はじめに
4年ほど前からエクセルのVBAで自分用の
業務アプリを制作し始めたエクセル業務効率
家?です。
python でAIを組みこんだ1ランク上の便
利アプリを作りたいと思い講座の受講を決め
ました。
本記事の概要
手書き数字認識の精度に不満があるので改良します
初めて MNIST の手書き数字データセット
を利用して学習済みモデルを作成しました。
さっそく手書き数字のファイル作ってモデ
ルに認識させてみたら、思ったよりも認識
精度が悪いです。
手書き数字を何でもサクサク認識してくれる
と思い込んでいた私としては満足いくレベル
ではありませんでした。
それで、認識精度アップを目指し工夫を行い
最終的にはペイントソフトで書いた数字の複
数認識を目指します。
この記事の対象の方としては、
MNIST の データセットを用いて 数字認識モ
デルを構築してみたけど、思ったような認識
精度が得られなかったという方です。
すこし長くなるとは思いますが、興味のある
方は是非ご覧ください。
改善方法とモデル作成の流れ
1.白黒反転データセット作成と学習
2.文字を太くする関数を作る
3.ノイズ有りデータセット学習
4.複数の数字認識に対応する
5.自作データセット作成と学習
1.白黒反転データセット作成と学習
数字を書く場合、白い紙に黒のペンで書くの
が一般的だと思います。
図のようにペイントアプリを使い28*28
pix の白い背景に 黒で数字を書いた画像を
作成します。
学習済みモデルに認識させると
”8です” と答えが返ってきて正しく認識し
ません。
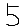
図: 28*28pix 黒文字で書いた5
これが認識できなかったら何が認識できるの
?ということで早速対策します。
原因は MNIST データセット の背景が黒
で 数字が白 ということにあるようです。
下の図は MNIST オリジナルデータの5
の画像です。確かに黒の背景に白文字で描か
れています。

図:MNISTデータセットの5
データセットを白黒反転して学習させれば認
識するようになるかも?ということで、まず
は白黒反転データセット作成と学習を行いま
す。
モデルはそのままに数字画像データを反転さ
せても認識できるような気がしますが今回は
より汎化性能の高いモデルを目指します。
白黒反転データ作りに取り掛かります。
使うのは cv2.bitwise_not 関数です
この関数は画像を白黒反転してくれます
使い方は以下のとおりです。
#cv2をインポート
import cv2
#imgを白黒反転
img=cv2.bitwise_not(img)
これで白黒反転した画像が作成できます。オ
リジナル画像を反転すると図のようになりま
す。

図:MNIST データを白黒反転した5
これで白黒反転画像ができました。
これを MNIST データ全てに行い白黒反転デ
ータセットを作ります。
MNIST データセットをダウンロードします
MNIST データセットは教師データとして6
万枚の手書き数字画像と正解ラベルデータ
テストデータとして1万枚の手書き数字画
像と正解ラベルとなっています。
#mnistの教師データとテストデータをダウンロードします。
(X_train,y_train),(X_test,y_test) = mnist.load_data()
ダウンロードした手書き数字画像データを白
黒反転します。
#cv2をインポート
import cv2
#教師データ60000枚を白黒反転
X_train_bit_n = cv2.bitwise_not(X_train)
#テストデータ10000枚を白黒反転
X_test_bit_n = cv2.bitwise_not(X_test)
白黒反転データセットができましたので、オ
リジナルのデータセットに追加します。
12万枚の教師データと2万枚のテストデー
タを作ります。
#オリジナルの教師データ60000枚に白黒反転教師データ60000枚を追加します。
X_train = np.append(X_train, X_train_bit_n, axis=0)
#オリジナルのテストデータ10000枚に白黒反転テストデータ10000枚を追加します。
X_test = np.append(X_test, X_test_bit_n, axis=0)
#教師データ正解ラベルはそのまま追加します
y_train = np.append(y_train, y_train, axis=0)
#テストデータ正解ラベルはそのまま追加します
y_test = np.append(y_test, y_test, axis=0)
#教師データ正解ラベルをワンホット値に変換します
y_train = to_categorical(y_train)
#テストデータ正解ラベルをワンホット値に変換します
y_test = to_categorical(y_test)
ワンホット値とは
例えば正解ラベルが2だった場合のワンホット値は
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0]
正解ラベルが6だった場合のワンホット値は
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0]
となります。
これで MNIST データセットと白黒反転デー
タセットを組み合わせたデータセットができ
ました。モデルに学習させます。
100エポック学習済みモデルを使って先程
の背景が白の5を認識させると、
先程までは ”8です” と答えていたモデルが
無事に ”5です” という答えが返ってきまし
た。成功です。
次は少し大きめの500×500pixのキャ
ンバスに数字を書きます。
図:ペイントソフトで書いた5
画像をモデルに認識させると ”2です” と
返ってきて正しく認識しません。
対策を考えます。
まずモデルにどのような画像が送られている
のか確認します。
下図の左がグレースケール化した後に2値化
したもので、右がその画像を(28、28)
にリサイズ、一番下がリサイズした画像を更
に2値化しています。
 |
 |
| 図:グレースケール化&2値化 | 図:処理後にリサイズ |

|
|
| 図:リサイズ後に2値化 |
画像を確認します。
描いた線が細いとリサイズした時に線がぼや
けます。更に2値化すると完全に数字が消え
てしまいます。
何も映ってなければ数字を判断することはで
きません。
2.文字を太くする関数を作る
次は線を太くする処理を行います。
線を太くするには膨張処理を行います。膨張
は cv2.dilate を使います。
#ナンパイをインポート
import numpy as np
#cv2をインポート
import cv2
# 8近傍フィルタ
filt = np.array([[1,1,1],
[1,0,1],
[1,1,1]], np.uint8)
#膨張
d_img = cv2.dilate(img, filt)
以下が実際のコードで、自作関数の中で膨張
を2回行っています。
# 膨張
def dilate_img(img, screen): # img, screen(背景が白か黒かそれ以外かw, b, c)
# screenはノイズのない背景が白のデータの場合"w",黒の場合"b"を返す
# 画面が暗い場合は"c"を返す
# 8近傍フィルタ
filt = np.array([[1,1,1],
[1,0,1],
[1,1,1]], np.uint8)
if screen == "w": # 背景が白ならば反転して2回膨張処理を行う
img = cv2.bitwise_not(img)
img = cv2.dilate(img, filt)
img = cv2.dilate(img, filt)
screen = 'b'
elif screen == 'b':
img = cv2.dilate(img, filt)
img = cv2.dilate(img, filt)
else: # 反転無しで2回膨張処理を行う
