フューチャーアーキテクト Advent Calendar 2016の21日目1の記事です。
競技プログラミングにおける、所謂ゲームAI系の長期コンテストについて書きます。
また、巷でよく聞く「競技プログラミングって仕事で役に立つんですか?」について、最後に少し触れます。
ゲームAIは面白そうだけど敷居が高いと感じるあなたへ
本記事は、ゲームAIコンテストがどんなものかなんとなく知っている、けどちゃんと取り組んだことが無いという人に向けた記事です。「初耳なんですが…」という方は、下記の素晴らしい記事を一読下さい。
- 強くなるためのプログラミング -様々なプログラミングコンテストとそのはじめ方- by ぴよぴよ.py
- ゲームAIコンテストのすすめ by iwashi31’s diary
なお、本記事ではサンプルコードをjava2で記載します。忙しいあなたも本記事のコードをコピー&ペースト、自分なりのカスタマイズを施して遊んでみて下さい。
※java以外の言語の方も、汎用的なアルゴリズムですので使用する言語の表現に直せばOK!
お題:Tron Battle
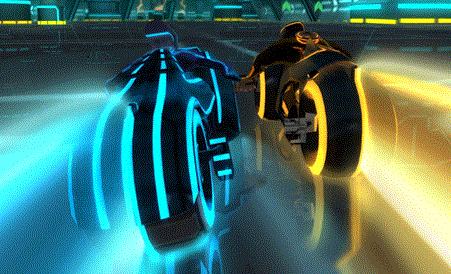
上記で紹介した「ゲームAIコンテストのすすめ」でもお題となっていますが、コンテストサイト「codingame」より「Tron Battle」を題材にします。下記リンク先のJOINボタンよりいつでも遊ぶことができますので、是非コードを実行しながらリプレイを鑑賞してみて下さい。
https://www.codingame.com/multiplayer/bot-programming/tron-battle
※ランキングに挑戦するにはログインが必要ですが、テスト実行だけであればログイン不要です。
ルール
- 縦20×横30マスのフィールドで2~4人のプレイヤーで対戦。
- 各プレイヤーは交互に上下左右のいずれかのマスに移動する。その場にとどまることはできない。
- 各プレイヤーが通ったセルは通行不可となる。
- フィールド外や通行不可のセルへ移動したプレイヤーは脱落、そのプレイヤーが通った跡のセルは再び通行可能となる。
- 入力が与えられてから100ms以内に次の手を出力できなかったら脱落。
- 最後まで脱落しなかった人が勝者。
シンプルなルールなので、リプレイを見て頂ければすぐに解ると思います。それでは早速やってみましょう。
自殺しないAIを作る

スーパーファミコンの名作「ボンバーマン」で、開始直後に誤って爆弾を置いてしまい、早々に敗退した苦い思い出が皆さんにもありませんか?私はよくあります。対戦ゲームにおいて自殺してしまうほど悲しいことはありません。
codingameでは、各言語のサンプルコードがデフォルトで設定されているのですが…。(一部省略)
class Player {
public static void main(String args[]) {
Scanner in = new Scanner(System.in);
while (true) {
int N = in.nextInt(); // total number of players (2 to 4).
int P = in.nextInt(); // your player number (0 to 3).
for (int i = 0; i < N; i++) {
int X0 = in.nextInt(); // starting X coordinate of lightcycle (or -1)
int Y0 = in.nextInt(); // starting Y coordinate of lightcycle (or -1)
int X1 = in.nextInt(); // starting X coordinate of lightcycle (can be the same as X0 if you play before this player)
int Y1 = in.nextInt(); // starting Y coordinate of lightcycle (can be the same as Y0 if you play before this player)
}
System.out.println("LEFT"); // A single line with UP, DOWN, LEFT or RIGHT
}
}
}
コードの最下部をご覧頂ければわかる通り、ひたすら左へ突っ走るだけのコードなのですぐに場外、自殺してしまいます。これをベースに、まずは自殺しないAIを作成します。
できました。(import文省略)
class Player {
// 上下左右への移動
static final int[] dx = new int[] { 1, 0, -1, 0 };
static final int[] dy = new int[] { 0, 1, 0, -1 };
static final String[] OUTPUT = new String[] { "RIGHT", "DOWN", "LEFT", "UP" };
static final int MAX_PLAYER_NUM = 4;
static final int COL = 30;
static final int ROW = 20;
public static void main(String args[]) {
Scanner in = new Scanner(System.in);
Player play = new Player();
Node now = null;
while (true) {
now = play.input(in, now);
Node ans = play.search(now);
System.out.println(ans.output);
now = ans;
}
}
private Node input(Scanner in, Node before) {
int N = in.nextInt(); // total number of players (2 to 4).
