久しぶりのQiita投稿です.現在,三菱UFJフィナンシャル・グループの戦略子会社であるJapan Digital Design株式会社でリサーチャーをしています.こちらは,Japan Digital Design Advent Calendar 2023 の7日目の記事になります!
本記事では,「強化学習を使ってポケモンをプレイする動画」についてご紹介させていただきます!

※ 動画内容の切り抜き利用につきましては,Peter Whidden氏の許可を頂いております.
※ 本記事では,ポケモンをプレイするための技術を解説していきますが,動画で見た方が面白いので,ご興味のある方はぜひご覧になってみてください!
導入
みなさま強化学習(reinforcement learning)をご存知でしょうか?
強化学習とは,機械学習の手法1つで,エージェント(AI)が環境とのやり取りを通じながら,累積報酬の期待値を最大にするように学習していく方法です.このような流れは以下の図のようになります.
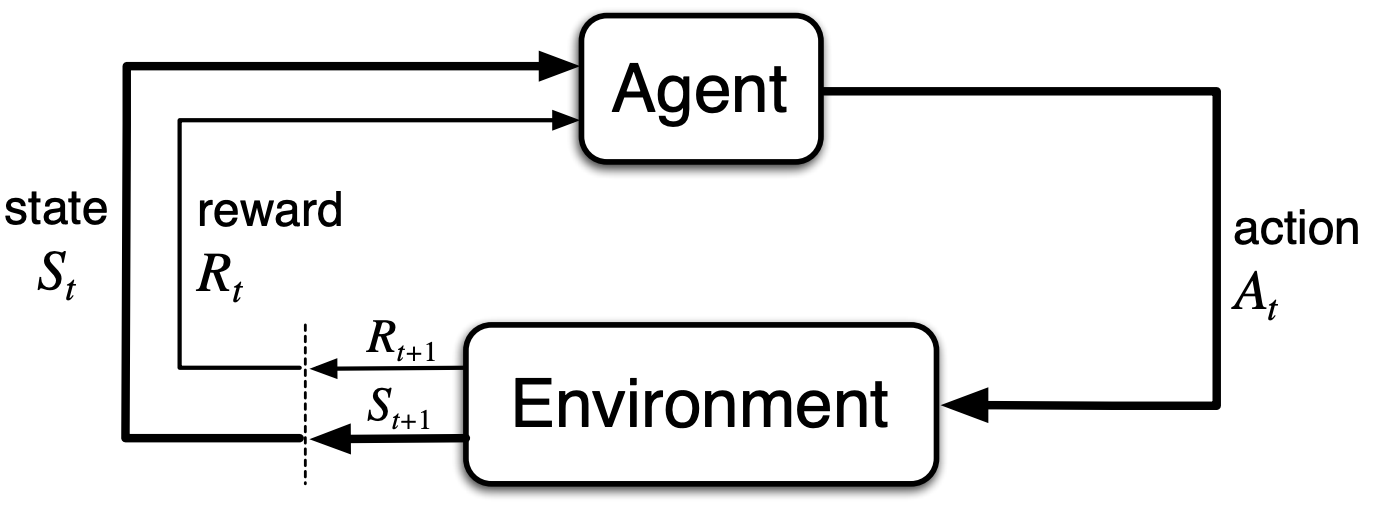 (引用元:Reinforcement Learning An Introduction 2nd Edition, R.S. Sutton and A.G. Barto)
(引用元:Reinforcement Learning An Introduction 2nd Edition, R.S. Sutton and A.G. Barto)
この強化学習と呼ばれる機械学習技術は,実際に様々なところで応用されています.例えば,ゲームの分野やロボット制御,自動運転,創薬の設計,金融市場におけるトレード,大規模言語モデル(LLM)の学習などです.
DeepMind社が開発した強化学習モデル(AlphaGo)が,囲碁のトッププロを破った時は,衝撃を感じました.囲碁は大量の行動パターンがありAIでは人を越えられないと言われていました.現在では,囲碁・将棋・チェス・Atariといった異なるゲームにも対応できるといったモデル(MuZero)や,囲碁よりも探索範囲の広いStarCraft IIといったゲームにおいてもプロに匹敵するモデル(AlphaStar)も提案されています.また,マインクラフトを用いて強化学習アルゴリズムを研究する試みも盛んに行われています(MineDojo).そして,様々なゲーム・マインクラフトで圧倒的な性能を誇るモデル(DreamerV3)も提案されています.現在ではLLMでも強化学習に匹敵する,もしくは上回るパフォーマンスを出したりします(AutoGPT, SPRING, Voyager).
さて,このようにゲームでは圧倒的に強いAIを作ることができる強化学習の手法ですが,2023年10月に面白い動画がYouTube上に公開されました.AIがポケモンをプレイするという動画です.
人間ならポケモンをプレイすることは簡単にできますが,AIが学習するためには相当の工夫が必要です.この動画で使われている技術を解説していきながら,なぜAIがポケモンをプレイできるのかという所を深掘りしながら強化学習について紹介していきたいと思います.
本題
さて,導入で述べたように強化学習は累積報酬が最大になるようにエージェントが学習されると書きました.
では,どのようにエージェントを学習することができるのでしょうか?
強化学習では,報酬(reward)に基づきエージェントが最適な行動を行うように学習されていきます.良い行動を取れば良い報酬が得られます.悪い行動を取れば悪い報酬となってしまいます.強化学習を適用する上で最もチャレンジングなものの1つに報酬をどのように定義するかがあります.例えば,AIがポケモンをプレイできるように学習するために報酬を以下のように設定してみましょう.