img = cv2.dilate(img, filt)
img = cv2.dilate(img, filt)
screen = 'b'
return img, screen
膨張は背景が白い画像で行うと線が細くなっ
てしまうので、背景が白い場合は白黒反転を
行ってから膨張を行います。
膨張を行う関数を3回繰り返し行ったのが図
2です。図3が膨張処理後にリサイズで、図
4がリサイズ後更に2値化しています。
|
 |
| 図1:元画像 | 図2:膨張の自作関数を3回 |
 |
 |
| 図3:関数処理後にリサイズ | 図4:リサイズ後に2値化 |
綺麗な画像が得られましたのでモデルに認識
させます。答えは ”4です”
不正解です。
今度は認識精度を高めるためにモデルをさら
に学習させます。
3.ノイズ有りデータセット学習
学習させるのは、 MNIST データセットに
ノイズを加えた mnist-corrupted のデータ
セットです。
mnist-corrupted は MNIST のテストデータ
を破損させたデータセットとなっています。
以下がその説明です。
MNISTCorrupted は、MNIST データセットのテスト画像に 15 個の破損を追加して生成されたデータセットです。このデータセットは、元の作成者によってアップロードされた静的で破損した MNIST テスト イメージをラップします。
という事のようなので、mnist-corrupted を
ダウンロードして、更にこのデータセットを反転さ
せたものも加えてモデルに再度学習させます。
以下の図のように学習が終了しました。
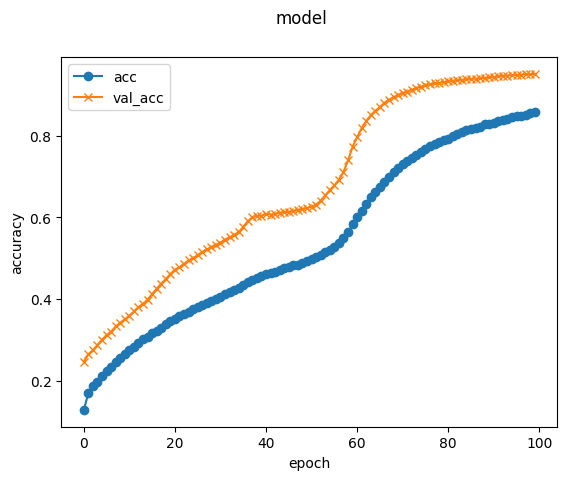
図15: mnist-corrupted データセットで 学習
先程のペイントで書いた5を認識させます。
答えは ”5です”
正解です。
ペイントソフトで書いた数字は何とか認識で
きました。次は複数の手書き数字も認識でき
るようにします。
4.複数の数字認識に対応する
考えた複数認識の手順は、まず数字の輪郭抽
出を行い、抽出した輪郭の座標をもとに画像
を切り出しファイルに保存というものです。
ファイルに保存された各数字を1つずつモデ
ルに認識させて最後にまとめて出力します。
それでは作成します。
まず輪郭を抽出して数字ごとに切り出してフ
ァイルに保存する関数を作成します。
輪郭を抽出するには cv2.findcontours を使
用します。この関数は使用する前に画像をグ
レースケール化と2値化を行っておく必要が
あります。
輪郭の座標を取得するには、
cv2.boundingRect を使用します。この関数
は輪郭の外接矩形を計算します。
以下がコードです。
#cv2をインポート
import cv2
def f_contours(img):
#グレースケール
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#2値化
retval, th_img = cv2.threshold(gray, 130, 255, THRESH_BINARY)
#輪郭を抽出する
contours, hierarchy
= cv2.findContours(th_img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
#輪郭を描画する
c_img
= cv2.drawContours(img, contours, -1, color=(0,255,0), thickness=2)
#輪郭のx, y, w, hを格納するリストを作成
n = []
#輪郭の位置を格納する
for i in contours:
x, y, w, h = cv2.boundingRect(i)
#外接矩形を描画した画像
img = cv2.rectangle(c_img, (x, y), (x+w, y+h), (0,255,0), 4)
#x、y、w、hを格納
n.append([x,y,w,h])
#x座標が一番左の外接矩形から並び替える
num_location=sorted(n)
#外接矩形を描画した画像と座標を返す
return img,num_location
cv.findContours() 関数には 3 つの引数があり、1 つ目はソース画像、2 つ目は輪郭検索モード、3 つ目は輪郭近似メソッドです。そして、変更された画像、輪郭、階層を出力します。等高線は、画像内のすべての輪郭の Python リストです。個々の等高線は、オブジェクトの境界点の(x、y)座標のNumpy配列です。
findContours の戻り値と引数は以下
の通りです
image(変更された画像), contours(輪郭), hierarchy(輪郭の階層)
= cv.findContours(ソース画像, 輪郭検索モード, 輪郭近似メソッド )
輪郭検索モードは5種類あります。
| RETR_EXTERNAL | 極端な外側の輪郭のみを取得します。すべての輪郭に設定されます。 |
|---|---|
| RETR_LIST | 階層関係を確立せずにすべての輪郭を取得します。 |
| RETR_CCOMP | すべての輪郭を取得し、2 レベルの階層に整理します。最上位レベルには、コンポーネントの外部境界があります。2番目のレベルでは、穴の境界があります。接続された構成部品の穴の内側に別の輪郭がある場合、その輪郭はトップレベルに配置されます。 |
| RETR_TREE | すべての輪郭を取得し、ネストされた輪郭の完全な階層を再構築します。 |
| RETR_FLOODFILL |
試した結果 RETR_EXTERNAL が良い結果
を得られたのでこれを使います。
輪郭近似メソッドは4種類あります。
| CHAIN_APPROX_NONE | 絶対にすべての等高線点を格納します。つまり、等高線の任意の 2 つの後続の点 (x1,y1) と (x2,y2) は、水平、垂直、または対角線の隣接、つまり max(abs(x1-x2),abs(y2-y1))==1 になります。 |
|---|---|
| CHAIN_APPROX_SIMPLE | 水平、垂直、および対角線のセグメントを圧縮し、その端点のみを残します。たとえば、直立した四角形の等高線は 4 つの点でエンコードされます。 |
| CHAIN_APPROX_TC89_L1 | Teh-Chin連鎖近似アルゴリズムのフレーバーの181つを適用します |
| CHAIN_APPROX_TC89_KCOS | Teh-Chin連鎖近似アルゴリズムのフレーバーの1つを適用します |
こちらも試した結果 CHAIN_APPROX_SIMPLE が良
い結果を得られたのでこれを使います。
この関数を使ってペイントソフトで書いた数
字の輪郭を抽出して外接矩形を描画したもの
が下の画像です。
 |

|
| 図:ペイントで書いた123 | 図:線を太くする処理後 輪郭を描画 |

|
|
| 図:数字をボックスで囲む |
各数字を囲むことができました。
今度はそれぞれの数字を切り出してファイル
に保存する関数を作成します。
以下がコードです。
#cv2をインポート
import cv2
#num_locationには輪郭位置がX座標が小さいものから順番に格納されている
#数字を切り出してファイルに保存する関数
def create_num_file(img, num_location, screen):
# 切り出し他画像の一時保存ディレクトリ名
dir_path = './' + NUM_FOLDER + '/'
# 切り出す余白の設定
if img.shape[0] <= 28:
m1, m2, m3, m4 = 0, 0, 0, 0
elif img.shape[0] <= 50:
m1, m2, m3, m4 = 1, 1, 1, 1
else:
m1, m2, m3, m4 = 10, 10, 10, 10