Node now = (before == null) ? new Node(N) : new Node(before);
now.P = in.nextInt(); // your player number (0 to 3).
for (int i = 0; i < now.N; i++) {
now.X0[i] = in.nextInt();
now.Y0[i] = in.nextInt();
now.X1[i] = in.nextInt();
now.Y1[i] = in.nextInt();
now.lockedField[i][now.X0[i]][now.Y0[i]] = true;
now.lockedField[i][now.X1[i]][now.Y1[i]] = true;
}
return now;
}
private Node search(Node now) {
PriorityQueue<Node> nexts = new PriorityQueue<Node>(Collections.reverseOrder());
for (int i = 0; i < dx.length; i++) {
Node next = new Node(now);
next.X0[now.P] = next.X1[now.P];
next.Y0[now.P] = next.Y1[now.P];
next.X1[now.P] += dx[i];
next.Y1[now.P] += dy[i];
next.output = OUTPUT[i];
next.score += eval(next);
nexts.add(next);
}
return nexts.poll();
}
private int eval(Node next) {
int x = next.X1[next.P];
int y = next.Y1[next.P];
if (canMove(next, x, y)) {
return 0;
} else {
return -1; // 通れない場合はマイナス減点。
}
}
private boolean canMove(Node n, int x, int y) {
if (x >= 0 && x < COL && y >= 0 && y < ROW) {
for (boolean[][] lf : n.lockedField) {
if (lf[x][y]) {
return false; // 通過済の場所は通れない。
}
}
return true;
}
return false; // 場外は通れない。
}
class Node implements Comparable<Node> {
public boolean[][][] lockedField = new boolean[MAX_PLAYER_NUM][COL][ROW]; // 通過済の場所を記憶する。
public Node parent = null;
public String output = null;
public int[] X0, Y0, X1, Y1;
public int P, N;
public int score;
public Node(int n) {
this.N = n;
X0 = new int[n];
Y0 = new int[n];
X1 = new int[n];
Y1 = new int[n];
}
public Node(Node n) {
this.parent = n;
this.score = n.score;
this.N = n.N;
this.P = n.P;
this.X0 = Arrays.copyOf(n.X0, n.X0.length);
this.Y0 = Arrays.copyOf(n.Y0, n.Y0.length);
this.X1 = Arrays.copyOf(n.X1, n.X1.length);
this.Y1 = Arrays.copyOf(n.Y1, n.Y1.length);
for (int i = 0; i < MAX_PLAYER_NUM; i++) {
for (int j = 0; j < COL; j++) {
for (int k = 0; k < ROW; k++) {
this.lockedField[i][j][k] = n.lockedField[i][j][k];
}
}
}
}
// ソート用
@Override
public int compareTo(Node o) {
return Double.compare(this.score, o.score);
}
}
}
上記コードでは下記のように処理を進めます。
- 入力(input:入力値を保存。)
- 探索(search:次のターンの候補:上下左右ぞれぞれに動くパターンを導出する。)
- 評価(eval:候補毎のスコアを算出する。今回は、通行不可の場合は減点する。)
- 出力(標準出力:最もスコアの高い移動方向を出力する。)
これで自殺しない子3ができました。早速ランキングに挑ませて見ましょう。
現時点で約3700人の参加者がいるので、真ん中から下くらいの実力みたいです。(2016/12/21時点)
更なる高みを目指して、オレ達の戦いはまだまだ続く!(そしてここからが本番です。)
先読みするAIを作る
先のAIは、なぜもっと上位にいけないのでしょうか?敗戦理由を探るため、リプレイを研究してみましょう。(こちら:黄色、あいて:赤色)

なるほど、自分から活路がない所に突っ込んでいますね。人間の目から見れば、ある程度先読みして上記のような道は避けるべきだと判断できます。ゲームAIというからには、人間が当然考えるような行動くらいはとって欲しいですよね?とらせましょう!