- ポケモンを捕まえる:報酬+1
- バトルに勝つ:報酬+3
- ジムで勝つ:報酬+5
この報酬のルールではエージェントがどうやって行動すれば良いか中々判断できません.というのも,これだとポケモンを捕まえるまではランダムな行動をし続けて,一向に進みません.このような状況は強化学習ではよく起こる現象です.
全然別の例ですが,Vizdoomの場合を見てみましょう.
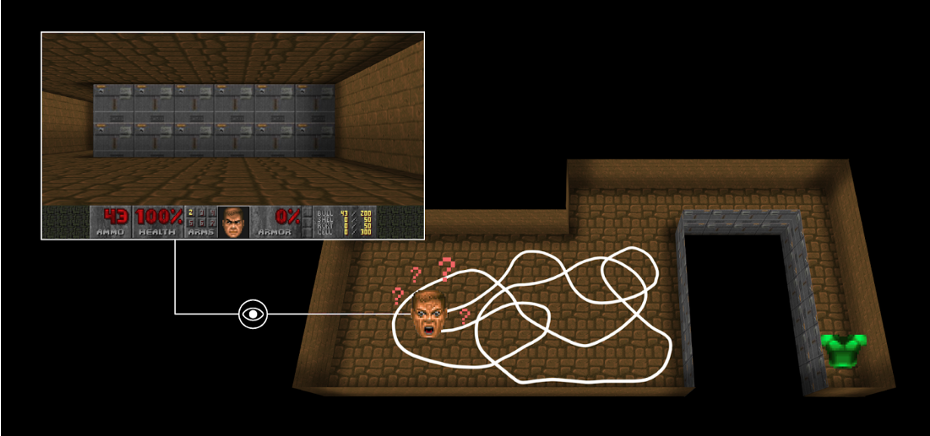
(引用元:https://huggingface.co/learn/deep-rl-course/unit5/curiosity)
ベストを取ったら報酬がもらえるが,それにたどり着くまでに非常に時間がかかる
エージェントはベストを見つけたら報酬が貰えるというものですが,この状況では,なかなかゴールに辿り着くことができません.
そこで,カリキュラム学習(Curriculum learning)の考え方を利用します.簡単なタスクから始めて,徐々に難しいタスクを解かせることで学習を行なっていく方法です.
- 簡単なタスク:報酬+1
- 中間のタスク:報酬+3
- 難しいタスク:報酬+5
まずは,最初の目的として,AIがマップを探索できるようになることを考えてみましょう.新しい場所に到達したら報酬を貰えるという内発的報酬(intrinsic reward),すなわち好奇心(curiosity)を考えます.
下図に示すように,動画内では,これまで訪れた場所の画像と現在との画像の差分を取ることで報酬を設計しています.
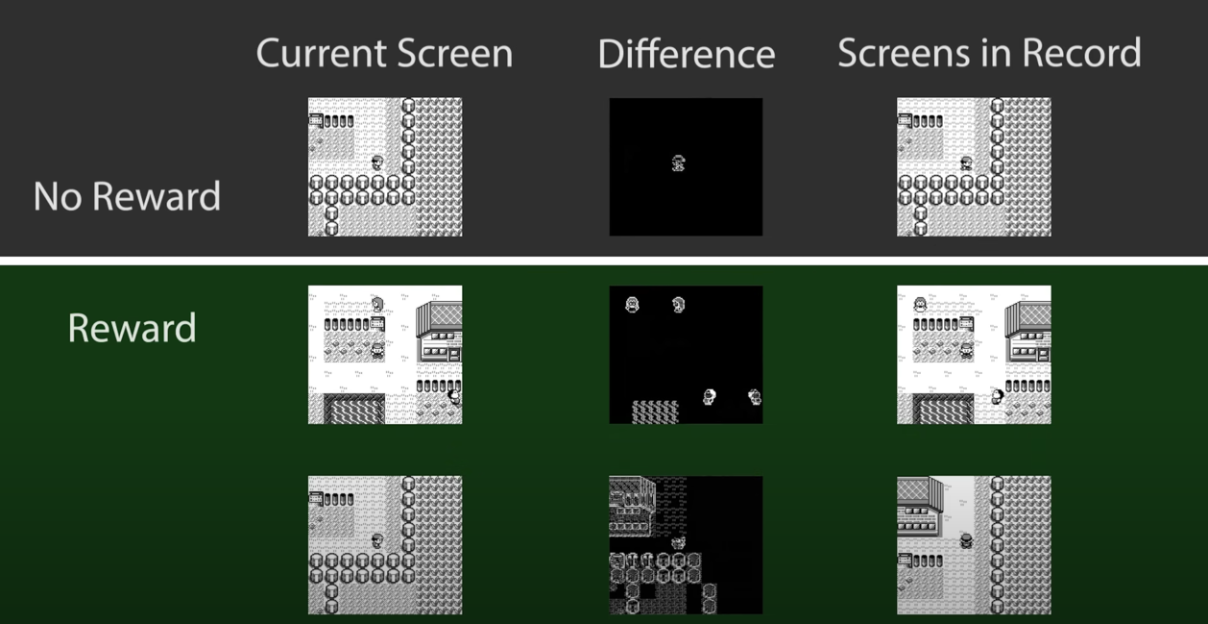
しかし,単純にこれだけでは問題が生じてしまいます.
