ZOZOテクノロジーズ #2 Advent Calendar 2019の4日目の記事になります。
gold_kouさんの3日連続エントリーからバトンを引き継ぎましたデータエンジニア 遠藤です。
現在、データ×テクノロジーでZOZOグループのマーケティングを支援するデータチームに所属して、データ処理基盤の運用などに従事しています。
Qiitaは今までずっとROM専だったのですが、今回のAdvent Calendar投稿を機にアカウントを作成したので、情報を発信していければと思っております。
はじめに
現在、ビッグデータに取り組むところのほとんどは、業務のあらゆるデータをデータウェアハウス(DWH)に集約しているかと思います。(弊社はBigQueryを用いています)
DWHのデータアーキテクチャとして、業務システムDBのテーブルコピーをそのまま持ってきて運用しているところも多いのではないのでしょうか?
DWHから何かを集計するために長いSQL文を書いていないでしょうか??
さらに、集計するたびに「このデータ集計、もっと簡単にできないものだろうか...」と感じたことがあるのではないでしょうか???
本記事は以上のモヤモヤを感じた方に贈る記事となります。
業務システムDB(OLTP)と分析システムDB(OLAP)
データベースは、大別すると2つの目的で利用されます。
- トランザクションの記録と参照
- データの分析
トランザクションの記録と参照には業務システムDB(OLTP) 、データの分析には**分析システムDB(OLAP)**をそれぞれ構築することで実現します。
OLTPとOLAPの特徴をまとめると以下の表になります。
| 業務システムDB(OLTP) | 分析システムDB(OLAP) | |
|---|---|---|
| 目的 | 業務処理の実行 | 業務処理の分析 |
| DBとしての動作 | SELECT・INSERT・UPDATE・DELETE | SELECT |
| 処理単位 | 個々の処理を扱う | データの集約 |
| 検索パターン | 定型的 | 非定型的 |
| 利用データの鮮度 | 現在 | 現在・過去 |
| 非機能要件 | 更新処理の同時実行性 | 高速な検索処理 |
| データモデル | ER設計・第三正規形 | 多次元データモデル/スタースキーマ |
OLTPとOLAPの特徴は全く対照的であり、DWHに業務システムDBのテーブルをそのままコピーして分析に使う設計では分析DBとして適さないことが分かります。
多次元データモデル
多次元データモデル(Multi Dimensional Data Model)とはOLAPにおいて要件の目的に基づく集計を行うためのデータモデルです。
多次元データモデルは、集計の元データとなるファクトと集計の目的を示すディメンションの2つの要素から構成されます。
ファクト
ある業務プロセスで起こる事象を「ファクト」として以下の情報を記録します。
- 業務プロセスの最小単位を構成するID群(ファクト1レコードが複数の業務プロセスを表すことがないように決定)
- ファクトが起こったTIMESTAMP
- 分析対象となる数値データ
- 各ディメンションの主キー(後述)
この各業務プロセスにおけるファクトデータが、集計のデータ元となり、集計時に用いる適切なID・集計数値データのみ抽出できるようにします。
ディメンション
以下のデータは全て「ディメンション」として保存します。
- 「~ごとに」といったデータを集約するためのデータ
- データを絞り込むために利用するためのデータ
ディメンションの項目は、適切なグループに分類して関連するデータをテーブルごとにまとめておくことで管理します。例えば、「〇〇に関するマスタデータ」はディメンションに相当します。
なお、ディメンション項目は、ディメンション項目内のコード値…_id・フラグ値…_flagのみならずコード値・フラグ値に対応する説明…_nameもあえて明記するようにします。