# (28,28)以下はそのままファイルに保存する
if img.shape[0] <= 28 or img.shape[1] <= 28:
cv2.imwrite(os.path.join(NUM_FOLDER, "num0" + ".png"), img)
else:
# 数字の数だけ画像を切り出してファイルを作る
for i in range(0, len(num_location)):
x, y, w, h = num_location[i]
# 画像を正方形に切り取る
n1, n2 = abs((h - w) // 2), abs((h - w) // 2)
# エラーにならない為の処理
if y - m1 < 0: # 切り取る幅が画像の上をオーバー
m1 = 0 # 上の余白を0
if y + h + m2 > img.shape[0]: # 切り取る幅が画像の下をオーバー
m2 = 0 # 下の余白を0
if x - n1 - m3 < 0: # 切り取る幅が画像の左端をオーバー
m3 = 0 # 左の余白を0
n1 = 0 # 正方形にする左の変数を0
if x + w + n2 + m4 > img.shape[1]: # 切り取る幅が画像の右端をオーバー
m4 = 0 # 右の余白を0
n2 = 0 # 正方形にする右の変数を0
# 画像を余白を付けて切り出す
trim_img = img[y - m1:y + h + m2, x - n1 - m3:x + w + n2 + m4]
# 切り出された画像の大きさに応じて線を太くする
if h > img.shape[0] * 0.9 and w > img.shape[1] * 0.9:
# 大きい画像は2度関数を使用
trim_img, screen = dilate_img(trim_img, screen)
trim_img, screen = dilate_img(trim_img, screen)
# 切り出した画像をそれぞれファイルに保存する
cv2.imwrite(os.path.join(NUM_FOLDER, 'num' + str(i) + '.png'), trim_img)
elif h > img.shape[0] * 0.5 and w > img.shape[1] * 0.5:
# 切り出した画面サイズが元画像の半分程度の場合は1度関数を使用
trim_img, screen = dilate_img(trim_img, screen)
# 切り出した画像をそれぞれファイルに保存する
cv2.imwrite(os.path.join(NUM_FOLDER, 'num' + str(i) + '.png'), trim_img)
else:
# 切り出した画像をそれぞれファイルに保存する
cv2.imwrite(os.path.join(NUM_FOLDER, 'num' + str(i) + '.png'), trim_img)
return dir_path
この関数を使い数字を切り出した画像が下の
図です。

|

|

|
| 図:切り出した1 | 図:切り出した2 | 図:切り出した3 |
この画像の輪郭を除いたものをそれぞれモデ
ルに認識させます。
結果はそれぞれ ”1です””2です””3です”
全て正解です。
数字を変えたり認識文字数を増やすなど条件
を変えて試すと6、7、8、9、の認識精度
が悪いのがわかりました。
そこで、自作の手書き数字データセットを作
り学習させて認識精度を一気に高めたいと思
います。
5.自作データセット作成と学習
まずペイントソフトで適当に0から9までの
数字を書いてそれぞれのフォルダにファイル
を保存します。
図:作成したフォルダ
各数字ごとに100個ぐらいファイルが作成
出来たらそのファイルを基に新たなデータセ
ットを作ります。
線を太くしたり、ランダムに上下左右移動や
右左回転させた画像を作成して
(28、28)にリサイズして保存します。
この方法で0~9までの画像ファイルを20
180個作って、それに対応した正解ラベル
のリストも作成しました。
以下がそのコードです。
まずペイントソフトの手書き画像ファイルか
らランダムな画像を作成するコードです。
#ライブラリをインポート
import cv2
import numpy as np
import math
import random
# 手書き数字ファイルをもとにランダムな(28,28)データを作成
# ペイントソフトで書いた手書き数字ファイルのディレクトリ名
NUM_FOLDER, NUM_FOLDER1 = 'num_data_0', 'num_data_1'
NUM_FOLDER2, NUM_FOLDER3 = 'num_data_2', 'num_data_3'
NUM_FOLDER4, NUM_FOLDER5 = 'num_data_4', 'num_data_5'
NUM_FOLDER6, NUM_FOLDER7 = 'num_data_6', 'num_data_7'
NUM_FOLDER8, NUM_FOLDER9 = 'num_data_8', 'num_data_9'
# 元画像と同じ階層にnum_datasetというフォルダを作成してください
NEW_FOLDER = num_dataset
# (28,28)データファイル名
NEW_FILENAME = num_file_
# 手書き数字フォルダごとにデータを作成していきます
# 作成したデータの中から使えないデータを省くのは手動です
for i in range(1):
a = NUM_FOLDER # 作成したい数字フォルダを指定する
data_list = os.listdir('../' + a)
n = len(data_list) + 1 # 同ファイル名上書き防止の通しナンバー
for j in data_list:
# 元ファイルを読み込む
im = cv2.imread('../' + NUM_FOLDER[:-2] +'/' + str(a[-1]) + '/' + str(j))
# 画像をnp配列に変換
im = np.array(im)
# 画像を太くする前に白黒反転して背景を黒にする
im = np.bitwise_not(im)
# 8近傍フィルタ
filt = np.array([[1,1,1],
[1,0,1],
[1,1,1]],np.uint8)
# 1~10までのランダムな値を作成
rn = random.randint(0,10)
# rnの値に応じて線を太くする回数を変える
# 線が細すぎると(28,28)にしたときに何も残らない
# ペイントソフトで描く時に太目で書いておくと良いかもしれません
if (rn >= 1 and rn <=3):
for i in range(0,12): # 12回繰り返す
im = cv2.dilate(im, filt)
elif(rn >= 4 and rn <=6):
for i in range(0,16): # 16回繰り返す
im = cv2.dilate(im, filt)
elif(rn >= 6 and rn <=8):
for i in range(0,18): # 18回繰り返す
im = cv2.dilate(im, filt)
elif rn >=9:
for i in range(0,22): # 22回繰り返す
im = cv2.dilate(im, filt)
im = cv2.dilate(im, filt)
# ランダムな数値の振れ幅を小さくすれば画像がフレームアウトする確率を減らせます
# 画像を回転させる
h, w = im.shape[:2]
affine = cv2.getRotationMatrix2D((0,0), random.randint(140,180), 1.0)
affine = cv2.getRotationMatrix2D((0,0), random.randint(0,40), 1.0)
im = cv2.warpAffine(im, affine, (w, h))