というのも,波が動いた時やNPCが動いた時でも報酬が得られてしまうからです.そのため,AIは「その場で止まる」という行動を学習してしまいます.これを防ぐために閾値を設定しています.

このように閾値を導入することで,新しい場所に到達するたびに報酬が得られるようになります.
また,動画では述べられていませんが,他のCuriosityの手法としては以下のようなものがあります.
- Random Network Distillation: Reinforcement learning with prediction-based rewards
- Go-Explore: a New Approach for Hard-Exploration Problems
- First return, then explore
今回のアプローチは,探索した状態をアーカイブするというGo-Exploreの一部を利用したようなものになっています.
レベル報酬
先ほどのセクションで説明した報酬を導入することで,マップの探索を行うことができるようになりました.しかし,これだけではバトルを積極的にポケモンを捕まえたり,バトルをしようというAIになりません.
そこで,レベルによる報酬を導入します.
まずは図のように単純に所持しているポケモンのレベルの総和を報酬となるようにしてみましょう.
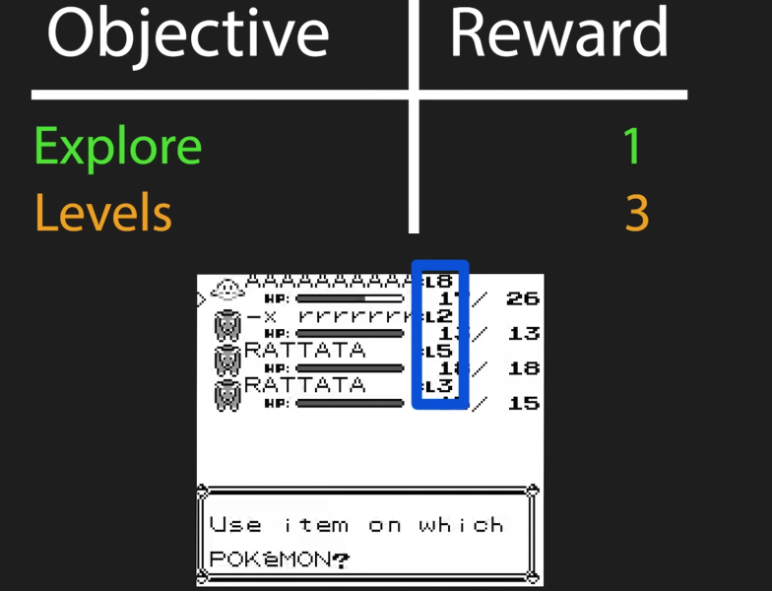
このようにすることで,積極的にポケモンを捕まえて,レベルを上げていく学習を行っていきます.動画内でもあるように,マサラタウン(Pallet Town)・トキワの森(Viridian Forest)からニビシティ(Pewter City)まではこの方針で到達することができます.
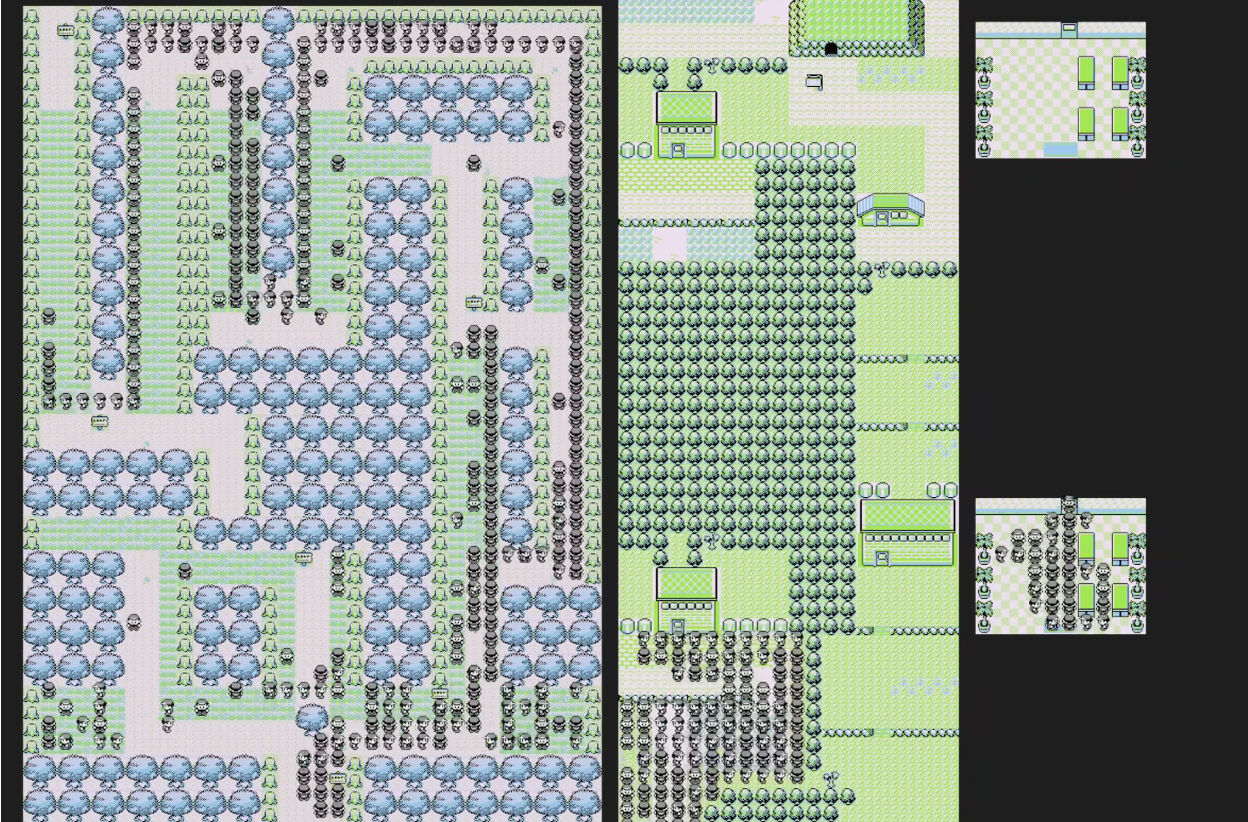
ポケモンセンター
この調子でジムバトルまで行けるようになりますが,1つ問題が生じます.これはポケモンセンターに行かないという問題です.バトルをすると,負ける場合があります.その場合,マサラタウンに戻ってしまい,最初からやり直しになってしまいます.
