触れたことがあるとは思いますが、大石の場合はそれが何十年も(!)前のことなのであらためて思い出してみました。![]()
モデル
Railsでサービスを提供するとき、rackサーバとしてはunicornかpumaを選択することが多いでしょう。
ここではunicornを例にして考えてみます。Railsになじみのない人にもわかるように、unicornがどうやってやってきたリクエストを処理しているのかを図で示してみます。
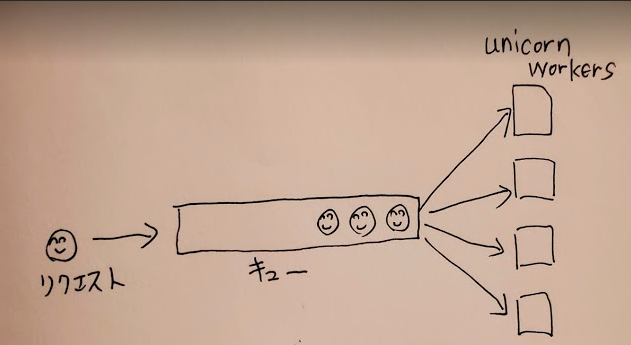
unicornはworkerプロセスを複数起動することによって並列処理を実現しています。
リクエストを受け付けるソケットはひとつだけで、手の空いているworkerプロセスのどれかがそのソケットからリクエストを受け取って処理を行います。
待つための行列はひとつだけで、処理するサービスが複数存在していることになります。
銀行のATMで順番待ちするときと同じ状態ですね。銀行のATMも順番待ちの行列はひとつだけで、複数のATMが存在しています。
銀行がそうしている理由はちゃんとあって、それは待ち行列理論から導き出せます(この記事を読めばわかります)。
また、CPUやI/O処理については今回はまったく考えません。これらを考えないことで問題をシンプルに捉えることができます。
もちろん現実ではこれらの影響を受けるので、待ち行列理論で導き出される結論よりも状況はより早く悪くなるはずです。
サーバ1台、unicorn worker数もひとつ
まずシンプルに、サーバが1台で、その上で動いているunicorn workerプロセスはひとつという状況を考えます。
このサービスを提供するRailsアプリは、平均して処理に500msかかるとします。
このサービスへのリクエストは平均して1秒間に1回やってくるとします。
この場合、待ち行列の計算をすると以下の結果が得られます。
- サービス利用率: 50%
- 待ち行列の平均の長さ: 0.5
- サービスを受けられるまで待つ時間の平均: 500ms
- 平均レイテンシ: 1s
Railsは平均して500msで処理をしますが、ユーザーが体験するレイテンシは平均して1sになりました。サービスとしてはだめな状態ですね。
この計算をしたrubyのコードを載せておきます。
require 'bigdecimal'
class Queueing
def initialize(server: , worker: , req_sec:, service_time: )
@server = BigDecimal(server)
@worker = BigDecimal(worker)
@req_sec = BigDecimal(req_sec)
@service_time = BigDecimal(service_time)
@_factorial = {}
@_part = {}
raise "Over capacity!" if ρ >= 1
end
def λ
@λ ||= (@req_sec / @server)
end
def μ
1 / @service_time
end
def ρ
@ρ ||= (all_service_time / @worker)
end
def wait_time
(pro_of_use * @service_time) / (@worker * (1 - ρ ))
end
def latency
wait_time + @service_time
end
def wait_length
@wait_length ||= ((ρ * pro_of_use) / (1 - ρ ))
end
private
def all_service_time
λ * @service_time
end
def e_all_s
Math::E ** (-all_service_time)
end
def pro_of_use
(1 - ν ) / (1 - (ρ * ν ))
end
def ν
@ν ||= 1 - ((e_all_s * part(@worker)) / (e_all_s * all_part_sum))
end
def part(num)
@_part[num] ||= (all_service_time**num)/factorial(num)
end
def factorial(num)
@_factorial[num] ||=
if num == 0
1
else
num * factorial(num - 1)
end
