HTTPはどうやってデータを渡しているか
本記事の目的
HTTPはネットでWebサイトにアクセスするにはほぼ使われるプロトコルとなった。
そのHTTPの情報を渡すためにはどのようになっているか概要を共有し、普段使っている技術に詳しくなってもらい セキュリティに敏感になってもらうこと を目的とする
お断り
本記事ではHTTPにおけるデータのやり取りのうち筆者が身近だと感じた点について記載する。
OSI参照モデルなどを期待された方は別の記事を参考にしてください。
TL;DR
- クエリ、ヘッダー、ボディの3箇所に任意の情報を持たせることができる
- Webページ/アプリであるアクションを契機にHTTPに情報を持たせてリクエストを実行することで情報のやり取りを行うことができる。
HTTPとは
GitHub Copilot Chatに解説してもらった。
HyperText Transfer Protocolの略で、ウェブブラウザとウェブサーバー間で情報をやり取りするためのプロトコル(通信規約)です。ウェブページを閲覧する際に、ブラウザはHTTPを使用してウェブサーバーにページの内容を要求し、サーバーはHTTPを使用してその内容をブラウザに送信します。
HTTPはステートレスなプロトコルで、それぞれのリクエストとレスポンスが独立しているため、サーバーは過去のリクエストや次のリクエストについて記憶していません。これにより、ウェブは大規模なユーザーと情報のやり取りを効率的に処理することができます。
HTTPリクエストは、メソッド(GET、POSTなど)、URL、ヘッダー、ボディから構成されます。メソッドはリクエストの種類を示し、URLはリクエストの対象を示し、ヘッダーはリクエストに関する追加情報を提供し、ボディは送信するデータを含みます。
HTTPレスポンスは、ステータスコード(200、404など)、ヘッダー、ボディから構成されます。ステータスコードはリクエストの結果を示し、ヘッダーはレスポンスに関する追加情報を提供し、ボディは要求されたデータを含みます。
クエリパラメータ
GitHub Copilot Chatに解説してもらった。
クエリパラメータは、URLの一部で、特定の情報をウェブサーバーに送信するために使用されます。これは通常、ウェブページの特定のビューや結果を取得するために使用されます。
クエリパラメータは、URLの末尾にある「?」記号の後に配置され、キーと値のペアで構成されます。複数のクエリパラメータは「&」記号で区切られます。
例えば、次のURLでは、searchとpageはクエリパラメータのキーで、それぞれの値はgithubと2です。
http://example.com/?search=github&page=2
これらのパラメータは、ウェブサーバーがリクエストを処理する方法を制御します。この例では、サーバーはgithubというキーワードで検索を行い、結果の2ページ目を返すように指示されます。
ヘッダー
GitHub Copilot Chatに解説してもらった。
リクエストヘッダーは、HTTPリクエストの一部で、クライアント(通常はウェブブラウザ)がサーバーに送信する追加情報を含みます。これらの情報は、リクエストの内容、クライアント自体、またはリクエストの目的に関する詳細を提供します。
リクエストヘッダーには以下のようなものがあります:
Accept: クライアントが理解できるコンテンツタイプ
Cookie: クライアントがサーバーから以前に受け取ったクッキー
User-Agent: クライアントのソフトウェア(ブラウザやOSなど)の情報
Authorization: クライアントの認証情報
これらのヘッダーは、サーバーがリクエストをどのように解釈し、レスポンスをどのように形成するかを決定するのに役立ちます。例えば、Acceptヘッダーはサーバーに、クライアントが理解できるデータ形式(HTML、JSONなど)を伝えます。