では,負けたら報酬を-1にするというアイディアを追加してみるとどうなるでしょうか?
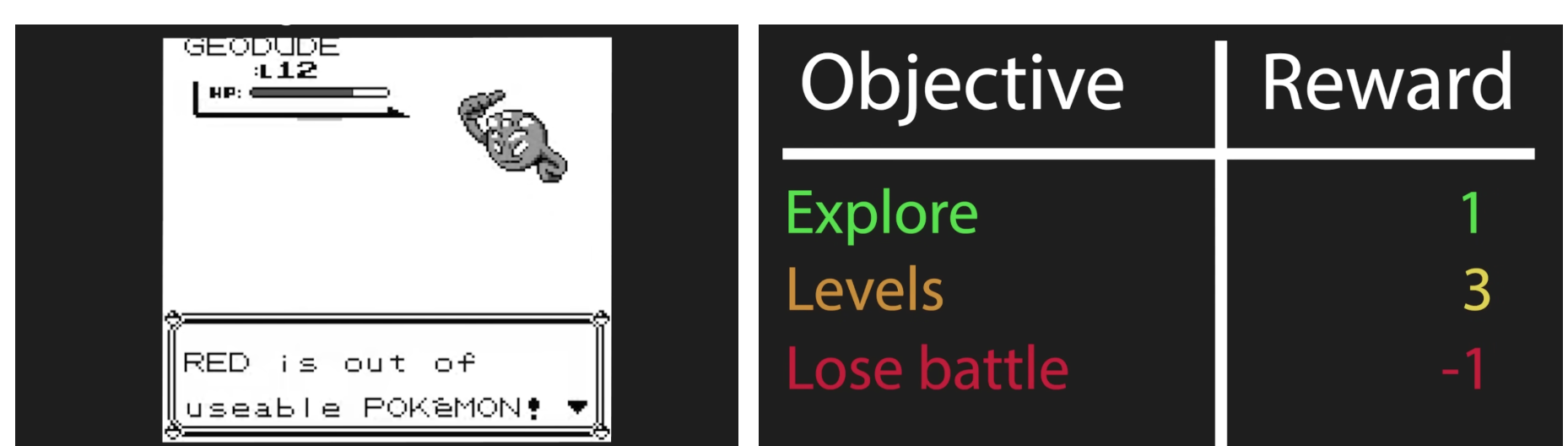
実際に,この報酬をすると,AIはバトルに負けた後,何も選択をしないという行動をとるようになります.こうするのはAIにとって合理的で行動をしなければ報酬がマイナスになることはありません.もっと別の方法を導入する必要があります.
また,学習をしていると一気に報酬が減少するという現象が生じています.それがポケモンを預けるという問題です.

先ほどの設定だと「レベル報酬=現在持っているポケモンのレベル総和」でした.これだと一気に報酬が減ってしまい,ポケモンセンターに行くことがAIにとって避けるべき行動となってしまいました.レベル報酬を変更する必要があります.
$$
\max(\Delta \text{level}, 0)
$$
レベルが上がった際に報酬を与えるように変更することで,この問題を解決できました.
ジムバトル
ジムバトルはAIにとって非常に難しいタスクです.というのも,AIは確率的な行動をとりますが,学習が進むにつれてうまくいった行動をとる傾向にあります.すなわち,これまでのバトルで以下の図でTACKLEを選択し続けることになります.
イシツブテとの戦いの場合では,BUBBLEを利用した方が有効ですが,この技を試すまでは有効かどうかわかりません.以下の図では,たまたまSPが0になっている状況であり,他の技を使うしかありませんでした.このようなランダム性によってAIがBUBBLEが有効であることを学習します.
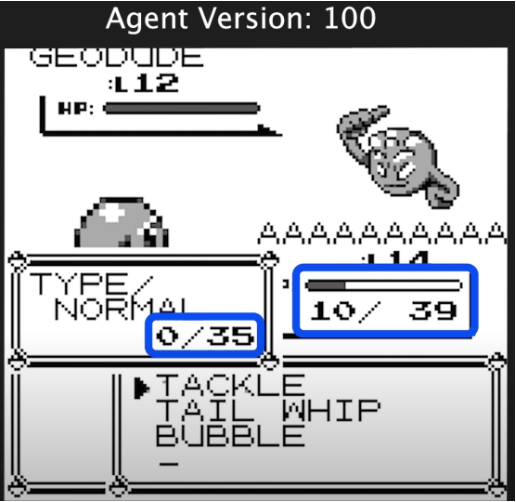
行動パターン
実際に学習をしていると,お月見山(Mt. Moon)で詰まることが多いです.これはこれまでの学習の過程で出口が壁沿いにあったことに依存しています.壁沿いに歩いていくと大きな変化が得られる(次のマップに進む)ことをAIが学習した結果です.