end
def all_part_sum
(0..@worker).sum {|n| part(n) }
end
end
server, worker, req_sec, service_time = ARGV[0..3]
m = Queueing.new(server: server, worker: worker, req_sec: req_sec, service_time: service_time)
puts "λ : #{m.λ .to_f}"
puts "μ : #{m.μ .to_f}"
puts "ρ : #{m.ρ .to_f}"
puts "wait length: #{m.wait_length.to_f}"
puts "wait time: #{m.wait_time.to_f}"
puts "latency: #{m.latency.to_f}"
計算に必要な数式を知りたい人(いますか?)については最後に載せている参考文献を参照してください。
サーバーを2台にしてみる
ユーザーの体験が著しく悪いので、サーバーを増やして2台にしてみましょう。
結果、以下のようになりました。
- サービス利用率: 25%
- 待ち行列の平均の長さ: 0.0833
- サービスを受けられるまで待つ時間の平均: 167ms
- 平均レイテンシ: 667ms
ユーザーのレイテンシは1sから667msへと改善しました。かなりよくなりましたね。
サーバを3台にしてみる
- サービス利用率: 16.7%
- 待ち行列の平均の長さ: 0.0333
- サービスを受けられるまで待つ時間の平均: 100ms
- 平均レイテンシ: 600ms
1->2 台にしたときほどではないですが、レイテンシは600msになりました。いいですね。
サーバは1台で、unicorn workerを3にしてみる。
今度はサーバを1台に戻して、unicorn worker数を3にふやしてみましょう。
- サービス利用率: 16.7%
- 待ち行列の平均の長さ: 0.0003
- サービスを受けられるまで待つ時間の平均: 3ms
- 平均レイテンシ: 503ms
なんと、サーバを3台に増やすより、unicorn worker数を3つにしたほうが効果が大きくなりました。レイテンシは503msなので、ほぼRailsの処理時間そのままです。
サーバを3台にした場合の平均レイテンシがunicorn workerを増やしたときよりも悪いのは、それぞれのサーバごとに待ち行列ができるためです。
1台のサーバで処理に時間がかかるリクエストがあった場合、そのサーバの待ち行列に入ってしまったリクエストは軒並み影響を受けることになります。
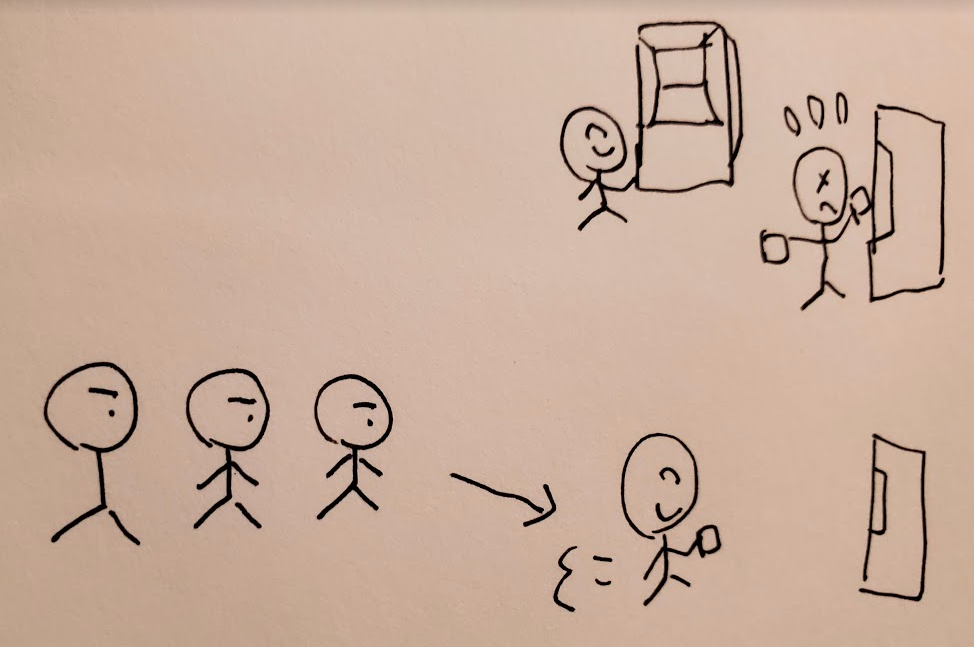
スーパーのレジを想像してみましょう。スーパーのレジは、レジごとに待ち行列があります。自分が並んだ列にレジの店員と長話をする人がいるとどうなりますか? 自分の順番が回ってくる時間が長くなってしまいますね。

では銀行のATMはどうでしょう。順番待ちの列はひとつで、ATMは複数台あります(unicornと同じですね)。たまたま大量に振り込み作業をする人がいたとしても、ほかのATMがあるので自分の順番が回ってくる時間はそれに影響をほぼ受けません。
待ち行列の計算でもこのことが表現されているわけです。
現実的なモデル
実際にサーバ1台でunicorn worker数1でサービスを運用する人はいないでしょう。
ここで現実的な値として以下の状況を想定してみます。
- サーバ台数: 30
- 1台あたりのunicorn worker数: 32
- Railsの平均処理時間: 500ms
サイト全体の平均処理時間がちょっと遅すぎますが、これで考えてみましょう。
960req/secのアクセス
平均して、1秒間に960のリクエストがやってくるとすると、結果は以下のとおりとなります。
- サービス利用率: 50%
- 待ち行列の平均の長さ: 0.0003
- サービスを受けられるまで待つ時間の平均: 0.009ms
- 平均レイテンシ: 500ms
Railsの平均処理時間とサービス稼働率は、サーバ1台、unicorn workerひとつのときと同じです。
しかし順番待ちの行列はほぼ空っぽで、レイテンシはRailsの処理時間そのままです。
これにはunicorn worker数が大きく影響しています。
960req/secをサーバ台数で割ると32req/secになります。つまり1台あたりのunicorn worker数と同じです。Railsの処理時間は500msなので十分に余裕があることになります。