GET /api/users HTTP/1.1
Host: example.com
Accept: text/html, application/xhtml+xml, application/xml;q=0.9, image/webp, */*;q=0.8
Content-Type: application/json
{
"name": "Alice",
"email": "alice@example.com"
}
ボディ
GitHub Copilot Chatに解説してもらった。
HTTPリクエストのボディは、クライアントがサーバーに送信するデータを含む部分です。GETリクエストなどの一部のHTTPメソッドではボディは使用されませんが、POSTやPUTのような他のメソッドでは、新しいリソースを作成したり、既存のリソースを更新したりするためにボディが使用されます。
ボディの内容は、リクエストヘッダーのContent-Typeフィールドによって指定される形式で送信されます。一般的な形式には、application/json(JSONデータ)、application/x-www-form-urlencoded(HTMLフォームから送信されるデータ)、multipart/form-data(ファイルアップロードなど)などがあります。
例えば、次のようなHTTP POSTリクエストでは、ボディはJSON形式のデータを含んでいます:
POST /api/users HTTP/1.1
Host: example.com
Content-Type: application/json
{
"name": "Alice",
"email": "alice@example.com"
}
このリクエストは、新しいユーザーを作成するためにサーバーに送信され、ユーザーの名前とメールアドレスがJSON形式でボディに含まれています。
HTTPの通信は以下のステップで行われます:
ユーザーがブラウザで検索を行う: ユーザーがブラウザの検索バーにキーワードを入力し、検索を開始します。
Webページの動き
GitHub Copilot Chatに解説してもらった。
ブラウザがHTTPリクエストを作成する: ブラウザは検索クエリを含むHTTP GETリクエストを作成します。このリクエストは、検索エンジンのサーバー(例えば、Googleのサーバー)に送信されます。
HTTPリクエストをサーバーに送信する: ブラウザは作成したHTTPリクエストをインターネットを通じてサーバーに送信します。
サーバーがリクエストを処理する: サーバーは受け取ったリクエストを解析し、必要な情報(この場合は検索クエリ)を抽出します。次に、そのクエリに対する検索結果を生成します。
サーバーがHTTPレスポンスを作成する: サーバーは検索結果を含むHTTPレスポンスを作成します。このレスポンスは、ステータスコード(通常は200)、レスポンスヘッダー、そしてレスポンスボディ(HTML形式の検索結果)を含みます。
HTTPレスポンスをブラウザに送信する: サーバーは作成したHTTPレスポンスをインターネットを通じてブラウザに送信します。
ブラウザがレスポンスを解析する: ブラウザは受け取ったレスポンスを解析し、HTML形式の検索結果を表示します。
以上が、ブラウザで検索サービスを使用する際のHTTP通信の基本的なステップです。
デモ
Googleの検索を見てみる。
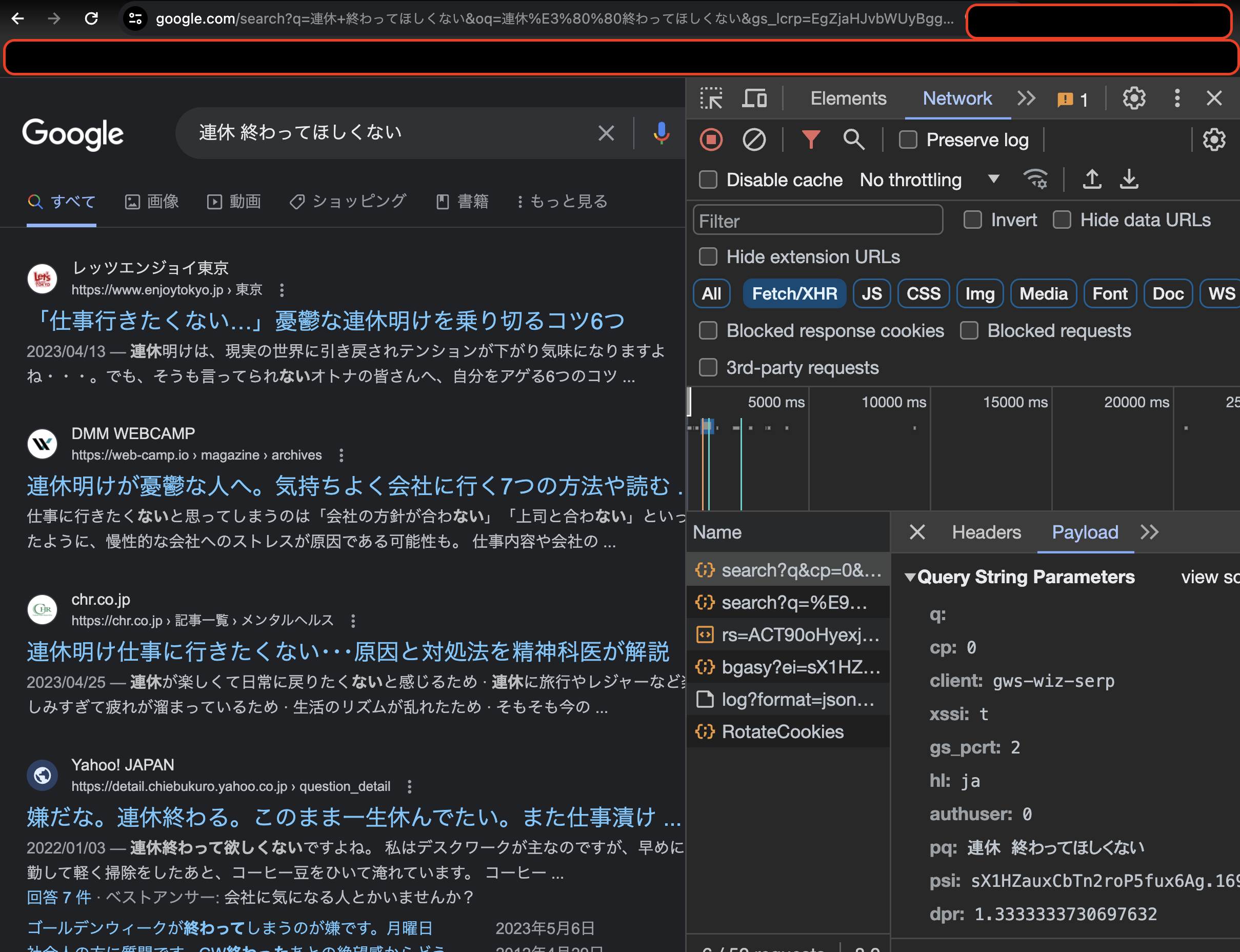
検索ボタンをクリックすると大量のクエリパラメータがURLに入っている。
その中でpqが検索ボックスに入力した文字列であった。
(ページを移動すると今何ページ目かの情報も入る。)