# 画像を縦横に移動させる
im = np.roll(im, random.randint(-10,10))
im = np.roll(im, random.randint(-10,10), axis=1)
# (28,28)にリサイズする
im = cv2.resize(im, (28, 28))
# 新しいファイルに保存する
cv2.imwrite('../' + NEW_FOLDER + '/' + NEW_FILENAME + str(a[-1]) + '/' + str(a[-1]) + '_' + str(n) + '.png', gray)
# ファイルに通しナンバーをふる
n = n + 1
次は作成した(28、28)画像と、それに
対応した正解を格納した配列を作り。それぞ
れをNumPy配列としてテキストファイルで
保存します。保存は np.save を使用します。
使い方は以下の通りです。
np.save(ファイル名, 保存したいNumPy配列)
これで npy ファイルが作成できます。
以下が実際のコードです。
# ラベルファイルとデータファイルを作成
# (28,28)サイズの画像ファイルとフォルダを入れるフォルダ名
NEW_FOLDER = num_dataset
# (28,28)の画像ファイルが入っている各フォルダ名
datasetfolder_list = ['num_file_0', 'num_file_1' ,'num_file_2',
'num_file_3', 'num_file_4', 'num_file_5',
'num_file_6', 'num_file_7', 'num_file_8',
'num_file_9']
n = [] # 正解ラベルを格納
X_train_data =[] # 画像ファイルを格納
for i in datasetfolder_list:
file_list = os.listdir('../' + NEW_FOLDER + '/' + str(i))
for j in file_list:
#各ファイルを読み込む
img = cv2.imread('../' + NEW_FOLDER + '/' + i + '/' + j)
print('j: ' + str(j))
# 画像をNumPy配列に変換する
img = np.array(img)
# 画像ファイルを格納する
X_train_data.append(img)
# 各ファイル名から正解ラベルを作り格納
n.append(str(i[-1]))
# 画像のNumpy配列をnp形式で保存する
np.save('../' + NEW_FOLDER + '/dataset_X_train', X_train_data)
# 正解ラベルをnp形式で保存する
np.save('../' + NEW_FOLDER + '/dataset_label',n)
npy ファイルが作成できました。作成し
た2つのファイルとこれまでに学習させて
きたモデルをグーグルコラボラトリにイン
ポートして、更に反転データも作って学習
させます。
グーグルコラボラトリへのインポートはド
ラッグ&ドロップでOKです。
作成した npy ファイルを読み込むには
np.load を使用します。使い方は以下の通
りです。
np.load(ファイル名)
以下が実際のコードです。
#np形式画像データを読み込む
my_data = np.load("/content/dataset_X_train.npy")
#np形式正解ラベルデータを読み込む
my_label = np.load("/content/dataset_label.npy")
a = [] # 画像を格納する
for i in my_data:
j = cv2.cvtColor(i, cv2.COLOR_BGR2GRAY)
# 画像をグレースケールで読み込み格納
a.append(j)
# 画像データをNumPy配列に変換
X = np.array(a)
# 正解ラベルデータをNumPy配列に変換
y = np.array(my_label)
# 画像データのランダムなインデックスを作成
rand_index = np.random.permutation(np.arange(len(X)))
# 画像データをランダムなインデックスで並び変える
X = X[rand_index]
# 正解ラベルをランダムなインデックスで並び替える
y = y[rand_index]
# データを教師データとテストデータに分割する
X_train_mc = X[:int(len(X) * 0.8)]
y_train_mc = y[:int(len(y) * 0.8)]
X_test_mc = X[int(len(X) * 0.8):]
y_test_mc = y[int(len(y) * 0.8):]
# 教師データ画像の白黒反転データを作成
X_train_b_n = cv2.bitwise_not(X_train_mc)
#テストデータ画像の白黒反転データを作成
X_test_b_n = cv2.bitwise_not(X_test_mc)
# 白黒反転した教師画像データを元データと合わせる
X_train = np.append(X_train_mc, X_train_b_n, axis=0)
# 白黒反転したテスト画像データを元データと合わせる
X_test = np.append(X_test_mc, X_test_b_n, axis=0)
# 教師正解ラベルデータを2つ合わせる
y_train = np.append(y_train_mc, y_train_mc, axis=0)
#テスト正解ラベルデータを2つ合わせる
y_test = np.append(y_test_mc, y_test_mc, axis=0)
#教師正解ラベルデータをワンホット値に変換する
y_train = to_categorical(y_train)
#テスト正解ラベルデータをワンホット値に変換する
y_test = to_categorical(y_test)
作成したデータセット数は20180で白黒
反転データを加えるので40360セットに
なります。このデータセットを使用してモデ
ルに400エポック学習させました。学習結
果は以下の通りです。


図:400エポック学習結果
左下の ”2” を ”3” と認識していますが精
度はかなり上がった印象です。更にバッチ数
を変えながら数回に分けて1410エポック
学習を行った結果がこちらです


図:1410エポック学習結果
認識が難しそうな数字が並んでいますが全て
正解です。
ペイントソフトで書いたファイルを読み込ま
せて認識させるとかなりの精度で認識できて
います。以上で改良はいったん終了となりま
す。
ペイントソフトで書いた数字を認識させるプ
ログラムですが、スキャナーからの画像とカ
メラからの画像を認識させる部分も一応作っ
て組み込んでいます。
カメラからの画像を処理するのが難しく、影
を除去するためにマスクをかけたり、画面の
暗さに合わせて自動で閾値を変化させたりす
る機能が必要だと感じました。
メインコードの中の、カメラからの画像処理
とスキャナーからの画像処理は改良の余地が
ありますので今後の課題とします。
以下が画像を切り出して数字を認識する全コ
ードです。
import os
from tensorflow.keras.preprocessing import image
import numpy as np
from tensorflow import keras
import cv2
from cv2 import THRESH_BINARY
import math
# 一次的に切り出した画像を保存するフォルダ
NUM_FOLDER = 'trim-num-file' # プログラムの最後でフォルダ内のファイルをすべて消去します
# ここから画像を切り出して予測する関数
# 画像サイズが大きすぎる場合は小さくする
def size_smaller(img):