実際に行動パターンを見てみると面白い挙動があります.

各矢印がAIが行動する挙動を表しており,右端にいる場合は上向きに,上にいる場合は左向きにといった具合で反時計回りの行動がなされています.
さらに,学習を行なっていくと,最初の挙動はほとんど同じような動き・行動をとるようになります.下の図は40画面を表したものですが,ほとんど同じ行動をとっています.
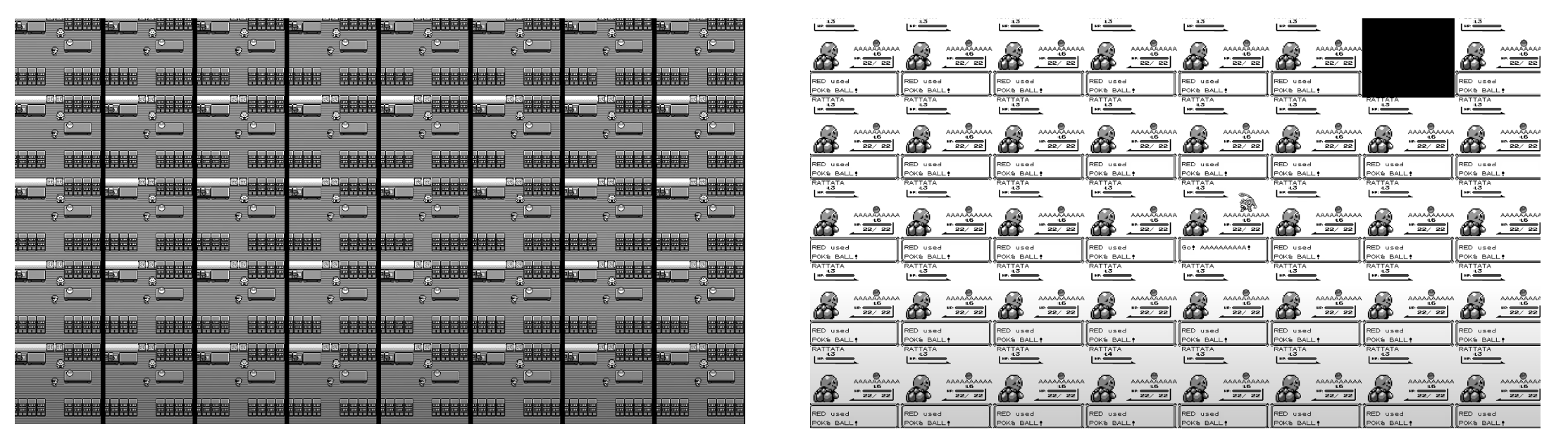
実はゲーム内部で乱数パラメータを持っており,どういう状況でポケモンが出現し,捕まえることができるかを計算することができるようになっています.強化学習の過程でAIはそういった状況を学習しており,最初に行うべき行動を学習していることになります.
これはTAS(tool-assisted superplay or supeedrun)で行われているようなことをAIが学習していることを表しているように思えます.
以上,強化学習でポケモンをどのようにプレイするかとその課題を述べてきました.以下では技術的な詳細を述べていきます.
強化学習アルゴリズム
本セクションでは強化学習アルゴリズムについて簡単に解説します.基本的にマルコフ決定過程(Markov Decision Process, MDP)という条件に従うことを前提としています.これは最初の図のように時刻$t$において,何らかの行動$a_t$を行うと,状態$s_{t+1}$に遷移するような確率モデルを表します.その時,環境から報酬$r_{t+1}$をもらえます.この累積報酬が最大になるようにエージェントが学習されていきます.最適な行動を選択する方法には,価値関数を用いたものや,最適な方策(policy)を求める方法があります.特に方策$π$は以下のような確率モデルで表現されることが多いです.
$$a_t = π_{\theta}(s_t)$$
ここで$\theta$は方策のパラメータを表しており,環境とのインタラクションを通して$\theta$を求めていきます.この$\theta$を求める方法は複数ありますが,よく方策勾配法(policy gradient)に基づく方法を使って推定していくことが多いです.
ポケモンをクリアするために,方策勾配法の一種であるProximal Policy Optimization(PPO)を利用しています.PPOは,2017年にJ. Schulmanらによって提案された方法で,行動空間が連続値である制御でよく使われる方法です.多くのタスクで学習が安定し,比較的良い性能が出ることが示されています.LLMが人間らしい回答をするように学習する際でも利用されています.
通常の方策勾配法では,複雑な環境だと方策勾配の値が大きく変わりすぎて学習が安定しないことが多いです.そのため,PPOでは,古い方策$\pi_{\text{old}}$と新しい方策$\pi$が大きく変わりすぎないようにすることを考え,以下の2つが提案されています.
- Clipped surrogate objective:
方策の比率$r_t(\theta) = \frac{\pi_\theta}{\pi_{\theta_\text{old}}}$とアドバンテージ関数の推定値$\hat{A}_t$の積をクリッピングする方法 - Adaptive KL penalty coefficient:
$\pi_{\theta_\text{old}}, \pi_{\theta}$のKLダイバージェンスを制限する方法
アドバンテージ関数は,どれくらい行動が平均的なものと比べて良かったかを表すスコアを表しています.