このサイトを落とす
さて、このサイトを落とすにはどれくらいアクセスしたらいいでしょうか。
簡単に表にしてみました。
| req/sec | 利用率(%) | 待ち数 | レイテンシ(ms) |
|---|---|---|---|
| 960 | 50 | 0 | 500 |
| 1500 | 78 | 0.45 | 509 |
| 1600 | 83 | 1.18 | 522 |
| 1700 | 89 | 3.1 | 555 |
| 1800 | 94 | 9.45 | 658 |
| 1900 | 99 | 88.4 | 1896 |
| 1919 | 99.9 | 1912 | 30392 |
1920req/secになると利用率が100%となり、待ち行列は永遠に増え続けることになります。サイトが落ちるということです。
unicornで使用するソケットのbacklogはデフォルトで1024なので、待ち行列数がこれを超えるとユーザーにステータスコード502が返ることになります。これもまた、サイトが落ちていると同義でしょう。
そこまでいかなくても、1900req/secでレイテンシが1896msとなっており、ユーザーは遅いサイトにいらいらしている状態になっています。これもまた、ユーザーに価値を安定して届けているとはいえないでしょう。
上の表からわかるようにサイトの状態はリクエスト数の増加に比例して悪化するのではなく、それ以上の増加率をもって急激に悪化するのです。
ある限界点のような箇所を超えると急にリクエストが詰まり出すといった体験を、サービスを運用したことがある人なら誰でもしたことがあると思います。
その理由のひとつがここにあります。
サーバを増やすな、処理時間を減らせ
さて、いままでRailsの処理時間は500msでがんばってきましたが、とうとうパフォーマンス改善に着手することにしました。
計測して解析して問題点を特定し、Railsの平均処理時間を400msにすることに成功しました。
たった100msかあ...とがっかりしたけどリリースしてみたらびっくり。サイトのキャパシティが大幅に向上したのです。
いままでサイトが確実に落ちていた1920req/secをさばけるようになりました。
そのリクエストがきても以下の状況です。多少の余裕さえもうかがえます。
- サービス利用率: 80%
- 待ち行列の平均の長さ: 0.64
- サービスを受けられるまで待つ時間の平均: 10ms
- 平均レイテンシ: 410ms
平均処理時間500msのまま、同様の待ち行列数の状態にするにはサーバを38台まで増やす必要がありました。
にしても、ユーザーが体験するレイテンシは410msと510msです。ユーザーは当然のことながら前者を支持するでしょう。
サイト運営者としても無駄に8台もサーバを増やさずに済みました(32のunicorn workerが動くスペックのAPサーバ8台を購入して運用するコストはいくらでしょうか...)。
待ち行列理論から考えると、処理時間の改善が与えるインパクトの大きさに驚きさえ覚えます。
SREが処理時間の悪化に目を光らせている理由がよくわかると思います。みなさんが考えているよりも、処理時間がサイト全体に与える影響ははるかに大きいのです。
稼働率50%にするために必要なサーバ台数と処理時間の関係
unicorn worker数は32のまま、1000req/secをさばきつつ稼働率50%以下にするために必要なサーバ台数が、平均処理時間によってどれくらい変化するかを計算してみました。
以下のようになります。
| 平均処理時間(ms) | 必要なサーバ台数 |
|---|---|
| 200 | 13 |
| 300 | 19 |
| 400 | 25 |
| 500 | 32 |
| 600 | 38 |
| 700 | 44 |
| 1000 | 63 |
| 2000 | 125 |
まとめ
- 待ち行列はサービスを処理するプロセスごとに用意するのではなく、全体でひとつにしたほうが効率がよい
- 稼働率が100%に近づくと待ち行列数は跳ね上がる(100%では無限大になる)
- サーバやプロセスを増やすよりも、処理時間を改善したほうが効果がはるかに大きい
改善できる処理にはちゃんと手を入れて処理時間を減少させることが、安定して価値をユーザーに届けるために重要なことだということがわかりました。
明日は食べログアドベントカレンダー2020の7日目の記事が公開されるのでご期待ください!
参考文献