if (img.shape[0] > 4000 or img.shape[1] > 3000):
img = cv2.resize(img, (img.shape[1] // 3, img.shape[0] // 3))
elif (img.shape[0] > 2000 or img.shape[1] > 1000):
img = cv2.resize(img, (img.shape[1] // 2, img.shape[0] // 2))
img_size = img.shape[0]
return img, img_size
# 背景が白ければ黒に反転する
def white_to_black(img):
yl = np.mean(img[0:img.shape[0], 0:img.shape[1] // 20])
yr = np.mean(img[0:img.shape[0], img.shape[1] - img.shape[1] // 20:img.shape[1]])
xt = np.mean(img[0:img.shape[0] // 20, 0:img.shape[1]])
xb = np.mean(img[img.shape[0] - img.shape[0] // 20:img.shape[0], 0:img.shape[1]])
if (yl > 140 and yl <= 255 or yr > 140 and yr <= 255
or xt > 140 and xt <= 255 or xb > 140 and xb <= 255):
img = cv2.bitwise_not(img)
return img
# 背景がノイズの入っていない白か黒か判断する
def noise_detect(img):
m = []
yl = np.mean(img[0:img.shape[0], 0:img.shape[1] // 20])
yr = np.mean(img[0:img.shape[0], img.shape[1] - img.shape[1] // 20:img.shape[1]])
xt = np.mean(img[0:img.shape[0] // 20, 0:img.shape[1]])
xb = np.mean(img[img.shape[0] - img.shape[0] // 20:img.shape[0], 0:img.shape[1]])
yl_min = np.min(img[0:img.shape[0], 0:img.shape[1] // 20])
yr_min = np.min(img[0:img.shape[0], img.shape[1] - img.shape[1] // 20:img.shape[1]])
xt_min = np.min(img[0:img.shape[0] // 20, 0:img.shape[1]])
xb_min = np.min(img[img.shape[0] - img.shape[0] // 20:img.shape[0], 0:img.shape[1]])
yl_max = np.max(img[0:img.shape[0], 0:img.shape[1] // 20])
yr_max = np.max(img[0:img.shape[0], img.shape[1] - img.shape[1] // 20:img.shape[1]])
xt_max = np.max(img[0:img.shape[0] // 20, 0:img.shape[1]])
xb_max = np.max(img[img.shape[0] - img.shape[0] // 20:img.shape[0], 0:img.shape[1]])
m_min = [yl_min, yr_min, xt_min, xb_min]
m_max = [yl_max, yr_max, xt_max, xb_max]
if (yl == 255 and yr == 255 and xt == 255 and xb == 255):
screen = "w"
d_lebel = 255
d_min = np.min(m_min)
d_max = np.max(img)
elif (yl == 0 and yr == 0 and xt == 0 and xb == 0):
screen = "b"
d_lebel = 0
d_min = np.min(m_min)
d_max = np.max(img)
else:
screen = "c"
d_lebel = (yl + yr + xt + xb) // 4
d_min = np.min(m_min)
d_max = np.max(img)
return img, screen, d_lebel, d_min, d_max, xb_min
# 画像にフレーム状のマスクをかけて主に四隅の影によるノイズを除去する
def mask(img, screen):
if screen == 'w':
print('w')
return img
elif screen =='b':
# 画像の横サイズを変数に格納
x_shape = img.shape[1]
# 画像の縦サイズを変数に格納
y_shape = img.shape[0]
# 画像横サイズの15%を変数に格納しマスクの位置調節で使用
bold_x = img.shape[1] // 15
# 画像縦サイズの15%を変数に格納しマスクの位置調節で使用
bold_y = img.shape[0] // 15
# 画像横サイズの1/3を変数に格納しマスクの幅調整で使用
divided_3 = img.shape[1] // 3
# 画像縦サイズの1/2を変数に格納
h = img.shape[0] // 2
# 画像横サイズの1/2を変数に格納
w = img.shape[1] // 2
# 画像の横幅の半分を円の半径とする
r = img.shape[1] // 2
# 時間短縮の為のステップ数を設定
step = 15
# 右下のマスク
for i in range(0, 90, step):
x = int(math.cos(math.radians(i)) * r)
y = int(math.sin(math.radians(i)) * r)
img[y + h + bold_y:, x + w - bold_x:] = 0
# 左下のマスク
for i in range(90, 180, step):
x = int(math.cos(math.radians(i)) * r)
y = int(math.sin(math.radians(i)) * r)
img[y + h + bold_y:, :x + w + bold_x] = 0
# 左上のマスク
for i in range(180, 270, step):
x = int(math.cos(math.radians(i)) * r)
y = int(math.sin(math.radians(i)) * r)
img[:y + w + bold_x, :x + w + bold_x] = 0
# 右上のマスク
for i in range(270, 360, step):
x = int(math.cos(math.radians(i)) * r)
y = int(math.sin(math.radians(i)) * r)
img[:y + w + bold_x, x + w - bold_x:] = 0
# フレームの継ぎ目のマスク
for i in range(0, bold_x, step):
img[divided_3:img.shape[0] - divided_3, 0:i] = 0
img[divided_3:img.shape[0], img.shape[1] - bold_x:] = 0
return img
elif screen == 'c':
# 画像の横サイズを変数に格納
x_shape = img.shape[1]