- Clipped surrogate objective
$$
L^{CLIP}(\theta)=\min(r_t(\theta)\hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_t)
$$
- Adaptive KL penalty coefficient
$$
L^{KLPEN}(\theta) = r_t(\theta)\hat{A}_t - \beta \text{KL}[\pi_{\theta_{\text{old}}}, \pi_{\theta}]
$$
Adaptive KLでは,現在のKLの期待値とKLターゲット値の大小に応じて$\beta$を動的に変更していきます.
- Objective
最終的な目的関数では,状態価値関数(Value function, VF)の近似および探索を行うためのエントロピー項を導入しています.以下の式はCLIPの場合です.
$$
L^{CLIP+VF+S}=\mathbb{\hat{E}}_t \left[L_t^{CLIP}(\theta) - c_1 L_t^{VF}(\theta)+c_2 S[\pi_{\theta}]\right]
$$
ここで,$L_t^{VF}$は状態価値関数の二乗平方誤差(MSE),$S$はエントロピー項を表します.PPOの性能を高めるために,以下のハイパーパラメータを調整することも必要になってきます.
- クリッピングパラメータ$\epsilon$
- KL係数$\beta$, KLターゲット値
- 価値関数の係数$c_1$
- エントロピー項の係数$c_2$
論文ではクリッピングを調整した方が性能が高くなっています.
改善の余地
Transfer Learning
転移学習(transfer learning)は,大量のデータセットで学習されたモデルを別のタスクで転用するための学習方法です.画像の領域ではよく利用されていると思いますが,データセットが少ないような場面で有効になることが多いです.
ポケモンの例では,OpenAIの開発したCLIP(Learning Transferable Visual Models From Natural Language Supervision)を利用しようとしています.
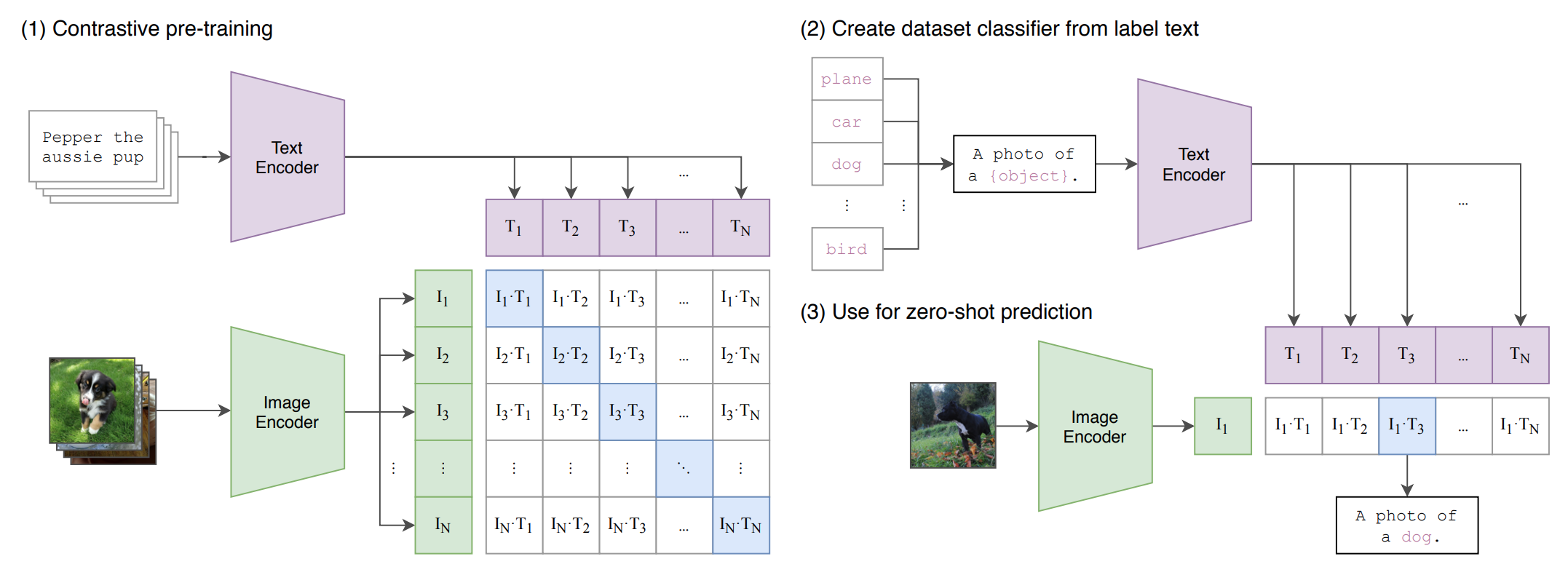
- Contrastive pre-training:画像とそれに関連するテキストの埋め込まれたベクトルの類似度が最大になるように学習をさせる
- Dataset classifier from label text: ラベルを識別するためのデータセットを用意する
- Zero-shot prediction:画像を入力すると,それに対応するテキストがゼロショットで推論できる
実際に試験的に学習された結果は下図のようになります.これらの情報を利用することで,内部報酬に利用できるかもしれません.