とらせました。
class Player {
// (変更なし)
static final int SEARCH_DEPTH = 100; // 100ターン先読みする。
// (変更なし)
private Node search(Node now) {
PriorityQueue<Node> nexts = new PriorityQueue<Node>(Collections.reverseOrder());
nexts.add(now);
for (int r = 0; r < SEARCH_DEPTH; r++) { // 指定していたターン分先読みする。
PriorityQueue<Node> tmp = nexts;
nexts = new PriorityQueue<Node>(Collections.reverseOrder());
while (tmp.size() > 0) {
Node n = tmp.poll();
for (int i = 0; i < dx.length; i++) {
Node next = new Node(n);
next.X0[now.P] = next.X1[now.P];
next.Y0[now.P] = next.Y1[now.P];
next.X1[now.P] = next.X1[now.P] + dx[i];
next.Y1[now.P] = next.Y1[now.P] + dy[i];
next.output = OUTPUT[i];
next.score += eval(next);
nexts.add(next);
}
}
}
Node cur = nexts.poll();
while (cur.parent != now) {
cur = cur.parent;
}
return cur;
}
private int eval(Node next) {
int x = next.X1[next.P];
int y = next.Y1[next.P];
if (canMove(next, x, y) && next.score >= 0) { // 既に脱落していた場合は減点。
next.lockedField[next.P][next.X1[next.P]][next.Y1[next.P]] = true;
return 0;
} else {
return -1;
}
}
// (変更なし)
}
100手まで先読み4し、活路が残る方向にしか移動しないAIです。これは強い!(確信)
早速戦わせましょう!
が、突然のエラー!
エラーメッセージからは、何やらtimeoutがどうのこうのと言われています。ちょっとルールをおさらいしてみましょう。
- 入力が与えられてから100ms以内に次の手を出力できなかったら脱落。
どうやら、100手先まで読むのは実行時間上難しいようです。とりあえず、ギリギリ時間内に先読み可能なターン数を調べましょう。調べました。どうやら5ターンが限界のようです。仕方がありません。今日はこのへんで勘弁してあげましょう。
とりあえず5ターン先読みでランキングに挑戦します。
結果、少しは上がりましたが5ターンだけでは大して強くなりませんね…。この先どうすればいいのでしょう…。
賢く先読みするAIを作る
AI作成で詰まった時は、人間ならどう考えるか立ち戻って考えます。あなたは一手一手、全てのパターンを考えながら先読みしますか?しませんよね?大変だし。
もしかして、あなたなら数多のパターンの中から比較的良さそうな手だけをピックアップし、その先が上手くいくかどうかをだけ考えるのではないでしょうか?実は、これをモデル化したものがゲーム木であり、そのゲーム木から良さそうな手を探すのがゲーム木探索です5!(ようやくタイトル回収)
先のAIのゲーム木は、全ての手を調べようとするあまり、単純計算で
4(ターン毎の手のパターン) ^ 100(先読みターン数) = 16069400…(0が50個続く)…000 パターン
もの手を調べる必要があります。そりゃあ時間内に終わらないわけだ。
では、このゲーム木の中から、良さそうな場合だけ選択していきましょう!
候補を絞って探索する(ビームサーチ)
では、どうやって良さそうな場合をピックアップするか考えていきます。現在は、通行不可を通った以降は減点し続ける評価関数となっています。多数の減点されたパターンまで先読みするのは無駄ですよね。絞りたいです。
そんな時、競技プログラミングでよく使われるアルゴリズム、ビームサーチを紹介します。ビームサーチは、総当りではなくいくつかの候補だけをピックアップし、先読みする手法です。
ということで、今回はターン毎にスコア上位20個くらいをピックアップしてみましょう。先読みターン数はどうしましょうか?どうせなら、先程できなかった100ターンに再チャレンジ6したいですね。
しました。
class Player {
// (変更なし)
static final int SEARCH_DEPTH = 100; // 100ターン先読み
static final int BEAM_WIDTH = 20; // 候補のスコア上位20個をピックアップ
// (変更なし)
private Node search(Node now) {
PriorityQueue<Node> nexts = new PriorityQueue<Node>();
nexts.add(now);
for (int r = 0; r < SEARCH_DEPTH; r++) {
PriorityQueue<Node> tmp = new PriorityQueue<Node>(Collections.reverseOrder());
for (int i = 0; i < BEAM_WIDTH && nexts.size() > 0; i++) {
tmp.add(nexts.poll()); // 上位20個だけをピックアップ。
}
nexts = new PriorityQueue<Node>(Collections.reverseOrder());
while (tmp.size() > 0) {
Node n = tmp.poll();
for (int i = 0; i < dx.length; i++) {
Node next = new Node(n);
next.X0[now.P] = next.X1[now.P];
next.Y0[now.P] = next.Y1[now.P];
next.X1[now.P] = next.X1[now.P] + dx[i];
next.Y1[now.P] = next.Y1[now.P] + dy[i];
next.output = OUTPUT[i];
next.score += eval(next);
nexts.add(next);
}
}
}
Node cur = nexts.poll();
while (cur.parent != now) {
cur = cur.parent;
}
return cur;
}
// (変更なし)
}
お手軽ですね♪
今度はtimeoutもないようです。ランキングはどうでしょう。

上がりました。上位1/3に食い込みました!