# 画像の縦サイズを変数に格納
y_shape = img.shape[0]
# 画像横サイズの15%を変数に格納しマスクの位置調節で使用
bold_x = img.shape[1] // 15
# 画像縦サイズの15%を変数に格納しマスクの位置調節で使用
bold_y = img.shape[0] // 15
# 画像横サイズの1/3を変数に格納しマスクの幅調整で使用
divided_3 = img.shape[1] // 3
# 画像縦サイズの1/2を変数に格納
h = img.shape[0] // 2
# 画像横サイズの1/2を変数に格納
w = img.shape[1] // 2
# 画像の横幅の半分を円の半径とする
r = img.shape[1] // 2
# 背景が白かったら黒にする
img = white_to_black(img)
# 時間短縮の為のステップ数を設定
step = 15
# 右下のマスク
for i in range(0, 90, step):
x = int(math.cos(math.radians(i)) * r)
y = int(math.sin(math.radians(i)) * r)
img[y + h + bold_y:, x + w - bold_x:] = 0
# 左下のマスク
for i in range(90, 180, step):
x = int(math.cos(math.radians(i)) * r)
y = int(math.sin(math.radians(i)) * r)
img[y + h + bold_y:, :x + w + bold_x] = 0
# 左上のマスク
for i in range(180, 270, step):
x = int(math.cos(math.radians(i)) * r)
y = int(math.sin(math.radians(i)) * r)
img[:y + w + bold_x, :x + w + bold_x] = 0
# 右上のマスク
for i in range(270, 360, step):
x = int(math.cos(math.radians(i)) * r)
y = int(math.sin(math.radians(i)) * r)
img[:y + w + bold_x, x + w - bold_x:] = 0
# フレームの継ぎ目のマスク
for i in range(0, bold_x, step):
img[divided_3:img.shape[0] - divided_3, 0:i] = 0
img[divided_3:img.shape[0], img.shape[1] - bold_x:] = 0
return img
# キャンバスの暗さに合わせて値を引き陰によるノイズを目立たなくする
def smoothing_darkness(img, d_lebel):
d = int(abs(d_lebel * 0.76))# 影カット閾値
if img.shape[0] != 28:
# 白の背景がもし暗かったら明るく修正する、キャンバスの大きさに合わせて判断する範囲を調整する
if(np.mean(img[0:img.shape[0], 0:img.shape[0] // 12]) > 200 and
np.mean(img[0:img.shape[0], 0:img.shape[0] // 12]) < 240):
img = img - d
elif(np.mean(img[0:img.shape[0], img.shape[1] - img.shape[0] // 12:img.shape[1]]) > 200 and
np.mean(img[0:img.shape[0], img.shape[1] - img.shape[0] // 12:img.shape[1]]) < 240):
img = img - d
elif(np.mean(img[0:img.shape[0]//12,0:img.shape[1]])>200 and
np.mean(img[0:img.shape[0] // 12, 0:img.shape[1]]) < 240):
img = img - d
elif(np.mean(img[img.shape[0] - img.shape[0] // 12:img.shape[0], 0:img.shape[1]]) > 200 and
np.mean(img[img.shape[0] - img.shape[0] // 12:img.shape[0], 0:img.shape[1]]) < 240):
img = img - d
elif(np.mean(img[0:img.shape[0], 0:img.shape[0] // 12]) > 180 and
np.mean(img[0:img.shape[0], 0:img.shape[0] // 12]) <= 200):
img = img - d
elif(np.mean(img[0:img.shape[0], img.shape[1] - img.shape[0] // 12:img.shape[1]]) > 180 and
np.mean(img[0:img.shape[0], img.shape[1] - img.shape[0] // 12:img.shape[1]]) <= 200):
img = img - d
elif(np.mean(img[0:img.shape[0] // 12, 0:img.shape[1]]) > 180 and
np.mean(img[0:img.shape[0] // 12, 0:img.shape[1]]) <= 200):
img = img - d
elif(np.mean(img[img.shape[0] - img.shape[0] // 12:img.shape[0], 0:img.shape[1]]) > 180 and
np.mean(img[img.shape[0] - img.shape[0] // 12:img.shape[0], 0:img.shape[1]]) <= 200):
img = img - d
return img
# 膨張
def dilate_img(img, screen):
# 背景が白で膨張をすると文字が見えなくなる
# screenはノイズのない背景が白のデータの場合"w",黒の場合"b"を返す
# 画面が暗い場合は"c"を返す
# 8近傍フィルタ
filt = np.array([[1,1,1],
[1,0,1],
[1,1,1]], np.uint8)
if screen == "w": # 背景が白ならば反転して2回膨張処理を行う
img = cv2.bitwise_not(img)
img = cv2.dilate(img, filt)
img = cv2.dilate(img, filt)
screen = 'b'
elif screen == 'b':
img = cv2.dilate(img, filt)
img = cv2.dilate(img, filt)
else: # 反転無しで2回膨張処理を行う
#img = cv2.bitwise_not(img)
img = cv2.dilate(img, filt)
img = cv2.dilate(img, filt)
screen = 'b'
return img, screen
def erode_img(img, screen):
# ノイズのない背景が白のデータの場合"w",黒の場合"b"を返す関数で判定
# 8近傍フィルタ
filt = np.array([[1,1,1],
[1,0,1],
[1,1,1]], np.uint8)
if screen == "w": # 背景が白ならば反転して2回収縮処理を行う
img = cv2.bitwise_not(img)
img = cv2.erode(img, filt)
