はじめに
最近zoomでの会議や授業などが増えてきていますが、やはり対面じゃないとどのくらい話に関心を持ってくれているのかわからない…ということがあると感じ、数値化してみればいいんじゃないか?と思い立ち作ってみました。
初投稿なので拙い部分もありますが最後まで読んでいただければ幸いです![]()
目的
zoom会議の画像または動画を取得し、写っている顔を認識、話への関心度を測定する。
実装
試しに
今回zoom会議に出席している人物の顔認識をするのにAmazon Rekognitionを使うことにしました。
使い方はこちらの記事を参考させていただきました。
https://qiita.com/G-awa/items/477f2324552cb908ecd0
import cv2
import numpy as np
import boto3
# スケールや色などの設定
scale_factor = .15
green = (0,255,0)
red = (0,0,255)
frame_thickness = 2
cap = cv2.VideoCapture(0)
rekognition = boto3.client('rekognition')
# フォントサイズ
fontscale = 1.0
# フォント色 (B, G, R)
color = (0, 120, 238)
# フォント
fontface = cv2.FONT_HERSHEY_DUPLEX
# q を押すまでループします。
while(True):
# フレームをキャプチャ取得
ret, frame = cap.read()
height, width, channels = frame.shape
# jpgに変換 画像ファイルをインターネットを介してAPIで送信するのでサイズを小さくしておく
small = cv2.resize(frame, (int(width * scale_factor), int(height * scale_factor)))
ret, buf = cv2.imencode('.jpg', small)
# Amazon RekognitionにAPIを投げる
faces = rekognition.detect_faces(Image={'Bytes':buf.tobytes()}, Attributes=['ALL'])
# 顔の周りに箱を描画する
for face in faces['FaceDetails']:
smile = face['Smile']['Value']
cv2.rectangle(frame,
(int(face['BoundingBox']['Left']*width),
int(face['BoundingBox']['Top']*height)),
(int((face['BoundingBox']['Left']+face['BoundingBox']['Width'])*width),
int((face['BoundingBox']['Top']+face['BoundingBox']['Height'])*height)),
green if smile else red, frame_thickness)
emothions = face['Emotions']
i = 0
for emothion in emothions:
cv2.putText(frame,
str(emothion['Type']) + ": " + str(emothion['Confidence']),
(25, 40 + (i * 25)),
fontface,
fontscale,
color)
i += 1
# 結果をディスプレイに表示
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
とりあえずコードを試しに動かしてみると顔認識&感情分析ができた!、、、のですが動画取得だと重くて途中で止まってしまいました。
なので画像を読み込ませることにします。
(これは参考にした記事のコードです。)
画面のキャプチャ
画像のキャプチャはこちらの記事を参考にさせていただきました。
https://qiita.com/koara-local/items/6a98298d793f22cf2e36
PILを利用して画面のキャプチャを行いました。
from PIL import ImageGrab
ImageGrab.grab().save("./capture/PIL_capture.png")
別にcaptureというフォルダを作りそのフォルダに保存するようにしました。
実装
import cv2
import numpy as np
import boto3
# スケールや色などの設定
scale_factor = .15
green = (0,255,0)
red = (0,0,255)
frame_thickness = 2
# cap = cv2.VideoCapture(0)
rekognition = boto3.client('rekognition')
# フォントサイズ
fontscale = 1.0
# フォント色 (B, G, R)
color = (0, 120, 238)
# フォント
fontface = cv2.FONT_HERSHEY_DUPLEX
from PIL import ImageGrab
ImageGrab.grab().save("./capture/PIL_capture.png")