ここまできたら、もっともっと先のターンまで考えたくなってきます。どうせなら制限時間めいっぱい使いたいですね。何か手はないでしょうか。
制限時間いっぱいまで探索する(chokudaiサーチ)
そんな時によく使われるのが、通称chokudaiサーチ7です。
先のアルゴリズムをちょちょいとすると、できます。
できました。
class Player {
// (変更なし)
static final int SEARCH_DEPTH = 150; // 150ターンまで先読みを伸ばす。
static final long TIME_LIMIT = 40_000; // この時間内めいっぱい探索する。
// (変更なし)
private Node search(Node now) {
@SuppressWarnings("unchecked")
PriorityQueue<Node>[] beam = new PriorityQueue[SEARCH_DEPTH + 1]; // 各ターンの候補を保存しておく。
for (int i = 0; i <= SEARCH_DEPTH; i++) {
beam[i] = new PriorityQueue<>(Collections.reverseOrder());
}
beam[0].add(now);
long startTime = System.nanoTime();
while ((System.nanoTime() - startTime) / 1000 <= TIME_LIMIT) { // 指定時間いっぱい探索する。
for (int r = 0; r < SEARCH_DEPTH; r++) {
Node n = beam[r].poll(); // 各ターン毎にひとつずつ探索。
if (n != null) {
for (int i = 0; i < dx.length; i++) {
Node next = new Node(n);
next.X0[now.P] = next.X1[now.P];
next.Y0[now.P] = next.Y1[now.P];
next.X1[now.P] = next.X1[now.P] + dx[i];
next.Y1[now.P] = next.Y1[now.P] + dy[i];
next.output = OUTPUT[i];
next.score += eval(next);
beam[r + 1].add(next);
}
}
if ((System.nanoTime() - startTime) / 1000 > TIME_LIMIT) { // 途中でも時間がきたら中断する。
break;
}
}
}
Node cur = beam[SEARCH_DEPTH].poll();
while (cur.parent != now) {
cur = cur.parent;
}
return cur;
}
// (変更なし)
}
かんたんに特徴を説明します8。ビームサーチは一ターンずつ先読みを深めていくのに対し、chokudaiサーチは、まだ未探索のスコア上位の候補をターン毎にひとつずつ読み進めていき、目的ターンに到達したらまた頭にもどります。これを制限時間いっぱいにくりかえして、得られた候補の中からもっとも良い手を選ぶアルゴリズムです。これにより、先読み数を150ターンまで伸してみました。※ただし、その分探索した候補数は少なくなります。
さて、気になるランキングは?

ほとんど変わりませんね。なぜでしょうか?
実は今のプログラムでは、先読みしている間は自分の動きしか考慮していません。「Tron Battle」は対戦ゲームのため、当然相手も動いてきます。
一般的に、二人対戦ゲームでは、自分の手×相手の手の数のゲーム木を作り、それをゲーム木探索していきます。しかし、今回の「Tron Battle」では、2~4人の対戦ゲームであり、ゲーム木はプレイヤー数に応じて指数的に複雑になってしまいます。
何か良い方法はないでしょうか?