screen = 'b'
elif screen == 'b':
img = cv2.erode(img, filt)
else: # 反転無しで2回収縮処理を行う
img = cv2.erode(img, filt)
screen = 'b'
return img, screen
# 輪郭を抽出する
def f_contours(img):
# 背景が白い場合画像の枠が輪郭としてカウントされるので処理する
img = white_to_black(img)
# グレースケール
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 2値化
_, th_img = cv2.threshold(gray, 130, 255, THRESH_BINARY)
# 輪郭を抽出する
contours, _ = cv2.findContours(th_img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 輪郭のx,y,w,hを格納するリストを作成
n = [] # 輪郭の位置
p = [] #
t = 0 #
thresh = 0.021 #0.028~0.021ノイズカット閾値
# 輪郭を格納する
for i in contours:
x, y, w, h = cv2.boundingRect(i)
# 縦横比が10倍以上は削除する(ノイズカット)
if (w // h > 0.1 and h // w < 10 or w // h < 10 and h // w > 0.1):
# 画像サイズの2.1%以下の輪郭は削除する(ノイズカット)
if (w > img.shape[1] * thresh and h > img.shape[0] * thresh):
n.append([x, y, w, h])
# 抽出した輪郭を左上から順番に並べる
num_location = sorted(n, key=lambda x:(x[1] // (img.shape[1] // 3), x[0]))
# 外接矩形を描画した画像と座標を返す
return img, num_location
# 切り出した画像を一旦ファイルに保存して認識した結果をリストに保存する
def create_num_file(img, num_location, screen):
# 切り出し他画像の一時保存ディレクトリ名
dir_path = './' + NUM_FOLDER + '/'
# 切り出す数字の余白設定
if img.shape[0] <= 28: # 画像サイズが(28,28)以下は余白無し
m1, m2, m3, m4 = 0, 0, 0, 0
elif img.shape[0] <= 50: # 画像サイズが(50,50)以下は余白1
m1, m2, m3, m4 = 1, 1, 1, 1
else: # 画像サイズが大きい場合の余白は10
m1, m2, m3, m4 = 10, 10, 10, 10
# 画像をファイルに保存する
if img.shape[0] <= 28 or img.shape[1] <= 28: # (28,28)の場合はそのままファイルに保存する
cv2.imwrite(os.path.join(NUM_FOLDER, "num0" + ".png"), img)
else:
# 画像サイズが大きければ数字の数だけ画像を切り出してファイルを保存する
for i in range(0, len(num_location)):
x, y, w, h = num_location[i]
# 画像を正方形に切り取る
n1, n2 = abs((h - w) // 2), abs((h - w) // 2)
# エラーにならない為の処理
if y - m1 < 0: # 切り取る幅が画像の上をオーバー
m1 = 0
if y + h + m2 > img.shape[0]: # 切り取る幅が画像の下をオーバー
m2 = 0
if x - n1 - m3 < 0: # 切り取る幅が画像の左端をオーバー
m3 = 0
n1 = 0
if x + w + n2 + m4 > img.shape[1]: # 切り取る幅が画像の右端をオーバー
m4 = 0
n2 = 0
# 画像を余白を付けて切り出す
trim_img = img[y - m1:y + h + m2, x - n1 - m3:x + w + n2 + m4]
# 切り出された画像の大きさに応じて線を太くする
if h > img.shape[0] * 0.9 and w > img.shape[1] * 0.9:
# 大きい画像は2度関数を使用
trim_img, screen = dilate_img(trim_img, screen)
trim_img, screen = dilate_img(trim_img, screen)
# 切り出した画像をそれぞれファイルに保存する
cv2.imwrite(os.path.join(NUM_FOLDER, 'num' + str(i) + '.png'), trim_img)
elif h > img.shape[0] * 0.5 and w > img.shape[1] * 0.5:
# 元画像の半分程度の画像は1度関数を使用
trim_img, screen = dilate_img(trim_img, screen)
# 切り出した画像をそれぞれファイルに保存する
cv2.imwrite(os.path.join(NUM_FOLDER, 'num' + str(i) + '.png'), trim_img)
else:
# 切り出した画像をそれぞれファイルに保存する
cv2.imwrite(os.path.join(NUM_FOLDER, 'num' + str(i) + '.png'), trim_img)
return dir_path
def from_paint(img, screen):
# グレースケール化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# matplotlibで表示できるように加工するペイントで作ったPNGはこれが必要
gray1 = cv2.cvtColor(gray, cv2.COLOR_BGR2RGB)
# 2値化
print(img.shape)
_, th_img = cv2.threshold(gray1, 130, 255, THRESH_BINARY)
# 2度膨張処理を行う
if (img.shape[0] <= 50 or img.shape[1] <= 50):
d_img = th_img
else:
d_img, screen = dilate_img(th_img, screen)
# 2度膨張処理を行う
if (img.shape[0] <= 500 or img.shape[1] <= 500):
d1_img = d_img
else:
d1_img, screen = dilate_img(d_img, screen)
# 2度膨張処理を行う
if (img.shape[0] <= 100 or img.shape[1] <= 100):
d2_img = d1_img
else:
d2_img, screen = dilate_img(d1_img, screen)
# 輪郭を抽出する
c_img, num_location = f_contours(d2_img)
# 画像を切り出してファイルに保存する
dir_path = create_num_file(c_img, num_location, screen)
return dir_path
def from_camera(img, screen, d_min, d_max, xb_min):
# 四隅のノイズを除去する
m_img = mask(img, screen)
# グレースケール化
gray = cv2.cvtColor(m_img, cv2.COLOR_BGR2GRAY)