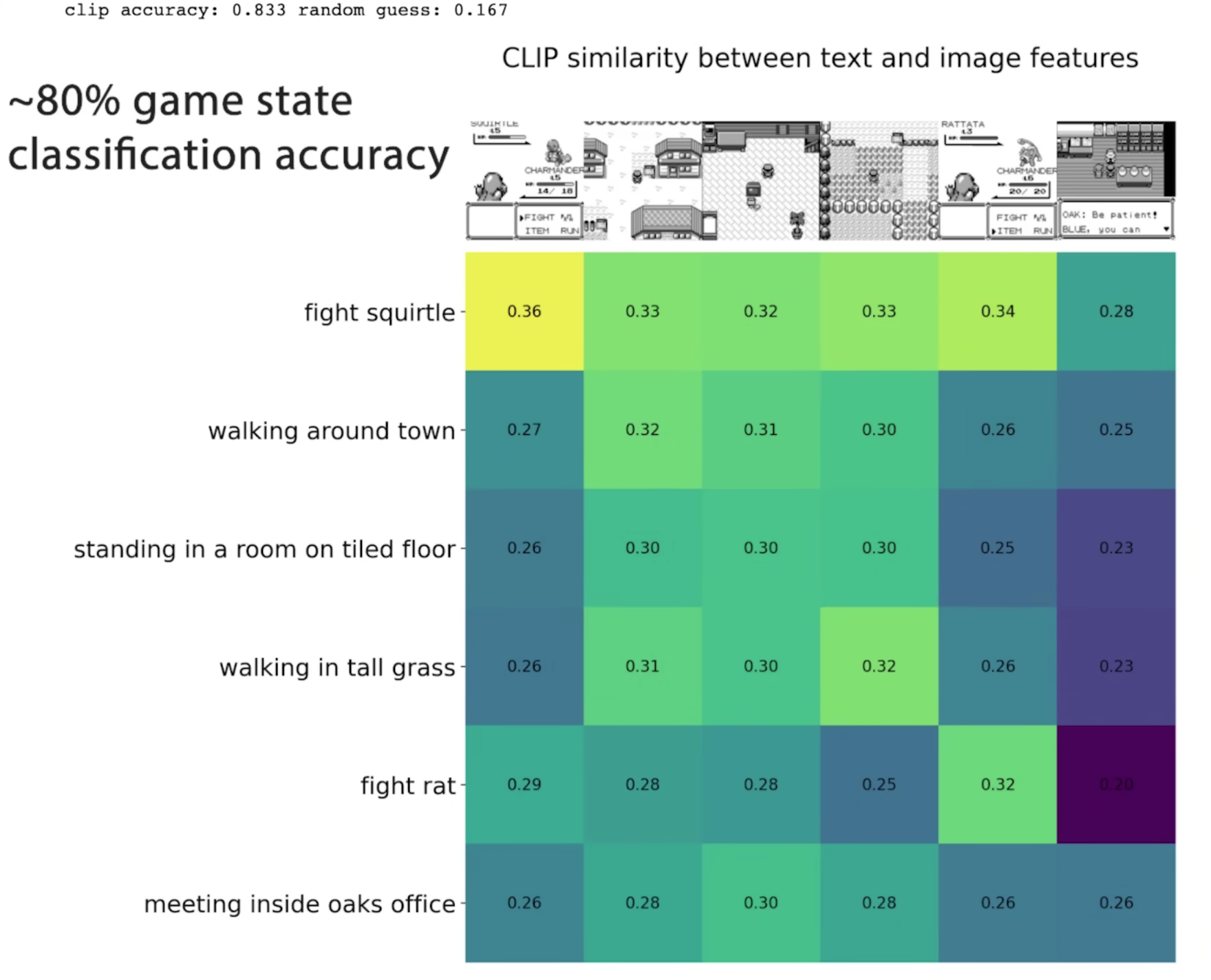
この図でfight squirtle, fight ratなどがありますが,すべてのポケモンを考慮した場合にも性能が出るのかは興味がありますね.
Environment modeling
PPO以外のアルゴリズムを利用する方法もあります.特に,環境をモデリングすることで性能を高めている方法があります.
- MuZero: 囲碁・チェス・将棋・Atariのゲームでルールを教えずにプロレベルの性能を出しているモデル
- DreamerV3: 環境をVAEなどを用いて中間的な表現で表した世界モデル(world model)を利用する強化学習手法
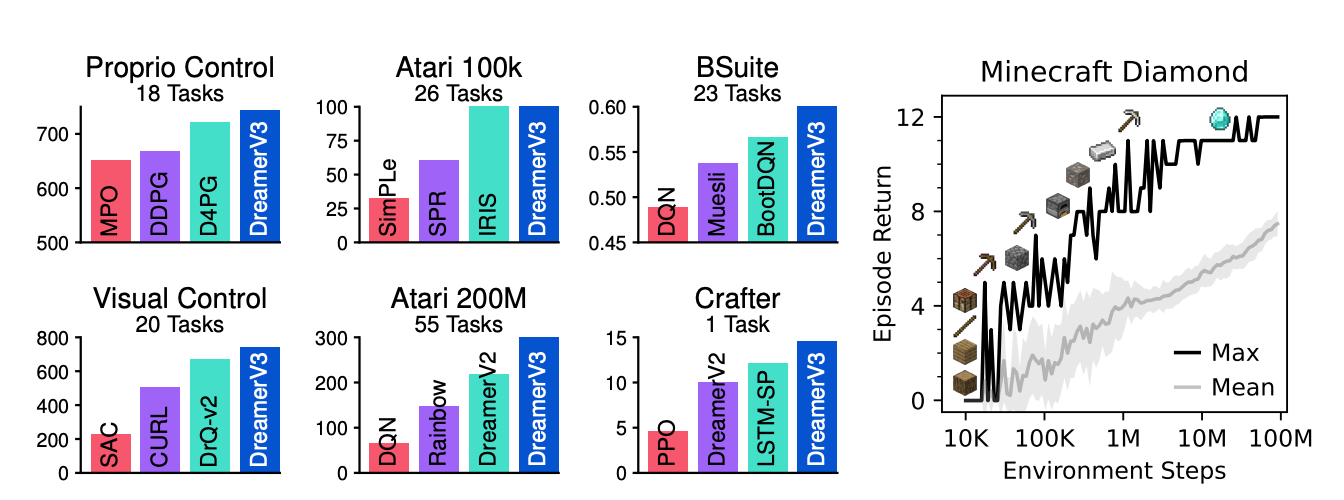
(引用元:D. Hafner et al., Mastering Diverse Domains through World Models)
同一のハイパーパラメータで複数のタスクを学習させた結果,DreamerV3は,多くの最先端の強化学習アルゴリズムよりも性能が高いことが確認されています.