# フレームをキャプチャ取得
# ret, frame = cap.read()
frame = cv2.imread("./capture/PIL_capture.png")
height, width, channels = frame.shape
frame = cv2.resize(frame,(int(width/2),int(height/2)),interpolation = cv2.INTER_AREA)
# jpgに変換 画像ファイルをインターネットを介してAPIで送信するのでサイズを小さくしておく
small = cv2.resize(frame, (int(width * scale_factor), int(height * scale_factor)))
ret, buf = cv2.imencode('.jpg', small)
# Amazon RekognitionにAPIを投げる
faces = rekognition.detect_faces(Image={'Bytes':buf.tobytes()}, Attributes=['ALL'])
# 顔の周りに箱を描画する
for face in faces['FaceDetails']:
smile = face['Smile']['Value']
cv2.rectangle(frame,
(int(face['BoundingBox']['Left']*width/2),
int(face['BoundingBox']['Top']*height/2)),
(int((face['BoundingBox']['Left']/2+face['BoundingBox']['Width']/2)*width),
int((face['BoundingBox']['Top']/2+face['BoundingBox']['Height']/2)*height)),
green if smile else red, frame_thickness)
emothions = face['Emotions']
i = 0
score = 0
for emothion in emothions:
if emothion["Type"] == "HAPPY":
score = score + emothion["Confidence"]
elif emothion["Type"] == "DISGUSTED":
score = score - emothion["Confidence"]
elif emothion["Type"] == "SURPRISED":
score = score + emothion["Confidence"]
elif emothion["Type"] == "ANGRY":
score = score - emothion["Confidence"]
elif emothion["Type"] == "CONFUSED":
score = score - emothion["Confidence"]
elif emothion["Type"] == "CALM":
score = score - emothion["Confidence"]
elif emothion["Type"] == "SAD":
score = score - emothion["Confidence"]
i += 1
if i == 7:
cv2.putText(frame,
"interested" +":"+ str(round(score,2)),
(int(face['BoundingBox']['Left']*width/2),
int(face['BoundingBox']['Top']*height/2)),
fontface,
fontscale,
color)
# 結果をディスプレイに表示
cv2.imshow('frame', frame)
cv2.waitKey(0)
cv2.destroyAllWindows()
画像の読み込み自体にはOpenCVを用いました。
Amazon RekognitionはHAPPY,DISGUSETED,SURPRISED,ANGRY,CONFUSED,CALM,SADの6つの感情が読み取れるのでHAPPYとSURPRISEDをプラスの感情(興味度高)、その他の感情をマイナスの感情(興味度低)として計算をしていき最終的に-100~100の範囲で興味度を認識した顔の上に表示するようにしました。
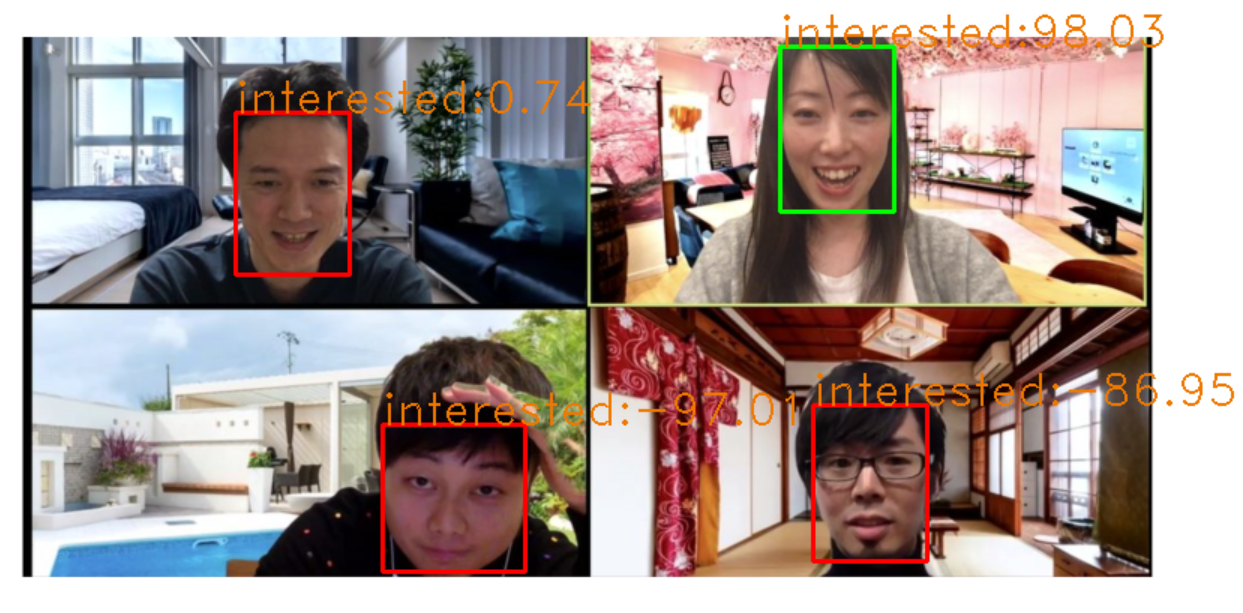
zoomで人を集められなかったため人の画像をお借りしています。
https://tanachannell.com/4869
Amazon Rekognitionにはほかにも機能があるので是非興味のある方は見てみてください!
https://docs.aws.amazon.com/ja_jp/rekognition/latest/dg/faces-detect-images.html
問題点
・zoomの参加人数が大人数の場合表示される文字同士が重なってしまいとても見づらくなってしまう。
・Zoom画面のキャプチャではないため実行してすぐにコマンドプロンプトを最小化しなければ画像にコマンドプロンプトが写ってしまう。
最後に
せっかく作ったのだから人に見てもらいたい!という思いで書き始めましたが、書いてると自分が作っている間の追体験ができ、勉強になりました。
自分がこんな風に作ったものが世の中に浸透していったらとても楽しいかもしれませんね!