# matplotlibで表示できるように加工するペイントで作った画像はこれが必要
p_img = cv2.cvtColor(gray, cv2.COLOR_BGR2RGB)
# 2値化
_, th_img = cv2.threshold(p_img, 110, 255, THRESH_BINARY)#130 薄い画像は20
# 2度膨張処理を行う
if (img.shape[0] <= 160 or img.shape[1] <= 160):
d_img = th_img
else:
d_img, screen = dilate_img(th_img, screen)
# 四隅のノイズを除去する
if (img.shape[0] > 1000 and img.shape[1] >1000):
m1_img = mask(d_img, screen)
else:
m1_img = d_img
# 輪郭を抽出する
c_img, num_location = f_contours(m1_img)
# 画像を切り出してファイルに保存する
dir_path = create_num_file(c_img, num_location, screen)
return dir_path
def from_scaner(img, screen):
# 四隅のノイズを除去する
m_img = mask(img, screen)
# グレースケール化
gray = cv2.cvtColor(m_img, cv2.COLOR_BGR2GRAY)
# matplotlibで表示できるように加工するペイントで作ったPNGはこれが必要
p_img = cv2.cvtColor(gray, cv2.COLOR_BGR2RGB)
# 2値化
_, th_img = cv2.threshold(p_img, 130, 255, THRESH_BINARY)
# 2度膨張処理を行う
if (img.shape[0] <= 50 or img.shape[1] <= 50):
d_img = th_img
else:
d_img, screen = dilate_img(th_img, screen)
# 収縮処理を行う
if (img.shape[0] <= 100 or img.shape[1] <= 100):
e_img = d_img
else:
e_img, screen = erode_img(d_img, screen)
# 四隅のノイズを除去する
m1_img = mask(e_img, screen)
# 2度膨張処理を行う
if (img.shape[0] <= 100 or img.shape[1] <= 100):
d1_img = m1_img
else:
d1_img, screen = dilate_img(m1_img, screen)
# 輪郭を抽出する
c_img, num_location = f_contours(d1_img)
# 画像を切り出してファイルに保存する
dir_path = create_num_file(c_img, num_location, screen)
return dir_path
# ここから画像を受け取り切り出して予測する
#学習済みモデルをロード
model = load_model('./model.h5', compile=False)
# 画像を読み込む
img = cv2.imread('./' + filepath)
# 画像をNumPy配列に変換
img = np.array(img)
# 処理速度向上のために画像サイズを小さくする
_ ,img_size = size_smaller(img)
# 主にカメラやスキャナー用
img, screen, d_lebel, d_min, d_max, xb_min = noise_detect(img)
# 暗い部分のある画像をスムーズにする
lite_img = smoothing_darkness(img, d_lebel)
# ペイント画像、カメラ画像、スキャナで処理を分ける
if img_size != 28 and d_lebel == 0 or d_lebel == 255:
# ペイントからの画像を処理
dir_path = from_paint(lite_img, screen)
elif (img_size != 28 and d_lebel > 160 and d_lebel <190 or d_lebel >3 and d_lebel < 30):
# カメラから画像を処理
dir_path = from_camera(lite_img, screen, d_min, d_max, xb_min)
elif (img_size != 28 and d_lebel >= 190 and d_lebel <255):
# スキャナーからの画像を処理
dir_path = from_scaner(lite_img, screen)
elif img_size == 28: #(28,28)サイズの画像は複数文字認識無し
# 輪郭を抽出する
_, num_location = f_contours(lite_img)
# 画像を切り出してファイルに保存する
dir_path = create_num_file(lite_img, num_location, screen)
p = [] # 認識結果を格納するリスト
q = 0 # 切り出して書き込んだファイル数をカウントする
# 指定のディレクトリ内のファイルを読み込み数字を認識する
for i in os.listdir(dir_path):
# 切り取った画像を読み込みむ
img = cv2.imread(dir_path + i)
# グレースケール化
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#(28,28)にリサイズ
img = cv2.resize(img,(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
# 変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
# リストに認識結果を格納する
if np.max(result) < 0.5: # 認識結果が0.5より小さい場合は(*)を表示する
p.append('(*)')
elif np.max(result) >= 0.5: # 認識結果が0.5以上の場合は認識結果を格納する
predicted = result.argmax()
p.append(classes[predicted])
q = q + 1
pred_answer = "これは " + ''.join(p) + " です"
print(str(pred_answer))
p=[] # リストをリセットする
# dir_pathフォルダ内の切り出した数字ファイルを削除します
for i in range(q): #書き込んだファイル分だけ消去する
# dir_path内の一番初めのファイルを削除
# gitkeepなどのファイルを入れた場合はインデックスは1にする
os.remove(dir_path + os.listdir(dir_path)[0])
このプログラムファイルと同じ階層に切り出
した画像を一時的に保存するtrim-num-fileフォル
ダを作成して、数字画像のファイルパスを手
動で指定すると、認識結果が表示されます。モデ
ルはご自身で作成したものをロードしてください。
まとめ
今回改良を行ってみて分かったことは
●暗い画像は認識させるのが難しい
●ペイントソフトで書いた数字は認識させ易い
●学習データの量を増やすと認識精度がアップ
するという事です。
今後はこれをベースとして改良して、今後帳
票などの紙データの入力支援に使うアプリを
作成したいと思います。最後までご覧いただ
きありがとうございました。