スタースキーマ
ファクト・ディメンションの例として、とあるシステムの注文データにあてはめると以下の図になります。
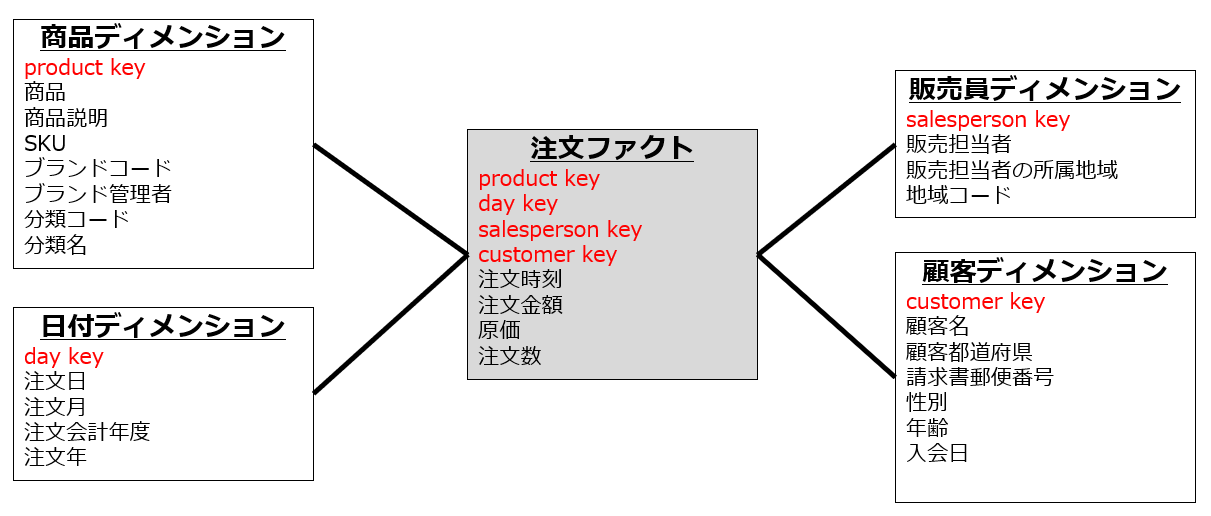
多次元データモデルをRDBMSで実装した形態は、ER図で表したときにその見た目が星形であることから、スタースキーマと呼ばれています。
スタースキーマは、利用者がファクトとディメンションを組み合わせるだけで集計が可能になることが目標であり、非エンジニアにとっても理解しやすい形になるように設計します。
OLTP側の視点から見ると、スタースキーマの設計は第三正規形になっていないことがありますが、ここではデータの整合性が目的ではないので第三正規形でなくても構わない形態になります。
スタースキーマにおける典型的な分析用クエリは以下になります。
SELECT product.category, -- 分析軸(商品ディメンション)
product.product, -- 分析軸(商品ディメンション)
SUM(order_fact.order_unit_price * order_fact.order_num) --集計結果(注文ファクト)
FROM order_fact
LEFT OUTER JOIN product
ON order_fact.product_key = product.product_key
LEFT OUTER JOIN day
ON order_fact.day_key = day.day_key
WHERE day.year = 2019 -- フィルタ条件(日付ディメンション)
AND day.month_name = 'December' -- フィルタ条件(日付ディメンション)
GROUP BY product.category, product.product --分析軸(商品ディメンション)
スタースキーマではファクトとディメンションの組み合わせを基本にクエリを作成するので、クエリ構文が定型化されます。
多次元データモデルを定着させる解決法
OLAPや多次元データモデルは、話題としてはQiitaにも他の人によって既に投稿されていますが、業務システムDBの話題と比べるとなかなか定着していないのが現状です。
その原因として、OLAP/スタースキーマの作成と運用を行うには膨大なコスト・システムリソースを要していたからだと考えられます。
スタースキーマを確立させるためには、業務DBとは別にデータの実体を用意しなければならないですし、(OLTPから変換する手間も必要)
OLAP上のテーブルカラム構成を更新する場合はデータの作り直しが1から発生します。
この課題に対して、弊社では**Looker上で多次元データモデルのOLAPを仮想的に作成**することで解決しました。つまり、Looker上で、BigQueryのOLTPコピーテーブルをOLAP多次元データモデルへ仮想的に変換して、データを取り出しやすい構造を構築しています。
弊社におけるLookerの利用法に関しては、以下の記事リンクからご覧ください。

おわりに
本記事では、分析システム(OLAP)のデータモデルの概要を紹介させていただきました。(今回は概要のみ触れさせていただきました)
集計が出しにくいと思った場合、そもそもデータモデルが適していないことから意識して、再度設計からやり直してみるのも手かもしれません。
まとめ
- 業務システム(OLTP)と分析システム(OLAP)のデータアーキテクチャは全く違う
- OLAPは多次元データモデルで設計するのが吉
- 多次元データモデルはファクトとディメンションで構成される
- 仮想的なOLAPの構築はLookerがとても有用
参考
http://www.dbstories.com/
分析DBに関するとても役立つブログ記事ばかりが載っていましたが、2019/12/04現在、リンク切れをおこしています。。。orz