Hierarchical Reinforcement Learning
階層的強化学習(Hierarchical Reinforcement Learning)は,複雑なタスクを小さいタスクに分割して学習させる方法です.例えば,WorkerとManagerという二つのモジュールからなるFeUdal Networks(FuN)が代表的なものです.同じ場面を何度も経験して過学習してしまうことを防ぐために,各場面に応じて学習させるアプローチが有効かもしれません(例えば,バトル画面だけ別に学習させて,後ほど統合するなど).
その他
動画内では述べられていませんが,LLMなどのアプローチも試してみたいですね.例えば,以下のような手法があります.
- AutoGPT: GPTを自動化するためのツール
- SPRING: 画像の記述子+質問の依存関係を考慮したコンテクストをプロンプトに与えることでDreamerV3を超える性能を達している
- Voyager: GPT-4とAutomatic CurriculumやIterative promptingを利用してMineCraftをプレイする.AutoGPTよりも性能が高い.
Pythonでポケモンをプレイする
ポケモンをPC上でプレイするには,「正式なROM」を用意する必要があります.Atariのようなゲームでは,研究用途としてArcade Learning Environment, ALEというROMが公開されています.また,実際にAIがポケモンをまともにプレイできるくらいになるためには,大量の計算リソースを用いて学習させる必要があります.
プレイするためのソースコードはGithub上に公開されています.
実際に試す
MacOSでは,python3.10の環境でREADME.mdに書いてあるとおりに実行すれば特に問題なく動きました.
git clone https://github.com/PWhiddy/PokemonRedExperiments.git
cd cd baselines
pip install -r requirements.txt
python run_pretrained_interactive.py

学習
強化学習のためのEnvや学習用のスクリプトも用意されているため,実際に学習も行うことができます.使用できる強化学習ライブラリは複数ありますが,私が利用したことがあるものは以下の2つです.
私は特に大規模並列計算が容易なRayをよく利用しています.強化学習ではCPUやGPUなどのリソースを大量に用意すると効率よくデータを収集できるため並列化が必要になってきます.これを簡単に行えるフレームワークがRayです.
例えば,GPUが4個で48並列でPPOを動かす場合は以下のコードになります.
import ray
from ray.rllib.algorithms import ppo
from red_gym_env_ray import RedGymEnv
env_config = {
"headless": True,
"save_final_state": True,
"early_stop": False,
"action_freq": 24,
"init_state": "../../has_pokedex_nballs.state",
"max_steps": 2048,
"print_rewards": False,
"save_video": False,
"fast_video": True,
"session_path": Path(f"session_{str(uuid.uuid4())[:8]}"),
"gb_path": "../../PokemonRed.gb",
"debug": False,
"sim_frame_dist": 500_000.0,
}
config = (
ppo.PPOConfig()
.environment(RedGymEnv, env_config=env_config)
.framework("torch")
.resources(num_gpus=4)
.rollouts(num_rollout_workers=48)
.training(
model={
"grayscale": True,
"framestack": True,
},
gamma=0.98,
entropy_coeff=0.1
train_batch_size=512
)
)
algo = config.build()
for _ in range(10):
results = algo.train()
print(results)
algo.save(f"outputs/models/pokemon")
今回のコードではevaluationは省略されています.強化学習やPPOのハイパーパラメータはタスクに応じて調整する必要はあります.AWSのEC2インスタンスを複数建て,並列学習といったことも簡単にできますし,弊社で利用しているDatabricksとの相性もよく大規模分散処理で学習させる時には非常に役立ちます.
最後に
ここまでポケモンの話題を書いてきましたが,実際に強化学習でゲームをプレイする際は,MineCraftも簡単に試すことができます.研究の題材として使われているため,エキスパートのデータセットも豊富です.ポケモンで使われているような報酬の工夫はゲームをプレイする上で非常に重要でした.このような考え方を応用してあげると強化学習を利用する際に役立つかもしれませんね.また,動画内で説明されていることを全ては説明できていません.詳細が気になる方はぜひ動画をご覧になることをお勧めします.
Japan Digital Design株式会社では,一緒に働いてくださる仲間を募集中です.カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください!
参考文献
各手法のリファレンスを以下に記載します.
-
Reinforcement Learning An Introduction 2nd Edition, R.S. Sutton and A.G. Barto
-
AlphaStar: Mastering the real-time strategy game StarCraft II
-
MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge
-
Voyager: An Open-Ended Embodied Agent with Large Language Models
-
SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning
注意)こちらの記事に関する内容は個人の見解であり,所属する組織の公式見解ではありません.