最新のアルゴリズムを使ってみる(モンテカルロ木探索)
この記事を読まれている方々の中に「AlphaGo」を知らない方はいないでしょう。そう、AIが囲碁のチャンピオンに勝つという、歴史的な出来事を実現させた、あの「AlphaGo」です。「AlphaGo」は、よく「Deep Learning」とセットで語られますが、もうひとつ特徴的なアルゴリズムを用いています。それが「モンテカルロ木探索(MCTS)」です。
アルゴリズムの仕組みは、下記の記事の説明がとても分かりやすいです。
モンテカルロで二人ゲーム by ustimawのブログ
早速「モンテカルロ木探索」を使ってみようと思ったのですが、ちょっと投稿日までに間に合いそうにないので、スキップします。すみません。すみません。もし暇ができたら追記します。
僕が考えた最強のAIを作る
さて、いくつかアルゴリズムを紹介してきましたが、トップはまだまだ遠いです。おそらく、使っているアルゴリズム自体には大差ないと思います。では何が違うか。"評価"部分です。
本記事は探索アルゴリズムに焦点を絞り、評価は「通行不可の場合に減点」という単純なものとしています。これに、下記のような改善を加えればグングンとランキングは上がるはずです。是非、色々試してみて下さい。その試行錯誤こそが競技プログラミングの醍醐味です。
- 脱落する場合を候補から省く9。
- なるべく真ん中のエリアを通ると加点。
- 相手の活路を塞ぐルートを通ると加点。
競技プログラミングとお仕事
競技プログラミングは、情報系の高専生~大学院生辺りがボリュームゾーンだからでしょうか、よく「競技プログラミングの能力は仕事で役に立つか?」という議論で盛り上がります。
※今年のAdventカレンダーでも盛り上がっています。
競技プログラマは競プロのコンテストを開いてる会社に就職しろ! by chokudaiのブログ2
私の意見は、
役に立つ。けど、本当に生かせる仕事は多くはない。
です。
競技プログラミングで身につく本質的な能力は、実際のデータの特性を捉えた新しい処理方法を素早く生み出せることにあると考えています。それは、学術的なR&Dとは少し異なり、決められた仕様に沿ったITシステム構築とは当然違う、その間に位置する仕事で最も価値を発揮するものではないでしょうか10。
では、そんな仕事はどこにあるか?Googleのような巨大サービス事業者にあるでしょう。サービス事業者以外でも、大量のデータ・特徴的なデータを集められる企業では、そのようなポジションがあると思います。そして、弊社にもあります。
フューチャーアーキテクトの仕事では、私の知る範囲だと下記のようなものに生かせると思っています。
- これまで担当者の勘と経験から決めていた各種計画を、大量のデータから合理的に決定する仕組み作り。
- 大勢の人の手を用いて捌いていた作業を、自動化の実現性の高い部分から切り分け、効率化する仕組み作り。
実際、私の隣の案件は1.の例に該当し、ある企業に対し、焼きなまし等最適化アルゴリズムをかなりの規模の実データに適用する試みを行っています11。そして、その案件が終われば別の企業の同種の案件に携わります。技術を軸に、多種多用な領域でチャレンジできるのは、弊社の良いところだと思っています。
最後に
ここまで読んで頂きありがとうございました。
巨大なゲーム木の広がりと、その中からベストな一手を掴みとるアルゴリズムを考える…。そんな、ゲームAIコンテストの面白さが伝わり一人でも多くの仲間ができれば嬉しいです。
本記事で紹介したコンテストサイトでは、2017/2/26から8日間の新しいコンテストが開かれます。「Tron Battle」はすでに終了したコンテストですが、新しいコンテストでは全員0からのスタートで、上位者に景品も付きます。興味を持たれた方は、是非一緒に参加しましょう!
参加URL:https://www.codingame.com/contests/ghost-in-the-cell
-
今日は筆者の誕生日です。ハッピバースデートゥーミー♪ プレゼント代わりに「いいね」をお願いします。 ↩
-
自分でコーディングしたプログラムを"子供"と表現してしまうのはなぜなんでしょうか? ↩
-
所謂「幅優先探索」です。 ↩
-
厳密な定義よりも、直感的にわかる表現を優先しています。 ↩
-
実際には実行時間を測りながら詰めていくんですが、今回は省略。 ↩
-
この界隈で知らない人はいない高橋直大さんがよく使っていたため。学術名は不明。 ↩
-
詳細はググって下さい。 ↩
-
本来真っ先にやるべきなんですが、今回はアルゴリズムにフォーカスしたかったので許してください。 ↩
-
ましてや、単純に"プログラミングができる"という評価では物足りないですよね。 ↩
-
私もそのうち一枚噛ませてもらおうと画策中です。 ↩